
AWS Certified Data Engineer - Associate - (DEA-C01) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 11 Single Choice
A media agency stores its re-creatable assets on Amazon Simple Storage Service (Amazon S3) buckets. The assets are accessed by a large number of users for the first few days and the frequency of access falls down drastically after a week. Although the assets would be accessed occasionally after the first week, they must continue to be immediately accessible when required. The cost of maintaining all the assets on Amazon S3 storage is turning out to be very expensive and the agency is looking at reducing costs as much as possible.
Can you suggest a way to lower the storage costs while fulfilling the business requirements?
Explanation

Click "Show Answer" to see the explanation here
Correct option:
Configure a lifecycle policy to transition the objects to Amazon S3 One Zone-Infrequent Access (S3 One Zone-IA) after 30 days
Amazon S3 One Zone-IA is for data that is accessed less frequently but requires rapid access when needed. Unlike other S3 Storage Classes which store data in a minimum of three Availability Zones (AZs), Amazon S3 One Zone-IA stores data in a single Availability Zone (AZ) and costs 20% less than Amazon S3 Standard-IA. Amazon S3 One Zone-IA is ideal for customers who want a lower-cost option for infrequently accessed and re-creatable data but do not require the availability and resilience of Amazon S3 Standard or Amazon S3 Standard-IA. The minimum storage duration is 30 days before you can transition objects from Amazon S3 Standard to Amazon S3 One Zone-IA.
Amazon S3 One Zone-IA offers the same high durability, high throughput, and low latency of Amazon S3 Standard, with a low per GB storage price and per GB retrieval fee. S3 Storage Classes can be configured at the object level, and a single bucket can contain objects stored across Amazon S3 Standard, Amazon S3 Intelligent-Tiering, Amazon S3 Standard-IA, and Amazon S3 One Zone-IA. You can also use S3 Lifecycle policies to automatically transition objects between storage classes without any application changes.
Constraints for Lifecycle storage class transitions:  via - https://docs.aws.amazon.com/AmazonS3/latest/dev/lifecycle-transition-general-considerations.html
via - https://docs.aws.amazon.com/AmazonS3/latest/dev/lifecycle-transition-general-considerations.html
Supported Amazon S3 lifecycle transitions: 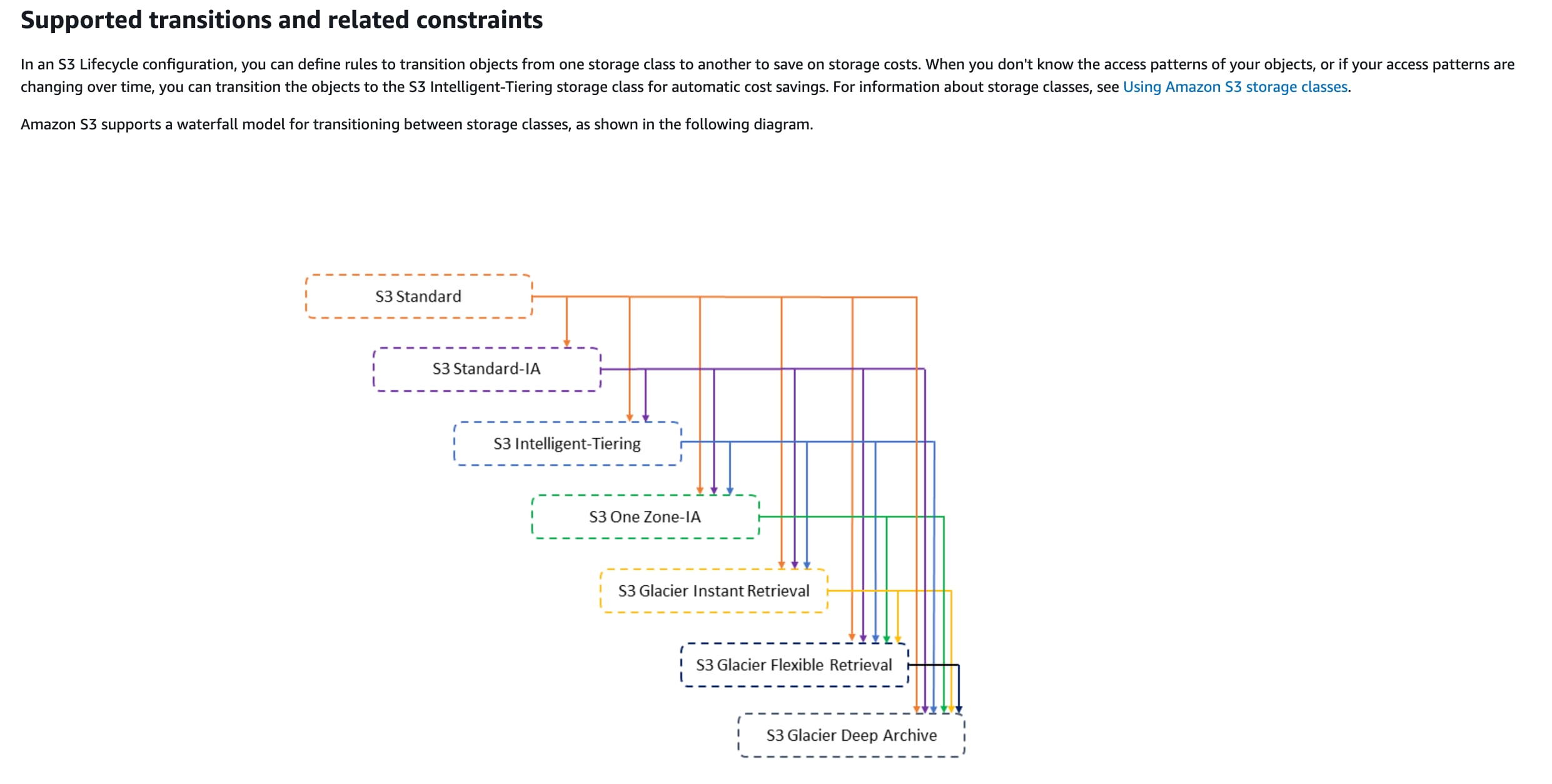 via - https://docs.aws.amazon.com/AmazonS3/latest/dev/lifecycle-transition-general-considerations.html
via - https://docs.aws.amazon.com/AmazonS3/latest/dev/lifecycle-transition-general-considerations.html
Incorrect options:
Configure a lifecycle policy to transition the objects to Amazon S3 Standard-Infrequent Access (S3 Standard-IA) after 7 days
Configure a lifecycle policy to transition the objects to Amazon S3 One Zone-Infrequent Access (S3 One Zone-IA) after 7 days
As mentioned earlier, the minimum storage duration is 30 days before you can transition objects from Amazon S3 Standard to Amazon S3 One Zone-IA or Amazon S3 Standard-IA, so both these options are added as distractors.
Configure a lifecycle policy to transition the objects to Amazon S3 Standard-Infrequent Access (S3 Standard-IA) after 30 days - Amazon S3 Standard-IA is for data that is accessed less frequently but requires rapid access when needed. S3 Standard-IA offers the high durability, high throughput, and low latency of Amazon S3 Standard, with a low per GB storage price and per GB retrieval fee. This combination of low cost and high performance makes Amazon S3 Standard-IA ideal for long-term storage, backups, and as a data store for disaster recovery files. However, it costs more than Amazon S3 One Zone-IA because of the redundant storage across Availability Zones (AZs). As the data is re-creatable, so you don't need to incur this additional cost.
References:
https://aws.amazon.com/s3/storage-classes/
https://docs.aws.amazon.com/AmazonS3/latest/dev/lifecycle-transition-general-considerations.html
Explanation
Correct option:
Configure a lifecycle policy to transition the objects to Amazon S3 One Zone-Infrequent Access (S3 One Zone-IA) after 30 days
Amazon S3 One Zone-IA is for data that is accessed less frequently but requires rapid access when needed. Unlike other S3 Storage Classes which store data in a minimum of three Availability Zones (AZs), Amazon S3 One Zone-IA stores data in a single Availability Zone (AZ) and costs 20% less than Amazon S3 Standard-IA. Amazon S3 One Zone-IA is ideal for customers who want a lower-cost option for infrequently accessed and re-creatable data but do not require the availability and resilience of Amazon S3 Standard or Amazon S3 Standard-IA. The minimum storage duration is 30 days before you can transition objects from Amazon S3 Standard to Amazon S3 One Zone-IA.
Amazon S3 One Zone-IA offers the same high durability, high throughput, and low latency of Amazon S3 Standard, with a low per GB storage price and per GB retrieval fee. S3 Storage Classes can be configured at the object level, and a single bucket can contain objects stored across Amazon S3 Standard, Amazon S3 Intelligent-Tiering, Amazon S3 Standard-IA, and Amazon S3 One Zone-IA. You can also use S3 Lifecycle policies to automatically transition objects between storage classes without any application changes.
Constraints for Lifecycle storage class transitions: via - https://docs.aws.amazon.com/AmazonS3/latest/dev/lifecycle-transition-general-considerations.html
Supported Amazon S3 lifecycle transitions: via - https://docs.aws.amazon.com/AmazonS3/latest/dev/lifecycle-transition-general-considerations.html
Incorrect options:
Configure a lifecycle policy to transition the objects to Amazon S3 Standard-Infrequent Access (S3 Standard-IA) after 7 days
Configure a lifecycle policy to transition the objects to Amazon S3 One Zone-Infrequent Access (S3 One Zone-IA) after 7 days
As mentioned earlier, the minimum storage duration is 30 days before you can transition objects from Amazon S3 Standard to Amazon S3 One Zone-IA or Amazon S3 Standard-IA, so both these options are added as distractors.
Configure a lifecycle policy to transition the objects to Amazon S3 Standard-Infrequent Access (S3 Standard-IA) after 30 days - Amazon S3 Standard-IA is for data that is accessed less frequently but requires rapid access when needed. S3 Standard-IA offers the high durability, high throughput, and low latency of Amazon S3 Standard, with a low per GB storage price and per GB retrieval fee. This combination of low cost and high performance makes Amazon S3 Standard-IA ideal for long-term storage, backups, and as a data store for disaster recovery files. However, it costs more than Amazon S3 One Zone-IA because of the redundant storage across Availability Zones (AZs). As the data is re-creatable, so you don't need to incur this additional cost.
References:
https://aws.amazon.com/s3/storage-classes/
https://docs.aws.amazon.com/AmazonS3/latest/dev/lifecycle-transition-general-considerations.html
Question 12 Single Choice
An IT company wants to process IoT data from the field devices of an agricultural sciences company. The data engineering team at the company is designing a new database infrastructure for capturing this IoT data. The database should be resilient with minimal operational overhead and require the least development effort. The application includes a device tracking system that stores the GPS data for all devices. Real-time IoT data, as well as metadata lookups, must be performed with high throughput and microsecond latency.
Which of the following options would you recommend as the MOST efficient solution for these requirements?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use DynamoDB as the database with DynamoDB Accelerator (DAX)
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It's a fully managed, multi-region, multi-master, durable NoSQL database with built-in security, backup and restore, and in-memory caching for internet-scale applications.
Amazon DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a 10x performance improvement – from milliseconds to microseconds – even at millions of requests per second. DAX does all the heavy lifting required to add in-memory acceleration to your DynamoDB tables, without requiring developers to manage cache invalidation, data population, or cluster management.
DAX Overview: 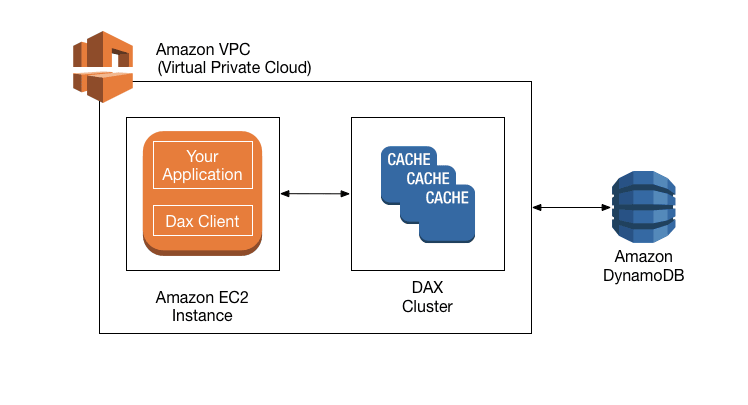 via - https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DAX.concepts.html
via - https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DAX.concepts.html
Typically, DynamoDB response times can be measured in single-digit milliseconds. Certain use cases require response times in microseconds. For these use cases, DynamoDB Accelerator (DAX) delivers fast response times for accessing eventually consistent data. Additionally, DAX reduces operational and application complexity by providing a managed service that is API-compatible with DynamoDB. Therefore, it requires only minimal functional changes to use with an existing application. Therefore, this is the correct option.
 via - https://docs.amazonaws.cn/en_us/amazondynamodb/latest/developerguide/DAX.html
via - https://docs.amazonaws.cn/en_us/amazondynamodb/latest/developerguide/DAX.html
Incorrect options:
Use RDS MySQL as the database with ElastiCache
The given use-case deals with IoT data which has a variable underlying data structure by its nature. Relational databases are not a good fit for capturing such data. Also integrating ElastiCache with RDS involves custom code at the application level as well as provisioning and maintaining a separate ElastiCache cluster. This operational overhead goes against the specified requirements.
Use Aurora MySQL as the database with Aurora cluster cache
The given use-case deals with IoT data which has a variable underlying data structure by its nature. Relational databases are not a good fit for capturing such data. In addition, the main benefit of the cluster cache feature is to improve the performance of the new primary/writer instance after failover occurs. So Aurora with cluster cache is not the right fit to handle IoT data with microsecond latency.
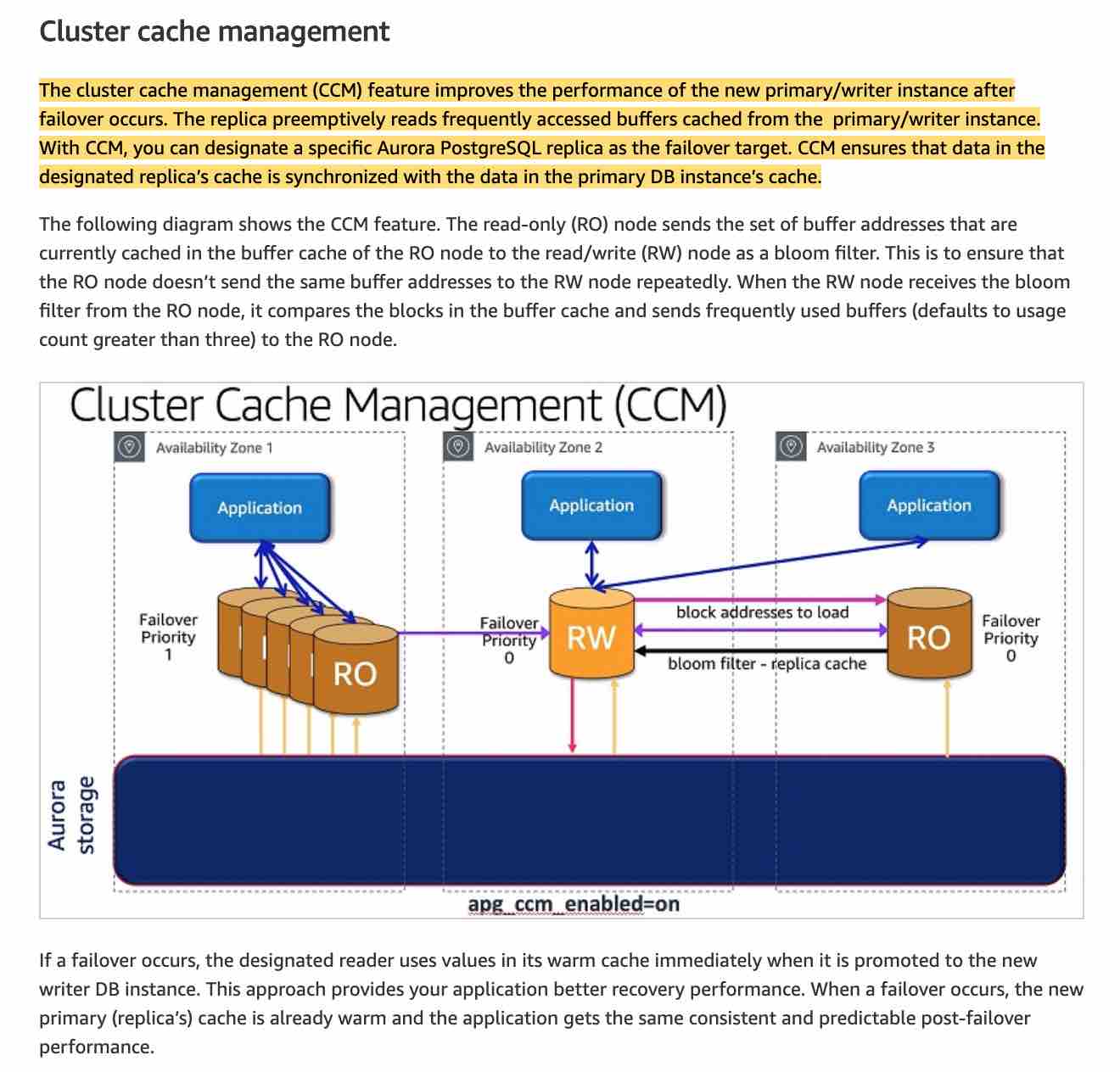 via - https://aws.amazon.com/blogs/database/introduction-to-aurora-postgresql-cluster-cache-management/
via - https://aws.amazon.com/blogs/database/introduction-to-aurora-postgresql-cluster-cache-management/
Use DocumentDB as the database with API Gateway
Amazon DocumentDB (with MongoDB compatibility) is a fast, reliable, and fully managed database service. Amazon DocumentDB makes it easy to set up, operate, and scale MongoDB-compatible databases in the cloud.
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. APIs act as the front door for applications to access data, business logic, or functionality from your backend services. Using API Gateway, you can create RESTful APIs and WebSocket APIs that enable real-time two-way communication applications.
This option has been added as a distractor as API Gateway cannot be used to optimize the database infrastructure for the given use case.
How API Gateway Works: 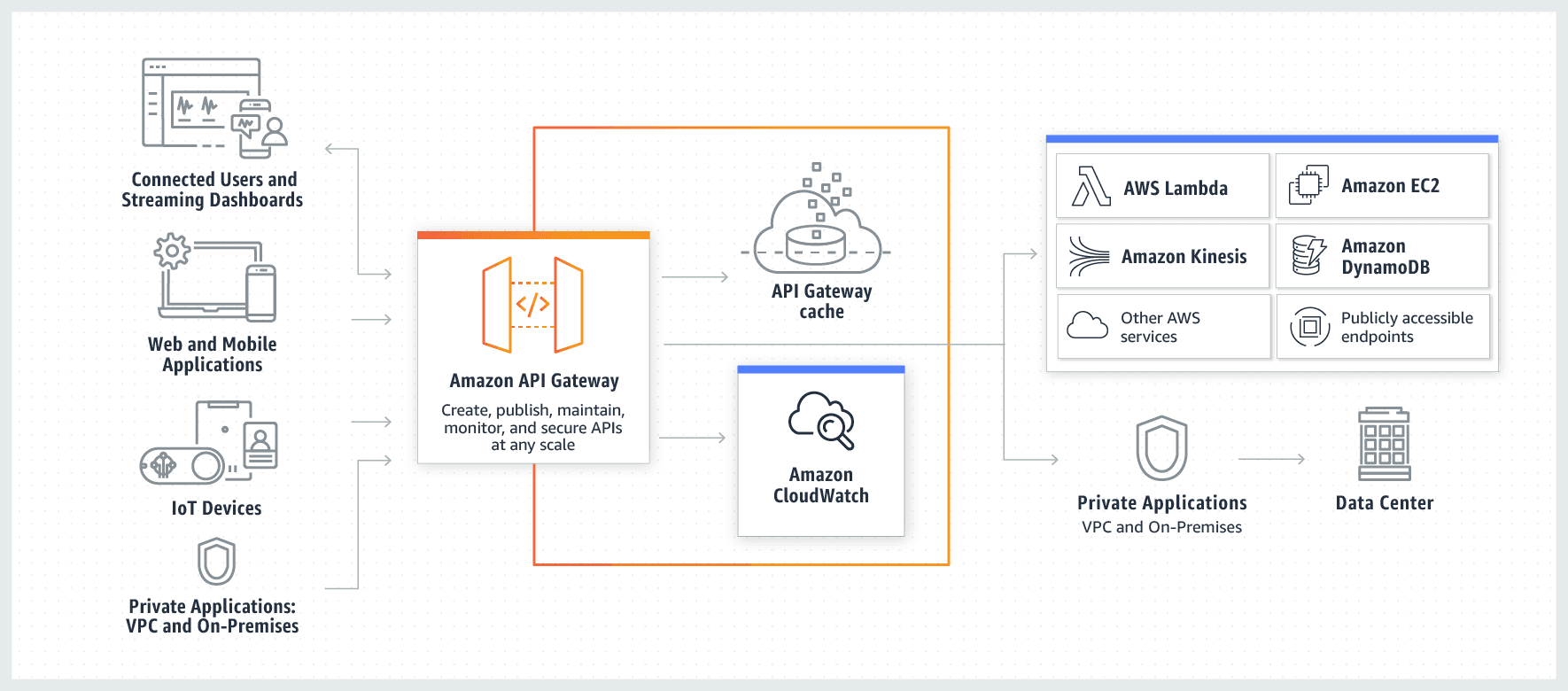 via - https://aws.amazon.com/api-gateway/
via - https://aws.amazon.com/api-gateway/
References:
https://docs.amazonaws.cn/en_us/amazondynamodb/latest/developerguide/DAX.html
https://aws.amazon.com/blogs/database/introduction-to-aurora-postgresql-cluster-cache-management/
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DAX.concepts.html
Explanation
Correct option:
Use DynamoDB as the database with DynamoDB Accelerator (DAX)
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It's a fully managed, multi-region, multi-master, durable NoSQL database with built-in security, backup and restore, and in-memory caching for internet-scale applications.
Amazon DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a 10x performance improvement – from milliseconds to microseconds – even at millions of requests per second. DAX does all the heavy lifting required to add in-memory acceleration to your DynamoDB tables, without requiring developers to manage cache invalidation, data population, or cluster management.
DAX Overview: via - https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DAX.concepts.html
Typically, DynamoDB response times can be measured in single-digit milliseconds. Certain use cases require response times in microseconds. For these use cases, DynamoDB Accelerator (DAX) delivers fast response times for accessing eventually consistent data. Additionally, DAX reduces operational and application complexity by providing a managed service that is API-compatible with DynamoDB. Therefore, it requires only minimal functional changes to use with an existing application. Therefore, this is the correct option.
via - https://docs.amazonaws.cn/en_us/amazondynamodb/latest/developerguide/DAX.html
Incorrect options:
Use RDS MySQL as the database with ElastiCache
The given use-case deals with IoT data which has a variable underlying data structure by its nature. Relational databases are not a good fit for capturing such data. Also integrating ElastiCache with RDS involves custom code at the application level as well as provisioning and maintaining a separate ElastiCache cluster. This operational overhead goes against the specified requirements.
Use Aurora MySQL as the database with Aurora cluster cache
The given use-case deals with IoT data which has a variable underlying data structure by its nature. Relational databases are not a good fit for capturing such data. In addition, the main benefit of the cluster cache feature is to improve the performance of the new primary/writer instance after failover occurs. So Aurora with cluster cache is not the right fit to handle IoT data with microsecond latency.
via - https://aws.amazon.com/blogs/database/introduction-to-aurora-postgresql-cluster-cache-management/
Use DocumentDB as the database with API Gateway
Amazon DocumentDB (with MongoDB compatibility) is a fast, reliable, and fully managed database service. Amazon DocumentDB makes it easy to set up, operate, and scale MongoDB-compatible databases in the cloud.
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. APIs act as the front door for applications to access data, business logic, or functionality from your backend services. Using API Gateway, you can create RESTful APIs and WebSocket APIs that enable real-time two-way communication applications.
This option has been added as a distractor as API Gateway cannot be used to optimize the database infrastructure for the given use case.
How API Gateway Works: via - https://aws.amazon.com/api-gateway/
References:
https://docs.amazonaws.cn/en_us/amazondynamodb/latest/developerguide/DAX.html
https://aws.amazon.com/blogs/database/introduction-to-aurora-postgresql-cluster-cache-management/
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DAX.concepts.html
Question 13 Single Choice
A nightly cron job generates a customer data file of 1 GB size in .xls format and stores it in an Amazon S3 bucket. A data engineer is tasked with concatenating the column in the file that contains customer first names with the column that contains customer last names and then calculating the number of distinct customers in the file.
Which of the following will you suggest to address this requirement with the least operational overhead?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Leverage AWS Glue DataBrew to create a recipe that uses the COUNT_DISTINCT aggregate function to determine the number of distinct customers
AWS Glue DataBrew is a visual data preparation tool that enables users to clean and normalize data without writing any code. Using DataBrew helps reduce the time it takes to prepare data for analytics and machine learning (ML) by up to 80 percent, compared to custom-developed data preparation. You can choose from over 250 ready-made transformations to automate data preparation tasks, such as filtering anomalies, converting data to standard formats, and correcting invalid values.
To prepare the data, you can choose from more than 250 point-and-click transformations. These include removing nulls, replacing missing values, fixing schema inconsistencies, creating columns based on functions, and many more. You can also use transformations to apply natural language processing (NLP) techniques to split sentences into phrases. Immediate previews show a portion of your data before and after transformation, so you can modify your recipe before applying it to the entire dataset.
For the given use case, you can use the COUNT_DISTINCT aggregate function to determine the number of distinct customers
COUNT_DISTINCT - Returns the total number of distinct values from the selected source columns in a new column. Empty and null values are ignored.
 via - https://docs.aws.amazon.com/databrew/latest/dg/recipe-actions.functions.COUNT_DISTINCT.html
via - https://docs.aws.amazon.com/databrew/latest/dg/recipe-actions.functions.COUNT_DISTINCT.html
Incorrect options:
Query the customer data file in .xls format stored in Amazon S3 using SQL commands via Amazon Athena - Athena supports creating tables and querying data from CSV, TSV, custom-delimited, and JSON formats; data from Hadoop-related formats: ORC, Apache Avro and Parquet; logs from Logstash, AWS CloudTrail logs, and Apache WebServer logs. You cannot query files stored in Amazon S3 in the .xls format via Amazon Athena.
Develop an Apache Spark job in an AWS Glue notebook to read the file in Amazon S3 and determine the number of distinct customers - It is certainly possible to develop an Apache Spark job in an AWS Glue notebook to read the file in Amazon S3 and determine the number of distinct customers by using countDistinct Function. However, this option involves significant operational overhead to develop the script, so it is ruled out.
Leverage AWS Glue DataBrew to create a recipe that uses the FLAG_DUPLICATE_ROWS function to determine the number of distinct customers
FLAG_DUPLICATE_ROWS - Returns a new column with a specified value in each row that indicates whether that row is an exact match of an earlier row in the dataset. When matches are found, they are flagged as duplicates. The initial occurrence is not flagged, because it doesn't match an earlier row. So, this option is not relevant for the given use case.
References:
https://docs.aws.amazon.com/databrew/latest/dg/what-is.html
https://docs.aws.amazon.com/databrew/latest/dg/recipe-actions.functions.COUNT_DISTINCT.html
https://docs.aws.amazon.com/databrew/latest/dg/recipe-actions.FLAG_DUPLICATE_ROWS.html
https://docs.aws.amazon.com/athena/latest/ug/supported-serdes.html
Explanation
Correct option:
Leverage AWS Glue DataBrew to create a recipe that uses the COUNT_DISTINCT aggregate function to determine the number of distinct customers
AWS Glue DataBrew is a visual data preparation tool that enables users to clean and normalize data without writing any code. Using DataBrew helps reduce the time it takes to prepare data for analytics and machine learning (ML) by up to 80 percent, compared to custom-developed data preparation. You can choose from over 250 ready-made transformations to automate data preparation tasks, such as filtering anomalies, converting data to standard formats, and correcting invalid values.
To prepare the data, you can choose from more than 250 point-and-click transformations. These include removing nulls, replacing missing values, fixing schema inconsistencies, creating columns based on functions, and many more. You can also use transformations to apply natural language processing (NLP) techniques to split sentences into phrases. Immediate previews show a portion of your data before and after transformation, so you can modify your recipe before applying it to the entire dataset.
For the given use case, you can use the COUNT_DISTINCT aggregate function to determine the number of distinct customers
COUNT_DISTINCT - Returns the total number of distinct values from the selected source columns in a new column. Empty and null values are ignored.
via - https://docs.aws.amazon.com/databrew/latest/dg/recipe-actions.functions.COUNT_DISTINCT.html
Incorrect options:
Query the customer data file in .xls format stored in Amazon S3 using SQL commands via Amazon Athena - Athena supports creating tables and querying data from CSV, TSV, custom-delimited, and JSON formats; data from Hadoop-related formats: ORC, Apache Avro and Parquet; logs from Logstash, AWS CloudTrail logs, and Apache WebServer logs. You cannot query files stored in Amazon S3 in the .xls format via Amazon Athena.
Develop an Apache Spark job in an AWS Glue notebook to read the file in Amazon S3 and determine the number of distinct customers - It is certainly possible to develop an Apache Spark job in an AWS Glue notebook to read the file in Amazon S3 and determine the number of distinct customers by using countDistinct Function. However, this option involves significant operational overhead to develop the script, so it is ruled out.
Leverage AWS Glue DataBrew to create a recipe that uses the FLAG_DUPLICATE_ROWS function to determine the number of distinct customers
FLAG_DUPLICATE_ROWS - Returns a new column with a specified value in each row that indicates whether that row is an exact match of an earlier row in the dataset. When matches are found, they are flagged as duplicates. The initial occurrence is not flagged, because it doesn't match an earlier row. So, this option is not relevant for the given use case.
References:
https://docs.aws.amazon.com/databrew/latest/dg/what-is.html
https://docs.aws.amazon.com/databrew/latest/dg/recipe-actions.functions.COUNT_DISTINCT.html
https://docs.aws.amazon.com/databrew/latest/dg/recipe-actions.FLAG_DUPLICATE_ROWS.html
https://docs.aws.amazon.com/athena/latest/ug/supported-serdes.html
Question 14 Single Choice
You are a data engineer at an IT company that recently moved its production application to AWS and migrated data from PostgreSQL to AWS DynamoDB. You are adding new tables to AWS DynamoDB and need to allow your application to query your data by the primary key and an alternate key. This option must be added at the outset when you are first creating tables, otherwise, changes cannot be done once the table is created.
Which of the following actions would you suggest?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Create a Local Secondary Index (LSI)
Some applications only need to query data using the base table's primary key; however, there may be situations where an alternate sort key would be helpful. To give your application a choice of sort keys, you can create one or more local secondary indexes on a table and issue Query or Scan requests against these indexes.
Local secondary indexes are created at the same time that you create a table. You cannot add a local secondary index to an existing table, nor can you delete any local secondary indexes that currently exist.
Differences between GSI and LSI:  via - https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/SecondaryIndexes.html
via - https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/SecondaryIndexes.html
Incorrect options:
Create DynamoDB Streams - DynamoDB Streams captures a time-ordered sequence of item-level modifications in any DynamoDB table and stores this information in a log for up to 24 hours. Applications can access this log and view the data items as they appeared before and after they were modified, in near real-time. This option is not relevant to the given use case.
Create a Global Secondary Index (GSI) - GSI is an index with a partition key and a sort key that can be different from those on the base table. Global secondary indexes can be created at the same time that you create a table. You can also add a new global secondary index to an existing table, or delete an existing global secondary index.
Migrate away from DynamoDB - Migrating to another database that is not NoSQL may cause you to make changes that require substantial code development.
Reference:
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/SecondaryIndexes.html
Explanation
Correct option:
Create a Local Secondary Index (LSI)
Some applications only need to query data using the base table's primary key; however, there may be situations where an alternate sort key would be helpful. To give your application a choice of sort keys, you can create one or more local secondary indexes on a table and issue Query or Scan requests against these indexes.
Local secondary indexes are created at the same time that you create a table. You cannot add a local secondary index to an existing table, nor can you delete any local secondary indexes that currently exist.
Differences between GSI and LSI: via - https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/SecondaryIndexes.html
Incorrect options:
Create DynamoDB Streams - DynamoDB Streams captures a time-ordered sequence of item-level modifications in any DynamoDB table and stores this information in a log for up to 24 hours. Applications can access this log and view the data items as they appeared before and after they were modified, in near real-time. This option is not relevant to the given use case.
Create a Global Secondary Index (GSI) - GSI is an index with a partition key and a sort key that can be different from those on the base table. Global secondary indexes can be created at the same time that you create a table. You can also add a new global secondary index to an existing table, or delete an existing global secondary index.
Migrate away from DynamoDB - Migrating to another database that is not NoSQL may cause you to make changes that require substantial code development.
Reference:
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/SecondaryIndexes.html
Question 15 Single Choice
A data engineer has been tasked to optimize Amazon Athena queries that are underperforming. Upon analysis, the data engineer realized that the files queried by Athena were not compressed and just stored as .csv files. The data engineer also noticed that users perform most queries by selecting a specific column.
What do you recommend to improve the query performance?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Change the data format from comma-separated text files to Apache Parquet. Compress the files using Snappy compression
Amazon Athena query performance improves if you convert your data into open-source columnar formats, such as Apache parquet or ORC.
Why choose Columnar storage formats:  via - https://docs.aws.amazon.com/athena/latest/ug/columnar-storage.html
via - https://docs.aws.amazon.com/athena/latest/ug/columnar-storage.html
To convert your existing raw data from other storage formats to Parquet or ORC, you can run CREATE TABLE AS SELECT (CTAS) queries in Athena and specify a data storage format as Parquet or ORC, or use the AWS Glue Crawler.
Compressing your data can speed up your queries significantly. The smaller data sizes reduce the data scanned from Amazon S3, resulting in lower costs of running queries. It also reduces the network traffic from Amazon S3 to Athena. Athena supports a variety of compression formats, including common formats like gzip, Snappy, and zstd.
SNAPPY – Compression algorithm that is part of the Lempel-Ziv 77 (LZ7) family. Snappy focuses on high compression and decompression speed rather than the maximum compression of data. This will improve the performance of the queries for the current use case.
Incorrect options:
Change the data format from comma-separated text files to JSON format. Apply Snappy compression - JSON is not a columnar format and is not as well optimized as Apache Parquet for Athena queries.
Change the data format from comma-separated text files to ORC - ORC is also a columnar format and provides an efficient way to store Hive data. ORC files are often smaller than Parquet files, and ORC indexes can make querying faster. We still need compression to speed up the Athena queries, so this option is not the best fit.
Change the data format from comma-separated text files to ZIP format - The ZIP file format is not supported by Athena.
References:
https://docs.aws.amazon.com/athena/latest/ug/performance-tuning.html
https://docs.aws.amazon.com/athena/latest/ug/compression-formats.html
Explanation
Correct option:
Change the data format from comma-separated text files to Apache Parquet. Compress the files using Snappy compression
Amazon Athena query performance improves if you convert your data into open-source columnar formats, such as Apache parquet or ORC.
Why choose Columnar storage formats: via - https://docs.aws.amazon.com/athena/latest/ug/columnar-storage.html
To convert your existing raw data from other storage formats to Parquet or ORC, you can run CREATE TABLE AS SELECT (CTAS) queries in Athena and specify a data storage format as Parquet or ORC, or use the AWS Glue Crawler.
Compressing your data can speed up your queries significantly. The smaller data sizes reduce the data scanned from Amazon S3, resulting in lower costs of running queries. It also reduces the network traffic from Amazon S3 to Athena. Athena supports a variety of compression formats, including common formats like gzip, Snappy, and zstd.
SNAPPY – Compression algorithm that is part of the Lempel-Ziv 77 (LZ7) family. Snappy focuses on high compression and decompression speed rather than the maximum compression of data. This will improve the performance of the queries for the current use case.
Incorrect options:
Change the data format from comma-separated text files to JSON format. Apply Snappy compression - JSON is not a columnar format and is not as well optimized as Apache Parquet for Athena queries.
Change the data format from comma-separated text files to ORC - ORC is also a columnar format and provides an efficient way to store Hive data. ORC files are often smaller than Parquet files, and ORC indexes can make querying faster. We still need compression to speed up the Athena queries, so this option is not the best fit.
Change the data format from comma-separated text files to ZIP format - The ZIP file format is not supported by Athena.
References:
https://docs.aws.amazon.com/athena/latest/ug/performance-tuning.html
https://docs.aws.amazon.com/athena/latest/ug/compression-formats.html
Question 16 Single Choice
A retail company is migrating its infrastructure from the on-premises data center to AWS Cloud. The company wants to deploy its two-tier application with the EC2 instance-based web servers in a public subnet and PostgreSQL RDS-based database layer in a private subnet. The company wants to ensure that the database access credentials used by the web servers are handled securely as well as these credentials are changed every 90 days in an automated way using a built-in integration.
Which of the following solutions would you recommend for the given use case?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use AWS Secrets Manager to store the database access credentials with the rotation interval configured to 90 days. Set up the application web servers to retrieve the credentials from the Secrets Manager
AWS Secrets Manager enables you to easily rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle. Users and applications retrieve secrets with a call to Secrets Manager APIs, eliminating the need to hardcode sensitive information in plain text. Secrets Manager offers secret rotation with built-in integration for Amazon RDS, Amazon Redshift, and Amazon DocumentDB.
Benefits of Secrets Manager:  via - https://aws.amazon.com/secrets-manager/
via - https://aws.amazon.com/secrets-manager/
Incorrect options:
Store the database access credentials as the EC2 instance user data. Configure the application web servers to retrieve the credentials from the user data while bootstrapping. Write custom code to change the database access credentials stored in the user data after 90 days - The given use-case mandates that the database secrets are rotated every 90 days using a built-in integration in an automated way. Writing custom code to change these credentials after 90 days violates this key requirement.
Store the database access credentials in an SSE-S3 encrypted text file on S3. Configure the application web servers to retrieve the credentials from S3 on system boot. Write custom code to change the database access credentials stored on the encrypted file after 90 days
Store the database access credentials in a KMS-encrypted text file on EFS. Configure the application web servers to retrieve the credentials from EFS on system boot. Write custom code to change the database access credentials stored on the encrypted file after 90 days
A key requirement of the use case is to automate the database access secrets rotation every 90 days using a built-in integration. Both these options involve writing custom code to change the database access credentials after 90 days. In addition, storing database access credentials in an external file (even if encrypted) is not a best practice, so both these options are incorrect.
Reference:
Explanation
Correct option:
Use AWS Secrets Manager to store the database access credentials with the rotation interval configured to 90 days. Set up the application web servers to retrieve the credentials from the Secrets Manager
AWS Secrets Manager enables you to easily rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle. Users and applications retrieve secrets with a call to Secrets Manager APIs, eliminating the need to hardcode sensitive information in plain text. Secrets Manager offers secret rotation with built-in integration for Amazon RDS, Amazon Redshift, and Amazon DocumentDB.
Benefits of Secrets Manager: via - https://aws.amazon.com/secrets-manager/
Incorrect options:
Store the database access credentials as the EC2 instance user data. Configure the application web servers to retrieve the credentials from the user data while bootstrapping. Write custom code to change the database access credentials stored in the user data after 90 days - The given use-case mandates that the database secrets are rotated every 90 days using a built-in integration in an automated way. Writing custom code to change these credentials after 90 days violates this key requirement.
Store the database access credentials in an SSE-S3 encrypted text file on S3. Configure the application web servers to retrieve the credentials from S3 on system boot. Write custom code to change the database access credentials stored on the encrypted file after 90 days
Store the database access credentials in a KMS-encrypted text file on EFS. Configure the application web servers to retrieve the credentials from EFS on system boot. Write custom code to change the database access credentials stored on the encrypted file after 90 days
A key requirement of the use case is to automate the database access secrets rotation every 90 days using a built-in integration. Both these options involve writing custom code to change the database access credentials after 90 days. In addition, storing database access credentials in an external file (even if encrypted) is not a best practice, so both these options are incorrect.
Reference:
Question 17 Single Choice
An Internet of Things (IoT) company would like to have a streaming system that performs real-time analytics on the ingested IoT data. Once the analytics is done, the company would like to send notifications back to the mobile applications of the IoT device owners.
Which of the following AWS technologies would you recommend to send these notifications to the mobile applications?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Amazon Kinesis Data Streams with Amazon Simple Notification Service (Amazon SNS)
Amazon Kinesis Data Streams makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information. Amazon Kinesis Data Streams offers key capabilities to cost-effectively process streaming data at any scale, along with the flexibility to choose the tools that best suit the requirements of your application.
With Amazon Kinesis Data Streams, you can ingest real-time data such as video, audio, application logs, website clickstreams, and IoT telemetry data for machine learning, analytics, and other applications. Amazon Kinesis Data Streams enables you to process and analyze data as it arrives and responds instantly instead of having to wait until all your data is collected before the processing can begin.
Amazon Kinesis Data Streams will be great for event streaming from IoT devices, but not for sending notifications as it doesn't have such a feature.
Amazon Simple Notification Service (Amazon SNS) is a highly available, durable, secure, fully managed pub/sub messaging service that enables you to decouple microservices, distributed systems, and serverless applications. Amazon SNS provides topics for high-throughput, push-based, many-to-many messaging. Amazon SNS is a notification service and will be perfect for this use case.
Streaming data with Amazon Kinesis Data Streams and using Amazon SNS to send the response notifications is the optimal solution for the given scenario.
Incorrect options:
Amazon Simple Queue Service (Amazon SQS) with Amazon Simple Notification Service (Amazon SNS) - Amazon Simple Queue Service (SQS) is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications. Amazon SQS eliminates the complexity and overhead associated with managing and operating message-oriented middleware and empowers developers to focus on differentiating work. Using SQS, you can send, store, and receive messages between software components at any volume, without losing messages or requiring other services to be available. Kinesis is better for streaming data since queues aren't meant for real-time streaming of data.
Amazon Kinesis Data Streams with Amazon Simple Email Service (Amazon SES) - Amazon Simple Email Service (Amazon SES) is a cloud-based email-sending service designed to help digital marketers and application developers send marketing, notification, and transactional emails. It is a reliable, cost-effective service for businesses of all sizes that use email to keep in contact with their customers. It is an email service and not a notification service as is the requirement in the current use case.
Amazon Kinesis Data Streams with Amazon Simple Queue Service (Amazon SQS) - As explained above, Amazon Kinesis Data Streams works well for streaming real-time data. Amazon SQS is a queuing service that helps decouple system architecture by offering flexibility and ease of maintenance. It cannot send notifications.
References:
Explanation
Correct option:
Amazon Kinesis Data Streams with Amazon Simple Notification Service (Amazon SNS)
Amazon Kinesis Data Streams makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information. Amazon Kinesis Data Streams offers key capabilities to cost-effectively process streaming data at any scale, along with the flexibility to choose the tools that best suit the requirements of your application.
With Amazon Kinesis Data Streams, you can ingest real-time data such as video, audio, application logs, website clickstreams, and IoT telemetry data for machine learning, analytics, and other applications. Amazon Kinesis Data Streams enables you to process and analyze data as it arrives and responds instantly instead of having to wait until all your data is collected before the processing can begin.
Amazon Kinesis Data Streams will be great for event streaming from IoT devices, but not for sending notifications as it doesn't have such a feature.
Amazon Simple Notification Service (Amazon SNS) is a highly available, durable, secure, fully managed pub/sub messaging service that enables you to decouple microservices, distributed systems, and serverless applications. Amazon SNS provides topics for high-throughput, push-based, many-to-many messaging. Amazon SNS is a notification service and will be perfect for this use case.
Streaming data with Amazon Kinesis Data Streams and using Amazon SNS to send the response notifications is the optimal solution for the given scenario.
Incorrect options:
Amazon Simple Queue Service (Amazon SQS) with Amazon Simple Notification Service (Amazon SNS) - Amazon Simple Queue Service (SQS) is a fully managed message queuing service that enables you to decouple and scale microservices, distributed systems, and serverless applications. Amazon SQS eliminates the complexity and overhead associated with managing and operating message-oriented middleware and empowers developers to focus on differentiating work. Using SQS, you can send, store, and receive messages between software components at any volume, without losing messages or requiring other services to be available. Kinesis is better for streaming data since queues aren't meant for real-time streaming of data.
Amazon Kinesis Data Streams with Amazon Simple Email Service (Amazon SES) - Amazon Simple Email Service (Amazon SES) is a cloud-based email-sending service designed to help digital marketers and application developers send marketing, notification, and transactional emails. It is a reliable, cost-effective service for businesses of all sizes that use email to keep in contact with their customers. It is an email service and not a notification service as is the requirement in the current use case.
Amazon Kinesis Data Streams with Amazon Simple Queue Service (Amazon SQS) - As explained above, Amazon Kinesis Data Streams works well for streaming real-time data. Amazon SQS is a queuing service that helps decouple system architecture by offering flexibility and ease of maintenance. It cannot send notifications.
References:
Question 18 Single Choice
A media company wants to get out of the business of owning and maintaining its own IT infrastructure. As part of this digital transformation, the media company wants to archive about 5 petabytes of data in its on-premises data center for durable long-term storage.
What is your recommendation to migrate this data in the MOST cost-optimal way?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Transfer the on-premises data into multiple AWS Snowball Edge Storage Optimized devices. Copy the AWS Snowball Edge data into Amazon S3 and create a lifecycle policy to transition the data into Amazon S3 Glacier
AWS Snowball Edge Storage Optimized is the optimal choice if you need to securely and quickly transfer dozens of terabytes to petabytes of data to AWS. It provides up to 80 TB of usable HDD storage, 40 vCPUs, 1 TB of SATA SSD storage, and up to 40 Gb network connectivity to address large-scale data transfer and pre-processing use cases. The data stored on the AWS Snowball Edge device can be copied into the Amazon S3 bucket and later transitioned into Amazon S3 Glacier via a lifecycle policy. You can't directly copy data from AWS Snowball Edge devices into Amazon S3 Glacier.
Incorrect options:
Transfer the on-premises data into multiple AWS Snowball Edge Storage Optimized devices. Copy the AWS Snowball Edge data into Amazon S3 Glacier - As mentioned earlier, you can't directly copy data from AWS Snowball Edge devices into Amazon S3 Glacier. Hence, this option is incorrect.
Set up AWS direct connect between the on-premises data center and AWS Cloud. Use this connection to transfer the data into Amazon S3 Glacier - AWS Direct Connect lets you establish a dedicated network connection between your network and one of the AWS Direct Connect locations. Using industry-standard 802.1q VLANs, this dedicated connection can be partitioned into multiple virtual interfaces. Direct Connect involves significant monetary investment and takes more than a month to set up, therefore it's not the correct fit for this use case where just a one-time data transfer has to be done.
Set up AWS Site-to-Site VPN connection between the on-premises data center and AWS Cloud. Use this connection to transfer the data into Amazon S3 Glacier - AWS Site-to-Site VPN enables you to securely connect your on-premises network or branch office site to your Amazon Virtual Private Cloud (Amazon VPC). VPN Connections are a good solution if you have an immediate need, and have low to modest bandwidth requirements. Because of the high data volume for the given use case, Site-to-Site VPN is not the correct choice.
Reference:
Explanation
Correct option:
Transfer the on-premises data into multiple AWS Snowball Edge Storage Optimized devices. Copy the AWS Snowball Edge data into Amazon S3 and create a lifecycle policy to transition the data into Amazon S3 Glacier
AWS Snowball Edge Storage Optimized is the optimal choice if you need to securely and quickly transfer dozens of terabytes to petabytes of data to AWS. It provides up to 80 TB of usable HDD storage, 40 vCPUs, 1 TB of SATA SSD storage, and up to 40 Gb network connectivity to address large-scale data transfer and pre-processing use cases. The data stored on the AWS Snowball Edge device can be copied into the Amazon S3 bucket and later transitioned into Amazon S3 Glacier via a lifecycle policy. You can't directly copy data from AWS Snowball Edge devices into Amazon S3 Glacier.
Incorrect options:
Transfer the on-premises data into multiple AWS Snowball Edge Storage Optimized devices. Copy the AWS Snowball Edge data into Amazon S3 Glacier - As mentioned earlier, you can't directly copy data from AWS Snowball Edge devices into Amazon S3 Glacier. Hence, this option is incorrect.
Set up AWS direct connect between the on-premises data center and AWS Cloud. Use this connection to transfer the data into Amazon S3 Glacier - AWS Direct Connect lets you establish a dedicated network connection between your network and one of the AWS Direct Connect locations. Using industry-standard 802.1q VLANs, this dedicated connection can be partitioned into multiple virtual interfaces. Direct Connect involves significant monetary investment and takes more than a month to set up, therefore it's not the correct fit for this use case where just a one-time data transfer has to be done.
Set up AWS Site-to-Site VPN connection between the on-premises data center and AWS Cloud. Use this connection to transfer the data into Amazon S3 Glacier - AWS Site-to-Site VPN enables you to securely connect your on-premises network or branch office site to your Amazon Virtual Private Cloud (Amazon VPC). VPN Connections are a good solution if you have an immediate need, and have low to modest bandwidth requirements. Because of the high data volume for the given use case, Site-to-Site VPN is not the correct choice.
Reference:
Question 19 Multiple Choice
A pharmaceutical company is considering moving to AWS Cloud to accelerate the research and development process. Most of the daily workflows would be centered around running batch jobs on Amazon EC2 instances with storage on Amazon Elastic Block Store (Amazon EBS) volumes. The CTO is concerned about meeting HIPAA compliance norms for sensitive data stored on Amazon EBS.
Which of the following options represent the correct capabilities of an encrypted Amazon EBS volume? (Select three)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Data at rest inside the volume is encrypted
Any snapshot created from the volume is encrypted
Data moving between the volume and the instance is encrypted
Amazon Elastic Block Store (Amazon EBS) provides block-level storage volumes for use with Amazon EC2 instances. When you create an encrypted Amazon EBS volume and attach it to a supported instance type, data stored at rest on the volume, data moving between the volume and the instance, snapshots created from the volume, and volumes created from those snapshots are all encrypted. It uses AWS Key Management Service (AWS KMS) customer master keys (CMK) when creating encrypted volumes and snapshots. Encryption operations occur on the servers that host Amazon EC2 instances, ensuring the security of both data-at-rest and data-in-transit between an instance and its attached Amazon EBS storage.
Incorrect options:
Data moving between the volume and the instance is NOT encrypted
Any snapshot created from the volume is NOT encrypted
Data at rest inside the volume is NOT encrypted
These three options contradict the explanation provided above, so these are incorrect.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSEncryption.html
Explanation
Correct options:
Data at rest inside the volume is encrypted
Any snapshot created from the volume is encrypted
Data moving between the volume and the instance is encrypted
Amazon Elastic Block Store (Amazon EBS) provides block-level storage volumes for use with Amazon EC2 instances. When you create an encrypted Amazon EBS volume and attach it to a supported instance type, data stored at rest on the volume, data moving between the volume and the instance, snapshots created from the volume, and volumes created from those snapshots are all encrypted. It uses AWS Key Management Service (AWS KMS) customer master keys (CMK) when creating encrypted volumes and snapshots. Encryption operations occur on the servers that host Amazon EC2 instances, ensuring the security of both data-at-rest and data-in-transit between an instance and its attached Amazon EBS storage.
Incorrect options:
Data moving between the volume and the instance is NOT encrypted
Any snapshot created from the volume is NOT encrypted
Data at rest inside the volume is NOT encrypted
These three options contradict the explanation provided above, so these are incorrect.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSEncryption.html
Question 20 Multiple Choice
A data engineer needs to set up a daily execution of Amazon Athena queries, each of which may take longer than 15 minutes to run. What are the two most cost-effective steps to achieve this requirement? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Set up an AWS Lambda function that uses the Athena Boto3 client start_query_execution API call to execute the Athena queries programmatically
You can an AWS Lambda function to execute Athena queries programmatically by using the Athena Boto3 client start_query_execution API call, like so:
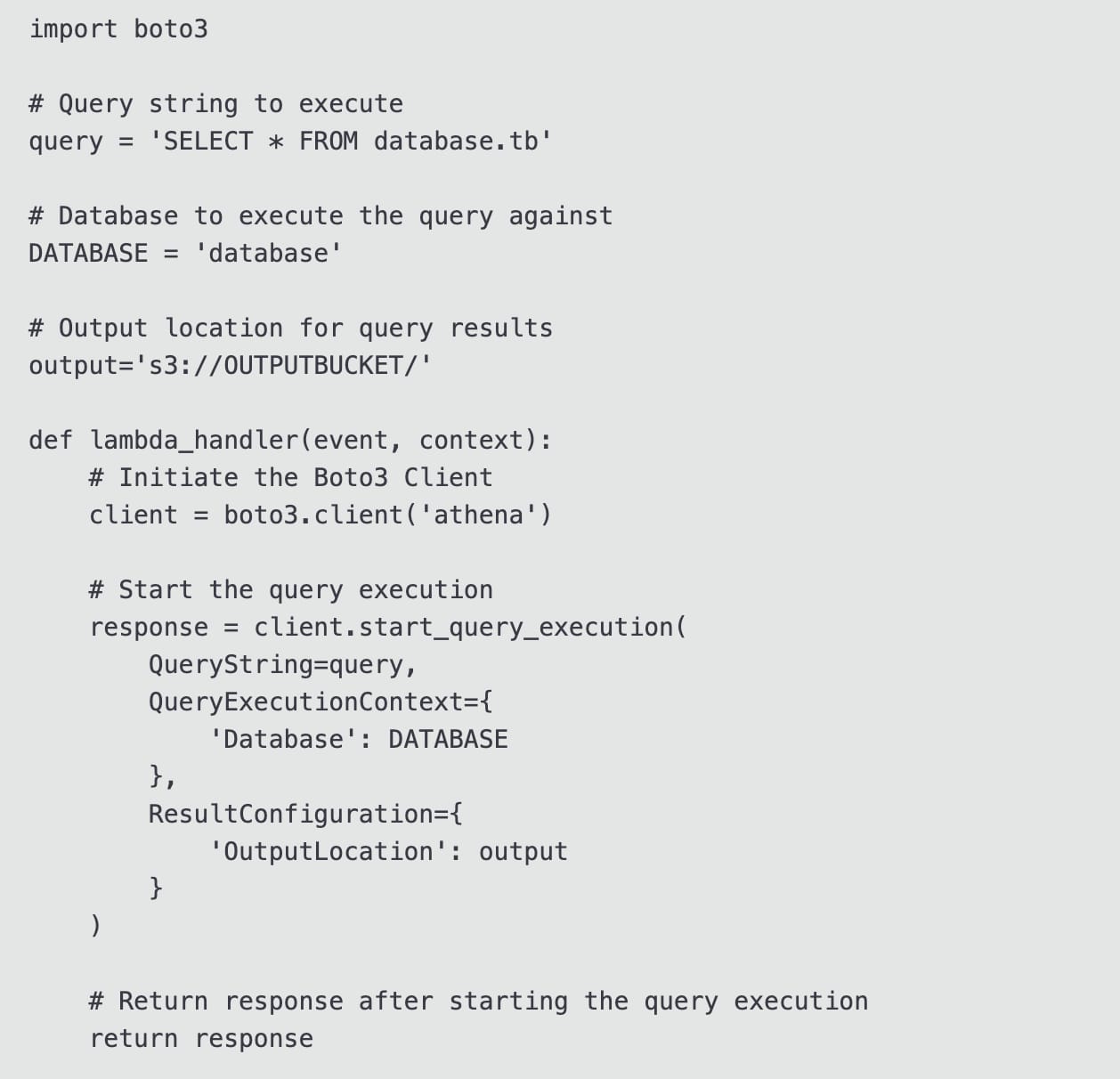 via - https://repost.aws/knowledge-center/schedule-query-athena
via - https://repost.aws/knowledge-center/schedule-query-athena
Set up a workflow in AWS Step Functions that incorporates two states. Configure the initial state prior to triggering the Lambda function. Establish the subsequent state as a Wait state, designed to periodically verify the completion status of the Athena query via the Athena Boto3 get_query_execution API call. Ensure the workflow is configured to initiate the subsequent query once the preceding one concludes
AWS Step Functions is a serverless orchestration service. It is based on state machines and tasks. In Step Functions, a workflow is called a state machine, which is a series of event-driven steps. Each step in a workflow is called a state. A Task state represents a unit of work that another AWS service, such as AWS Lambda, performs. A Task state can call any AWS service or API.
States are elements in your state machine. A state is referred to by its name, which can be any string, but must be unique within the scope of the entire state machine.
States can perform a variety of functions in your state machine:
Do some work in your state machine (a Task state)
Make a choice between branches of execution (a Choice state)
Stop an execution with a failure or success (a Fail or Succeed state)
Pass its input to its output, or inject some fixed data into the workflow (a Pass state)
Provide a delay for a certain amount of time or until a specified date and time (a Wait state)
Begin parallel branches of execution (a Parallel state)
Dynamically iterate steps (a Map state)
The AWS Step Functions service integration with Amazon Athena enables you to use Step Functions to start and stop query execution and get query results. Using Step Functions, you can run ad-hoc or scheduled data queries, and retrieve results targeting your S3 data lakes.
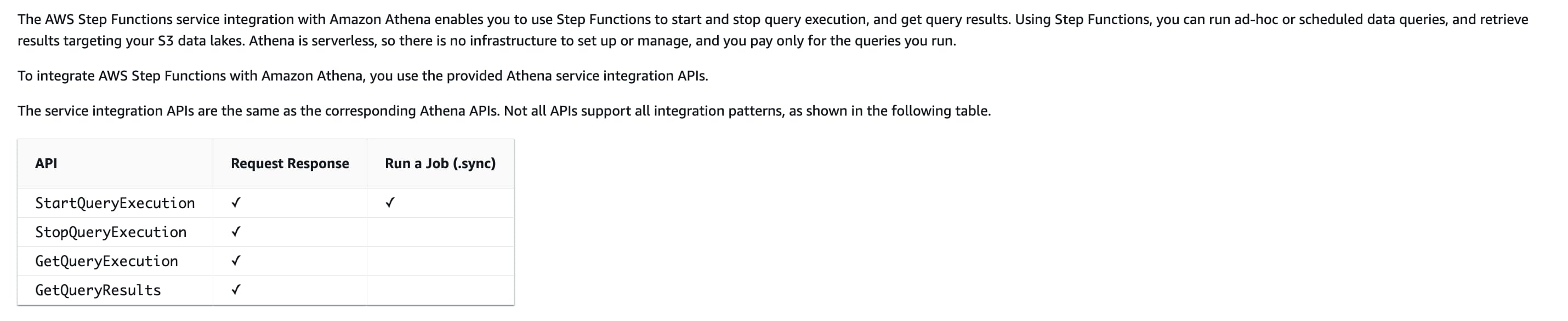 via - https://docs.aws.amazon.com/step-functions/latest/dg/connect-athena.html
via - https://docs.aws.amazon.com/step-functions/latest/dg/connect-athena.html
For the given use case, incorporating a Wait state into the workflow allows for regular monitoring of the Athena query's status, advancing to the subsequent step only after the query is finalized. Step Functions are better suited for managing long-running processes and maintaining the status across different stages of the workflow.
Incorrect options:
Set up an AWS Glue Python shell job that uses the Athena Boto3 client start_query_execution API call to execute the Athena queries programmatically - Although you could certainly use an AWS Glue Python shell job to invoke the start_query_execution API call via the Athena Boto3 client, however, it turns out to be costlier than using a Lambda function to invoke the call. So, this option is incorrect.
Set up a workflow in AWS Step Functions that incorporates two states. Configure the initial state prior to triggering the AWS Glue Python shell job. Establish the subsequent state as a Wait state, designed to periodically verify the completion status of the Athena query via the Athena Boto3 get_query_execution API call. Ensure the workflow is configured to initiate the subsequent query once the preceding one concludes - As mentioned earlier, for the given use case - leveraging an AWS Glue Python shell job instead of a Lambda function is a costlier proposition, so this option is incorrect.
Develop a Python shell script in AWS Glue to implement a sleep timer that checks every 5 minutes if the current Athena query has successfully completed. Set up the script so that it triggers the subsequent query once the current one is confirmed to have finished - It is costlier as well as resource-inefficient to check for the status of Athena query execution every 5 minutes via a long-running Glue job. So, this option is incorrect.
References:
https://repost.aws/knowledge-center/schedule-query-athena
https://docs.aws.amazon.com/step-functions/latest/dg/welcome.html
https://docs.aws.amazon.com/step-functions/latest/dg/connect-athena.html
Explanation
Correct options:
Set up an AWS Lambda function that uses the Athena Boto3 client start_query_execution API call to execute the Athena queries programmatically
You can an AWS Lambda function to execute Athena queries programmatically by using the Athena Boto3 client start_query_execution API call, like so:
via - https://repost.aws/knowledge-center/schedule-query-athena
Set up a workflow in AWS Step Functions that incorporates two states. Configure the initial state prior to triggering the Lambda function. Establish the subsequent state as a Wait state, designed to periodically verify the completion status of the Athena query via the Athena Boto3 get_query_execution API call. Ensure the workflow is configured to initiate the subsequent query once the preceding one concludes
AWS Step Functions is a serverless orchestration service. It is based on state machines and tasks. In Step Functions, a workflow is called a state machine, which is a series of event-driven steps. Each step in a workflow is called a state. A Task state represents a unit of work that another AWS service, such as AWS Lambda, performs. A Task state can call any AWS service or API.
States are elements in your state machine. A state is referred to by its name, which can be any string, but must be unique within the scope of the entire state machine.
States can perform a variety of functions in your state machine:
Do some work in your state machine (a Task state)
Make a choice between branches of execution (a Choice state)
Stop an execution with a failure or success (a Fail or Succeed state)
Pass its input to its output, or inject some fixed data into the workflow (a Pass state)
Provide a delay for a certain amount of time or until a specified date and time (a Wait state)
Begin parallel branches of execution (a Parallel state)
Dynamically iterate steps (a Map state)
The AWS Step Functions service integration with Amazon Athena enables you to use Step Functions to start and stop query execution and get query results. Using Step Functions, you can run ad-hoc or scheduled data queries, and retrieve results targeting your S3 data lakes.
via - https://docs.aws.amazon.com/step-functions/latest/dg/connect-athena.html
For the given use case, incorporating a Wait state into the workflow allows for regular monitoring of the Athena query's status, advancing to the subsequent step only after the query is finalized. Step Functions are better suited for managing long-running processes and maintaining the status across different stages of the workflow.
Incorrect options:
Set up an AWS Glue Python shell job that uses the Athena Boto3 client start_query_execution API call to execute the Athena queries programmatically - Although you could certainly use an AWS Glue Python shell job to invoke the start_query_execution API call via the Athena Boto3 client, however, it turns out to be costlier than using a Lambda function to invoke the call. So, this option is incorrect.
Set up a workflow in AWS Step Functions that incorporates two states. Configure the initial state prior to triggering the AWS Glue Python shell job. Establish the subsequent state as a Wait state, designed to periodically verify the completion status of the Athena query via the Athena Boto3 get_query_execution API call. Ensure the workflow is configured to initiate the subsequent query once the preceding one concludes - As mentioned earlier, for the given use case - leveraging an AWS Glue Python shell job instead of a Lambda function is a costlier proposition, so this option is incorrect.
Develop a Python shell script in AWS Glue to implement a sleep timer that checks every 5 minutes if the current Athena query has successfully completed. Set up the script so that it triggers the subsequent query once the current one is confirmed to have finished - It is costlier as well as resource-inefficient to check for the status of Athena query execution every 5 minutes via a long-running Glue job. So, this option is incorrect.
References:
https://repost.aws/knowledge-center/schedule-query-athena
https://docs.aws.amazon.com/step-functions/latest/dg/welcome.html
https://docs.aws.amazon.com/step-functions/latest/dg/connect-athena.html


