
AWS Certified Developer - Associate - (DVA-C02) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 1 Multiple Choice
A review of Amazon CloudWatch metrics shows that there are a high number of reads taking place on a primary database built on Amazon Aurora with MySQL. What can a developer do to improve the read scaling of the database? (Select TWO.)
Explanation

Click "Show Answer" to see the explanation here
Aurora Replicas can help improve read scaling because it synchronously updates data with the primary database (within 100 ms). Aurora Replicas are created in the same DB cluster within a Region. With Aurora MySQL you can also enable binlog replication to another Aurora DB cluster which can be in the same or a different Region.
CORRECT: "Create Aurora Replicas in same cluster as the primary database instance" is the correct answer (as explained above.)
CORRECT: "Create a separate Aurora MySQL cluster and configure binlog replication" is also a correct answer (as explained above.)
INCORRECT: "Create a duplicate Aurora database cluster to process read requests" is incorrect. A duplicate Aurora database cluster would be a separate database with read and write capability and would not help with read scaling.
INCORRECT: "Create a duplicate Aurora primary database to process read requests" is incorrect. A duplicate Aurora primary database would be for read and write requests and would not help with read scaling.
INCORRECT: "Creating read replicas of Aurora in a S3 global bucket as the primary read source" is incorrect. S3 is an object storage service. It cannot be used to host databases.
References:
Explanation
Aurora Replicas can help improve read scaling because it synchronously updates data with the primary database (within 100 ms). Aurora Replicas are created in the same DB cluster within a Region. With Aurora MySQL you can also enable binlog replication to another Aurora DB cluster which can be in the same or a different Region.
CORRECT: "Create Aurora Replicas in same cluster as the primary database instance" is the correct answer (as explained above.)
CORRECT: "Create a separate Aurora MySQL cluster and configure binlog replication" is also a correct answer (as explained above.)
INCORRECT: "Create a duplicate Aurora database cluster to process read requests" is incorrect. A duplicate Aurora database cluster would be a separate database with read and write capability and would not help with read scaling.
INCORRECT: "Create a duplicate Aurora primary database to process read requests" is incorrect. A duplicate Aurora primary database would be for read and write requests and would not help with read scaling.
INCORRECT: "Creating read replicas of Aurora in a S3 global bucket as the primary read source" is incorrect. S3 is an object storage service. It cannot be used to host databases.
References:
Question 2 Single Choice
A company has created a set of APIs using Amazon API Gateway and exposed them to partner companies. The APIs have caching enabled for all stages. The partners require a method of invalidating the cache that they can build into their applications.
What can the partners use to invalidate the API cache?
Explanation
Click "Show Answer" to see the explanation here
You can enable API caching in Amazon API Gateway to cache your endpoint's responses. With caching, you can reduce the number of calls made to your endpoint and also improve the latency of requests to your API.
When you enable caching for a stage, API Gateway caches responses from your endpoint for a specified time-to-live (TTL) period, in seconds. API Gateway then responds to the request by looking up the endpoint response from the cache instead of making a request to your endpoint. The default TTL value for API caching is 300 seconds. The maximum TTL value is 3600 seconds. TTL=0 means caching is disabled.
A client of your API can invalidate an existing cache entry and reload it from the integration endpoint for individual requests. The client must send a request that contains the Cache-Control: max-age=0 header.
The client receives the response directly from the integration endpoint instead of the cache, provided that the client is authorized to do so. This replaces the existing cache entry with the new response, which is fetched from the integration endpoint.
To grant permission for a client, attach a policy of the following format to an IAM execution role for the user.
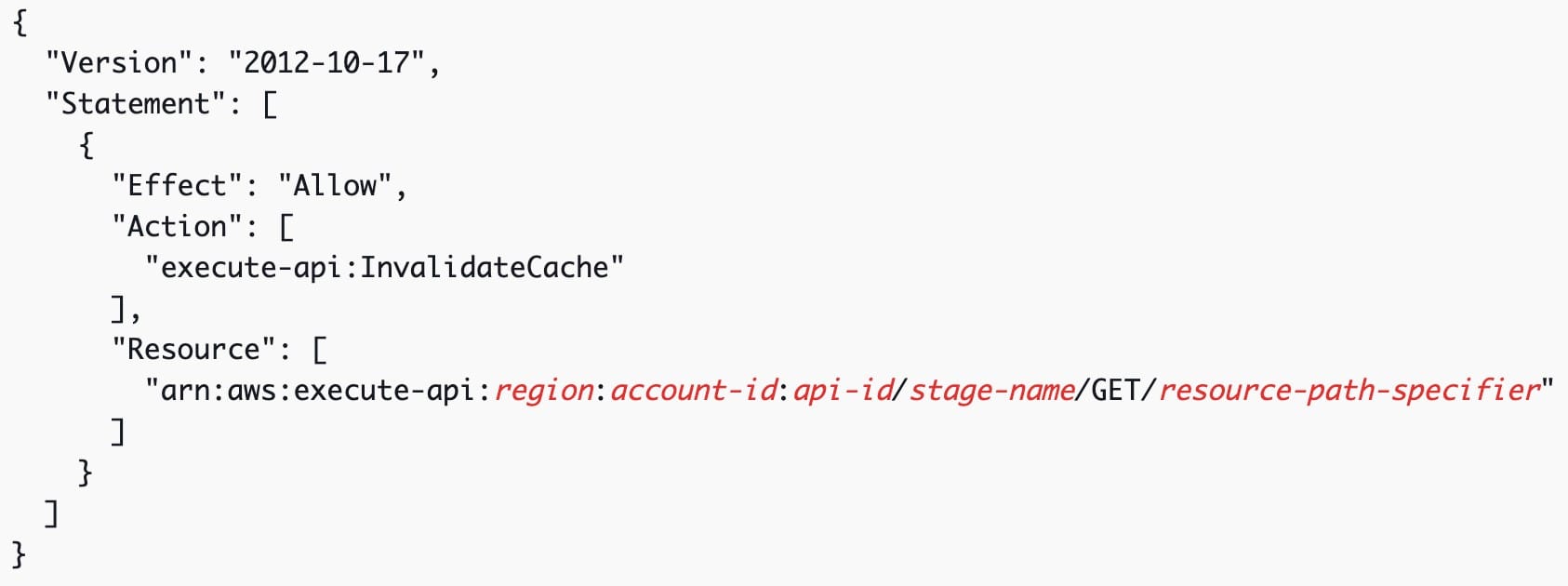
This policy allows the API Gateway execution service to invalidate the cache for requests on the specified resource (or resources).
Therefore, as described above the solution is to get the partners to pass the HTTP header Cache-Control: max-age=0.
CORRECT: "They can pass the HTTP header Cache-Control: max-age=0" is the correct answer.
INCORRECT: "They can use the query string parameter INVALIDATE_CACHE" is incorrect. This is not a valid method of invalidating the cache with API Gateway.
INCORRECT: "They must wait for the TTL to expire" is incorrect as this is not true, you do not need to wait as you can pass the HTTP header Cache-Control: max-age=0 whenever you need to in order to invalidate the cache.
INCORRECT: "They can invoke an AWS API endpoint which invalidates the cache" is incorrect. This is not a valid method of invalidating the cache with API Gateway.
References:
https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-caching.html
Explanation
You can enable API caching in Amazon API Gateway to cache your endpoint's responses. With caching, you can reduce the number of calls made to your endpoint and also improve the latency of requests to your API.
When you enable caching for a stage, API Gateway caches responses from your endpoint for a specified time-to-live (TTL) period, in seconds. API Gateway then responds to the request by looking up the endpoint response from the cache instead of making a request to your endpoint. The default TTL value for API caching is 300 seconds. The maximum TTL value is 3600 seconds. TTL=0 means caching is disabled.
A client of your API can invalidate an existing cache entry and reload it from the integration endpoint for individual requests. The client must send a request that contains the Cache-Control: max-age=0 header.
The client receives the response directly from the integration endpoint instead of the cache, provided that the client is authorized to do so. This replaces the existing cache entry with the new response, which is fetched from the integration endpoint.
To grant permission for a client, attach a policy of the following format to an IAM execution role for the user.
This policy allows the API Gateway execution service to invalidate the cache for requests on the specified resource (or resources).
Therefore, as described above the solution is to get the partners to pass the HTTP header Cache-Control: max-age=0.
CORRECT: "They can pass the HTTP header Cache-Control: max-age=0" is the correct answer.
INCORRECT: "They can use the query string parameter INVALIDATE_CACHE" is incorrect. This is not a valid method of invalidating the cache with API Gateway.
INCORRECT: "They must wait for the TTL to expire" is incorrect as this is not true, you do not need to wait as you can pass the HTTP header Cache-Control: max-age=0 whenever you need to in order to invalidate the cache.
INCORRECT: "They can invoke an AWS API endpoint which invalidates the cache" is incorrect. This is not a valid method of invalidating the cache with API Gateway.
References:
https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-caching.html
Question 3 Single Choice
An e-commerce web application that shares session state on-premises is being migrated to AWS. The application must be fault tolerant, natively highly scalable, and any service interruption should not affect the user experience.
What is the best option to store the session state?
Explanation
Click "Show Answer" to see the explanation here
There are various ways to manage user sessions including storing those sessions locally to the node responding to the HTTP request or designating a layer in your architecture which can store those sessions in a scalable and robust manner. Common approaches used include utilizing Sticky sessions or using a Distributed Cache for your session management.
In this scenario, a distributed cache is suitable for storing session state data. ElastiCache can perform this role and with the Redis engine replication is also supported. Therefore, the solution is fault-tolerant and natively highly scalable.
CORRECT: "Store the session state in Amazon ElastiCache" is the correct answer.
INCORRECT: "Store the session state in Amazon CloudFront" is incorrect as CloudFront is not suitable for storing session state data, it is used for caching content for better global performance.
INCORRECT: "Store the session state in Amazon S3" is incorrect as though you can store session data in Amazon S3 and replicate the data to another bucket, this would result in a service interruption if the S3 bucket was not accessible.
INCORRECT: "Enable session stickiness using elastic load balancers" is incorrect as this feature directs sessions from a specific client to a specific EC2 instances. Therefore, if the instance fails the user must be redirected to another EC2 instance and the session state data would be lost.
References:
Explanation
There are various ways to manage user sessions including storing those sessions locally to the node responding to the HTTP request or designating a layer in your architecture which can store those sessions in a scalable and robust manner. Common approaches used include utilizing Sticky sessions or using a Distributed Cache for your session management.
In this scenario, a distributed cache is suitable for storing session state data. ElastiCache can perform this role and with the Redis engine replication is also supported. Therefore, the solution is fault-tolerant and natively highly scalable.
CORRECT: "Store the session state in Amazon ElastiCache" is the correct answer.
INCORRECT: "Store the session state in Amazon CloudFront" is incorrect as CloudFront is not suitable for storing session state data, it is used for caching content for better global performance.
INCORRECT: "Store the session state in Amazon S3" is incorrect as though you can store session data in Amazon S3 and replicate the data to another bucket, this would result in a service interruption if the S3 bucket was not accessible.
INCORRECT: "Enable session stickiness using elastic load balancers" is incorrect as this feature directs sessions from a specific client to a specific EC2 instances. Therefore, if the instance fails the user must be redirected to another EC2 instance and the session state data would be lost.
References:
Question 4 Single Choice
A developer has deployed an application on AWS Lambda. The application uses Python and must generate and then upload a file to an Amazon S3 bucket. The developer must implement the upload functionality with the least possible change to the application code.
Which solution BEST meets these requirements?
Explanation
Click "Show Answer" to see the explanation here
The best practice for Lambda development is to bundle all dependencies used by your Lambda function, including the AWS SDK. However, since this question specifically requests that the least possible changes are made to the application code, the developer can instead use the SDK for Python that is installed in the Lambda environment to upload the file to Amazon S3.
CORRECT: "Use the AWS SDK for Python that is installed in the Lambda execution environment" is the correct answer (as explained above.)
INCORRECT: "Include the AWS SDK for Python in the Lambda function code" is incorrect.
This is the best practice for deployment. However, in this case the developer must minimize changes to code and including the SDK as a dependency in the code would require potential updates to existing Python code.
INCORRECT: "Make an HTTP request directly to the S3 API to upload the file" is incorrect.
AWS supports uploads to S3 using the console, AWS SDKs, REST API, and the AWS CLI.
INCORRECT: "Use the AWS CLI that is installed in the Lambda execution environment" is incorrect.
The AWS CLI is not installed in the Lambda execution environment.
References:
https://aws.amazon.com/blogs/compute/upcoming-changes-to-the-python-sdk-in-aws-lambda/
Explanation
The best practice for Lambda development is to bundle all dependencies used by your Lambda function, including the AWS SDK. However, since this question specifically requests that the least possible changes are made to the application code, the developer can instead use the SDK for Python that is installed in the Lambda environment to upload the file to Amazon S3.
CORRECT: "Use the AWS SDK for Python that is installed in the Lambda execution environment" is the correct answer (as explained above.)
INCORRECT: "Include the AWS SDK for Python in the Lambda function code" is incorrect.
This is the best practice for deployment. However, in this case the developer must minimize changes to code and including the SDK as a dependency in the code would require potential updates to existing Python code.
INCORRECT: "Make an HTTP request directly to the S3 API to upload the file" is incorrect.
AWS supports uploads to S3 using the console, AWS SDKs, REST API, and the AWS CLI.
INCORRECT: "Use the AWS CLI that is installed in the Lambda execution environment" is incorrect.
The AWS CLI is not installed in the Lambda execution environment.
References:
https://aws.amazon.com/blogs/compute/upcoming-changes-to-the-python-sdk-in-aws-lambda/
Question 5 Single Choice
A Developer is deploying an application in a microservices architecture on Amazon ECS. The Developer needs to choose the best task placement strategy to MINIMIZE the number of instances that are used. Which task placement strategy should be used?
Explanation
Click "Show Answer" to see the explanation here
A task placement strategy is an algorithm for selecting instances for task placement or tasks for termination. Task placement strategies can be specified when either running a task or creating a new service.
Amazon ECS supports the following task placement strategies:
binpack - Place tasks based on the least available amount of CPU or memory. This minimizes the number of instances in use.
random - Place tasks randomly.
spread - Place tasks evenly based on the specified value. Accepted values are instanceId (or host, which has the same effect), or any platform or custom attribute that is applied to a container instance, such as attribute:ecs.availability-zone. Service tasks are spread based on the tasks from that service. Standalone tasks are spread based on the tasks from the same task group.
The binpack task placement strategy is the most suitable for this scenario as it minimizes the number of instances used which is a requirement for this solution.
CORRECT: "binpack" is the correct answer.
INCORRECT: "random" is incorrect as this would assign tasks randomly to EC2 instances which would not result in minimizing the number of instances used.
INCORRECT: "spread" is incorrect as this would spread the tasks based on a specified value. This is not used for minimizing the number of instances used.
INCORRECT: "weighted" is incorrect as this is not an ECS task placement strategy. Weighted is associated with Amazon Route 53 routing policies.
References:
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task-placement-strategies.html
Explanation
A task placement strategy is an algorithm for selecting instances for task placement or tasks for termination. Task placement strategies can be specified when either running a task or creating a new service.
Amazon ECS supports the following task placement strategies:
binpack - Place tasks based on the least available amount of CPU or memory. This minimizes the number of instances in use.
random - Place tasks randomly.
spread - Place tasks evenly based on the specified value. Accepted values are instanceId (or host, which has the same effect), or any platform or custom attribute that is applied to a container instance, such as attribute:ecs.availability-zone. Service tasks are spread based on the tasks from that service. Standalone tasks are spread based on the tasks from the same task group.
The binpack task placement strategy is the most suitable for this scenario as it minimizes the number of instances used which is a requirement for this solution.
CORRECT: "binpack" is the correct answer.
INCORRECT: "random" is incorrect as this would assign tasks randomly to EC2 instances which would not result in minimizing the number of instances used.
INCORRECT: "spread" is incorrect as this would spread the tasks based on a specified value. This is not used for minimizing the number of instances used.
INCORRECT: "weighted" is incorrect as this is not an ECS task placement strategy. Weighted is associated with Amazon Route 53 routing policies.
References:
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task-placement-strategies.html
Question 6 Single Choice
An organization is selling memorabilia that is illegal in specific countries. How can a developer restrict access to the website to countries where the memorabilia are illegal?
Explanation
Click "Show Answer" to see the explanation here
AWS WAF can be used to set up a WEB ACL that can be used to block statements that originate from a specific country.
CORRECT: "Create a Web ACL in AWS WAF with a rule that matches the specified countries and blocks access" is the correct answer (as explained above.)
INCORRECT: "Create a Web ACL in AWS Shield with a rule that matches the specified countries and blocks access" is incorrect. AWS Shield is used to protect from DDoS attacks.
INCORRECT: "Create a Web ACL in AWS WAF with a rule that matches the specified countries and triggers an SNS notification" is incorrect. This will not block access to specific countries.
INCORRECT: " Create a Web ACL in AWS Shield with a rule that matches the specified countries and triggers an SNS notification" is incorrect. This will not block access to specific countries.
References:
https://aws.amazon.com/premiumsupport/knowledge-center/waf-allow-block-country-geolocation/
Explanation
AWS WAF can be used to set up a WEB ACL that can be used to block statements that originate from a specific country.
CORRECT: "Create a Web ACL in AWS WAF with a rule that matches the specified countries and blocks access" is the correct answer (as explained above.)
INCORRECT: "Create a Web ACL in AWS Shield with a rule that matches the specified countries and blocks access" is incorrect. AWS Shield is used to protect from DDoS attacks.
INCORRECT: "Create a Web ACL in AWS WAF with a rule that matches the specified countries and triggers an SNS notification" is incorrect. This will not block access to specific countries.
INCORRECT: " Create a Web ACL in AWS Shield with a rule that matches the specified countries and triggers an SNS notification" is incorrect. This will not block access to specific countries.
References:
https://aws.amazon.com/premiumsupport/knowledge-center/waf-allow-block-country-geolocation/
Question 7 Single Choice
A developer must identify the public IP addresses of clients connecting to Amazon EC2 instances behind a public Application Load Balancer (ALB). The EC2 instances run an HTTP server that logs all requests to a log file.
How can the developer ensure the client public IP addresses are captured in the log files on the EC2 instances?
Explanation
Click "Show Answer" to see the explanation here
The X-Forwarded-For request header is automatically added and helps you identify the IP address of a client when you use an HTTP or HTTPS load balancer.
Because load balancers intercept traffic between clients and servers, your server access logs contain only the IP address of the load balancer. To see the IP address of the client, use the X-Forwarded-For request header.
The HTTP server may need to be configured to include the x-forwarded-for request header in the log files. Once this is done, the logs will contain the public IP addresses of the clients.
CORRECT: "Configure the HTTP server to add the x-forwarded-for request header to the logs" is the correct answer (as explained above.)
INCORRECT: "Configure the HTTP server to add the x-forwarded-proto request header to the logs" is incorrect.
This request header identifies the protocol (HTTP or HTTPS).
INCORRECT: "Install the AWS X-Ray daemon on the EC2 instances and configure request logging" is incorrect.
X-Ray is used for tracing applications; it will not help identify the public IP addresses of clients.
INCORRECT: "Install the Amazon CloudWatch Logs agent on the EC2 instances and configure logging" is incorrect.
The Amazon CloudWatch Logs agent will send application and system logs to CloudWatch Logs. This does not help to capture the client IP addresses of connections.
References:
Explanation
The X-Forwarded-For request header is automatically added and helps you identify the IP address of a client when you use an HTTP or HTTPS load balancer.
Because load balancers intercept traffic between clients and servers, your server access logs contain only the IP address of the load balancer. To see the IP address of the client, use the X-Forwarded-For request header.
The HTTP server may need to be configured to include the x-forwarded-for request header in the log files. Once this is done, the logs will contain the public IP addresses of the clients.
CORRECT: "Configure the HTTP server to add the x-forwarded-for request header to the logs" is the correct answer (as explained above.)
INCORRECT: "Configure the HTTP server to add the x-forwarded-proto request header to the logs" is incorrect.
This request header identifies the protocol (HTTP or HTTPS).
INCORRECT: "Install the AWS X-Ray daemon on the EC2 instances and configure request logging" is incorrect.
X-Ray is used for tracing applications; it will not help identify the public IP addresses of clients.
INCORRECT: "Install the Amazon CloudWatch Logs agent on the EC2 instances and configure logging" is incorrect.
The Amazon CloudWatch Logs agent will send application and system logs to CloudWatch Logs. This does not help to capture the client IP addresses of connections.
References:
Question 8 Single Choice
An application needs to generate SMS text messages and emails for a large number of subscribers. Which AWS service can be used to send these messages to customers?
Explanation
Click "Show Answer" to see the explanation here
Amazon Simple Notification Service (Amazon SNS) is a web service that coordinates and manages the delivery or sending of messages to subscribing endpoints or clients. In Amazon SNS, there are two types of clients—publishers and subscribers—also referred to as producers and consumers.
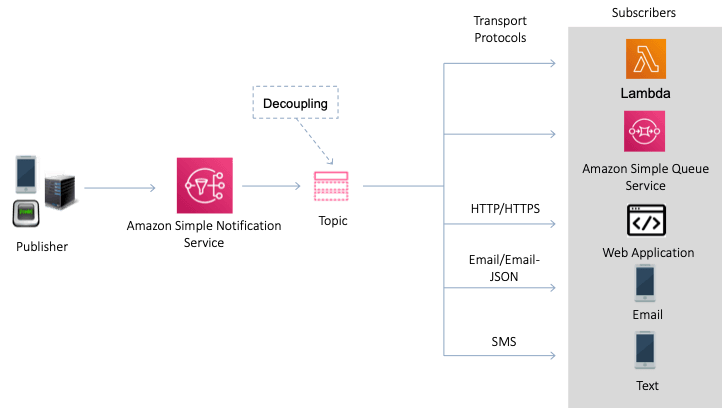
Publishers communicate asynchronously with subscribers by producing and sending a message to a topic, which is a logical access point and communication channel.
Subscribers (that is, web servers, email addresses, Amazon SQS queues, AWS Lambda functions) consume or receive the message or notification over one of the supported protocols (that is, Amazon SQS, HTTP/S, email, SMS, Lambda) when they are subscribed to the topic.
CORRECT: "Amazon SNS" is the correct answer.
INCORRECT: "Amazon SES" is incorrect as this service only sends email, not SMS text messages.
INCORRECT: "Amazon SQS" is incorrect as this is a hosted message queue for decoupling application components.
INCORRECT: "Amazon SWF" is incorrect as the Simple Workflow Service is used for orchestrating multi-step workflows.
References:
Explanation
Amazon Simple Notification Service (Amazon SNS) is a web service that coordinates and manages the delivery or sending of messages to subscribing endpoints or clients. In Amazon SNS, there are two types of clients—publishers and subscribers—also referred to as producers and consumers.
Publishers communicate asynchronously with subscribers by producing and sending a message to a topic, which is a logical access point and communication channel.
Subscribers (that is, web servers, email addresses, Amazon SQS queues, AWS Lambda functions) consume or receive the message or notification over one of the supported protocols (that is, Amazon SQS, HTTP/S, email, SMS, Lambda) when they are subscribed to the topic.
CORRECT: "Amazon SNS" is the correct answer.
INCORRECT: "Amazon SES" is incorrect as this service only sends email, not SMS text messages.
INCORRECT: "Amazon SQS" is incorrect as this is a hosted message queue for decoupling application components.
INCORRECT: "Amazon SWF" is incorrect as the Simple Workflow Service is used for orchestrating multi-step workflows.
References:
Question 9 Single Choice
An application uses an Amazon RDS database. The company requires that the performance of database reads is improved, and they want to add a caching layer in front of the database. The cached data must be encrypted, and the solution must be highly available.
Which solution will meet these requirements?
Explanation
Click "Show Answer" to see the explanation here
Amazon ElastiCache is an in-memory database cache that can be used in front of Amazon RDS. The key to answering this question is to know the differences between ElastiCache Memcached and ElastiCache Redis. To support both encryption and high availability we must use ElastiCache Redis with cluster mode enabled.
You can see the differences between the different engines and configuration options for ElastiCache in the table below:
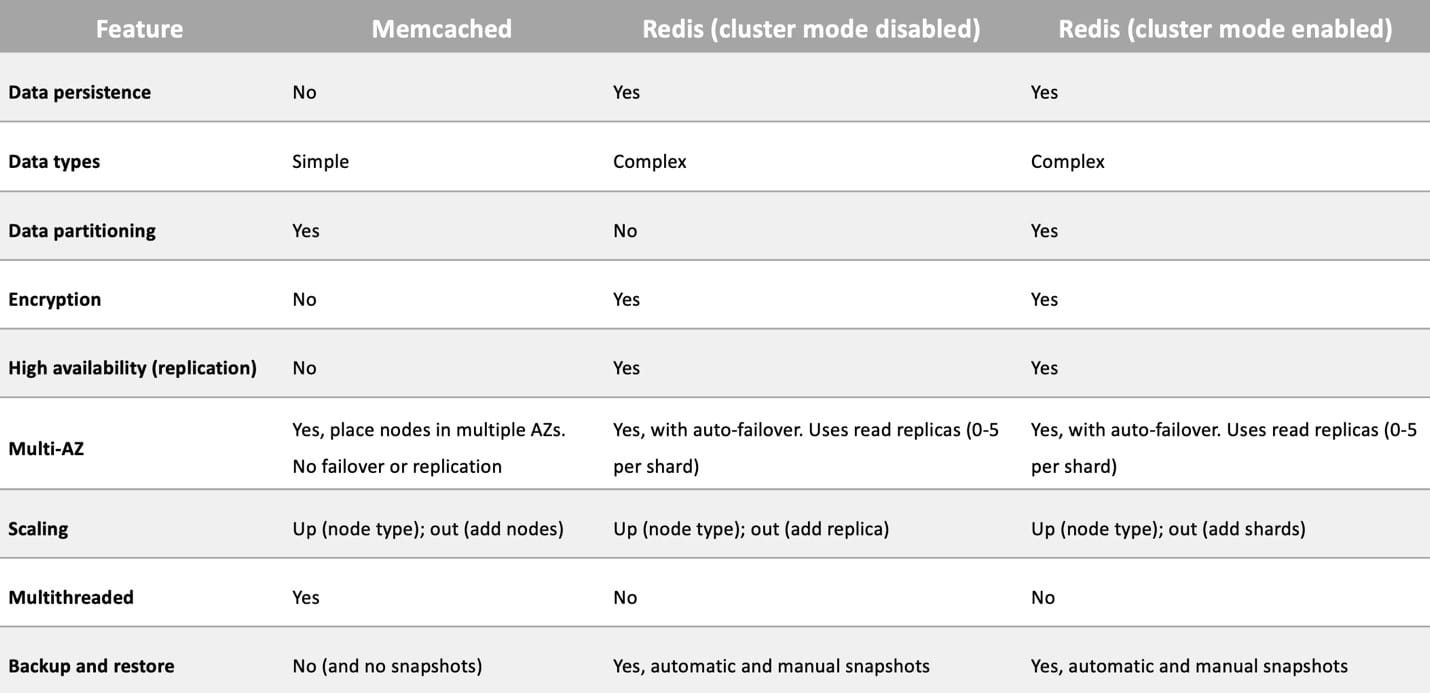
CORRECT: "Amazon ElastiCache for Redis in cluster mode" is the correct answer (as explained above.)
INCORRECT: "Amazon ElastiCache for Memcached" is incorrect.
The Memcached engine does not support encryption or high availability.
INCORRECT: "Amazon CloudFront with multiple origins" is incorrect.
You cannot configure an Amazon RDS as an origin for Amazon RDS. Also, what would the second origin be anyway? There’s only one database!
INCORRECT: "Amazon DynamoDB Accelerator (DAX)" is incorrect.
DynamoDB DAX can be used to increase the performance of DynamoDB tables and offload read requests. It cannot be used in front of an Amazon RDS database.
References:
https://docs.aws.amazon.com/AmazonElastiCache/latest/red-ug/Replication.Redis-RedisCluster.html
Explanation
Amazon ElastiCache is an in-memory database cache that can be used in front of Amazon RDS. The key to answering this question is to know the differences between ElastiCache Memcached and ElastiCache Redis. To support both encryption and high availability we must use ElastiCache Redis with cluster mode enabled.
You can see the differences between the different engines and configuration options for ElastiCache in the table below:
CORRECT: "Amazon ElastiCache for Redis in cluster mode" is the correct answer (as explained above.)
INCORRECT: "Amazon ElastiCache for Memcached" is incorrect.
The Memcached engine does not support encryption or high availability.
INCORRECT: "Amazon CloudFront with multiple origins" is incorrect.
You cannot configure an Amazon RDS as an origin for Amazon RDS. Also, what would the second origin be anyway? There’s only one database!
INCORRECT: "Amazon DynamoDB Accelerator (DAX)" is incorrect.
DynamoDB DAX can be used to increase the performance of DynamoDB tables and offload read requests. It cannot be used in front of an Amazon RDS database.
References:
https://docs.aws.amazon.com/AmazonElastiCache/latest/red-ug/Replication.Redis-RedisCluster.html
Question 10 Single Choice
A startup is developing a prototype for a news aggregator application. This application will display the latest news for a specific industry and provide a RESTful API endpoint that clients can invoke. Where feasible, the application should leverage AWS's caching features to reduce the load on the backend service. The backend of the application is expected to handle a modest amount of traffic, primarily during testing periods.
Which method would be the most cost-effective for the developer to implement this REST endpoint?
Explanation
Click "Show Answer" to see the explanation here
AWS API Gateway, combined with AWS Lambda, offers a serverless solution where costs are directly related to usage. API Gateway also provides a caching feature which can help reduce the load on the backend.
CORRECT: "Utilize AWS API Gateway with an AWS Lambda function as the backend and enable caching in API Gateway" is the correct answer (as explained above.)
INCORRECT: "Launch an Amazon EC2 instance, host the application on it, and employ Amazon ElastiCache for caching purposes" is incorrect.
Using an Amazon EC2 instance would incur constant costs, regardless of whether the instance is in use or idle. Additionally, employing AWS ElastiCache could increase the costs unnecessarily, especially for a prototype application.
INCORRECT: "Construct an Amazon ECS service for the application, using Amazon ElastiCache for caching" is incorrect.
Amazon ECS is overkill for a simple prototype application like this. It requires more resources and management than a serverless solution.
INCORRECT: "Deploy an AWS Elastic Beanstalk application and use Amazon DynamoDB for caching services" is incorrect.
While AWS Elastic Beanstalk simplifies application deployment, it does not inherently provide caching capabilities. Amazon DynamoDB is a database service, not a caching service, making it unsuitable for this requirement.
References:
https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-caching.html
Explanation
AWS API Gateway, combined with AWS Lambda, offers a serverless solution where costs are directly related to usage. API Gateway also provides a caching feature which can help reduce the load on the backend.
CORRECT: "Utilize AWS API Gateway with an AWS Lambda function as the backend and enable caching in API Gateway" is the correct answer (as explained above.)
INCORRECT: "Launch an Amazon EC2 instance, host the application on it, and employ Amazon ElastiCache for caching purposes" is incorrect.
Using an Amazon EC2 instance would incur constant costs, regardless of whether the instance is in use or idle. Additionally, employing AWS ElastiCache could increase the costs unnecessarily, especially for a prototype application.
INCORRECT: "Construct an Amazon ECS service for the application, using Amazon ElastiCache for caching" is incorrect.
Amazon ECS is overkill for a simple prototype application like this. It requires more resources and management than a serverless solution.
INCORRECT: "Deploy an AWS Elastic Beanstalk application and use Amazon DynamoDB for caching services" is incorrect.
While AWS Elastic Beanstalk simplifies application deployment, it does not inherently provide caching capabilities. Amazon DynamoDB is a database service, not a caching service, making it unsuitable for this requirement.
References:
https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-caching.html


