
AWS Certified DevOps Engineer - Professional - (DOP-C02) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 1 Multiple Choice
The security policy of a company mandates encrypting all AMIs that the company shares across its AWS accounts. An AWS account (Account A) has a custom AMI that is not encrypted. This AMI needs to be shared with another AWS Account B. Account B has Amazon EC2 instances configured with an Auto Scaling group that will use the AMI. Account A already has an AWS Key Management Service (AWS KMS) key.
As a DevOps Engineer, which combination of steps will you take to share the AMI with Account B while adhering to the company's security policy? (Select two)
Explanation

Click "Show Answer" to see the explanation here
Correct options:
In Account A, create an encrypted AMI from the unencrypted version and specify the KMS key in the copy action. Modify the key policy to give permissions to Account B for creating a grant. Share the encrypted AMI with Account B
In Account B, create a KMS grant that delegates permissions to the service-linked role attached to the Auto Scaling group
As per the security policy of the company, encrypt the unencrypted AMI using the KMS key. The encrypted snapshots must be encrypted with a KMS key. You can’t share AMIs that are backed by snapshots that are encrypted with the default AWS-managed key.
Amazon EC2 Auto Scaling uses service-linked roles to delegate permissions to other AWS services. Amazon EC2 Auto Scaling service-linked roles are predefined and include permissions that Amazon EC2 Auto Scaling requires to call other AWS services on your behalf. The predefined permissions also include access to your AWS-managed keys. However, they do not include access to your customer-managed keys, allowing you to maintain full control over these keys.
If you create a customer-managed key in a different account than the Auto Scaling group, you must use a grant in combination with the key policy to allow cross-account access to the key. This is a two-step process (refer to the image attached)
The first policy allows Account A to give an IAM user or role in the specified Account B permission to create a grant for the key. However, this does not by itself give any users access to the key.
Then, from Account B which contains the Auto Scaling group, create a grant that delegates the relevant permissions to the appropriate service-linked role. The
Grantee Principalelement of the grant is the ARN of the appropriate service-linked role. Thekey-idis the ARN of the key.
Key policy sections that allow cross-account access to the customer-managed key:  via - https://docs.aws.amazon.com/autoscaling/ec2/userguide/key-policy-requirements-EBS-encryption.html
via - https://docs.aws.amazon.com/autoscaling/ec2/userguide/key-policy-requirements-EBS-encryption.html
Incorrect options:
In Account A, create an encrypted AMI from the unencrypted version with AWS managed key. Modify the key policy to give permissions to Account B for creating a grant. Share the encrypted AMI with Account B
In Account A, create an encrypted AMI from the unencrypted version and specify the KMS key in the copy action. Modify permissions on the AMI to be accessible from Account B
In Account A, create an encrypted AMI from the unencrypted version and encrypt the associated EBS snapshots with it. Specify the KMS key in the copy action. Share the encrypted AMI with Account B
These three options contradict the explanation provided above, so these options are incorrect.
References:
https://docs.aws.amazon.com/autoscaling/ec2/userguide/key-policy-requirements-EBS-encryption.html
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/sharingamis-explicit.html
Explanation
Correct options:
In Account A, create an encrypted AMI from the unencrypted version and specify the KMS key in the copy action. Modify the key policy to give permissions to Account B for creating a grant. Share the encrypted AMI with Account B
In Account B, create a KMS grant that delegates permissions to the service-linked role attached to the Auto Scaling group
As per the security policy of the company, encrypt the unencrypted AMI using the KMS key. The encrypted snapshots must be encrypted with a KMS key. You can’t share AMIs that are backed by snapshots that are encrypted with the default AWS-managed key.
Amazon EC2 Auto Scaling uses service-linked roles to delegate permissions to other AWS services. Amazon EC2 Auto Scaling service-linked roles are predefined and include permissions that Amazon EC2 Auto Scaling requires to call other AWS services on your behalf. The predefined permissions also include access to your AWS-managed keys. However, they do not include access to your customer-managed keys, allowing you to maintain full control over these keys.
If you create a customer-managed key in a different account than the Auto Scaling group, you must use a grant in combination with the key policy to allow cross-account access to the key. This is a two-step process (refer to the image attached)
The first policy allows Account A to give an IAM user or role in the specified Account B permission to create a grant for the key. However, this does not by itself give any users access to the key.
Then, from Account B which contains the Auto Scaling group, create a grant that delegates the relevant permissions to the appropriate service-linked role. The
Grantee Principalelement of the grant is the ARN of the appropriate service-linked role. Thekey-idis the ARN of the key.
Key policy sections that allow cross-account access to the customer-managed key: via - https://docs.aws.amazon.com/autoscaling/ec2/userguide/key-policy-requirements-EBS-encryption.html
Incorrect options:
In Account A, create an encrypted AMI from the unencrypted version with AWS managed key. Modify the key policy to give permissions to Account B for creating a grant. Share the encrypted AMI with Account B
In Account A, create an encrypted AMI from the unencrypted version and specify the KMS key in the copy action. Modify permissions on the AMI to be accessible from Account B
In Account A, create an encrypted AMI from the unencrypted version and encrypt the associated EBS snapshots with it. Specify the KMS key in the copy action. Share the encrypted AMI with Account B
These three options contradict the explanation provided above, so these options are incorrect.
References:
https://docs.aws.amazon.com/autoscaling/ec2/userguide/key-policy-requirements-EBS-encryption.html
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/sharingamis-explicit.html
Question 2 Single Choice
A company uses an AWS CodePipeline pipeline to deploy updates to the API several times a month. As part of this process, the DevOps team exports the JavaScript SDK for the API from the API Gateway console and uploads it to an Amazon S3 bucket, which is being used as an origin for an Amazon CloudFront distribution. Web clients access the SDK through the CloudFront distribution's endpoint. The goal is to have an automated solution that ensures the latest SDK is always available to clients whenever there's a new API deployment.
As an AWS Certified DevOps Engineer - Professional, what solution will you suggest?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Set up a CodePipeline action that runs immediately after the API deployment stage. Configure this action to invoke an AWS Lambda function. The Lambda function will then download the SDK from API Gateway, upload it to the S3 bucket, and create a CloudFront invalidation for the SDK path
AWS CodePipeline is a fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates. By creating a CodePipeline action with an AWS Lambda function immediately after the API deployment stage, the DevOps team can automate the process of downloading the SDK from API Gateway and uploading it to the S3 bucket. Additionally, the Lambda function can create a CloudFront invalidation for the SDK path, ensuring that web clients get the latest SDK without any caching issues.
Incorrect options:
Set up an Amazon EventBridge rule that reacts to CreateDeployment events from aws.apigateway. Configure this rule to leverage the CodePipeline integration with API Gateway to export the SDK to Amazon S3. Trigger another action that calls the S3 API to invalidate the cache for the SDK path
Set up a CodePipeline action that runs immediately after the API deployment stage. Configure this action to leverage the CodePipeline integration with API Gateway to export the SDK to Amazon S3. Trigger another action that calls the S3 API to invalidate the cache for the SDK path
You cannot use any S3 API to invalidate the CloudFront cache, so both of these options are incorrect.
Set up an Amazon EventBridge rule on a schedule that is invoked every 5 minutes. Configure this rule to invoke an AWS Lambda function. The Lambda function will then download the SDK from API Gateway, upload it to the S3 bucket, and create a CloudFront invalidation for the SDK path - It is wasteful to invoke an EventBridge rule every 5 minutes to invalidate the CloudFront cache. You should only invalidate the cache when the API has actually been updated.
References:
https://docs.aws.amazon.com/apigateway/latest/developerguide/how-to-deploy-api.html
Explanation
Correct option:
Set up a CodePipeline action that runs immediately after the API deployment stage. Configure this action to invoke an AWS Lambda function. The Lambda function will then download the SDK from API Gateway, upload it to the S3 bucket, and create a CloudFront invalidation for the SDK path
AWS CodePipeline is a fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates. By creating a CodePipeline action with an AWS Lambda function immediately after the API deployment stage, the DevOps team can automate the process of downloading the SDK from API Gateway and uploading it to the S3 bucket. Additionally, the Lambda function can create a CloudFront invalidation for the SDK path, ensuring that web clients get the latest SDK without any caching issues.
Incorrect options:
Set up an Amazon EventBridge rule that reacts to CreateDeployment events from aws.apigateway. Configure this rule to leverage the CodePipeline integration with API Gateway to export the SDK to Amazon S3. Trigger another action that calls the S3 API to invalidate the cache for the SDK path
Set up a CodePipeline action that runs immediately after the API deployment stage. Configure this action to leverage the CodePipeline integration with API Gateway to export the SDK to Amazon S3. Trigger another action that calls the S3 API to invalidate the cache for the SDK path
You cannot use any S3 API to invalidate the CloudFront cache, so both of these options are incorrect.
Set up an Amazon EventBridge rule on a schedule that is invoked every 5 minutes. Configure this rule to invoke an AWS Lambda function. The Lambda function will then download the SDK from API Gateway, upload it to the S3 bucket, and create a CloudFront invalidation for the SDK path - It is wasteful to invoke an EventBridge rule every 5 minutes to invalidate the CloudFront cache. You should only invalidate the cache when the API has actually been updated.
References:
https://docs.aws.amazon.com/apigateway/latest/developerguide/how-to-deploy-api.html
Question 3 Single Choice
A production support team manages a web application running on a fleet of Amazon EC2 instances configured with an Application Load balancer (ALB). The instances run in an EC2 Auto Scaling group across multiple Availability Zones. A critical bug fix has to be deployed to the production application. The team needs a deployment strategy that can:
a) Create another fleet of instances with the same capacity and configuration as the original one. b) Continue access to the original application without a downtime c) Transition the traffic to the new fleet when the deployment is fully done. The production test team has requested a two-hour window to complete thorough testing on the new fleet of instances. d) Terminate the original fleet automatically once the test window expires.
As a DevOps engineer, which deployment solution will you choose to cater to all the given requirements?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use AWS CodeDeploy with a deployment type configured to Blue/Green deployment configuration. To terminate the original fleet after two hours, change the deployment settings of the Blue/Green deployment. Set Original instances value to Terminate the original instances in the deployment group and choose a waiting period of two hours
Traditional deployments with in-place upgrades make it difficult to validate your new application version in a production deployment while also continuing to run the earlier version of the application. Blue/Green deployments provide a level of isolation between your blue and green application environments. This helps ensure spinning up a parallel green environment does not affect the resources underpinning your blue environment. This isolation reduces your deployment risk.
After you deploy the green environment, you have the opportunity to validate it. You might do that with test traffic before sending production traffic to the green environment, or by using a very small fraction of production traffic, to better reflect real user traffic. This is called canary analysis or canary testing. If you discover the green environment is not operating as expected, there is no impact on the blue environment. You can route traffic back to it, minimizing impaired operation or downtime and limiting the blast radius of impact.
This ability to simply roll traffic back to the operational environment is a key benefit of Blue/Green deployments. You can roll back to the blue environment at any time during the deployment process. Impaired operation or downtime is minimized because the impact is limited to the window of time between green environment issue detection and the shift of traffic back to the blue environment. Additionally, the impact is limited to the portion of traffic going to the green environment, not all traffic. If the blast radius of deployment errors is reduced, so is the overall deployment risk.
In AWS CodeDeploy Blue/Green deployment type, for deployment groups that contain more than one instance, the overall deployment succeeds if the application revision is deployed to all of the instances. The exception to this rule is that if deployment to the last instance fails, the overall deployment still succeeds. This is because CodeDeploy allows only one instance at a time to be taken offline with the CodeDeployDefault.OneAtATime configuration (If you don't specify a deployment configuration, CodeDeploy uses the CodeDeployDefault.OneAtATime deployment configuration).
If you choose Terminate the original instances in the deployment group: After traffic is rerouted to the replacement environment, the instances that were deregistered from the load balancer are terminated following the wait period you specify.
Blue/Green deployment example: 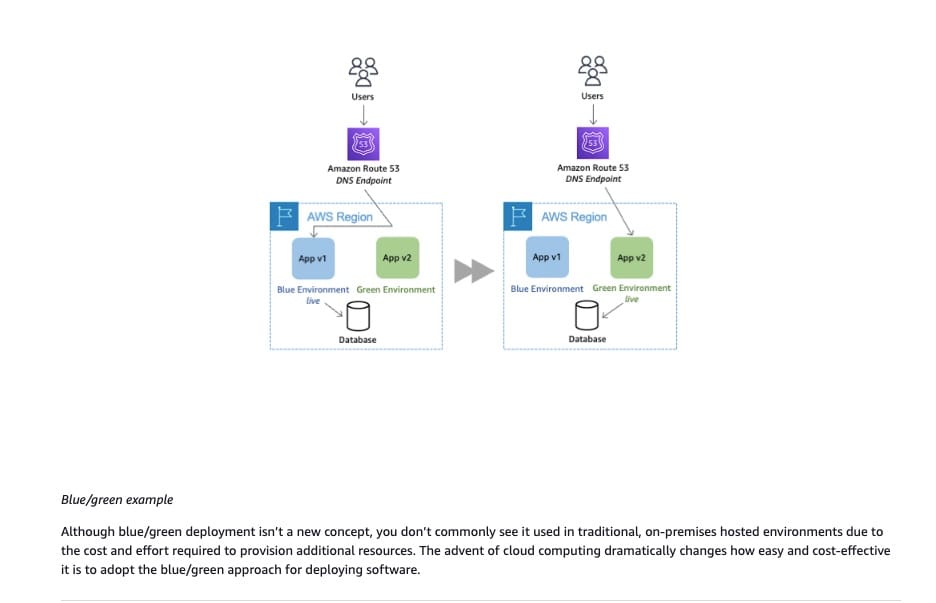 via - https://docs.aws.amazon.com/whitepapers/latest/blue-green-deployments/introduction.html
via - https://docs.aws.amazon.com/whitepapers/latest/blue-green-deployments/introduction.html
Incorrect options:
Configure AWS Elastic Beanstalk to perform a Blue/Green deployment. This will create a new environment different from the original environment to continue serving the production traffic. Terminate the original environment after two hours and confirming the DNS changes of the new environment have propagated correctly
Configure AWS Elastic Beanstalk to use rolling deployment policy. Elastic Beanstalk splits the environment's Amazon EC2 instances into batches and deploys the new version of the application to one batch at a time. Production traffic is served unaffected. Use rolling restarts to restart the proxy and application servers running on your environment's instances without downtime
These two options use AWS Elastic Beanstalk, which creates a new environment and not a new fleet of EC2 instances, as needed in the use case. Hence, these are incorrect.
Use AWS CodeDeploy with a deployment type configured to Blue/Green deployment configuration. To terminate the original fleet after two hours, change the deployment settings of the Blue/Green deployment. Set Original instances value to Terminate the original instances in the deployment group and choose a waiting period of two hours. Choose OneAtATime Deployment configuration setting to deregister the original fleet of instances one at a time to provide increased test time for the production team - Deregistering the original fleet of instances one at a time is not possible. After traffic is successfully routed to the replacement environment, instances in the original environment are deregistered all at once no matter which deployment configuration is selected.
References:
https://docs.aws.amazon.com/codedeploy/latest/userguide/deployment-configurations.html
https://docs.aws.amazon.com/whitepapers/latest/blue-green-deployments/introduction.html
https://docs.aws.amazon.com/codedeploy/latest/userguide/deployment-groups-create-blue-green.html
https://docs.aws.amazon.com/codedeploy/latest/userguide/deployment-configurations.html
Explanation
Correct option:
Use AWS CodeDeploy with a deployment type configured to Blue/Green deployment configuration. To terminate the original fleet after two hours, change the deployment settings of the Blue/Green deployment. Set Original instances value to Terminate the original instances in the deployment group and choose a waiting period of two hours
Traditional deployments with in-place upgrades make it difficult to validate your new application version in a production deployment while also continuing to run the earlier version of the application. Blue/Green deployments provide a level of isolation between your blue and green application environments. This helps ensure spinning up a parallel green environment does not affect the resources underpinning your blue environment. This isolation reduces your deployment risk.
After you deploy the green environment, you have the opportunity to validate it. You might do that with test traffic before sending production traffic to the green environment, or by using a very small fraction of production traffic, to better reflect real user traffic. This is called canary analysis or canary testing. If you discover the green environment is not operating as expected, there is no impact on the blue environment. You can route traffic back to it, minimizing impaired operation or downtime and limiting the blast radius of impact.
This ability to simply roll traffic back to the operational environment is a key benefit of Blue/Green deployments. You can roll back to the blue environment at any time during the deployment process. Impaired operation or downtime is minimized because the impact is limited to the window of time between green environment issue detection and the shift of traffic back to the blue environment. Additionally, the impact is limited to the portion of traffic going to the green environment, not all traffic. If the blast radius of deployment errors is reduced, so is the overall deployment risk.
In AWS CodeDeploy Blue/Green deployment type, for deployment groups that contain more than one instance, the overall deployment succeeds if the application revision is deployed to all of the instances. The exception to this rule is that if deployment to the last instance fails, the overall deployment still succeeds. This is because CodeDeploy allows only one instance at a time to be taken offline with the CodeDeployDefault.OneAtATime configuration (If you don't specify a deployment configuration, CodeDeploy uses the CodeDeployDefault.OneAtATime deployment configuration).
If you choose Terminate the original instances in the deployment group: After traffic is rerouted to the replacement environment, the instances that were deregistered from the load balancer are terminated following the wait period you specify.
Blue/Green deployment example: via - https://docs.aws.amazon.com/whitepapers/latest/blue-green-deployments/introduction.html
Incorrect options:
Configure AWS Elastic Beanstalk to perform a Blue/Green deployment. This will create a new environment different from the original environment to continue serving the production traffic. Terminate the original environment after two hours and confirming the DNS changes of the new environment have propagated correctly
Configure AWS Elastic Beanstalk to use rolling deployment policy. Elastic Beanstalk splits the environment's Amazon EC2 instances into batches and deploys the new version of the application to one batch at a time. Production traffic is served unaffected. Use rolling restarts to restart the proxy and application servers running on your environment's instances without downtime
These two options use AWS Elastic Beanstalk, which creates a new environment and not a new fleet of EC2 instances, as needed in the use case. Hence, these are incorrect.
Use AWS CodeDeploy with a deployment type configured to Blue/Green deployment configuration. To terminate the original fleet after two hours, change the deployment settings of the Blue/Green deployment. Set Original instances value to Terminate the original instances in the deployment group and choose a waiting period of two hours. Choose OneAtATime Deployment configuration setting to deregister the original fleet of instances one at a time to provide increased test time for the production team - Deregistering the original fleet of instances one at a time is not possible. After traffic is successfully routed to the replacement environment, instances in the original environment are deregistered all at once no matter which deployment configuration is selected.
References:
https://docs.aws.amazon.com/codedeploy/latest/userguide/deployment-configurations.html
https://docs.aws.amazon.com/whitepapers/latest/blue-green-deployments/introduction.html
https://docs.aws.amazon.com/codedeploy/latest/userguide/deployment-groups-create-blue-green.html
https://docs.aws.amazon.com/codedeploy/latest/userguide/deployment-configurations.html
Question 4 Single Choice
In a multinational company, various AWS accounts are efficiently managed using AWS Control Tower. The company operates both internal and public applications across its infrastructure. To streamline operations, each application team is assigned a dedicated AWS account responsible for hosting their respective applications. These accounts are consolidated under an organization in AWS Organizations. Additionally, a specific AWS Control Tower member account acts as a centralized DevOps hub, offering Continuous Integration/Continuous Deployment (CI/CD) pipelines that application teams utilize to deploy applications to their designated AWS accounts. A specialized IAM role for deployment is available within this central DevOps account.
Currently, a particular application team is facing challenges while attempting to deploy its application to an Amazon Elastic Kubernetes Service (Amazon EKS) cluster situated in their application-specific AWS account. They have an existing IAM role for deployment within the application AWS account. The deployment process relies on an AWS CodeBuild project, configured within the centralized DevOps account, and utilizes an IAM service role for CodeBuild. However, the deployment process is encountering an Unauthorized error when trying to establish connections to the cross-account EKS cluster from the CodeBuild environment.
To resolve this error and facilitate a successful deployment, what solution would you recommend?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Establish a trust relationship in the application account's deployment IAM role for the centralized DevOps account, allowing the sts:AssumeRole action. Also, grant the application account's deployment IAM role the necessary access to the EKS cluster. Additionally, configure the EKS cluster aws-auth ConfigMap to map the role to the appropriate system permissions
By configuring a trust relationship in the application account's deployment IAM role for the centralized DevOps account, using the sts:AssumeRole action, CodeBuild in the centralized DevOps account will be allowed to assume the IAM role in the application account. This will enable CodeBuild to access the EKS cluster in the application account. Additionally, granting the application account's deployment IAM role the necessary access to the EKS cluster ensures that it has the required permissions to perform the deployment tasks. Finally, configuring the EKS cluster aws-auth ConfigMap to map the role to the appropriate system permissions ensures that the IAM role has the required permissions within the EKS cluster.
 via - https://docs.aws.amazon.com/STS/latest/APIReference/API_AssumeRole.html
via - https://docs.aws.amazon.com/STS/latest/APIReference/API_AssumeRole.html
Incorrect options:
Establish a trust relationship in the application account's deployment IAM role for the centralized DevOps account, allowing the sts:AssumeRoleWithSAML action. Also, grant the centralized DevOps account's deployment IAM role the required access to CodeBuild and the EKS cluster
Establish a trust relationship in the centralized DevOps account's deployment IAM role for the application account, allowing the sts:AssumeRoleWithSAML action. Also, grant the centralized DevOps account's deployment IAM role the required access to CodeBuild
AssumeRoleWithSAML is used for federation scenarios involving SAML-based identity providers, which is not relevant to the given use case, so both these options are incorrect.
Establish a trust relationship in the centralized DevOps account for the application account's deployment IAM role, allowing the sts:AssumeRole action. Also, grant the application account's deployment IAM role the necessary access to the EKS cluster. Additionally, configure the EKS cluster aws-auth ConfigMap to map the role to the appropriate system permissions
You need to configure a trust relationship in the application account's deployment IAM role for the centralized DevOps account, so that CodeBuild in the centralized DevOps account can assume the IAM role in the application account, by using the sts:AssumeRole action. However, this option sets up the trust relationship in the reverse direction, so it's incorrect.
References:
https://docs.aws.amazon.com/STS/latest/APIReference/API_AssumeRole.html
https://docs.aws.amazon.com/eks/latest/userguide/add-user-role.html
https://docs.aws.amazon.com/STS/latest/APIReference/API_AssumeRoleWithSAML.html
Explanation
Correct option:
Establish a trust relationship in the application account's deployment IAM role for the centralized DevOps account, allowing the sts:AssumeRole action. Also, grant the application account's deployment IAM role the necessary access to the EKS cluster. Additionally, configure the EKS cluster aws-auth ConfigMap to map the role to the appropriate system permissions
By configuring a trust relationship in the application account's deployment IAM role for the centralized DevOps account, using the sts:AssumeRole action, CodeBuild in the centralized DevOps account will be allowed to assume the IAM role in the application account. This will enable CodeBuild to access the EKS cluster in the application account. Additionally, granting the application account's deployment IAM role the necessary access to the EKS cluster ensures that it has the required permissions to perform the deployment tasks. Finally, configuring the EKS cluster aws-auth ConfigMap to map the role to the appropriate system permissions ensures that the IAM role has the required permissions within the EKS cluster.
via - https://docs.aws.amazon.com/STS/latest/APIReference/API_AssumeRole.html
Incorrect options:
Establish a trust relationship in the application account's deployment IAM role for the centralized DevOps account, allowing the sts:AssumeRoleWithSAML action. Also, grant the centralized DevOps account's deployment IAM role the required access to CodeBuild and the EKS cluster
Establish a trust relationship in the centralized DevOps account's deployment IAM role for the application account, allowing the sts:AssumeRoleWithSAML action. Also, grant the centralized DevOps account's deployment IAM role the required access to CodeBuild
AssumeRoleWithSAML is used for federation scenarios involving SAML-based identity providers, which is not relevant to the given use case, so both these options are incorrect.
Establish a trust relationship in the centralized DevOps account for the application account's deployment IAM role, allowing the sts:AssumeRole action. Also, grant the application account's deployment IAM role the necessary access to the EKS cluster. Additionally, configure the EKS cluster aws-auth ConfigMap to map the role to the appropriate system permissions
You need to configure a trust relationship in the application account's deployment IAM role for the centralized DevOps account, so that CodeBuild in the centralized DevOps account can assume the IAM role in the application account, by using the sts:AssumeRole action. However, this option sets up the trust relationship in the reverse direction, so it's incorrect.
References:
https://docs.aws.amazon.com/STS/latest/APIReference/API_AssumeRole.html
https://docs.aws.amazon.com/eks/latest/userguide/add-user-role.html
https://docs.aws.amazon.com/STS/latest/APIReference/API_AssumeRoleWithSAML.html
Question 5 Single Choice
An e-commerce company is deploying its flagship application on Amazon EC2 instances. The DevOps team at the company needs a solution to query both the application logs as well as the AWS account API activity.
As an AWS Certified DevOps Engineer - Professional, what solution will you recommend to meet these requirements?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Set up AWS CloudTrail to deliver the API logs to CloudWatch Logs. Leverage the Amazon CloudWatch Agent to deliver logs from the EC2 instances to Amazon CloudWatch Logs. Utilize the CloudWatch Logs Insights to query both sets of logs
CloudTrail is enabled by default for your AWS account. You can use Event history in the CloudTrail console to view, search, download, archive, analyze, and respond to account activity across your AWS infrastructure. This includes activity made through the AWS Management Console, AWS Command Line Interface, and AWS SDKs and APIs. For an ongoing record of events in your AWS account, you can create a trail. A trail enables CloudTrail to deliver log files to an Amazon S3 bucket. By default, when you create a trail in the console, the trail applies to all AWS Regions. The trail logs events from all Regions in the AWS partition and delivers the log files to the Amazon S3 bucket that you specify. Additionally, you can configure other AWS services to further analyze and act upon the event data collected in CloudTrail logs.
You can also configure CloudTrail with CloudWatch Logs to monitor your trail API logs and be notified when specific activity occurs. When you configure your trail to send events to CloudWatch Logs, CloudTrail sends only the events that match your trail settings. For example, if you configure your trail to log data events only, your trail sends data events only to your CloudWatch Logs log group. CloudTrail supports sending data, Insights, and management events to CloudWatch Logs.
You can collect metrics and logs from Amazon EC2 instances and on-premises servers with the CloudWatch agent. You can store and view the metrics that you collect with the CloudWatch agent in CloudWatch just as you can with any other CloudWatch metrics. The default namespace for metrics collected by the CloudWatch agent is CWAgent, although you can specify a different namespace when you configure the agent. The logs collected by the unified CloudWatch agent are processed and stored in Amazon CloudWatch Logs
For the given use case, you can have both AWS CloudTrail as well as the Amazon CloudWatch Agent deliver the respective logs to CloudWatch Logs. You can then use the CloudWatch Logs Insights to query both sets of logs.
Incorrect options:
Set up AWS CloudTrail to deliver the API logs to Amazon S3. Leverage the Amazon CloudWatch Agent to deliver logs from the EC2 instances to Amazon S3. Utilize Amazon Athena to query both sets of logs - You cannot use the Amazon CloudWatch Agent to deliver logs from the EC2 instances to Amazon S3. So, this option is incorrect.
Set up AWS CloudTrail to deliver the API logs to Kinesis Data Streams. Leverage the Amazon CloudWatch Agent to deliver logs from the EC2 instances to Kinesis Data Streams. Direct both the Kinesis Data Streams to direct the stream output to Kinesis Data Analytics for running near-real-time queries on both sets of logs - You cannot deliver the API logs from AWS CloudTrail to Kinesis Data Streams. Similarly, you cannot have the Amazon CloudWatch Agent deliver logs from the EC2 instances to Kinesis Data Streams. So, both these options are incorrect.
Set up AWS CloudTrail to deliver the API logs to Amazon S3. Leverage the Amazon CloudWatch Agent to deliver logs from the EC2 instances to Amazon CloudWatch Logs. Utilize Amazon Athena to query both sets of logs - You cannot use Amazon Athena to query logs published to Amazon CloudWatch Logs, so this option is incorrect.
References:
https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-getting-started.html
Explanation
Correct option:
Set up AWS CloudTrail to deliver the API logs to CloudWatch Logs. Leverage the Amazon CloudWatch Agent to deliver logs from the EC2 instances to Amazon CloudWatch Logs. Utilize the CloudWatch Logs Insights to query both sets of logs
CloudTrail is enabled by default for your AWS account. You can use Event history in the CloudTrail console to view, search, download, archive, analyze, and respond to account activity across your AWS infrastructure. This includes activity made through the AWS Management Console, AWS Command Line Interface, and AWS SDKs and APIs. For an ongoing record of events in your AWS account, you can create a trail. A trail enables CloudTrail to deliver log files to an Amazon S3 bucket. By default, when you create a trail in the console, the trail applies to all AWS Regions. The trail logs events from all Regions in the AWS partition and delivers the log files to the Amazon S3 bucket that you specify. Additionally, you can configure other AWS services to further analyze and act upon the event data collected in CloudTrail logs.
You can also configure CloudTrail with CloudWatch Logs to monitor your trail API logs and be notified when specific activity occurs. When you configure your trail to send events to CloudWatch Logs, CloudTrail sends only the events that match your trail settings. For example, if you configure your trail to log data events only, your trail sends data events only to your CloudWatch Logs log group. CloudTrail supports sending data, Insights, and management events to CloudWatch Logs.
You can collect metrics and logs from Amazon EC2 instances and on-premises servers with the CloudWatch agent. You can store and view the metrics that you collect with the CloudWatch agent in CloudWatch just as you can with any other CloudWatch metrics. The default namespace for metrics collected by the CloudWatch agent is CWAgent, although you can specify a different namespace when you configure the agent. The logs collected by the unified CloudWatch agent are processed and stored in Amazon CloudWatch Logs
For the given use case, you can have both AWS CloudTrail as well as the Amazon CloudWatch Agent deliver the respective logs to CloudWatch Logs. You can then use the CloudWatch Logs Insights to query both sets of logs.
Incorrect options:
Set up AWS CloudTrail to deliver the API logs to Amazon S3. Leverage the Amazon CloudWatch Agent to deliver logs from the EC2 instances to Amazon S3. Utilize Amazon Athena to query both sets of logs - You cannot use the Amazon CloudWatch Agent to deliver logs from the EC2 instances to Amazon S3. So, this option is incorrect.
Set up AWS CloudTrail to deliver the API logs to Kinesis Data Streams. Leverage the Amazon CloudWatch Agent to deliver logs from the EC2 instances to Kinesis Data Streams. Direct both the Kinesis Data Streams to direct the stream output to Kinesis Data Analytics for running near-real-time queries on both sets of logs - You cannot deliver the API logs from AWS CloudTrail to Kinesis Data Streams. Similarly, you cannot have the Amazon CloudWatch Agent deliver logs from the EC2 instances to Kinesis Data Streams. So, both these options are incorrect.
Set up AWS CloudTrail to deliver the API logs to Amazon S3. Leverage the Amazon CloudWatch Agent to deliver logs from the EC2 instances to Amazon CloudWatch Logs. Utilize Amazon Athena to query both sets of logs - You cannot use Amazon Athena to query logs published to Amazon CloudWatch Logs, so this option is incorrect.
References:
https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-getting-started.html
Question 6 Multiple Choice
For deployments across AWS accounts, an e-commerce company has decided to use AWS CodePipeline to deploy an AWS CloudFormation stack in an AWS account (account A) to a different AWS account (account B).
What combination of steps will you take to configure this requirement? (Select three)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
In account A, create a customer-managed AWS KMS key that grants usage permissions to account A's CodePipeline service role and account B. Also, create an Amazon Simple Storage Service (Amazon S3) bucket with a bucket policy that grants account B access to the bucket
In account B, create a cross-account IAM role. In account A, add the AssumeRole permission to account A's CodePipeline service role to allow it to assume the cross-account role in account B
In account B, create a service role for the CloudFormation stack that includes the required permissions for the services deployed by the stack. In account A, update the CodePipeline configuration to include the resources associated with account B
Complete list of steps for configuring the requirement:  via - https://aws.amazon.com/premiumsupport/knowledge-center/codepipeline-deploy-cloudformation/
via - https://aws.amazon.com/premiumsupport/knowledge-center/codepipeline-deploy-cloudformation/
Incorrect options:
In account A, create a customer-managed AWS KMS key that grants usage permissions to account A's CodePipeline service role and account B. In account B, create an Amazon Simple Storage Service (Amazon S3) bucket with a bucket policy that grants account A access to the bucket
In account A, create a service role for the CloudFormation stack that includes the required permissions for the services deployed by the stack. In account B, update the CodePipeline configuration to include the resources associated with account A
In account B, add the AssumeRole permission to account A's CodePipeline service role to allow it to assume the cross-account role in account A
These three options contradict the explanation provided above, so these are incorrect.
Reference:
https://aws.amazon.com/premiumsupport/knowledge-center/codepipeline-deploy-cloudformation/
Explanation
Correct options:
In account A, create a customer-managed AWS KMS key that grants usage permissions to account A's CodePipeline service role and account B. Also, create an Amazon Simple Storage Service (Amazon S3) bucket with a bucket policy that grants account B access to the bucket
In account B, create a cross-account IAM role. In account A, add the AssumeRole permission to account A's CodePipeline service role to allow it to assume the cross-account role in account B
In account B, create a service role for the CloudFormation stack that includes the required permissions for the services deployed by the stack. In account A, update the CodePipeline configuration to include the resources associated with account B
Complete list of steps for configuring the requirement: via - https://aws.amazon.com/premiumsupport/knowledge-center/codepipeline-deploy-cloudformation/
Incorrect options:
In account A, create a customer-managed AWS KMS key that grants usage permissions to account A's CodePipeline service role and account B. In account B, create an Amazon Simple Storage Service (Amazon S3) bucket with a bucket policy that grants account A access to the bucket
In account A, create a service role for the CloudFormation stack that includes the required permissions for the services deployed by the stack. In account B, update the CodePipeline configuration to include the resources associated with account A
In account B, add the AssumeRole permission to account A's CodePipeline service role to allow it to assume the cross-account role in account A
These three options contradict the explanation provided above, so these are incorrect.
Reference:
https://aws.amazon.com/premiumsupport/knowledge-center/codepipeline-deploy-cloudformation/
Question 7 Multiple Choice
An AWS managed cloudformation-stack-drift-detection-check rule is defined in AWS Config for drift detection in AWS CloudFormation resources. The DevOps team is facing two issues:
a) How to detect drifts of Cloudformation custom resources b) Drift status of the stack shows as IN_SYNC in the CloudFormation console, the following is the drift detection error - 'While AWS CloudFormation failed to detect drift, defaulting to NON_COMPLIANT. Re-evaluate the rule and try again. If the problem persists contact AWS CloudFormation support'
As a DevOps Engineer, which steps will you combine to fix the aforementioned issues? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
The cloudformation-stack-drift-detection-check rule checks if the actual configuration of a Cloud Formation stack differs, or has drifted, from the expected configuration. A stack is considered to have drifted if one or more of its resources differ from their expected configuration. The rule and the stack are COMPLIANT when the stack drift status is IN_SYNC. The rule is NON_COMPLIANT if the stack drift status is DRIFTED.
CloudFormation offers a drift detection feature to detect unmanaged configuration changes to stacks and resources. This will let you take corrective action to put the stack resources back in sync with their definitions in the stack template. To return a resource to compliance, the resource definition changes can be reverted directly.
AWS Config rule depends on the availability of DetectStackDrift action of CloudFormation API. AWS Config defaults the rule to NON_COMPLIANT when throttling occurs
AWS Config rule depends on the availability of DetectStackDrift. You receive a throttling or "Rate Exceeded" error because AWS Config defaults the rule to NON_COMPLIANT when throttling occurs.
Resolve the error resulting from the availability of DetectStackDrift:  via - https://repost.aws/knowledge-center/config-cloudformation-drift-detection
via - https://repost.aws/knowledge-center/config-cloudformation-drift-detection
AWS CloudFormation does not support drift detection of custom resources
AWS CloudFormation supports resource import and drift detection operations for only supported resource types. Custom resource types are not currently supported.
Incorrect options:
You receive the error when the AWS Identity and Access Management (IAM) role for the required cloudformationRoleArn parameter doesn't have sufficient service permissions - Any issues with permissions will not result in the shown error. Permissions error looks something like this: "Your stack drift detection operation for the specific stack has failed. Check your existing AWS CloudFormation role permissions and add the missing permissions."
This error is a false positive and can be ignored for this scenario - This option just acts as a distractor.
AWS CloudFormation only determines drift for property values that are explicitly set. Explicitly set the property values for your custom resource to be included in drift - It is true that CloudFormation only determines drift for property values that are explicitly set, either through the stack template or by specifying template parameters. However, custom resources are not currently supported for drift.
References:
[[https://repost.aws/questions/QUolH-EWnHRNGDbnUiu3chXw/how-to-detect-drifts-of-cloudformation-custom-resource](https://repost.aws/questions/QUolH-EWnHRNGDbnUiu3chXw/how-to-detect-drifts-of-cloudformation-custom-resource)]
https://repost.aws/knowledge-center/config-cloudformation-drift-detection
Explanation
Correct options:
The cloudformation-stack-drift-detection-check rule checks if the actual configuration of a Cloud Formation stack differs, or has drifted, from the expected configuration. A stack is considered to have drifted if one or more of its resources differ from their expected configuration. The rule and the stack are COMPLIANT when the stack drift status is IN_SYNC. The rule is NON_COMPLIANT if the stack drift status is DRIFTED.
CloudFormation offers a drift detection feature to detect unmanaged configuration changes to stacks and resources. This will let you take corrective action to put the stack resources back in sync with their definitions in the stack template. To return a resource to compliance, the resource definition changes can be reverted directly.
AWS Config rule depends on the availability of DetectStackDrift action of CloudFormation API. AWS Config defaults the rule to NON_COMPLIANT when throttling occurs
AWS Config rule depends on the availability of DetectStackDrift. You receive a throttling or "Rate Exceeded" error because AWS Config defaults the rule to NON_COMPLIANT when throttling occurs.
Resolve the error resulting from the availability of DetectStackDrift: via - https://repost.aws/knowledge-center/config-cloudformation-drift-detection
AWS CloudFormation does not support drift detection of custom resources
AWS CloudFormation supports resource import and drift detection operations for only supported resource types. Custom resource types are not currently supported.
Incorrect options:
You receive the error when the AWS Identity and Access Management (IAM) role for the required cloudformationRoleArn parameter doesn't have sufficient service permissions - Any issues with permissions will not result in the shown error. Permissions error looks something like this: "Your stack drift detection operation for the specific stack has failed. Check your existing AWS CloudFormation role permissions and add the missing permissions."
This error is a false positive and can be ignored for this scenario - This option just acts as a distractor.
AWS CloudFormation only determines drift for property values that are explicitly set. Explicitly set the property values for your custom resource to be included in drift - It is true that CloudFormation only determines drift for property values that are explicitly set, either through the stack template or by specifying template parameters. However, custom resources are not currently supported for drift.
References:
[[https://repost.aws/questions/QUolH-EWnHRNGDbnUiu3chXw/how-to-detect-drifts-of-cloudformation-custom-resource](https://repost.aws/questions/QUolH-EWnHRNGDbnUiu3chXw/how-to-detect-drifts-of-cloudformation-custom-resource)]
https://repost.aws/knowledge-center/config-cloudformation-drift-detection
Question 8 Single Choice
A company hosts all its web applications on Amazon EC2 instances. The company is looking for a security solution that will proactively detect software vulnerabilities and unintended network exposure of the instances. The solution should also include an audit trail of all login activities on the instances.
Which solution will meet these requirements?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Configure Amazon Inspector to detect vulnerabilities on the EC2 instances. Install the Amazon CloudWatch Agent to capture system logs and record them via Amazon CloudWatch Logs. Configure your trail to send log events to CloudWatch Logs
Amazon Inspector is an automated vulnerability management service that continually scans Amazon Elastic Compute Cloud (EC2), AWS Lambda functions, and container workloads for software vulnerabilities and unintended network exposure. To successfully scan Amazon EC2 instances for software vulnerabilities, Amazon Inspector requires that these instances have the SSM agent installed. Amazon Inspector uses SSM Agent to collect application inventory, which can be set up as Amazon Virtual Private Cloud (VPC) endpoints to avoid sending information over the internet.
You can use Amazon CloudWatch Logs to monitor, store, and access your log files from Amazon Elastic Compute Cloud (Amazon EC2) instances, AWS CloudTrail, Route 53, and other sources.
CloudWatch Logs enables you to centralize the logs from all of your systems, applications, and AWS services that you use, in a single, highly scalable service. You can then easily view them, search them for specific error codes or patterns, filter them based on specific fields, or archive them securely for future analysis. CloudWatch Logs enables you to see all of your logs, regardless of their source, as a single and consistent flow of events ordered by time.
Configure CloudTrail with CloudWatch Logs to monitor your trail logs and be notified when specific activity occurs.
How Amazon Inspector Works: 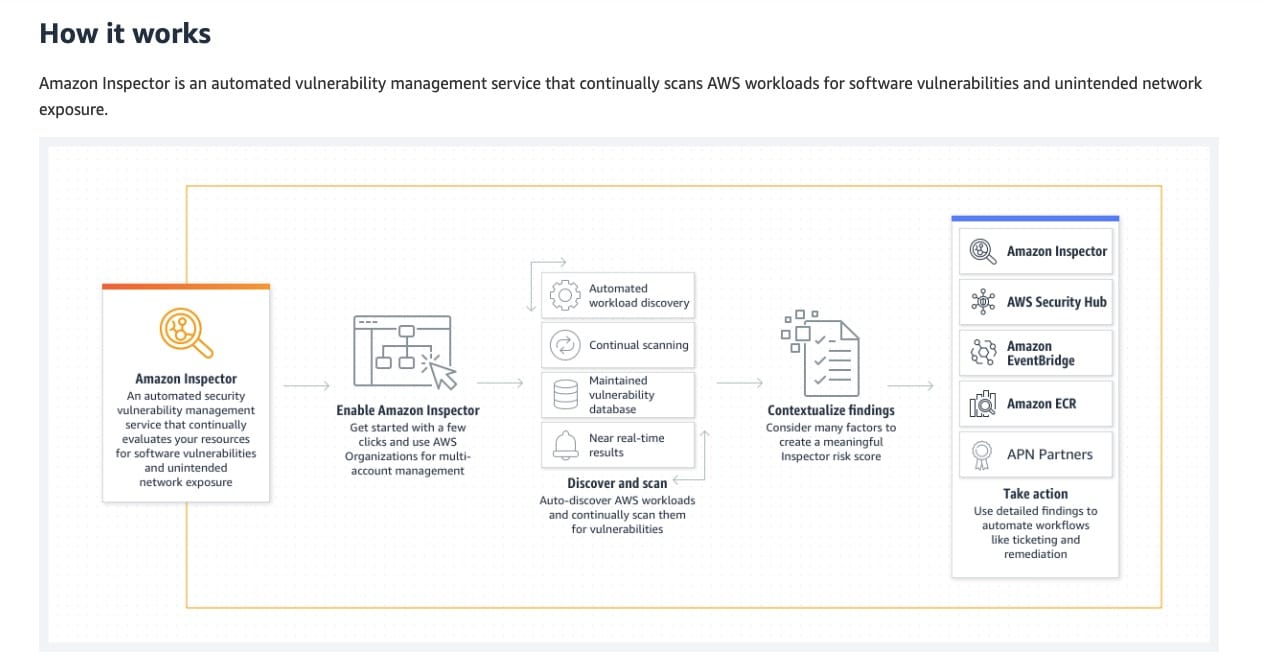 via - https://aws.amazon.com/inspector/
via - https://aws.amazon.com/inspector/
Incorrect options:
Configure AWS Systems Manager's Systems Manager (SSM) agent to collect software vulnerabilities of the Amazon EC2 instances. Configure a Systems Manager Automation runbook to automatically patch the vulnerabilities identified by the SSM agent - SSM agent does not scan or detect vulnerabilities on Amazon EC2 instances.
Configure Amazon ECR image scanning to scan for vulnerabilities on the EC2 instances. Amazon ECR sends an event to Amazon EventBridge when an image scan is completed. Configure CloudTrail to send its trail data to Amazon EventBridge for further processing/notification - Amazon ECR provides basic scanning type which uses the Common Vulnerabilities and Exposures (CVEs) database from the open-source Clair project. It is for container applications alone. Also, ECR image scanning identifies software vulnerabilities only in operating system packages.
Configure Amazon GuardDuty to detect vulnerabilities and threats on the EC2 instances. Integrate with a workflow system to review the findings and trigger an AWS Lambda function to automate the remediation process - Amazon GuardDuty is a threat detection service that continuously monitors for malicious activity and unauthorized behavior to protect your AWS accounts, Amazon Elastic Compute Cloud (EC2) workloads, container applications, Amazon Aurora databases, and data stored in Amazon Simple Storage Service (S3). It is not a vulnerability management service.
References:
https://docs.aws.amazon.com/inspector/v1/userguide/inspector_introduction.html
Explanation
Correct option:
Configure Amazon Inspector to detect vulnerabilities on the EC2 instances. Install the Amazon CloudWatch Agent to capture system logs and record them via Amazon CloudWatch Logs. Configure your trail to send log events to CloudWatch Logs
Amazon Inspector is an automated vulnerability management service that continually scans Amazon Elastic Compute Cloud (EC2), AWS Lambda functions, and container workloads for software vulnerabilities and unintended network exposure. To successfully scan Amazon EC2 instances for software vulnerabilities, Amazon Inspector requires that these instances have the SSM agent installed. Amazon Inspector uses SSM Agent to collect application inventory, which can be set up as Amazon Virtual Private Cloud (VPC) endpoints to avoid sending information over the internet.
You can use Amazon CloudWatch Logs to monitor, store, and access your log files from Amazon Elastic Compute Cloud (Amazon EC2) instances, AWS CloudTrail, Route 53, and other sources.
CloudWatch Logs enables you to centralize the logs from all of your systems, applications, and AWS services that you use, in a single, highly scalable service. You can then easily view them, search them for specific error codes or patterns, filter them based on specific fields, or archive them securely for future analysis. CloudWatch Logs enables you to see all of your logs, regardless of their source, as a single and consistent flow of events ordered by time.
Configure CloudTrail with CloudWatch Logs to monitor your trail logs and be notified when specific activity occurs.
How Amazon Inspector Works: via - https://aws.amazon.com/inspector/
Incorrect options:
Configure AWS Systems Manager's Systems Manager (SSM) agent to collect software vulnerabilities of the Amazon EC2 instances. Configure a Systems Manager Automation runbook to automatically patch the vulnerabilities identified by the SSM agent - SSM agent does not scan or detect vulnerabilities on Amazon EC2 instances.
Configure Amazon ECR image scanning to scan for vulnerabilities on the EC2 instances. Amazon ECR sends an event to Amazon EventBridge when an image scan is completed. Configure CloudTrail to send its trail data to Amazon EventBridge for further processing/notification - Amazon ECR provides basic scanning type which uses the Common Vulnerabilities and Exposures (CVEs) database from the open-source Clair project. It is for container applications alone. Also, ECR image scanning identifies software vulnerabilities only in operating system packages.
Configure Amazon GuardDuty to detect vulnerabilities and threats on the EC2 instances. Integrate with a workflow system to review the findings and trigger an AWS Lambda function to automate the remediation process - Amazon GuardDuty is a threat detection service that continuously monitors for malicious activity and unauthorized behavior to protect your AWS accounts, Amazon Elastic Compute Cloud (EC2) workloads, container applications, Amazon Aurora databases, and data stored in Amazon Simple Storage Service (S3). It is not a vulnerability management service.
References:
https://docs.aws.amazon.com/inspector/v1/userguide/inspector_introduction.html
Question 9 Single Choice
As a security best practice, a company has decided to back up all of its Amazon Elastic Block Store (Amazon EBS) volumes every week. To implement this change, developers are mandated to tag all Amazon EBS volumes with a custom tag. The company runs an automated solution that reads the custom tag having the value of the desired backup frequency as weekly for each EBS volume and then the solution schedules the backup. However, a recent audit report has highlighted the fact that a few EBS volumes were not backed up as expected because of the missing custom tag.
As a DevOps engineer which solution will you choose to enforce backup for all EBS volumes used by an AWS account?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Set up AWS Config in the AWS account. Use a managed rule for Resource Type EC2::Volume that returns a compliance failure if the custom tag is not applied to the EBS volume. Configure a remediation action that uses custom AWS Systems Manager Automation documents (runbooks) to apply the custom tag with predefined backup frequency to all non-compliant EBS volumes
Set up AWS Config in the AWS account that needs the security best practice implemented. You can use the managed rule required-tags to check if your resources have the tags that you specify. For example, you can check whether your Amazon EC2 instances have the CostCenter tag, while also checking if all your RDS instances have one set of Keys tag. Separate multiple values with commas. You can check up to 6 tags at a time. This managed rule is applicable for the EC2::Volume Resource Type.
AWS Config managed rule that checks required-tags:  via - https://docs.aws.amazon.com/config/latest/developerguide/required-tags.html
via - https://docs.aws.amazon.com/config/latest/developerguide/required-tags.html
This managed rule checks for the existence of the custom tag on the EBS volume. When an EBS volume is found to be non-compliant, you can specify a remediation action through a custom AWS Systems Manager Automation document to apply the custom tag with a predefined backup frequency to all non-compliant EBS volumes.
AWS Config rules remediation with automation runbooks architecture: 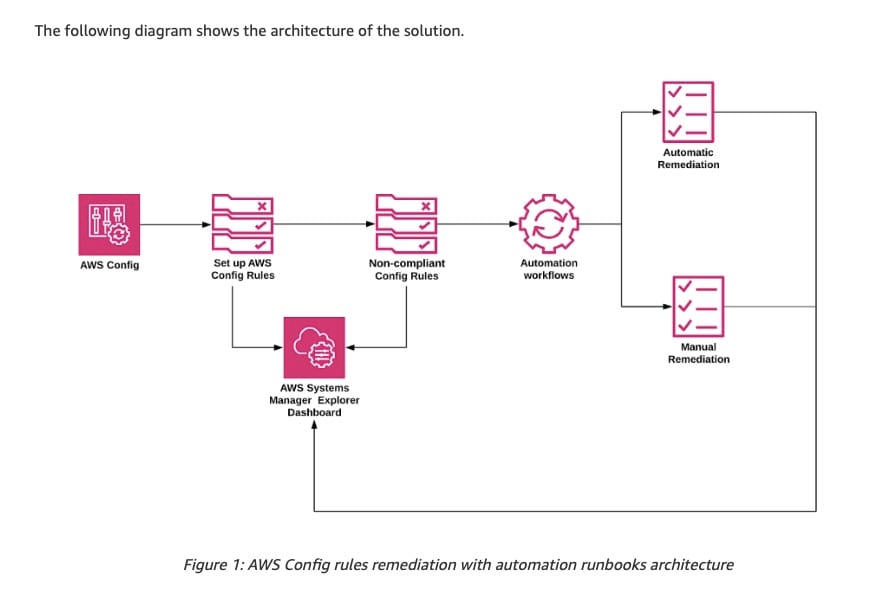 via - https://aws.amazon.com/blogs/mt/remediate-noncompliant-aws-config-rules-with-aws-systems-manager-automation-runbooks/
via - https://aws.amazon.com/blogs/mt/remediate-noncompliant-aws-config-rules-with-aws-systems-manager-automation-runbooks/
Incorrect options:
Set up AWS Config in the AWS account. Use a managed rule for Resource Type EC2::Instance that returns a compliance failure if the custom tag is not applied on the EBS volume attached to the instance. Configure a remediation action that uses a custom AWS Systems Manager Automation documents (runbooks) to apply the custom tag with predefined backup frequency to all non-compliant EBS volumes - In this option, the Resource type is mentioned as AWS::EC2::Instance. This is incorrect since the compliance check has to be done only for the EBS volume and not for the EC2 instance.
Create an Amazon EventBridge rule that responds to an EBS CreateVolume event from AWS CloudTrail logs. Configure a custom AWS Systems Manager Automation runbook to apply the custom tag with the default weekly value. Specify this runbook as the target of the EventBridge rule - This option is incorrect, as it's possible to remove the custom tag post the creation of the EBS volume and this action would still stay undetected. The right solution is to leverage AWS Config to ensure ongoing backup compliance for EBS volumes for the given use case.
Create an Amazon EventBridge rule that responds to an EBS VolumeBackup check event from AWS Trusted Advisor. Configure a custom AWS Systems Manager Automation runbook to apply the custom tag with the default weekly value. Specify this runbook as the target of the EventBridge rule - AWS Trusted Advisor scans your AWS infrastructure, compares with AWS best practices, and provides recommended actions. Remedial actions are not possible with AWS Trusted Advisor.
References:
https://docs.aws.amazon.com/config/latest/developerguide/required-tags.html
Explanation
Correct option:
Set up AWS Config in the AWS account. Use a managed rule for Resource Type EC2::Volume that returns a compliance failure if the custom tag is not applied to the EBS volume. Configure a remediation action that uses custom AWS Systems Manager Automation documents (runbooks) to apply the custom tag with predefined backup frequency to all non-compliant EBS volumes
Set up AWS Config in the AWS account that needs the security best practice implemented. You can use the managed rule required-tags to check if your resources have the tags that you specify. For example, you can check whether your Amazon EC2 instances have the CostCenter tag, while also checking if all your RDS instances have one set of Keys tag. Separate multiple values with commas. You can check up to 6 tags at a time. This managed rule is applicable for the EC2::Volume Resource Type.
AWS Config managed rule that checks required-tags: via - https://docs.aws.amazon.com/config/latest/developerguide/required-tags.html
This managed rule checks for the existence of the custom tag on the EBS volume. When an EBS volume is found to be non-compliant, you can specify a remediation action through a custom AWS Systems Manager Automation document to apply the custom tag with a predefined backup frequency to all non-compliant EBS volumes.
AWS Config rules remediation with automation runbooks architecture: via - https://aws.amazon.com/blogs/mt/remediate-noncompliant-aws-config-rules-with-aws-systems-manager-automation-runbooks/
Incorrect options:
Set up AWS Config in the AWS account. Use a managed rule for Resource Type EC2::Instance that returns a compliance failure if the custom tag is not applied on the EBS volume attached to the instance. Configure a remediation action that uses a custom AWS Systems Manager Automation documents (runbooks) to apply the custom tag with predefined backup frequency to all non-compliant EBS volumes - In this option, the Resource type is mentioned as AWS::EC2::Instance. This is incorrect since the compliance check has to be done only for the EBS volume and not for the EC2 instance.
Create an Amazon EventBridge rule that responds to an EBS CreateVolume event from AWS CloudTrail logs. Configure a custom AWS Systems Manager Automation runbook to apply the custom tag with the default weekly value. Specify this runbook as the target of the EventBridge rule - This option is incorrect, as it's possible to remove the custom tag post the creation of the EBS volume and this action would still stay undetected. The right solution is to leverage AWS Config to ensure ongoing backup compliance for EBS volumes for the given use case.
Create an Amazon EventBridge rule that responds to an EBS VolumeBackup check event from AWS Trusted Advisor. Configure a custom AWS Systems Manager Automation runbook to apply the custom tag with the default weekly value. Specify this runbook as the target of the EventBridge rule - AWS Trusted Advisor scans your AWS infrastructure, compares with AWS best practices, and provides recommended actions. Remedial actions are not possible with AWS Trusted Advisor.
References:
https://docs.aws.amazon.com/config/latest/developerguide/required-tags.html
Question 10 Single Choice
A DevOps Engineer needs to use the AWS CloudFormation stack to deploy an application. But the DevOps Engineer does not have the required permissions to provision the resources specified in the AWS CloudFormation template.
Which solution will allow the DevOps Engineer to deploy the stack while providing the least privileges possible?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Create an AWS CloudFormation service role with required permissions and associate this service role to the stack. Grant the developer iam:PassRole permissions to pass the role to the service. Use this newly created service role during stack deployments
A service role is an AWS Identity and Access Management (IAM) role that allows AWS CloudFormation to make calls to resources in a stack on your behalf. You can specify an IAM role that allows AWS CloudFormation to create, update, or delete your stack resources. By default, AWS CloudFormation uses a temporary session that it generates from your user credentials for stack operations. If you specify a service role, AWS CloudFormation uses that role's credentials.
Use a service role to explicitly specify the actions that AWS CloudFormation can perform, which might not always be the same actions that you or other users can do. For example, you might have administrative privileges, but you can limit AWS CloudFormation access to only Amazon EC2 actions.
When you specify a service role, AWS CloudFormation always uses that role for all operations that are performed on that stack. It is not possible to remove a service role attached to a stack after the stack is created. Other users that have permission to perform operations on this stack will be able to use this role, but they must have the iam:PassRole permission.
To pass a role (and its permissions) to an AWS service, a user must have permission to pass the role to the service. This helps administrators ensure that only approved users can configure a service with a role that grants permissions. To allow a user to pass a role to an AWS service, you must grant PassRole permission to the user's IAM user, role, or group.
 via - https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/using-iam-servicerole.html
via - https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/using-iam-servicerole.html
Incorrect options:
Create an AWS CloudFormation service role with full permissions and associate this service role to the stack. Grant the developer iam:PassRole permissions. Limit the permissions to pass a role based on tags attached to the role using the ResourceTag/key-name condition key - Giving full permissions is against the security best practice that says a role should have the least possible privileges to complete the action needed. AWS suggests not using the ResourceTag condition key in a policy with the iam:PassRole action. You cannot use the tag on an IAM role to control access to who can pass that role.
Create an AWS CloudFormation service role with necessary permissions and use aws:SourceIp AWS-wide condition to specify the IP addresses of the developers. Associate this service role to the stack. Grant the developer iam:PassRole permissions to pass the role to the service. Use this newly created service role during stack deployments - This statement is incorrect. AWS suggests not using the aws:SourceIp AWS-wide condition. AWS CloudFormation provisions resources by using its own IP address, not the IP address of the originating request. For example, when you create a stack, AWS CloudFormation makes requests from its IP address to launch an Amazon EC2 instance or to create an Amazon S3 bucket, not from the IP address from the CreateStack call or the AWS CloudFormation create-stack command.
Create an AWS CloudFormation service role with required permissions and associate this service role to the stack. Use this newly created service role during stack deployments - To pass a role (and its permissions) to an AWS service, a user must have permission to pass the role to the service. To allow a user to pass a role to an AWS service, you must grant the PassRole permission to the user's IAM user, role, or group. Granting the developer iam:PassRole permissions to pass the role to the service is a necessary step if the developers have to deploy the CloudFormation stacks.
References:
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/using-iam-servicerole.html
https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_use_passrole.html
https://docs.aws.amazon.com/IAM/latest/UserGuide/access_tags.html
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/using-iam-template.html
Explanation
Correct option:
Create an AWS CloudFormation service role with required permissions and associate this service role to the stack. Grant the developer iam:PassRole permissions to pass the role to the service. Use this newly created service role during stack deployments
A service role is an AWS Identity and Access Management (IAM) role that allows AWS CloudFormation to make calls to resources in a stack on your behalf. You can specify an IAM role that allows AWS CloudFormation to create, update, or delete your stack resources. By default, AWS CloudFormation uses a temporary session that it generates from your user credentials for stack operations. If you specify a service role, AWS CloudFormation uses that role's credentials.
Use a service role to explicitly specify the actions that AWS CloudFormation can perform, which might not always be the same actions that you or other users can do. For example, you might have administrative privileges, but you can limit AWS CloudFormation access to only Amazon EC2 actions.
When you specify a service role, AWS CloudFormation always uses that role for all operations that are performed on that stack. It is not possible to remove a service role attached to a stack after the stack is created. Other users that have permission to perform operations on this stack will be able to use this role, but they must have the iam:PassRole permission.
To pass a role (and its permissions) to an AWS service, a user must have permission to pass the role to the service. This helps administrators ensure that only approved users can configure a service with a role that grants permissions. To allow a user to pass a role to an AWS service, you must grant PassRole permission to the user's IAM user, role, or group.
via - https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/using-iam-servicerole.html
Incorrect options:
Create an AWS CloudFormation service role with full permissions and associate this service role to the stack. Grant the developer iam:PassRole permissions. Limit the permissions to pass a role based on tags attached to the role using the ResourceTag/key-name condition key - Giving full permissions is against the security best practice that says a role should have the least possible privileges to complete the action needed. AWS suggests not using the ResourceTag condition key in a policy with the iam:PassRole action. You cannot use the tag on an IAM role to control access to who can pass that role.
Create an AWS CloudFormation service role with necessary permissions and use aws:SourceIp AWS-wide condition to specify the IP addresses of the developers. Associate this service role to the stack. Grant the developer iam:PassRole permissions to pass the role to the service. Use this newly created service role during stack deployments - This statement is incorrect. AWS suggests not using the aws:SourceIp AWS-wide condition. AWS CloudFormation provisions resources by using its own IP address, not the IP address of the originating request. For example, when you create a stack, AWS CloudFormation makes requests from its IP address to launch an Amazon EC2 instance or to create an Amazon S3 bucket, not from the IP address from the CreateStack call or the AWS CloudFormation create-stack command.
Create an AWS CloudFormation service role with required permissions and associate this service role to the stack. Use this newly created service role during stack deployments - To pass a role (and its permissions) to an AWS service, a user must have permission to pass the role to the service. To allow a user to pass a role to an AWS service, you must grant the PassRole permission to the user's IAM user, role, or group. Granting the developer iam:PassRole permissions to pass the role to the service is a necessary step if the developers have to deploy the CloudFormation stacks.
References:
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/using-iam-servicerole.html
https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_use_passrole.html
https://docs.aws.amazon.com/IAM/latest/UserGuide/access_tags.html
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/using-iam-template.html


