
AWS Certified Data Engineer - Associate - (DEA-C01) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 1 Single Choice
The data engineering team at a company wants to analyze Amazon S3 storage access patterns to decide when to transition the right data to the right storage class.
Which of the following represents a correct option regarding the capabilities of Amazon S3 Analytics storage class analysis?
Explanation

Click "Show Answer" to see the explanation here
Correct option:
Storage class analysis only provides recommendations for Standard to Standard IA classes
By using Amazon S3 analytics Storage Class Analysis you can analyze storage access patterns to help you decide when to transition the right data to the right storage class. This new Amazon S3 analytics feature observes data access patterns to help you determine when to transition less frequently accessed STANDARD storage to the STANDARD_IA (IA, for infrequent access) storage class.
Storage class analysis only provides recommendations for Standard to Standard IA classes.
After storage class analysis observes the infrequent access patterns of a filtered set of data over a period of time, you can use the analysis results to help you improve your lifecycle configurations. You can configure storage class analysis to analyze all the objects in a bucket. Or, you can configure filters to group objects together for analysis by common prefix (that is, objects that have names that begin with a common string), by object tags, or by both prefix and tags.
Incorrect options:
Storage class analysis only provides recommendations for Standard to Standard One-Zone IA classes
Storage class analysis only provides recommendations for Standard to Glacier Deep Archive classes
Storage class analysis only provides recommendations for Standard to Glacier Flexible Retrieval classes
These three options contradict the explanation provided above, so these options are incorrect.
References:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html
https://docs.aws.amazon.com/AmazonS3/latest/userguide/analytics-storage-class.html
Explanation
Correct option:
Storage class analysis only provides recommendations for Standard to Standard IA classes
By using Amazon S3 analytics Storage Class Analysis you can analyze storage access patterns to help you decide when to transition the right data to the right storage class. This new Amazon S3 analytics feature observes data access patterns to help you determine when to transition less frequently accessed STANDARD storage to the STANDARD_IA (IA, for infrequent access) storage class.
Storage class analysis only provides recommendations for Standard to Standard IA classes.
After storage class analysis observes the infrequent access patterns of a filtered set of data over a period of time, you can use the analysis results to help you improve your lifecycle configurations. You can configure storage class analysis to analyze all the objects in a bucket. Or, you can configure filters to group objects together for analysis by common prefix (that is, objects that have names that begin with a common string), by object tags, or by both prefix and tags.
Incorrect options:
Storage class analysis only provides recommendations for Standard to Standard One-Zone IA classes
Storage class analysis only provides recommendations for Standard to Glacier Deep Archive classes
Storage class analysis only provides recommendations for Standard to Glacier Flexible Retrieval classes
These three options contradict the explanation provided above, so these options are incorrect.
References:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html
https://docs.aws.amazon.com/AmazonS3/latest/userguide/analytics-storage-class.html
Question 2 Multiple Choice
An e-commerce company runs its workloads on Amazon EMR clusters. The data engineering team at the company manually installs third-party libraries on the newly launched clusters by logging onto the master nodes. The team wants to develop an automated solution that will replace this human intervention.
Which of the following options would you recommend for the given requirement? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Upload the required installation scripts in Amazon S3 and execute them using custom bootstrap actions
You can use a bootstrap action to install additional software or customize the configuration of the EMR cluster instances. Bootstrap actions are scripts that run on the cluster after Amazon EMR launches the instance using the Amazon Linux Amazon Machine Image (AMI). Bootstrap actions run before Amazon EMR installs the applications that you specify when you create the cluster and before cluster nodes begin processing data.
 via - https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-plan-bootstrap.html
via - https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-plan-bootstrap.html
Provision an Amazon EC2 instance with Amazon Linux and install the required third-party libraries on the instance. Create an AMI using this EC2 instance and then use this AMI to launch the EMR cluster
You can create Amazon EMR clusters that have custom Amazon Machine Images (AMI) running Amazon Linux. You can create the AMI from an EC2 instance running Amazon Linux. Make sure that you have installed all the required third-party libraries on this EC2 instance. This allows you to preload additional software on your AMI and use these AMIs to launch your EMR clusters.
Incorrect options:
Upload the required installation scripts in DynamoDB and use a Lambda function to execute these scripts for installing the third-party libraries on the EMR cluster - This option has been added as a distractor. You can only load installation scripts from Amazon S3 for custom bootstrap actions on the EMR cluster.
Provision an Amazon EC2 instance with Amazon Linux and install the required third-party libraries on the instance and then use this EC2 instance to launch the EMR cluster - You need to use an AMI to launch the EMR cluster. You cannot directly use an EC2 instance to launch an EMR cluster.
Upload the required installation scripts in Amazon S3 and execute them using AWS EMR CLI - You can automate the installation of libraries by executing the installation scripts on S3 via custom bootstrap actions. You cannot replace custom bootstrap actions with AWS EMR CLI for the given use case.
References:
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-plan-bootstrap.html
Explanation
Correct options:
Upload the required installation scripts in Amazon S3 and execute them using custom bootstrap actions
You can use a bootstrap action to install additional software or customize the configuration of the EMR cluster instances. Bootstrap actions are scripts that run on the cluster after Amazon EMR launches the instance using the Amazon Linux Amazon Machine Image (AMI). Bootstrap actions run before Amazon EMR installs the applications that you specify when you create the cluster and before cluster nodes begin processing data.
via - https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-plan-bootstrap.html
Provision an Amazon EC2 instance with Amazon Linux and install the required third-party libraries on the instance. Create an AMI using this EC2 instance and then use this AMI to launch the EMR cluster
You can create Amazon EMR clusters that have custom Amazon Machine Images (AMI) running Amazon Linux. You can create the AMI from an EC2 instance running Amazon Linux. Make sure that you have installed all the required third-party libraries on this EC2 instance. This allows you to preload additional software on your AMI and use these AMIs to launch your EMR clusters.
Incorrect options:
Upload the required installation scripts in DynamoDB and use a Lambda function to execute these scripts for installing the third-party libraries on the EMR cluster - This option has been added as a distractor. You can only load installation scripts from Amazon S3 for custom bootstrap actions on the EMR cluster.
Provision an Amazon EC2 instance with Amazon Linux and install the required third-party libraries on the instance and then use this EC2 instance to launch the EMR cluster - You need to use an AMI to launch the EMR cluster. You cannot directly use an EC2 instance to launch an EMR cluster.
Upload the required installation scripts in Amazon S3 and execute them using AWS EMR CLI - You can automate the installation of libraries by executing the installation scripts on S3 via custom bootstrap actions. You cannot replace custom bootstrap actions with AWS EMR CLI for the given use case.
References:
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-plan-bootstrap.html
Question 3 Single Choice
An application uses Kinesis Data Streams to process real-time data for business analytics. Monitoring this incoming and outgoing data stream from the Kinesis Data Streams is important for the performance of the system as well as the downstream applications. For a read-intensive requirement, the age for the last record in the data stream for all the GetRecords requests need to be tracked.
Which stream-level metric will help address this requirement?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
GetRecords.IteratorAgeMilliseconds - GetRecords.IteratorAgeMilliseconds measures the age in milliseconds of the last record in the stream for all GetRecords requests. A value of zero for this metric indicates that the records are current within the stream. A lower value is preferred. To monitor any performance issues, increase the number of consumers for your stream so that the data is processed more quickly. To optimize your application code, increase the number of consumers to reduce the delay in processing records.
Incorrect options:
GetRecords.Latency - GetRecords.Latency measures the time taken for each GetRecords operation on the stream over a specified time period. Confirms sufficient physical resources or record processing logic for increased stream throughput. Processes larger batches of data to reduce network and other downstream latencies in your application. The GetRecords.Latency metric confirms that the IDLE_TIME_BETWEEN_READS_IN_MILLIS setting is set to keep up with stream processing.
PutRecords.Latency - PutRecords.Latency measures the time taken for each PutRecords operation on the stream over a specified time period. If the PutRecords.Latency value is high, aggregate records into a larger file to put batch data into the Kinesis data stream.
ReadProvisionedThroughputExceeded - ReadProvisionedThroughputExceeded measures the count of GetRecords calls that throttled during a given time period, exceeding the service or shard limits for Kinesis Data Streams. A value of zero indicates that the data consumers aren't exceeding service quotas. Any other value indicates that the throughput limit is exceeded, requiring additional shards.
References:
https://aws.amazon.com/premiumsupport/knowledge-center/kinesis-data-streams-troubleshoot/
https://docs.aws.amazon.com/streams/latest/dev/monitoring.html
Explanation
Correct option:
GetRecords.IteratorAgeMilliseconds - GetRecords.IteratorAgeMilliseconds measures the age in milliseconds of the last record in the stream for all GetRecords requests. A value of zero for this metric indicates that the records are current within the stream. A lower value is preferred. To monitor any performance issues, increase the number of consumers for your stream so that the data is processed more quickly. To optimize your application code, increase the number of consumers to reduce the delay in processing records.
Incorrect options:
GetRecords.Latency - GetRecords.Latency measures the time taken for each GetRecords operation on the stream over a specified time period. Confirms sufficient physical resources or record processing logic for increased stream throughput. Processes larger batches of data to reduce network and other downstream latencies in your application. The GetRecords.Latency metric confirms that the IDLE_TIME_BETWEEN_READS_IN_MILLIS setting is set to keep up with stream processing.
PutRecords.Latency - PutRecords.Latency measures the time taken for each PutRecords operation on the stream over a specified time period. If the PutRecords.Latency value is high, aggregate records into a larger file to put batch data into the Kinesis data stream.
ReadProvisionedThroughputExceeded - ReadProvisionedThroughputExceeded measures the count of GetRecords calls that throttled during a given time period, exceeding the service or shard limits for Kinesis Data Streams. A value of zero indicates that the data consumers aren't exceeding service quotas. Any other value indicates that the throughput limit is exceeded, requiring additional shards.
References:
https://aws.amazon.com/premiumsupport/knowledge-center/kinesis-data-streams-troubleshoot/
https://docs.aws.amazon.com/streams/latest/dev/monitoring.html
Question 4 Single Choice
A financial analytics company wants to gather insights from personal finance data stored on Amazon S3 in the Microsoft Excel workbook format.
Which of the following represents a serverless solution to interactively discover, clean and transform this raw data for performing this analysis?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Leverage AWS Glue DataBrew to analyze the data stored on Amazon S3
AWS Glue DataBrew is a visual data preparation tool that enables users to clean and normalize data. AWS Glue DataBrew is a serverless solution to get insights from raw data. You can interactively discover, visualize, clean, and transform raw data. DataBrew makes smart suggestions to help you identify data quality issues that can be difficult to find and time-consuming to fix. To prepare the data, you can choose from more than 250 point-and-click transformations. These include removing nulls, replacing missing values, fixing schema inconsistencies, creating columns based on functions, and many more.
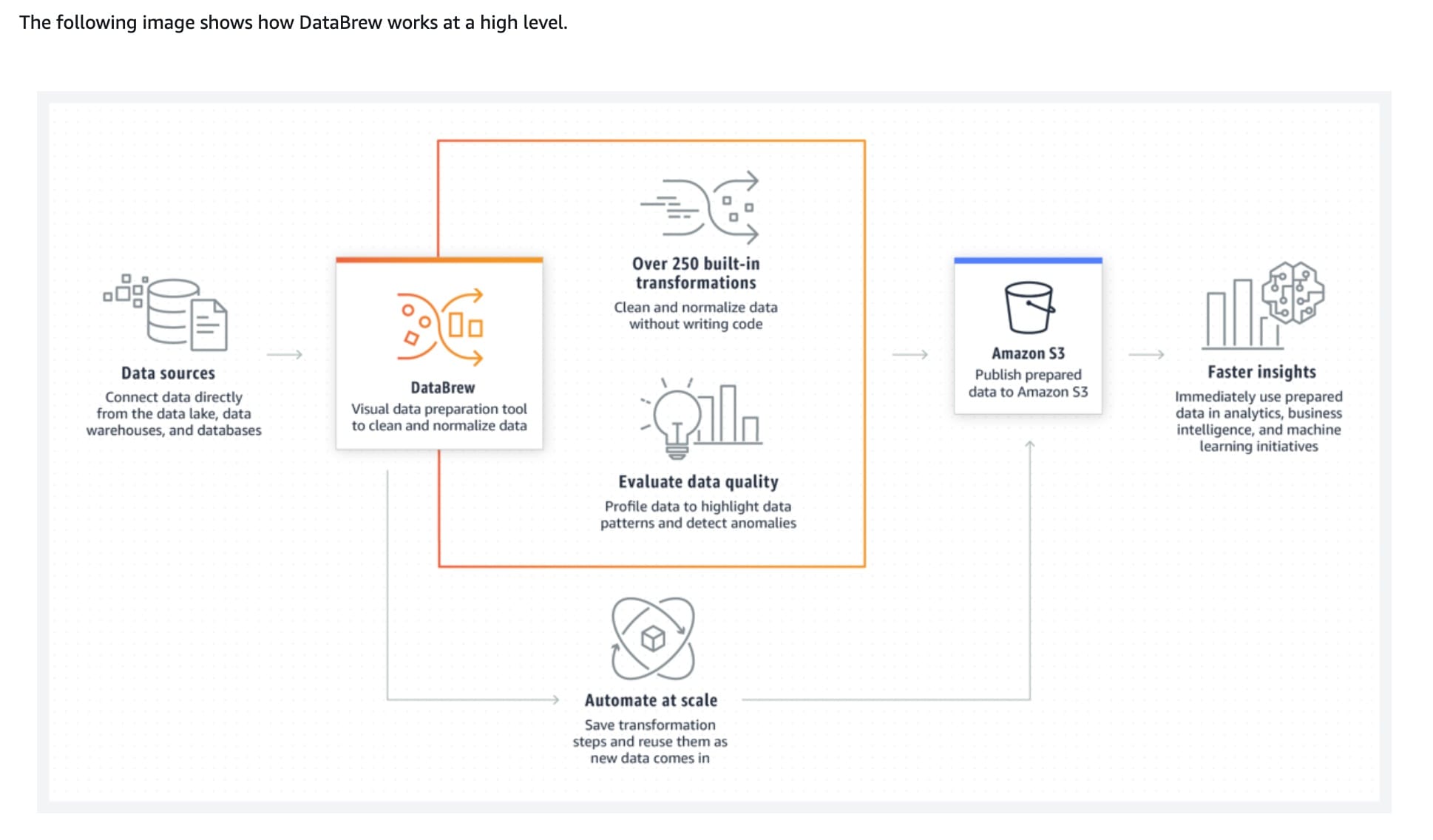 via - https://docs.aws.amazon.com/databrew/latest/dg/what-is.html
via - https://docs.aws.amazon.com/databrew/latest/dg/what-is.html
Regarding any files stored in Amazon S3 or any files that you upload from a local drive, DataBrew supports the following file formats: comma-separated value (CSV), Microsoft Excel, JSON, ORC, and Parquet.
Incorrect options:
Leverage Amazon Athena to analyze the data stored on Amazon S3 - Amazon Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena supports creating tables and querying data from CSV, TSV, custom-delimited, and JSON formats; data from Hadoop-related formats: ORC, Apache Avro and Parquet; logs from Logstash, AWS CloudTrail logs, and Apache WebServer logs. Athena does not support querying data from files stored in the Microsoft Excel workbook format, so this option is incorrect.
Leverage Amazon Redshift Spectrum to analyze the data stored on Amazon S3 - Using Amazon Redshift Spectrum, you can efficiently query and retrieve structured and semistructured data from files in Amazon S3 without having to load the data into Amazon Redshift tables. Redshift does not support reading Excel files directly, as it can only support CSV, AVRO, JSON, PARQUET and ORC formats.
Leverage Amazon Glue Data Catalog to analyze the data stored on Amazon S3 - The AWS Glue Data Catalog contains references to data that is used as sources and targets of your extract, transform, and load (ETL) jobs in AWS Glue. To create your data warehouse or data lake, you must catalog this data. The AWS Glue Data Catalog is an index to the location, schema, and runtime metrics of your data. The Amazon Glue Data Catalog itself cannot be used to analyze the data stored on Amazon S3.
AWS Glue Data Catalog: 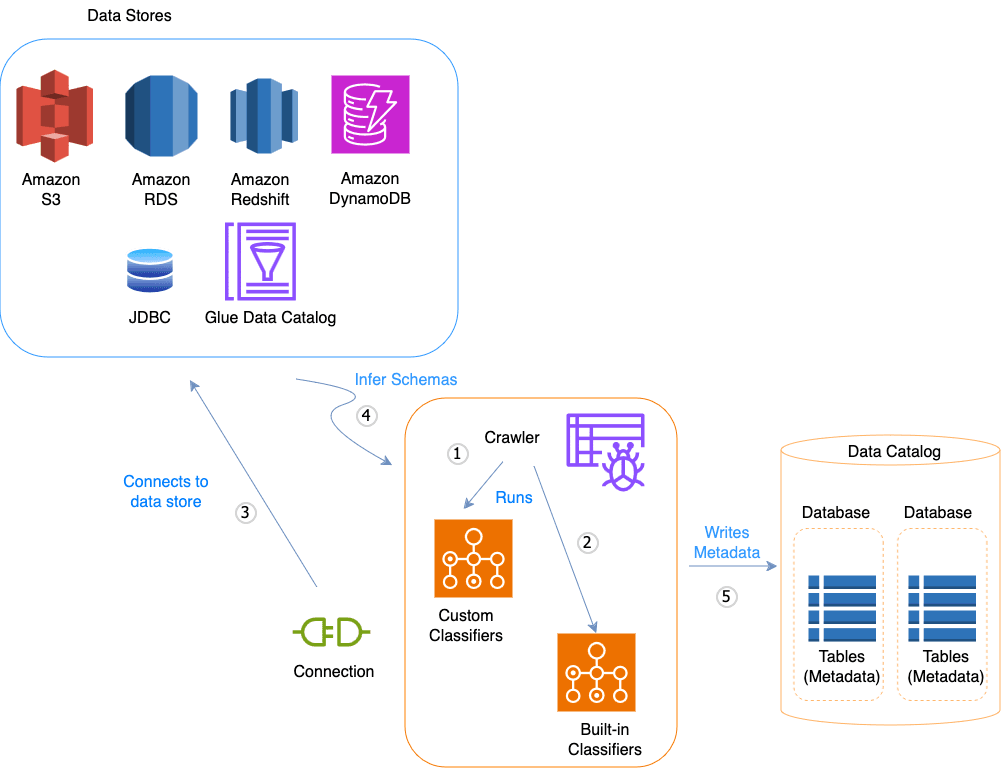 via - https://docs.aws.amazon.com/glue/latest/dg/catalog-and-crawler.html
via - https://docs.aws.amazon.com/glue/latest/dg/catalog-and-crawler.html
References:
https://docs.aws.amazon.com/databrew/latest/dg/what-is.html
https://docs.aws.amazon.com/athena/latest/ug/what-is.html
https://docs.aws.amazon.com/databrew/latest/dg/supported-data-file-sources.html
https://docs.aws.amazon.com/athena/latest/ug/supported-serdes.html
https://docs.aws.amazon.com/glue/latest/dg/catalog-and-crawler.html
https://docs.aws.amazon.com/redshift/latest/dg/c-using-spectrum.html
https://docs.aws.amazon.com/redshift/latest/dg/copy-parameters-data-format.html
Explanation
Correct option:
Leverage AWS Glue DataBrew to analyze the data stored on Amazon S3
AWS Glue DataBrew is a visual data preparation tool that enables users to clean and normalize data. AWS Glue DataBrew is a serverless solution to get insights from raw data. You can interactively discover, visualize, clean, and transform raw data. DataBrew makes smart suggestions to help you identify data quality issues that can be difficult to find and time-consuming to fix. To prepare the data, you can choose from more than 250 point-and-click transformations. These include removing nulls, replacing missing values, fixing schema inconsistencies, creating columns based on functions, and many more.
via - https://docs.aws.amazon.com/databrew/latest/dg/what-is.html
Regarding any files stored in Amazon S3 or any files that you upload from a local drive, DataBrew supports the following file formats: comma-separated value (CSV), Microsoft Excel, JSON, ORC, and Parquet.
Incorrect options:
Leverage Amazon Athena to analyze the data stored on Amazon S3 - Amazon Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena supports creating tables and querying data from CSV, TSV, custom-delimited, and JSON formats; data from Hadoop-related formats: ORC, Apache Avro and Parquet; logs from Logstash, AWS CloudTrail logs, and Apache WebServer logs. Athena does not support querying data from files stored in the Microsoft Excel workbook format, so this option is incorrect.
Leverage Amazon Redshift Spectrum to analyze the data stored on Amazon S3 - Using Amazon Redshift Spectrum, you can efficiently query and retrieve structured and semistructured data from files in Amazon S3 without having to load the data into Amazon Redshift tables. Redshift does not support reading Excel files directly, as it can only support CSV, AVRO, JSON, PARQUET and ORC formats.
Leverage Amazon Glue Data Catalog to analyze the data stored on Amazon S3 - The AWS Glue Data Catalog contains references to data that is used as sources and targets of your extract, transform, and load (ETL) jobs in AWS Glue. To create your data warehouse or data lake, you must catalog this data. The AWS Glue Data Catalog is an index to the location, schema, and runtime metrics of your data. The Amazon Glue Data Catalog itself cannot be used to analyze the data stored on Amazon S3.
AWS Glue Data Catalog: via - https://docs.aws.amazon.com/glue/latest/dg/catalog-and-crawler.html
References:
https://docs.aws.amazon.com/databrew/latest/dg/what-is.html
https://docs.aws.amazon.com/athena/latest/ug/what-is.html
https://docs.aws.amazon.com/databrew/latest/dg/supported-data-file-sources.html
https://docs.aws.amazon.com/athena/latest/ug/supported-serdes.html
https://docs.aws.amazon.com/glue/latest/dg/catalog-and-crawler.html
https://docs.aws.amazon.com/redshift/latest/dg/c-using-spectrum.html
https://docs.aws.amazon.com/redshift/latest/dg/copy-parameters-data-format.html
Question 5 Multiple Choice
The web development team at an IT company has about 200 TB of web-log data that is stored in an Amazon S3 bucket as raw text. Each log file is identified by a key of the type year-month-day_log_HHmmss.txt where HHmmss denotes the time the log file was created. The data engineering team has created an Amazon Athena table that links to the given S3 bucket. The team executes several queries every hour against a subset of the table's columns. The company wants a Hive-metastore compatible solution that costs less and requires less maintenance to support the ongoing analytics on this log data.
As an AWS Certified Data Engineer Associate, which of the following solutions would you combine to address these requirements? (Select three)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Change the log files to Apache Parquet format
Partition the data by using a key prefix of the form date=year-month-day/ to the S3 objects
Drop and recreate the table with the PARTITIONED BY clause. Load the partitions by executing the MSCK REPAIR TABLE statement
Amazon Athena is an interactive query service that makes it easy to analyze data stored in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
By partitioning your data, you can restrict the amount of data scanned by each query, thus improving performance and reducing cost. You can partition your data by any key. A common practice is to partition the data based on time, often leading to a multi-level partitioning scheme.
Athena can use Apache Hive style partitions, whose data paths contain key-value pairs connected by equal signs (for example, country=us/... or year=2021/month=01/day=26/...). Thus, the paths include both the names of the partition keys and the values that each path represents.
Athena can also use non-Hive style partitioning schemes. For example, CloudTrail logs and Kinesis Data Firehose delivery streams use separate path components for date parts such as data/2021/01/26/us/6fc7845e.json. For such non-Hive compatible data, you use ALTER TABLE ADD PARTITION to add the partitions manually.
Since the given use case needs a hive-metastore compatible solution, you can use a key prefix of the form date=year-month-day/ for partitioning data and use MSCK REPAIR TABLE statement to load the partitions.
Considerations and Limitations for Athena: 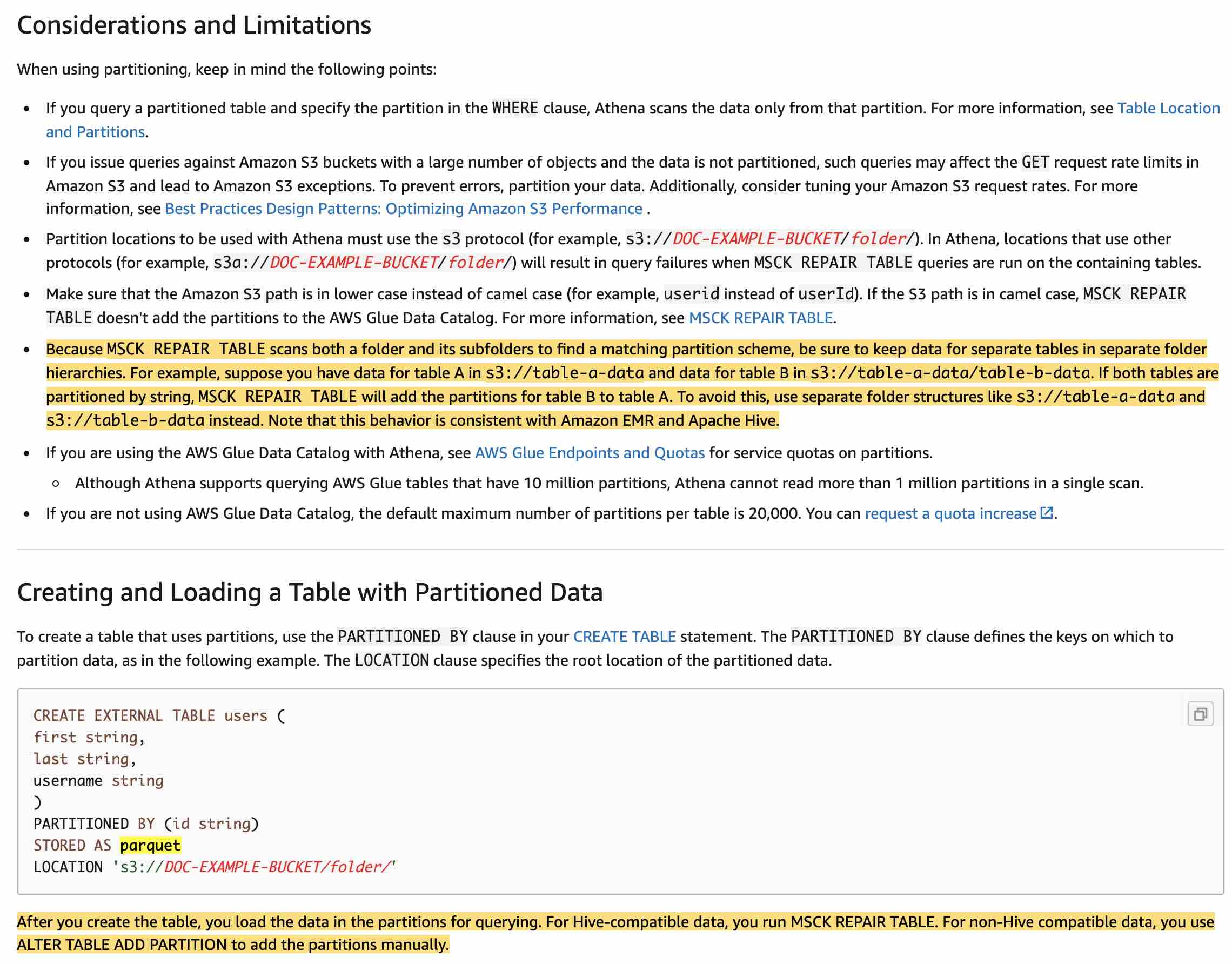 via - https://docs.aws.amazon.com/athena/latest/ug/partitions.html
via - https://docs.aws.amazon.com/athena/latest/ug/partitions.html
Avro is a row-based storage format whereas Parquet is a columnar-based storage format. Writing operations in Avro are more efficient than Parquet whereas Parquet is much better for analytical operations since the reads and querying are much more efficient than writing. Parquet is better suited for querying a subset of columns in a multi-column table whereas Avro is better suited for ETL operations where we need to query all the columns.
For the given use case, several queries are executed every hour, so Parquet is a better format than Avro.
Highly recommend the following blog on the top performance tuning tips for Amazon Athena: https://aws.amazon.com/blogs/big-data/top-10-performance-tuning-tips-for-amazon-athena/
Incorrect options:
Drop and recreate the table with the PARTITIONED BY clause. Load the partitions by executing the ALTER TABLE ADD PARTITION statement
Partition the data by using a key prefix of the form year-month-day/ to the S3 objects
Change the log files to Apache Avro format
Per the explanation provided above, these three options do not meet the requirements for the given use case, so these options are incorrect.
References:
https://www.clairvoyant.ai/blog/big-data-file-formats
https://docs.aws.amazon.com/athena/latest/ug/partitions.html
https://aws.amazon.com/blogs/big-data/top-10-performance-tuning-tips-for-amazon-athena/
https://docs.aws.amazon.com/athena/latest/ug/connect-to-data-source-hive.html
Explanation
Correct options:
Change the log files to Apache Parquet format
Partition the data by using a key prefix of the form date=year-month-day/ to the S3 objects
Drop and recreate the table with the PARTITIONED BY clause. Load the partitions by executing the MSCK REPAIR TABLE statement
Amazon Athena is an interactive query service that makes it easy to analyze data stored in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
By partitioning your data, you can restrict the amount of data scanned by each query, thus improving performance and reducing cost. You can partition your data by any key. A common practice is to partition the data based on time, often leading to a multi-level partitioning scheme.
Athena can use Apache Hive style partitions, whose data paths contain key-value pairs connected by equal signs (for example, country=us/... or year=2021/month=01/day=26/...). Thus, the paths include both the names of the partition keys and the values that each path represents.
Athena can also use non-Hive style partitioning schemes. For example, CloudTrail logs and Kinesis Data Firehose delivery streams use separate path components for date parts such as data/2021/01/26/us/6fc7845e.json. For such non-Hive compatible data, you use ALTER TABLE ADD PARTITION to add the partitions manually.
Since the given use case needs a hive-metastore compatible solution, you can use a key prefix of the form date=year-month-day/ for partitioning data and use MSCK REPAIR TABLE statement to load the partitions.
Considerations and Limitations for Athena: via - https://docs.aws.amazon.com/athena/latest/ug/partitions.html
Avro is a row-based storage format whereas Parquet is a columnar-based storage format. Writing operations in Avro are more efficient than Parquet whereas Parquet is much better for analytical operations since the reads and querying are much more efficient than writing. Parquet is better suited for querying a subset of columns in a multi-column table whereas Avro is better suited for ETL operations where we need to query all the columns.
For the given use case, several queries are executed every hour, so Parquet is a better format than Avro.
Highly recommend the following blog on the top performance tuning tips for Amazon Athena: https://aws.amazon.com/blogs/big-data/top-10-performance-tuning-tips-for-amazon-athena/
Incorrect options:
Drop and recreate the table with the PARTITIONED BY clause. Load the partitions by executing the ALTER TABLE ADD PARTITION statement
Partition the data by using a key prefix of the form year-month-day/ to the S3 objects
Change the log files to Apache Avro format
Per the explanation provided above, these three options do not meet the requirements for the given use case, so these options are incorrect.
References:
https://www.clairvoyant.ai/blog/big-data-file-formats
https://docs.aws.amazon.com/athena/latest/ug/partitions.html
https://aws.amazon.com/blogs/big-data/top-10-performance-tuning-tips-for-amazon-athena/
https://docs.aws.amazon.com/athena/latest/ug/connect-to-data-source-hive.html
Question 6 Single Choice
A data analytics job requires data from multiple sources like Amazon DynamoDB, Amazon RDS, and Amazon Redshift. The job is run on Amazon Athena.
Which of the following is the MOST cost-effective way to join data from these sources?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use Amazon Athena Federated Query to join the data from all data sources
If you have data in sources other than Amazon S3, you can use Athena Federated Query to query the data in place or build pipelines that extract data from multiple data sources and store them in Amazon S3. With Athena Federated Query, you can run SQL queries across data stored in relational, non-relational, object, and custom data sources.
Athena uses data source connectors that run on AWS Lambda to run federated queries. A data source connector is a piece of code that can translate between your target data source and Athena. You can think of a connector as an extension of Athena's query engine. Prebuilt Athena data source connectors exist for data sources like Amazon CloudWatch Logs, Amazon DynamoDB, Amazon DocumentDB, and Amazon RDS, and JDBC-compliant relational data sources such MySQL, and PostgreSQL
Incorrect options:
Copy the data from all the sources into a single S3 bucket. Use Athena queries on the saved S3 data - Copying data from all sources into Amazon S3 results in unnecessary storage costs on S3, therefore, this option is incorrect.
Develop an AWS Glue job using Apache Spark to join the data from all the sources - You can certainly leverage an AWS Glue job using Apache Spark to perform data analytics on these sources, however, this solution is not cost-effective.
Provision an EMR cluster to join the data from all the sources. Configure Spark for Athena to run the data analysis job - Provisioning and setting up an EMR cluster is time-consuming and it is also not cost-effective for the given use case.
References:
https://docs.aws.amazon.com/athena/latest/ug/connect-to-a-data-source.html
Explanation
Correct option:
Use Amazon Athena Federated Query to join the data from all data sources
If you have data in sources other than Amazon S3, you can use Athena Federated Query to query the data in place or build pipelines that extract data from multiple data sources and store them in Amazon S3. With Athena Federated Query, you can run SQL queries across data stored in relational, non-relational, object, and custom data sources.
Athena uses data source connectors that run on AWS Lambda to run federated queries. A data source connector is a piece of code that can translate between your target data source and Athena. You can think of a connector as an extension of Athena's query engine. Prebuilt Athena data source connectors exist for data sources like Amazon CloudWatch Logs, Amazon DynamoDB, Amazon DocumentDB, and Amazon RDS, and JDBC-compliant relational data sources such MySQL, and PostgreSQL
Incorrect options:
Copy the data from all the sources into a single S3 bucket. Use Athena queries on the saved S3 data - Copying data from all sources into Amazon S3 results in unnecessary storage costs on S3, therefore, this option is incorrect.
Develop an AWS Glue job using Apache Spark to join the data from all the sources - You can certainly leverage an AWS Glue job using Apache Spark to perform data analytics on these sources, however, this solution is not cost-effective.
Provision an EMR cluster to join the data from all the sources. Configure Spark for Athena to run the data analysis job - Provisioning and setting up an EMR cluster is time-consuming and it is also not cost-effective for the given use case.
References:
https://docs.aws.amazon.com/athena/latest/ug/connect-to-a-data-source.html
Question 7 Single Choice
A logistics company operates a near real-time inventory tracking system for vehicle depots across multiple geographic regions. Third-party vendors upload multiple logs of vehicle arrivals and departures in the form of small compressed files (less than 10 KB) to a central Amazon S3 bucket. The company needs to immediately process new uploads to keep a dashboard up to date. The dashboard must be refreshed near real-time to reflect the latest vehicle inventory across regions. A data engineer is tasked with designing a cost-effective, low-latency, and scalable solution that automates the processing and transformation of the uploaded data, enables ad hoc querying for business analysts, and supports visual reporting through dashboards.
Which solution will best meet these requirements in the most cost-effective and scalable manner?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use AWS Glue to process the uploaded S3 data files. Configure S3 Event Notifications to trigger AWS Lambda for near real-time orchestration. Use Amazon Athena for on-demand querying of transformed data stored in S3. Use Amazon QuickSight to visualize the results through an interactive dashboard
This solution combines AWS Glue for serverless ETL with S3 Event Notifications that trigger AWS Lambda, allowing near real-time ingestion and processing of small, compressed files immediately after they are uploaded. Amazon Athena provides cost-effective, on-demand SQL querying directly against S3 without the need for infrastructure provisioning. Amazon QuickSight connects to Athena for real-time dashboards, making this architecture scalable, serverless, and cost-efficient, especially given the small file sizes and frequency of uploads.
Incorrect options:
Use a provisioned Amazon EMR cluster running Spark to ingest and process the compressed files from S3. Trigger workflows using Amazon EventBridge rules and Step Functions. Store processed data in Amazon RDS and use Amazon Managed Grafana to visualize the vehicle inventory dashboards - While this solution uses EMR and Step Functions for data processing and orchestration, provisioning an EMR cluster introduces high fixed costs and overhead, which is not ideal for processing small 5–10 KB files. Additionally, Amazon RDS is not optimal for analytical workloads or schema evolution based on incoming log files. Grafana is suitable for operational metrics, but using it for tabular business dashboards increases complexity and may require additional plug-ins or integrations.
Use Amazon Kinesis Data Firehose to stream incoming vehicle log files from S3 and transform them on-the-fly with AWS Lambda. Store transformed data in Amazon Redshift. Use Redshift Query Editor V2 for ad hoc queries and Amazon QuickSight for reporting dashboards - Kinesis Firehose is designed for streaming high-throughput data, not for event-based ingestion of small files dropped periodically into S3. Triggering transformations through Lambda per file is inefficient in this context. Additionally, Redshift is a costlier option for variable, low-volume usage patterns, especially when Athena can directly query S3 at a fraction of the cost and without provisioning. This architecture introduces unnecessary complexity for the company’s use case.
Use Amazon OpenSearch Ingestion Pipelines to pull data from S3, process the log files, and index them into Amazon OpenSearch Service. Use OpenSearch Dashboards for real-time visualization. Enable scheduled queries with AWS Glue for historical analysis and reporting - OpenSearch is designed for full-text search and log analytics rather than structured, relational data analysis. While ingestion pipelines can process data from S3, the system is optimized for search-based analytics over large unstructured data (e.g., logs), not small files with structured schema. Also, OpenSearch Dashboards lacks deep business intelligence features like multi-dimensional KPIs, visual pivoting, or tabular reporting. This makes it suboptimal for the company’s analytics dashboard needs.
References:
https://docs.aws.amazon.com/athena/latest/ug/what-is.html
https://docs.aws.amazon.com/glue/latest/dg/starting-workflow-eventbridge.html
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-what-is-emr.html
Explanation
Correct option:
Use AWS Glue to process the uploaded S3 data files. Configure S3 Event Notifications to trigger AWS Lambda for near real-time orchestration. Use Amazon Athena for on-demand querying of transformed data stored in S3. Use Amazon QuickSight to visualize the results through an interactive dashboard
This solution combines AWS Glue for serverless ETL with S3 Event Notifications that trigger AWS Lambda, allowing near real-time ingestion and processing of small, compressed files immediately after they are uploaded. Amazon Athena provides cost-effective, on-demand SQL querying directly against S3 without the need for infrastructure provisioning. Amazon QuickSight connects to Athena for real-time dashboards, making this architecture scalable, serverless, and cost-efficient, especially given the small file sizes and frequency of uploads.
Incorrect options:
Use a provisioned Amazon EMR cluster running Spark to ingest and process the compressed files from S3. Trigger workflows using Amazon EventBridge rules and Step Functions. Store processed data in Amazon RDS and use Amazon Managed Grafana to visualize the vehicle inventory dashboards - While this solution uses EMR and Step Functions for data processing and orchestration, provisioning an EMR cluster introduces high fixed costs and overhead, which is not ideal for processing small 5–10 KB files. Additionally, Amazon RDS is not optimal for analytical workloads or schema evolution based on incoming log files. Grafana is suitable for operational metrics, but using it for tabular business dashboards increases complexity and may require additional plug-ins or integrations.
Use Amazon Kinesis Data Firehose to stream incoming vehicle log files from S3 and transform them on-the-fly with AWS Lambda. Store transformed data in Amazon Redshift. Use Redshift Query Editor V2 for ad hoc queries and Amazon QuickSight for reporting dashboards - Kinesis Firehose is designed for streaming high-throughput data, not for event-based ingestion of small files dropped periodically into S3. Triggering transformations through Lambda per file is inefficient in this context. Additionally, Redshift is a costlier option for variable, low-volume usage patterns, especially when Athena can directly query S3 at a fraction of the cost and without provisioning. This architecture introduces unnecessary complexity for the company’s use case.
Use Amazon OpenSearch Ingestion Pipelines to pull data from S3, process the log files, and index them into Amazon OpenSearch Service. Use OpenSearch Dashboards for real-time visualization. Enable scheduled queries with AWS Glue for historical analysis and reporting - OpenSearch is designed for full-text search and log analytics rather than structured, relational data analysis. While ingestion pipelines can process data from S3, the system is optimized for search-based analytics over large unstructured data (e.g., logs), not small files with structured schema. Also, OpenSearch Dashboards lacks deep business intelligence features like multi-dimensional KPIs, visual pivoting, or tabular reporting. This makes it suboptimal for the company’s analytics dashboard needs.
References:
https://docs.aws.amazon.com/athena/latest/ug/what-is.html
https://docs.aws.amazon.com/glue/latest/dg/starting-workflow-eventbridge.html
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-what-is-emr.html
Question 8 Multiple Choice
The data engineering team at a social media company wants to use Amazon CloudWatch alarms to automatically recover Amazon EC2 instances if they become impaired. The team has hired you to provide subject matter expertise.
Which of the following statements would you identify as CORRECT regarding this automatic recovery process? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
A recovered instance is identical to the original instance, including the instance ID, private IP addresses, Elastic IP addresses, and all instance metadata
If your instance has a public IPv4 address, it retains the public IPv4 address after recovery
You can create an Amazon CloudWatch alarm to automatically recover the Amazon EC2 instance if it becomes impaired due to an underlying hardware failure or a problem that requires AWS involvement to repair. Terminated instances cannot be recovered. A recovered instance is identical to the original instance, including the instance ID, private IP addresses, Elastic IP addresses, and all instance metadata. If the impaired instance is in a placement group, the recovered instance runs in the placement group. If your instance has a public IPv4 address, it retains the public IPv4 address after recovery. During instance recovery, the instance is migrated during an instance reboot, and any data that is in memory is lost.
Incorrect options:
Terminated Amazon EC2 instances can be recovered if they are configured at the launch of instance - This is incorrect as terminated instances cannot be recovered.
During instance recovery, the instance is migrated during an instance reboot, and any data that is in memory is retained - As mentioned above, during instance recovery, the instance is migrated during an instance reboot, and any data that is in memory is lost.
If your instance has a public IPv4 address, it does not retain the public IPv4 address after recovery - As mentioned above, if your instance has a public IPv4 address, it retains the public IPv4 address after recovery.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-recover.html
Explanation
Correct options:
A recovered instance is identical to the original instance, including the instance ID, private IP addresses, Elastic IP addresses, and all instance metadata
If your instance has a public IPv4 address, it retains the public IPv4 address after recovery
You can create an Amazon CloudWatch alarm to automatically recover the Amazon EC2 instance if it becomes impaired due to an underlying hardware failure or a problem that requires AWS involvement to repair. Terminated instances cannot be recovered. A recovered instance is identical to the original instance, including the instance ID, private IP addresses, Elastic IP addresses, and all instance metadata. If the impaired instance is in a placement group, the recovered instance runs in the placement group. If your instance has a public IPv4 address, it retains the public IPv4 address after recovery. During instance recovery, the instance is migrated during an instance reboot, and any data that is in memory is lost.
Incorrect options:
Terminated Amazon EC2 instances can be recovered if they are configured at the launch of instance - This is incorrect as terminated instances cannot be recovered.
During instance recovery, the instance is migrated during an instance reboot, and any data that is in memory is retained - As mentioned above, during instance recovery, the instance is migrated during an instance reboot, and any data that is in memory is lost.
If your instance has a public IPv4 address, it does not retain the public IPv4 address after recovery - As mentioned above, if your instance has a public IPv4 address, it retains the public IPv4 address after recovery.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-recover.html
Question 9 Single Choice
A company regularly extracts about 2 TB of data daily from various data sources - including MySQL, MSSQL Server, Oracle, Vertica, and Teradata Vantage. Some of these sources feature undefined or frequently changing data schemas. A data engineer is tasked with implementing a solution that can automatically detect the schema of these data sources and perform data extraction, transformation, and loading to an Amazon S3 bucket.
What solution would meet these needs while minimizing operational overhead?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Utilize AWS Glue to detect the schema including any ongoing changes. Extract, transform, and load the data into the S3 bucket by creating the ETL pipeline in Apache Spark
In many use cases, the data teams responsible for building the data pipeline don’t have any control of the source schema, and they need to build a solution to identify changes in the source schema in order to be able to build the process or automation around it.
For example, assume you’re receiving claim files from different external partners in the form of flat files, and you’ve built a solution to process claims based on these files. However, because these files were sent by external partners, you don’t have much control over the schema and data format. For example, columns such as customer_id and claim_id were changed to customerid and claimid by one partner, and another partner added new columns such as customer_age and earning and kept the rest of the columns the same. You need to identify such changes in advance so you can edit the ETL job to accommodate the changes, such as changing the column name or adding new columns to process the claims.
You can capture these schema changes in your data source using an AWS Glue crawler. You can use an AWS Glue crawler to extract the metadata from data in an S3 bucket. Then you can use an AWS Glue ETL job to extract the changes in the schema to the AWS Glue Data Catalog. You can develop the code for the AWS Glue ETL job using Apache Spark.
 via - https://aws.amazon.com/blogs/big-data/identify-source-schema-changes-using-aws-glue/
via - https://aws.amazon.com/blogs/big-data/identify-source-schema-changes-using-aws-glue/
 via - https://aws.amazon.com/blogs/big-data/identify-source-schema-changes-using-aws-glue/
via - https://aws.amazon.com/blogs/big-data/identify-source-schema-changes-using-aws-glue/
Incorrect options:
Utilize Amazon EMR to detect the schema including any ongoing changes. Extract, transform, and load the data into the S3 bucket by creating the ETL pipeline in Apache Spark - You will have to write significant code using Apache Spark in Amazon EMR to be able to detect the schema including any ongoing changes. So, this option is not the best fit for the given use case.
Utilize PySpark to detect the schema including any ongoing changes. Extract, transform, and load the data into the S3 bucket by creating the ETL pipeline in AWS Lambda - AWS Lambda has a maximum execution time (timeout) of 15 minutes which is not sufficient to run an ETL pipeline to process 2 TB of data daily. As such, AWS Lambda is not designed to run big data ETL pipelines. So, this option just acts as a distractor.
Utilize Redshift spectrum to detect the schema including any ongoing changes. Extract, transform, and load the data into the S3 bucket by creating a stored procedure in Amazon Redshift - You can define an Amazon Redshift stored procedure using the PostgreSQL procedural language PL/pgSQL to perform a set of SQL queries and logical operations. The procedure is stored in the database and available for any user with sufficient database privileges. You cannot use a stored procedure in Amazon Redshift to perform ETL operations for the given use case. This option just acts as a distractor.
References:
https://aws.amazon.com/blogs/big-data/identify-source-schema-changes-using-aws-glue/
https://docs.aws.amazon.com/glue/latest/dg/add-job.html
https://docs.aws.amazon.com/redshift/latest/dg/stored-procedure-overview.html
Explanation
Correct option:
Utilize AWS Glue to detect the schema including any ongoing changes. Extract, transform, and load the data into the S3 bucket by creating the ETL pipeline in Apache Spark
In many use cases, the data teams responsible for building the data pipeline don’t have any control of the source schema, and they need to build a solution to identify changes in the source schema in order to be able to build the process or automation around it.
For example, assume you’re receiving claim files from different external partners in the form of flat files, and you’ve built a solution to process claims based on these files. However, because these files were sent by external partners, you don’t have much control over the schema and data format. For example, columns such as customer_id and claim_id were changed to customerid and claimid by one partner, and another partner added new columns such as customer_age and earning and kept the rest of the columns the same. You need to identify such changes in advance so you can edit the ETL job to accommodate the changes, such as changing the column name or adding new columns to process the claims.
You can capture these schema changes in your data source using an AWS Glue crawler. You can use an AWS Glue crawler to extract the metadata from data in an S3 bucket. Then you can use an AWS Glue ETL job to extract the changes in the schema to the AWS Glue Data Catalog. You can develop the code for the AWS Glue ETL job using Apache Spark.
via - https://aws.amazon.com/blogs/big-data/identify-source-schema-changes-using-aws-glue/
via - https://aws.amazon.com/blogs/big-data/identify-source-schema-changes-using-aws-glue/
Incorrect options:
Utilize Amazon EMR to detect the schema including any ongoing changes. Extract, transform, and load the data into the S3 bucket by creating the ETL pipeline in Apache Spark - You will have to write significant code using Apache Spark in Amazon EMR to be able to detect the schema including any ongoing changes. So, this option is not the best fit for the given use case.
Utilize PySpark to detect the schema including any ongoing changes. Extract, transform, and load the data into the S3 bucket by creating the ETL pipeline in AWS Lambda - AWS Lambda has a maximum execution time (timeout) of 15 minutes which is not sufficient to run an ETL pipeline to process 2 TB of data daily. As such, AWS Lambda is not designed to run big data ETL pipelines. So, this option just acts as a distractor.
Utilize Redshift spectrum to detect the schema including any ongoing changes. Extract, transform, and load the data into the S3 bucket by creating a stored procedure in Amazon Redshift - You can define an Amazon Redshift stored procedure using the PostgreSQL procedural language PL/pgSQL to perform a set of SQL queries and logical operations. The procedure is stored in the database and available for any user with sufficient database privileges. You cannot use a stored procedure in Amazon Redshift to perform ETL operations for the given use case. This option just acts as a distractor.
References:
https://aws.amazon.com/blogs/big-data/identify-source-schema-changes-using-aws-glue/
https://docs.aws.amazon.com/glue/latest/dg/add-job.html
https://docs.aws.amazon.com/redshift/latest/dg/stored-procedure-overview.html
Question 10 Single Choice
A financial services company stores confidential data on an Amazon Simple Storage Service (S3) bucket. The compliance guidelines require that files be stored with server-side encryption. The encryption used must be Advanced Encryption Standard (AES-256) and the company does not want to manage the encryption keys.
What do you recommend?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Server-side encryption with Amazon S3 managed keys (SSE-S3)
Using Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3), each object is encrypted with a unique key employing strong multi-factor encryption. As an additional safeguard, it encrypts the key itself with a master key that it regularly rotates. Amazon S3 server-side encryption uses one of the strongest block ciphers available, 256-bit Advanced Encryption Standard (AES-256), to encrypt your data. There are no additional fees for using server-side encryption with Amazon S3-managed keys (SSE-S3). By default, Amazon S3 encrypts all objects using SSE-S3.
Incorrect options:
Server-side encryption with customer-provided keys (SSE-C) - You manage the encryption keys and Amazon S3 manages the encryption as it writes to disks and decryption when you access your objects.
Client Side Encryption - You can encrypt data client-side and upload the encrypted data to Amazon S3. In this case, you manage the encryption process, the encryption keys, and related tools.
Server-side encryption with AWS KMS keys (SSE-KMS) - Similar to SSE-S3 and also provides you with an audit trail of when your key was used and by whom. Additionally, you have the option to create and manage encryption keys yourself. Although SSE-KMS provides an option where AWS manages the encryption key on your behalf, however, this entails a usage fee for the KMS key. So this option is not the best fit for the given use case.
Reference:
https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingEncryption.html
Explanation
Correct option:
Server-side encryption with Amazon S3 managed keys (SSE-S3)
Using Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3), each object is encrypted with a unique key employing strong multi-factor encryption. As an additional safeguard, it encrypts the key itself with a master key that it regularly rotates. Amazon S3 server-side encryption uses one of the strongest block ciphers available, 256-bit Advanced Encryption Standard (AES-256), to encrypt your data. There are no additional fees for using server-side encryption with Amazon S3-managed keys (SSE-S3). By default, Amazon S3 encrypts all objects using SSE-S3.
Incorrect options:
Server-side encryption with customer-provided keys (SSE-C) - You manage the encryption keys and Amazon S3 manages the encryption as it writes to disks and decryption when you access your objects.
Client Side Encryption - You can encrypt data client-side and upload the encrypted data to Amazon S3. In this case, you manage the encryption process, the encryption keys, and related tools.
Server-side encryption with AWS KMS keys (SSE-KMS) - Similar to SSE-S3 and also provides you with an audit trail of when your key was used and by whom. Additionally, you have the option to create and manage encryption keys yourself. Although SSE-KMS provides an option where AWS manages the encryption key on your behalf, however, this entails a usage fee for the KMS key. So this option is not the best fit for the given use case.
Reference:
https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingEncryption.html


