
AWS Certified Machine Learning Engineer - Associate - (MLA-C01) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 11 Single Choice
You are an ML engineer at a startup that is developing a recommendation engine for an e-commerce platform. The workload involves training models on large datasets and deploying them to serve real-time recommendations to customers. The training jobs are sporadic but require significant computational power, while the inference workloads must handle varying traffic throughout the day. The company is cost-conscious and aims to balance cost efficiency with the need for scalability and performance.
Given these requirements, which approach to resource allocation is the MOST SUITABLE for training and inference, and why?
Explanation

Click "Show Answer" to see the explanation here
Correct option:
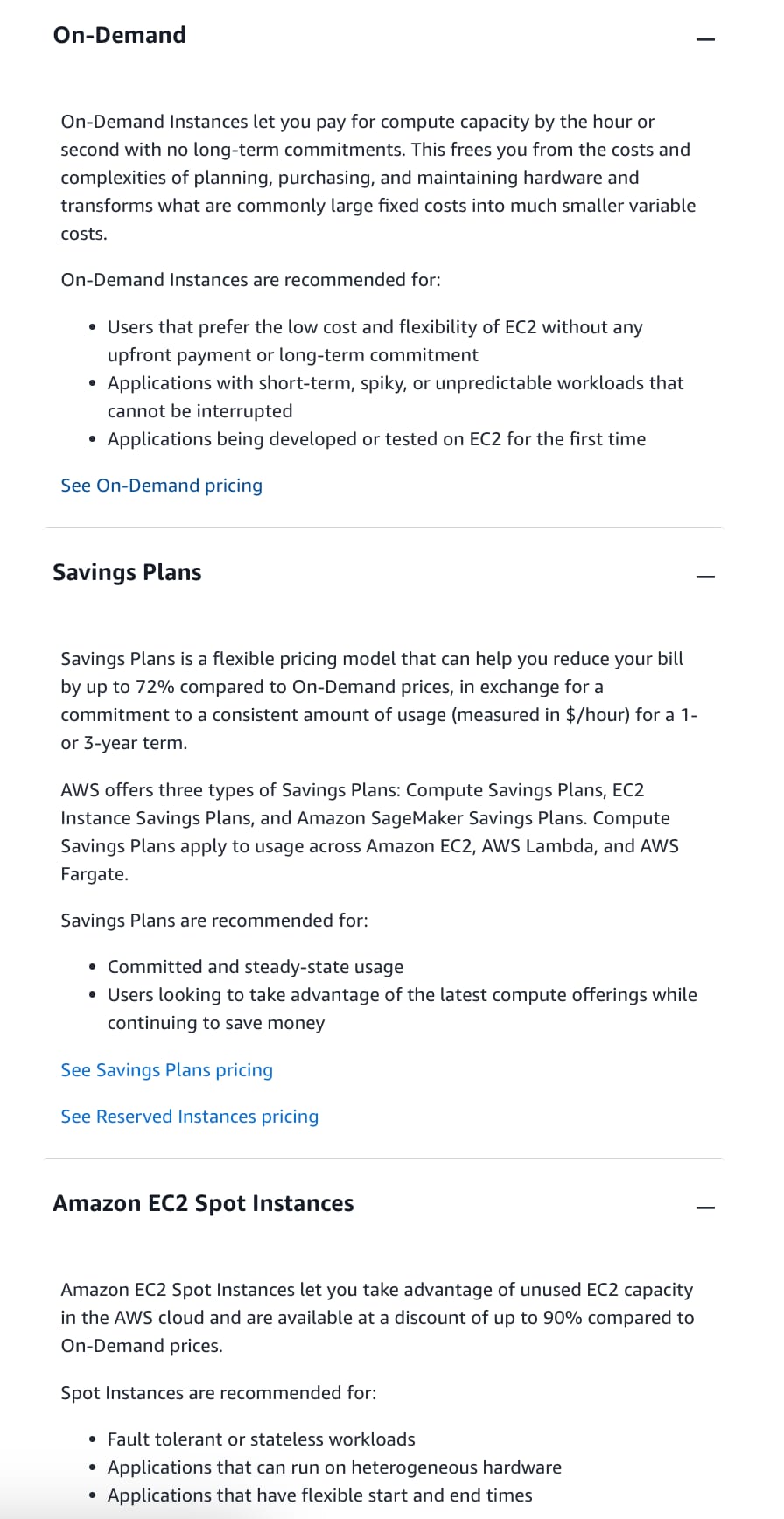
Use on-demand instances for training, allowing the flexibility to scale resources as needed, and use provisioned resources with auto-scaling for inference to handle varying traffic while controlling costs
Using on-demand instances for training offers flexibility, allowing you to allocate resources only when needed, which is ideal for sporadic training jobs. For inference, provisioned resources with auto-scaling ensure that the system can handle varying traffic while controlling costs, as it can scale down during periods of low demand.
 via - https://aws.amazon.com/ec2/pricing/
via - https://aws.amazon.com/ec2/pricing/
Incorrect options:
Use on-demand instances for both training and inference to ensure that the company only pays for the compute resources it uses when it needs them, avoiding any upfront commitments - On-demand instances are flexible and ensure that you only pay for what you use, but they can be more expensive over time compared to provisioned resources, especially if workloads are consistent and predictable. This approach may be suboptimal for cost-sensitive long-term use.
Use provisioned resources with reserved instances for both training and inference to lock in lower costs and guarantee resource availability, ensuring predictability in budgeting - Provisioned resources with reserved instances provide cost savings and guaranteed availability but lack the flexibility needed for sporadic training jobs. For inference workloads with fluctuating demand, this approach might not handle traffic spikes efficiently without additional auto-scaling mechanisms.
Use provisioned resources with spot instances for both training and inference to take advantage of the lowest possible costs, accepting the potential for interruptions during workload execution - Spot instances provide significant cost savings but come with the risk of interruptions, which can be problematic for both training and real-time inference workloads. This option is generally better suited for non-critical batch jobs where interruptions can be tolerated.
References:
https://aws.amazon.com/ec2/pricing/
https://aws.amazon.com/ec2/pricing/reserved-instances/
https://aws.amazon.com/ec2/spot/
https://docs.aws.amazon.com/sagemaker/latest/dg/endpoint-auto-scaling-prerequisites.html
Explanation
Correct option:
Use on-demand instances for training, allowing the flexibility to scale resources as needed, and use provisioned resources with auto-scaling for inference to handle varying traffic while controlling costs
Using on-demand instances for training offers flexibility, allowing you to allocate resources only when needed, which is ideal for sporadic training jobs. For inference, provisioned resources with auto-scaling ensure that the system can handle varying traffic while controlling costs, as it can scale down during periods of low demand.
via - https://aws.amazon.com/ec2/pricing/
Incorrect options:
Use on-demand instances for both training and inference to ensure that the company only pays for the compute resources it uses when it needs them, avoiding any upfront commitments - On-demand instances are flexible and ensure that you only pay for what you use, but they can be more expensive over time compared to provisioned resources, especially if workloads are consistent and predictable. This approach may be suboptimal for cost-sensitive long-term use.
Use provisioned resources with reserved instances for both training and inference to lock in lower costs and guarantee resource availability, ensuring predictability in budgeting - Provisioned resources with reserved instances provide cost savings and guaranteed availability but lack the flexibility needed for sporadic training jobs. For inference workloads with fluctuating demand, this approach might not handle traffic spikes efficiently without additional auto-scaling mechanisms.
Use provisioned resources with spot instances for both training and inference to take advantage of the lowest possible costs, accepting the potential for interruptions during workload execution - Spot instances provide significant cost savings but come with the risk of interruptions, which can be problematic for both training and real-time inference workloads. This option is generally better suited for non-critical batch jobs where interruptions can be tolerated.
References:
https://aws.amazon.com/ec2/pricing/
https://aws.amazon.com/ec2/pricing/reserved-instances/
https://aws.amazon.com/ec2/spot/
https://docs.aws.amazon.com/sagemaker/latest/dg/endpoint-auto-scaling-prerequisites.html
Question 12 Single Choice
A financial institution has deployed a machine learning model using Amazon SageMaker to predict whether credit card transactions are fraudulent. To ensure model performance remains consistent, the company configured Amazon SageMaker Model Monitor to track deviations in the model accuracy over time. The model's baseline accuracy was recorded during its initial deployment. However, after several months of operation, the model’s accuracy drops significantly despite no changes being made to the model.
What could be the reason for the reduced model accuracy?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Concept drift occurred in the underlying customer data that was used for predictions, changing the relationship between input features and the target variable over time
Concept drift happens when the relationship between input features (e.g., customer transaction patterns, demographics, or usage behaviors) and the target variable (e.g., fraud detection or churn likelihood) changes over time. For instance:
Customer behavior might evolve, resulting in new patterns that were not present in the original training dataset.
Fraud tactics may have changed, altering the model’s assumptions and causing it to make inaccurate predictions.
While the model may still receive input data that appears valid, the patterns it learned during training no longer match real-world behaviors. This leads to a significant drop in predictive performance, such as accuracy or F1 score.
Automate model retraining with Amazon SageMaker Pipelines when drift is detected: 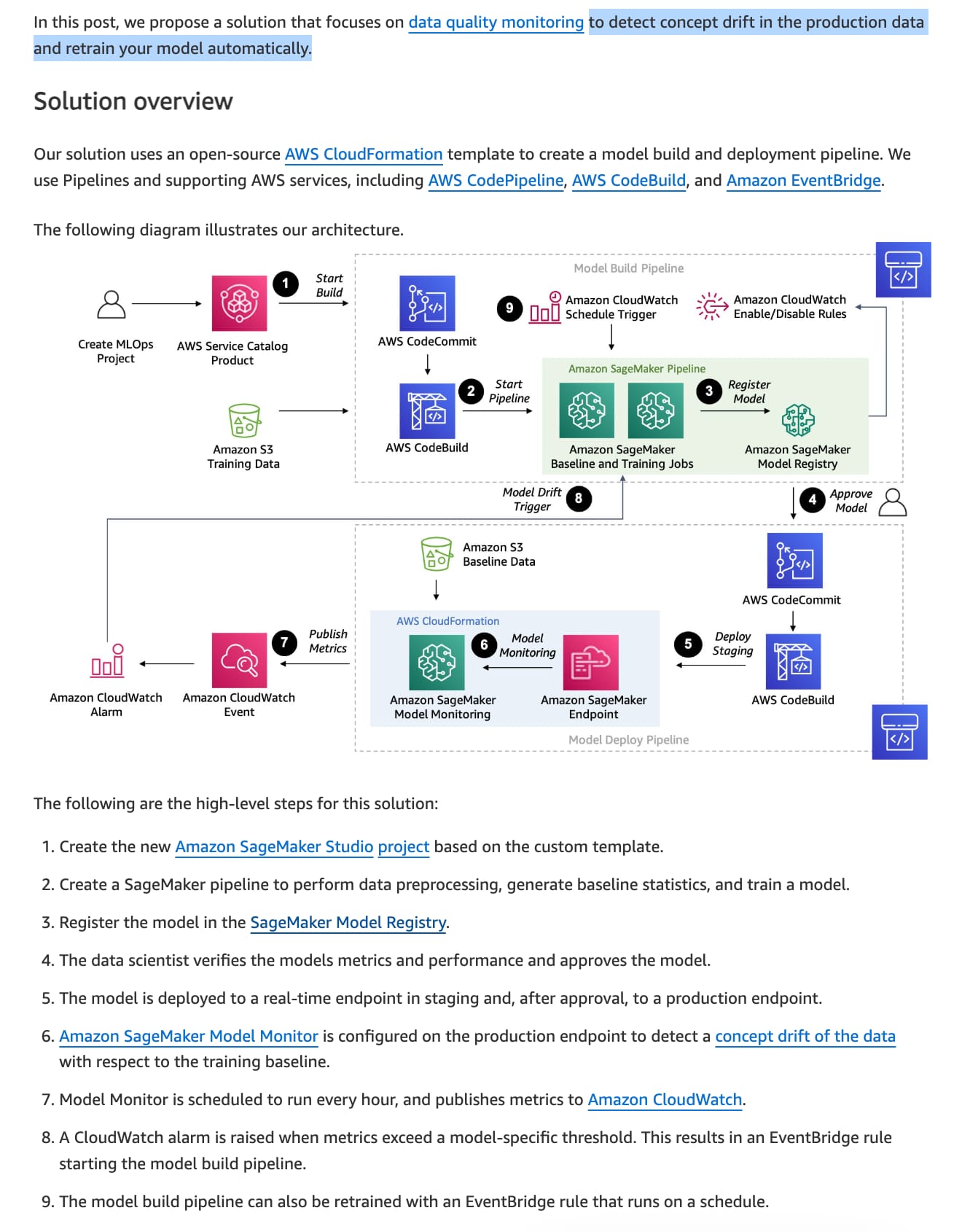 via - https://aws.amazon.com/blogs/machine-learning/automate-model-retraining-with-amazon-sagemaker-pipelines-when-drift-is-detected/
via - https://aws.amazon.com/blogs/machine-learning/automate-model-retraining-with-amazon-sagemaker-pipelines-when-drift-is-detected/
Incorrect options:
The model’s hyperparameters have automatically adjusted during inference, causing a decline in predictive accuracy - Hyperparameters do not automatically adjust in production. SageMaker deployments use a static model until explicitly retrained or updated.
Amazon SageMaker Model Monitor miscalculated the accuracy metric due to a configuration error - SageMaker Model Monitor accurately captures metrics unless the input configuration is incorrect, which is unlikely if it previously worked as expected.
The deployed model’s architecture degraded over time, reducing its predictive performance - Model architectures do not degrade over time. Reduced accuracy typically results from data drift or concept drift, not the model itself.
Reference:
Explanation
Correct option:
Concept drift occurred in the underlying customer data that was used for predictions, changing the relationship between input features and the target variable over time
Concept drift happens when the relationship between input features (e.g., customer transaction patterns, demographics, or usage behaviors) and the target variable (e.g., fraud detection or churn likelihood) changes over time. For instance:
Customer behavior might evolve, resulting in new patterns that were not present in the original training dataset.
Fraud tactics may have changed, altering the model’s assumptions and causing it to make inaccurate predictions.
While the model may still receive input data that appears valid, the patterns it learned during training no longer match real-world behaviors. This leads to a significant drop in predictive performance, such as accuracy or F1 score.
Automate model retraining with Amazon SageMaker Pipelines when drift is detected: via - https://aws.amazon.com/blogs/machine-learning/automate-model-retraining-with-amazon-sagemaker-pipelines-when-drift-is-detected/
Incorrect options:
The model’s hyperparameters have automatically adjusted during inference, causing a decline in predictive accuracy - Hyperparameters do not automatically adjust in production. SageMaker deployments use a static model until explicitly retrained or updated.
Amazon SageMaker Model Monitor miscalculated the accuracy metric due to a configuration error - SageMaker Model Monitor accurately captures metrics unless the input configuration is incorrect, which is unlikely if it previously worked as expected.
The deployed model’s architecture degraded over time, reducing its predictive performance - Model architectures do not degrade over time. Reduced accuracy typically results from data drift or concept drift, not the model itself.
Reference:
Question 13 Single Choice
You are tasked with building a predictive model for customer lifetime value (CLV) using Amazon SageMaker. Given the complexity of the model, it’s crucial to optimize hyperparameters to achieve the best possible performance. You decide to use SageMaker’s automatic model tuning (hyperparameter optimization) with Random Search strategy to fine-tune the model. You have a large dataset, and the tuning job involves several hyperparameters, including the learning rate, batch size, and dropout rate.
During the tuning process, you observe that some of the trials are not converging effectively, and the results are not as expected. You suspect that the hyperparameter ranges or the strategy you are using may need adjustment.
Which of the following approaches is MOST LIKELY to improve the effectiveness of the hyperparameter tuning process?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Switch from the Random Search strategy to the Bayesian Optimization strategy and narrow the range of critical hyperparameters
When you’re training machine learning models, each dataset and model needs a different set of hyperparameters, which are a kind of variable. The only way to determine these is through multiple experiments, where you pick a set of hyperparameters and run them through your model. This is called hyperparameter tuning. In essence, you're training your model sequentially with different sets of hyperparameters. This process can be manual, or you can pick one of several automated hyperparameter tuning methods.
Bayesian Optimization is a technique based on Bayes’ theorem, which describes the probability of an event occurring related to current knowledge. When this is applied to hyperparameter optimization, the algorithm builds a probabilistic model from a set of hyperparameters that optimizes a specific metric. It uses regression analysis to iteratively choose the best set of hyperparameters.
Random Search selects groups of hyperparameters randomly on each iteration. It works well when a relatively small number of the hyperparameters primarily determine the model outcome.
Bayesian Optimization is more efficient than Random Search for hyperparameter tuning, especially when dealing with complex models and large hyperparameter spaces. It learns from previous trials to predict the best set of hyperparameters, thus focusing the search more effectively. Narrowing the range of critical hyperparameters can further improve the chances of finding the optimal values, leading to better model convergence and performance.
How hyperparameter tuning with Amazon SageMaker works:
 via - https://docs.aws.amazon.com/sagemaker/latest/dg/automatic-model-tuning-how-it-works.html
via - https://docs.aws.amazon.com/sagemaker/latest/dg/automatic-model-tuning-how-it-works.html
Incorrect options:
Increase the number of hyperparameters being tuned and widen the range for all hyperparameters - Increasing the number of hyperparameters and widening the range without any strategic approach can lead to a more extensive search space, which could cause the tuning process to become inefficient and less likely to converge on optimal values.
Decrease the number of total trials but increase the number of parallel jobs to speed up the tuning process - Reducing the total number of trials might speed up the tuning process, but it also reduces the chances of finding the best hyperparameters, especially if the model is complex. Increasing parallel jobs can improve throughput but doesn't necessarily enhance the quality of the search.
Use the Grid Search strategy with a wide range for all hyperparameters and increase the number of total trials - Grid Search works well, but it’s relatively tedious and computationally intensive, especially with large numbers of hyperparameters. It is less efficient than Bayesian Optimization for complex models. A wide range of hyperparameters without focus would result in more trials, but it is not guaranteed to find the best values, especially with a larger search space.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/automatic-model-tuning-how-it-works.html
https://aws.amazon.com/what-is/hyperparameter-tuning/
https://docs.aws.amazon.com/sagemaker/latest/dg/automatic-model-tuning.html
Explanation
Correct option:
Switch from the Random Search strategy to the Bayesian Optimization strategy and narrow the range of critical hyperparameters
When you’re training machine learning models, each dataset and model needs a different set of hyperparameters, which are a kind of variable. The only way to determine these is through multiple experiments, where you pick a set of hyperparameters and run them through your model. This is called hyperparameter tuning. In essence, you're training your model sequentially with different sets of hyperparameters. This process can be manual, or you can pick one of several automated hyperparameter tuning methods.
Bayesian Optimization is a technique based on Bayes’ theorem, which describes the probability of an event occurring related to current knowledge. When this is applied to hyperparameter optimization, the algorithm builds a probabilistic model from a set of hyperparameters that optimizes a specific metric. It uses regression analysis to iteratively choose the best set of hyperparameters.
Random Search selects groups of hyperparameters randomly on each iteration. It works well when a relatively small number of the hyperparameters primarily determine the model outcome.
Bayesian Optimization is more efficient than Random Search for hyperparameter tuning, especially when dealing with complex models and large hyperparameter spaces. It learns from previous trials to predict the best set of hyperparameters, thus focusing the search more effectively. Narrowing the range of critical hyperparameters can further improve the chances of finding the optimal values, leading to better model convergence and performance.
How hyperparameter tuning with Amazon SageMaker works:
via - https://docs.aws.amazon.com/sagemaker/latest/dg/automatic-model-tuning-how-it-works.html
Incorrect options:
Increase the number of hyperparameters being tuned and widen the range for all hyperparameters - Increasing the number of hyperparameters and widening the range without any strategic approach can lead to a more extensive search space, which could cause the tuning process to become inefficient and less likely to converge on optimal values.
Decrease the number of total trials but increase the number of parallel jobs to speed up the tuning process - Reducing the total number of trials might speed up the tuning process, but it also reduces the chances of finding the best hyperparameters, especially if the model is complex. Increasing parallel jobs can improve throughput but doesn't necessarily enhance the quality of the search.
Use the Grid Search strategy with a wide range for all hyperparameters and increase the number of total trials - Grid Search works well, but it’s relatively tedious and computationally intensive, especially with large numbers of hyperparameters. It is less efficient than Bayesian Optimization for complex models. A wide range of hyperparameters without focus would result in more trials, but it is not guaranteed to find the best values, especially with a larger search space.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/automatic-model-tuning-how-it-works.html
https://aws.amazon.com/what-is/hyperparameter-tuning/
https://docs.aws.amazon.com/sagemaker/latest/dg/automatic-model-tuning.html
Question 14 Multiple Choice
You are a Data Scientist working for an e-commerce company that is developing a machine learning model to predict whether a customer will make a purchase based on their browsing behavior. You need to evaluate the model's performance using different evaluation metrics to understand how well the model is predicting the positive class (i.e., customers who will make a purchase). The dataset is imbalanced, with a small percentage of customers making a purchase. Given this context, you must decide on the most appropriate evaluation techniques to assess your model's effectiveness and identify potential areas for improvement.
Which of the following evaluation techniques and metrics should you prioritize when assessing the performance of your model, considering the dataset's imbalance and the need for a comprehensive understanding of both false positives and false negatives? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Evaluate the model using the confusion matrix, which provides insights into true positives, false positives, true negatives, and false negatives, allowing you to calculate additional metrics such as precision, recall, and F1 score
The confusion matrix illustrates in a table the number or percentage of correct and incorrect predictions for each class by comparing an observation's predicted class and its true class. The confusion matrix is crucial for understanding the detailed performance of your model, especially in an imbalanced dataset. It allows you to calculate additional metrics such as precision, recall, and F1 score, which are essential for understanding how well your model handles false positives and false negatives.
Use precision and recall to focus on the model's ability to correctly identify positive cases while minimizing false positives and false negatives
Precision and recall are particularly important in an imbalanced dataset. Precision measures the proportion of true positive predictions among all positive predictions, while recall measures the proportion of actual positives that are correctly identified. Focusing on these metrics helps in assessing how well the model avoids false positives and false negatives, which is critical in your scenario.
Key metrics to measure machine learning model performance:


via - https://docs.aws.amazon.com/sagemaker/latest/dg/autopilot-metrics-validation.html
Incorrect options:
Use accuracy as the primary metric, as it measures the percentage of correct predictions out of all predictions made by the model - While accuracy is a common metric, it is not suitable for imbalanced datasets because it can be misleading. A model predicting the majority class most of the time can achieve high accuracy without effectively capturing the minority class (e.g., customers who make a purchase).
Prioritize Root mean squared error (RMSE) as the key metric, as it measures the average magnitude of the errors between predicted and actual values - RMSE is a regression metric, not suitable for classification problems. In this scenario, you are dealing with a classification task, so metrics like precision, recall, and F1 score are more appropriate.
Utilize the AUC-ROC curve to evaluate the model’s ability to distinguish between classes across various thresholds, particularly in the presence of class imbalance - The AUC-ROC curve is a useful tool, especially in imbalanced datasets. However, understanding the confusion matrix and calculating precision and recall provide more direct insights into the types of errors the model is making, which is crucial for improving the model’s performance in your specific context.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/autopilot-metrics-validation.html
https://docs.aws.amazon.com/machine-learning/latest/dg/binary-classification.html
Explanation
Correct options:
Evaluate the model using the confusion matrix, which provides insights into true positives, false positives, true negatives, and false negatives, allowing you to calculate additional metrics such as precision, recall, and F1 score
The confusion matrix illustrates in a table the number or percentage of correct and incorrect predictions for each class by comparing an observation's predicted class and its true class. The confusion matrix is crucial for understanding the detailed performance of your model, especially in an imbalanced dataset. It allows you to calculate additional metrics such as precision, recall, and F1 score, which are essential for understanding how well your model handles false positives and false negatives.
Use precision and recall to focus on the model's ability to correctly identify positive cases while minimizing false positives and false negatives
Precision and recall are particularly important in an imbalanced dataset. Precision measures the proportion of true positive predictions among all positive predictions, while recall measures the proportion of actual positives that are correctly identified. Focusing on these metrics helps in assessing how well the model avoids false positives and false negatives, which is critical in your scenario.
Key metrics to measure machine learning model performance:
via - https://docs.aws.amazon.com/sagemaker/latest/dg/autopilot-metrics-validation.html
Incorrect options:
Use accuracy as the primary metric, as it measures the percentage of correct predictions out of all predictions made by the model - While accuracy is a common metric, it is not suitable for imbalanced datasets because it can be misleading. A model predicting the majority class most of the time can achieve high accuracy without effectively capturing the minority class (e.g., customers who make a purchase).
Prioritize Root mean squared error (RMSE) as the key metric, as it measures the average magnitude of the errors between predicted and actual values - RMSE is a regression metric, not suitable for classification problems. In this scenario, you are dealing with a classification task, so metrics like precision, recall, and F1 score are more appropriate.
Utilize the AUC-ROC curve to evaluate the model’s ability to distinguish between classes across various thresholds, particularly in the presence of class imbalance - The AUC-ROC curve is a useful tool, especially in imbalanced datasets. However, understanding the confusion matrix and calculating precision and recall provide more direct insights into the types of errors the model is making, which is crucial for improving the model’s performance in your specific context.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/autopilot-metrics-validation.html
https://docs.aws.amazon.com/machine-learning/latest/dg/binary-classification.html
Question 15 Single Choice
A financial services company is developing an AI-based credit risk assessment system using Amazon SageMaker. The system needs to support end-to-end ML workflows, including experimentation, model training, version management, deployment, and monitoring. To comply with internal governance policies, the company requires a manual approval-based workflow to ensure that only approved models can be deployed to production endpoints. All training data should be securely stored in Amazon S3, and the models should be managed through a centralized system.
Which solution will best meet these requirements?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use SageMaker Pipelines with conditional steps to implement manual approval workflows for model deployment
Amazon SageMaker Pipelines is the recommended solution for implementing manual approval-based workflows for model deployment. SageMaker Pipelines allows you to design automated ML workflows, including steps for training, registering models in SageMaker Model Registry, and deploying models to endpoints. You can use conditional steps in SageMaker Pipelines to introduce a manual approval step before proceeding to production deployments. This ensures only models explicitly approved by a human reviewer are deployed, which aligns perfectly with the requirement for governance and control.
Key Benefits:
Supports manual approval workflows within automated pipelines.
Integrates seamlessly with SageMaker Model Registry to manage approved models.
Reduces operational overhead by automating model deployment with built-in approval checks.
Incorrect options:
Use Amazon SageMaker Model Monitor to validate and approve models before deployment - SageMaker Model Monitor is designed to detect drift and monitor model quality after deployment. It does not provide manual approval workflows or enforce governance before deployment.
Use AWS CodePipeline to manage deployments and set manual approval actions for endpoint updates - While AWS CodePipeline can include manual approval actions, it is primarily a CI/CD tool. It does not integrate natively with SageMaker Model Registry or support the orchestration of ML workflows like SageMaker Pipelines does. This makes it less suitable for the ML-specific use case described.
Use Amazon SageMaker Lineage Tracking to validate and approve models before deployment - SageMaker Lineage Tracking is used to track the lineage of artifacts (e.g., datasets, models, and experiments) within an ML workflow. It provides visibility into the relationships between components, such as which dataset and training job produced a specific model version. However, it does not support manual approval workflows or enforce governance for deploying models to production. While lineage tracking is valuable for auditing and reproducibility, it does not include built-in mechanisms for validating or approving models for deployment.
Reference:
https://docs.aws.amazon.com/sagemaker/latest/dg/model-registry-approve.html
Explanation
Correct option:
Use SageMaker Pipelines with conditional steps to implement manual approval workflows for model deployment
Amazon SageMaker Pipelines is the recommended solution for implementing manual approval-based workflows for model deployment. SageMaker Pipelines allows you to design automated ML workflows, including steps for training, registering models in SageMaker Model Registry, and deploying models to endpoints. You can use conditional steps in SageMaker Pipelines to introduce a manual approval step before proceeding to production deployments. This ensures only models explicitly approved by a human reviewer are deployed, which aligns perfectly with the requirement for governance and control.
Key Benefits:
Supports manual approval workflows within automated pipelines.
Integrates seamlessly with SageMaker Model Registry to manage approved models.
Reduces operational overhead by automating model deployment with built-in approval checks.
Incorrect options:
Use Amazon SageMaker Model Monitor to validate and approve models before deployment - SageMaker Model Monitor is designed to detect drift and monitor model quality after deployment. It does not provide manual approval workflows or enforce governance before deployment.
Use AWS CodePipeline to manage deployments and set manual approval actions for endpoint updates - While AWS CodePipeline can include manual approval actions, it is primarily a CI/CD tool. It does not integrate natively with SageMaker Model Registry or support the orchestration of ML workflows like SageMaker Pipelines does. This makes it less suitable for the ML-specific use case described.
Use Amazon SageMaker Lineage Tracking to validate and approve models before deployment - SageMaker Lineage Tracking is used to track the lineage of artifacts (e.g., datasets, models, and experiments) within an ML workflow. It provides visibility into the relationships between components, such as which dataset and training job produced a specific model version. However, it does not support manual approval workflows or enforce governance for deploying models to production. While lineage tracking is valuable for auditing and reproducibility, it does not include built-in mechanisms for validating or approving models for deployment.
Reference:
https://docs.aws.amazon.com/sagemaker/latest/dg/model-registry-approve.html
Question 16 Single Choice
You are an ML engineer at a data analytics company tasked with training a deep learning model on a large, computationally intensive dataset. The training job can tolerate interruptions and is expected to run for several hours or even days, depending on the available compute resources. The company has a limited budget for cloud infrastructure, so you need to minimize costs as much as possible.
Which strategy is the MOST EFFECTIVE for your ML training job while minimizing cost and ensuring the job completes successfully?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use Amazon SageMaker Managed Spot Training to dynamically allocate Spot Instances for the training job, automatically retrying any interrupted instances via checkpoints
Managed Spot Training uses Amazon EC2 Spot instance to run training jobs instead of on-demand instances. You can specify which training jobs use spot instances and a stopping condition that specifies how long SageMaker waits for a job to run using Amazon EC2 Spot instances. Spot instances can be interrupted, causing jobs to take longer to start or finish. You can configure your managed spot training job to use checkpoints. SageMaker copies checkpoint data from a local path to Amazon S3. When the job is restarted, SageMaker copies the data from Amazon S3 back into the local path. The training job can then resume from the last checkpoint instead of restarting.
 via -
via - Incorrect options:
Use Amazon EC2 Auto Scaling to automatically add Spot Instances to the training job based on demand, and configure the job to continue processing even if some Spot Instances are interrupted - Amazon EC2 Auto Scaling can add Spot Instances based on demand, but it does not provide the same level of automation and resilience as SageMaker Managed Spot Training, especially for ML-specific workloads where Spot interruptions need to be handled gracefully.
Deploy the training job on a fixed number of On-Demand EC2 instances to ensure stability, and manually add Spot Instances as needed to speed up the job during off-peak hours - Using a fixed number of On-Demand EC2 instances provides stability, but manually adding Spot Instances introduces complexity and may not fully optimize costs. Automating this process with SageMaker is more efficient.
Start the training job using only Spot Instances to minimize cost, and switch to On-Demand instances manually if any Spot Instances are interrupted during training - Starting with only Spot Instances minimizes costs, but manually switching to On-Demand instances increases the risk of delays and interruptions if Spot capacity becomes unavailable. SageMaker Managed Spot Training offers a more reliable and automated solution.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/model-managed-spot-training.html
Explanation
Correct option:
Use Amazon SageMaker Managed Spot Training to dynamically allocate Spot Instances for the training job, automatically retrying any interrupted instances via checkpoints
Managed Spot Training uses Amazon EC2 Spot instance to run training jobs instead of on-demand instances. You can specify which training jobs use spot instances and a stopping condition that specifies how long SageMaker waits for a job to run using Amazon EC2 Spot instances. Spot instances can be interrupted, causing jobs to take longer to start or finish. You can configure your managed spot training job to use checkpoints. SageMaker copies checkpoint data from a local path to Amazon S3. When the job is restarted, SageMaker copies the data from Amazon S3 back into the local path. The training job can then resume from the last checkpoint instead of restarting.
Incorrect options:
Use Amazon EC2 Auto Scaling to automatically add Spot Instances to the training job based on demand, and configure the job to continue processing even if some Spot Instances are interrupted - Amazon EC2 Auto Scaling can add Spot Instances based on demand, but it does not provide the same level of automation and resilience as SageMaker Managed Spot Training, especially for ML-specific workloads where Spot interruptions need to be handled gracefully.
Deploy the training job on a fixed number of On-Demand EC2 instances to ensure stability, and manually add Spot Instances as needed to speed up the job during off-peak hours - Using a fixed number of On-Demand EC2 instances provides stability, but manually adding Spot Instances introduces complexity and may not fully optimize costs. Automating this process with SageMaker is more efficient.
Start the training job using only Spot Instances to minimize cost, and switch to On-Demand instances manually if any Spot Instances are interrupted during training - Starting with only Spot Instances minimizes costs, but manually switching to On-Demand instances increases the risk of delays and interruptions if Spot capacity becomes unavailable. SageMaker Managed Spot Training offers a more reliable and automated solution.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/model-managed-spot-training.html
Question 17 Single Choice
A healthcare company is building a predictive model to identify high-risk patients for hospital readmission. The dataset includes patient records such as demographic information, past diagnoses, and admission history. The data is stored in Amazon S3 and a relational database hosted on an on-premises PostgreSQL server. The dataset has a class imbalance issue where very few patients are flagged as high-risk, which affects the performance of the model. Additionally, the dataset contains both categorical features (e.g., "diagnosis type") and numerical features (e.g., "days in hospital"). The ML engineer must preprocess the data to resolve the class imbalance and ensure the dataset is ready for training, using a solution that requires minimal operational effort.
Which solution will meet these requirements?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use Amazon SageMaker Data Wrangler's 'balance data' operation to oversample the minority class to resolve the class imbalance
Amazon SageMaker Data Wrangler provides an intuitive, visual interface for performing data preparation tasks. Key benefits include:
No-code approach with minimal operational overhead.
Supports popular techniques for balancing data (oversampling/undersampling).
Integrates seamlessly with Amazon S3 and SageMaker workflows.
The "balance data" operation in SageMaker Data Wrangler allows users to easily address class imbalance issues using techniques like -
Oversampling: Duplicating data from the minority class.
Undersampling: Reducing the majority class data to match the minority class.
This built-in operation eliminates the need for custom scripts or complex workflows, ensuring the task is completed with minimal operational effort. The balanced dataset can then be directly exported to SageMaker for model training.
Balance your data for machine learning with Amazon SageMaker Data Wrangler: 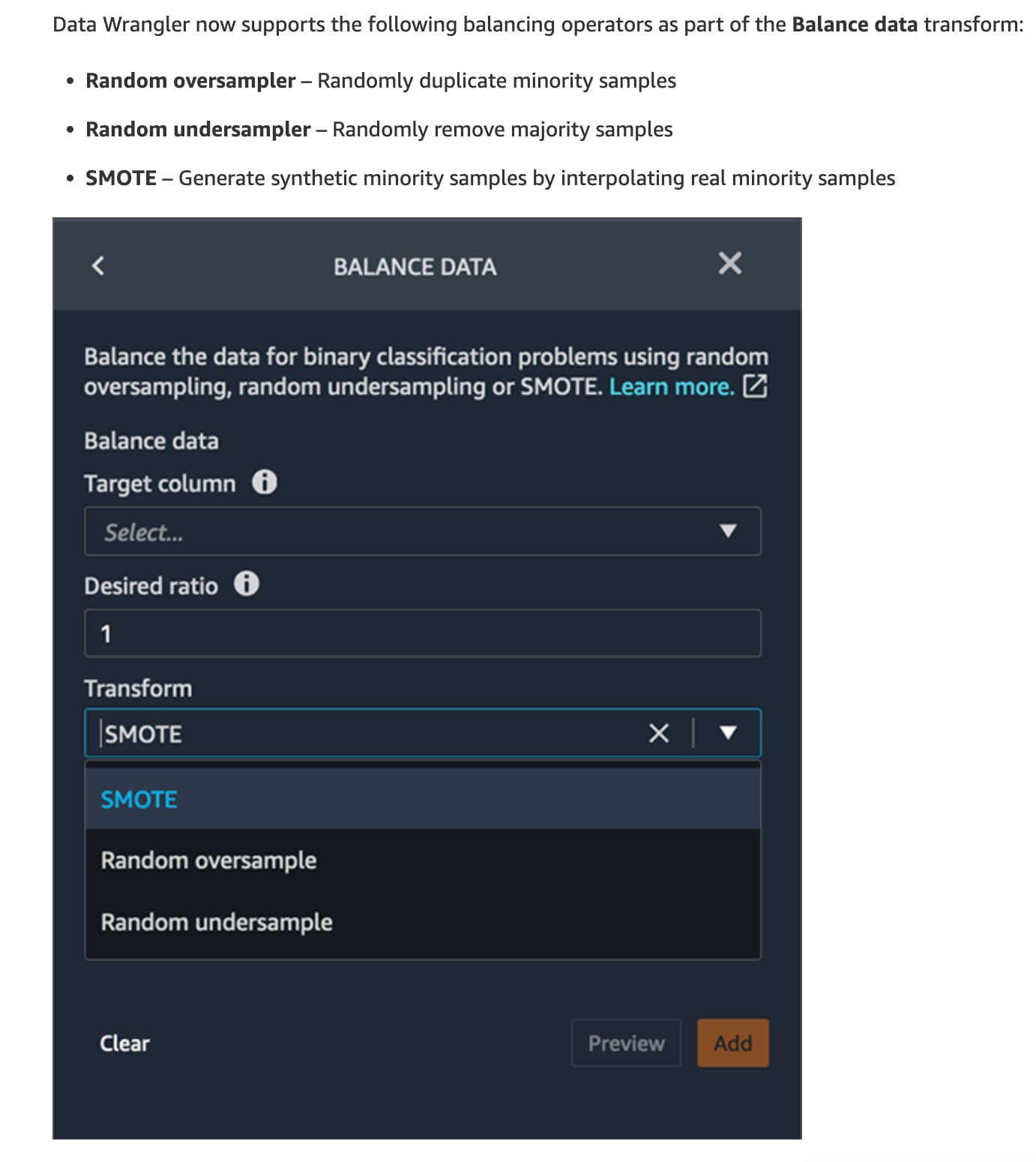 via - https://aws.amazon.com/blogs/machine-learning/balance-your-data-for-machine-learning-with-amazon-sagemaker-data-wrangler/
via - https://aws.amazon.com/blogs/machine-learning/balance-your-data-for-machine-learning-with-amazon-sagemaker-data-wrangler/
Incorrect options:
Leverage AWS Glue DataBrew’s native features to clean and transform the dataset, including attempting to balance class distribution by duplicating records from the minority class - AWS Glue DataBrew provides built-in capabilities for data cleaning and transformations, such as filtering rows, handling missing data, and applying basic aggregations. However, DataBrew does not have native features for oversampling or undersampling to balance class distributions. Addressing class imbalance would require custom steps or manual workarounds, which increase operational overhead compared to SageMaker Data Wrangler's built-in "balance data" operation.
Use SageMaker Feature Store to automatically balance the class distribution in the dataset - SageMaker Feature Store is used for storing and serving preprocessed features, but it does not provide functionality to balance data.
Use AWS Glue ETL jobs to write custom scripts for handling class imbalance by oversampling the minority class - AWS Glue ETL jobs require custom Python or PySpark scripts for balancing data, which increases operational overhead compared to SageMaker Data Wrangler's built-in operations.
References:
Explanation
Correct option:
Use Amazon SageMaker Data Wrangler's 'balance data' operation to oversample the minority class to resolve the class imbalance
Amazon SageMaker Data Wrangler provides an intuitive, visual interface for performing data preparation tasks. Key benefits include:
No-code approach with minimal operational overhead.
Supports popular techniques for balancing data (oversampling/undersampling).
Integrates seamlessly with Amazon S3 and SageMaker workflows.
The "balance data" operation in SageMaker Data Wrangler allows users to easily address class imbalance issues using techniques like -
Oversampling: Duplicating data from the minority class.
Undersampling: Reducing the majority class data to match the minority class.
This built-in operation eliminates the need for custom scripts or complex workflows, ensuring the task is completed with minimal operational effort. The balanced dataset can then be directly exported to SageMaker for model training.
Balance your data for machine learning with Amazon SageMaker Data Wrangler: via - https://aws.amazon.com/blogs/machine-learning/balance-your-data-for-machine-learning-with-amazon-sagemaker-data-wrangler/
Incorrect options:
Leverage AWS Glue DataBrew’s native features to clean and transform the dataset, including attempting to balance class distribution by duplicating records from the minority class - AWS Glue DataBrew provides built-in capabilities for data cleaning and transformations, such as filtering rows, handling missing data, and applying basic aggregations. However, DataBrew does not have native features for oversampling or undersampling to balance class distributions. Addressing class imbalance would require custom steps or manual workarounds, which increase operational overhead compared to SageMaker Data Wrangler's built-in "balance data" operation.
Use SageMaker Feature Store to automatically balance the class distribution in the dataset - SageMaker Feature Store is used for storing and serving preprocessed features, but it does not provide functionality to balance data.
Use AWS Glue ETL jobs to write custom scripts for handling class imbalance by oversampling the minority class - AWS Glue ETL jobs require custom Python or PySpark scripts for balancing data, which increases operational overhead compared to SageMaker Data Wrangler's built-in operations.
References:
Question 18 Single Choice
You are a machine learning engineer at a healthcare company responsible for developing and deploying an end-to-end ML workflow for predicting patient readmission rates. The workflow involves data preprocessing, model training, hyperparameter tuning, and deployment. Additionally, the solution must support regular retraining of the model as new data becomes available, with minimal manual intervention. You need to select the right solution to orchestrate this workflow efficiently while ensuring scalability, reliability, and ease of management.
Given these requirements, which of the following options is the MOST SUITABLE for orchestrating your ML workflow?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Implement the entire ML workflow using Amazon SageMaker Pipelines, which provides integrated orchestration for data processing, model training, tuning, and deployment
Amazon SageMaker Pipelines is a purpose-built workflow orchestration service to automate machine learning (ML) development. SageMaker Pipelines is specifically designed to orchestrate end-to-end ML workflows, integrating data processing, model training, hyperparameter tuning, and deployment in a seamless manner. It provides built-in versioning, lineage tracking, and support for continuous integration and delivery (CI/CD), making it the best choice for this use case.
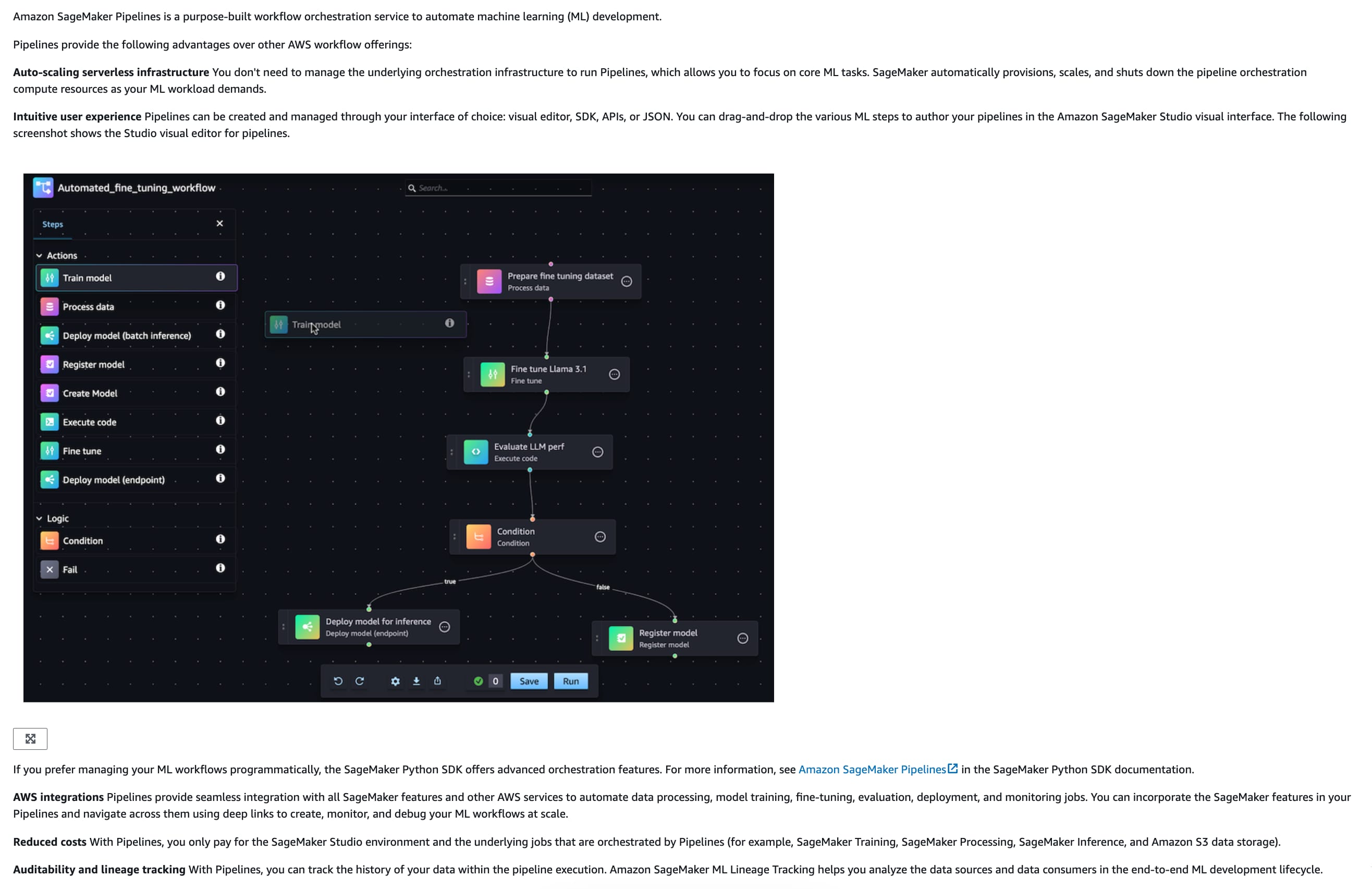 via - https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines.html
via - https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines.html
Incorrect options:
Use AWS Step Functions to define and orchestrate each step of the ML workflow, integrate with SageMaker for model training and deployment, and leverage AWS Lambda for data preprocessing tasks - AWS Step Functions is a powerful service for orchestrating workflows, and it can integrate with SageMaker and Lambda. However, using Step Functions for the entire ML workflow adds complexity since it requires coordinating multiple services, whereas SageMaker Pipelines provides a more seamless, integrated solution for ML-specific workflows.
Leverage Amazon EC2 instances to manually execute each step of the ML workflow, use Amazon RDS for storing intermediate results, and deploy the model using Amazon SageMaker endpoints - Manually managing each step of the ML workflow using EC2 instances and RDS is labor-intensive, prone to errors, and not scalable. It also lacks the automation and orchestration capabilities needed for a robust ML workflow.
Use AWS Glue for data preprocessing, Amazon SageMaker for model training and tuning, and manually deploy the model to an Amazon EC2 instance for inference - While using AWS Glue for data preprocessing and SageMaker for training is possible, manually deploying the model on EC2 lacks the orchestration and management features provided by SageMaker Pipelines. This approach also misses out on the integrated tracking, automation, and scalability features offered by SageMaker Pipelines.
Reference:
https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines.html
Explanation
Correct option:
Implement the entire ML workflow using Amazon SageMaker Pipelines, which provides integrated orchestration for data processing, model training, tuning, and deployment
Amazon SageMaker Pipelines is a purpose-built workflow orchestration service to automate machine learning (ML) development. SageMaker Pipelines is specifically designed to orchestrate end-to-end ML workflows, integrating data processing, model training, hyperparameter tuning, and deployment in a seamless manner. It provides built-in versioning, lineage tracking, and support for continuous integration and delivery (CI/CD), making it the best choice for this use case.
via - https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines.html
Incorrect options:
Use AWS Step Functions to define and orchestrate each step of the ML workflow, integrate with SageMaker for model training and deployment, and leverage AWS Lambda for data preprocessing tasks - AWS Step Functions is a powerful service for orchestrating workflows, and it can integrate with SageMaker and Lambda. However, using Step Functions for the entire ML workflow adds complexity since it requires coordinating multiple services, whereas SageMaker Pipelines provides a more seamless, integrated solution for ML-specific workflows.
Leverage Amazon EC2 instances to manually execute each step of the ML workflow, use Amazon RDS for storing intermediate results, and deploy the model using Amazon SageMaker endpoints - Manually managing each step of the ML workflow using EC2 instances and RDS is labor-intensive, prone to errors, and not scalable. It also lacks the automation and orchestration capabilities needed for a robust ML workflow.
Use AWS Glue for data preprocessing, Amazon SageMaker for model training and tuning, and manually deploy the model to an Amazon EC2 instance for inference - While using AWS Glue for data preprocessing and SageMaker for training is possible, manually deploying the model on EC2 lacks the orchestration and management features provided by SageMaker Pipelines. This approach also misses out on the integrated tracking, automation, and scalability features offered by SageMaker Pipelines.
Reference:
https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines.html
Question 19 Single Choice
You are a lead machine learning engineer at a growing tech startup that is developing a recommendation system for a mobile app. The recommendation engine must be able to scale quickly as the user base grows, remain cost-effective to align with the startup’s budget constraints, and be easy to maintain by a small team of engineers. The company has decided to use AWS for the ML infrastructure. Your goal is to design an infrastructure that meets these needs, ensuring that it can handle rapid scaling, remains within budget, and is simple to update and monitor.
Which combination of practices and AWS services is MOST LIKELY to result in a maintainable, scalable, and cost-effective ML infrastructure?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use Amazon SageMaker for both training and deployment, leverage auto-scaling endpoints for real-time inference, and apply SageMaker Pipelines for orchestrating end-to-end ML workflows, ensuring scalability and automation
Amazon SageMaker provides a managed service for both training and deployment, which simplifies the infrastructure and reduces operational overhead. Auto-scaling endpoints in SageMaker ensure the system can handle increasing demand without manual intervention. SageMaker Pipelines automates the entire ML workflow, enabling continuous integration and delivery (CI/CD) practices, making the infrastructure scalable, maintainable, and cost-effective.
Incorrect options:
Implement Amazon SageMaker for model training, deploy the models using Amazon EC2 with manual scaling to handle inference, and use AWS CloudFormation for managing infrastructure as code to ensure repeatability - Using Amazon SageMaker for training and Amazon EC2 for inference with manual scaling can work, but it requires more effort to manage scaling, and manually managing infrastructure is less maintainable. Auto-scaling and automation would be more effective for a growing startup.
Train models using Amazon EMR for cost efficiency, deploy the models using AWS Lambda for serverless inference, and manually monitor the system using CloudWatch to reduce operational overhead - While Amazon EMR is cost-effective for big data processing, it’s not optimized for ML model training in the same way that SageMaker is. AWS Lambda is useful for serverless inference but may not scale effectively for high-volume, real-time recommendations. Manual monitoring adds operational overhead.
Use Amazon SageMaker for training, deploy models on Amazon ECS for flexible scaling, and implement infrastructure monitoring with a combination of CloudWatch and AWS Systems Manager to ensure maintainability - Amazon ECS offers flexible scaling, but SageMaker’s auto-scaling capabilities and built-in integration with ML workflows make it more suitable for this use case. Additionally, SageMaker Pipelines offers better orchestration for ML tasks compared to a manually managed solution.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/endpoint-auto-scaling-prerequisites.html
https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines.html
Explanation
Correct option:
Use Amazon SageMaker for both training and deployment, leverage auto-scaling endpoints for real-time inference, and apply SageMaker Pipelines for orchestrating end-to-end ML workflows, ensuring scalability and automation
Amazon SageMaker provides a managed service for both training and deployment, which simplifies the infrastructure and reduces operational overhead. Auto-scaling endpoints in SageMaker ensure the system can handle increasing demand without manual intervention. SageMaker Pipelines automates the entire ML workflow, enabling continuous integration and delivery (CI/CD) practices, making the infrastructure scalable, maintainable, and cost-effective.
Incorrect options:
Implement Amazon SageMaker for model training, deploy the models using Amazon EC2 with manual scaling to handle inference, and use AWS CloudFormation for managing infrastructure as code to ensure repeatability - Using Amazon SageMaker for training and Amazon EC2 for inference with manual scaling can work, but it requires more effort to manage scaling, and manually managing infrastructure is less maintainable. Auto-scaling and automation would be more effective for a growing startup.
Train models using Amazon EMR for cost efficiency, deploy the models using AWS Lambda for serverless inference, and manually monitor the system using CloudWatch to reduce operational overhead - While Amazon EMR is cost-effective for big data processing, it’s not optimized for ML model training in the same way that SageMaker is. AWS Lambda is useful for serverless inference but may not scale effectively for high-volume, real-time recommendations. Manual monitoring adds operational overhead.
Use Amazon SageMaker for training, deploy models on Amazon ECS for flexible scaling, and implement infrastructure monitoring with a combination of CloudWatch and AWS Systems Manager to ensure maintainability - Amazon ECS offers flexible scaling, but SageMaker’s auto-scaling capabilities and built-in integration with ML workflows make it more suitable for this use case. Additionally, SageMaker Pipelines offers better orchestration for ML tasks compared to a manually managed solution.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/endpoint-auto-scaling-prerequisites.html
https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines.html
Question 20 Multiple Choice
You are a Machine Learning Engineer working for a large retail company that has developed multiple machine learning models to improve various aspects of their business, including personalized recommendations, generative AI, and fraud detection. The models have different deployment requirements:
The recommendations models need to handle real-time inference with low latency.
The generative AI model requires high scalability to manage fluctuating loads.
The fraud detection model is a large model and needs to be integrated into serverless applications to minimize infrastructure management.
Which of the following deployment targets should you choose for the different machine learning models, given their specific requirements? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Deploy the real-time recommendation model using Amazon SageMaker endpoints to ensure low-latency, high-availability, and managed infrastructure for real-time inference
Real-time inference is ideal for inference workloads where you have real-time, interactive, low latency requirements. You can deploy your model to SageMaker hosting services and get an endpoint that can be used for inference. These endpoints are fully managed and support autoscaling.
This makes it an ideal choice for the recommendation model, which must provide fast responses to user interactions with minimal downtime.
Deploy the generative AI model using Amazon Elastic Kubernetes Service (Amazon EKS) to leverage containerized microservices for high scalability and control over the deployment environment
Amazon EKS is designed for containerized applications that need high scalability and flexibility. It is suitable for the generative AI model, which may require complex orchestration and scaling in response to varying demand, while giving you full control over the deployment environment.
 via - https://aws.amazon.com/blogs/containers/deploy-generative-ai-models-on-amazon-eks/
via - https://aws.amazon.com/blogs/containers/deploy-generative-ai-models-on-amazon-eks/
Incorrect options:
Use AWS Lambda to deploy the fraud detection model, which requires rapid scaling and integration into an existing serverless architecture, minimizing infrastructure management - While AWS Lambda is excellent for serverless applications, it may not be the best choice for a fraud detection model if it requires continuous, low-latency processing or needs to handle very high throughput. Lambda is better suited for lightweight, event-driven tasks rather than long-running, complex inference jobs.
Choose Amazon Elastic Container Service (Amazon ECS) for the recommendation model, as it provides container orchestration for large-scale, batch processing workloads with tight integration into other AWS services - Amazon ECS is a good choice for containerized workloads but is generally more appropriate for batch processing or large-scale, stateless applications. It might not provide the low-latency and real-time capabilities needed for the recommendation model.
Deploy all models using Amazon SageMaker endpoints for consistency and ease of management, regardless of their individual requirements for scalability, latency, or integration - Deploying all models using Amazon SageMaker endpoints without considering their specific requirements for latency, scalability, and integration would be suboptimal. While SageMaker endpoints are highly versatile, they may not be the best fit for every use case, especially for models requiring serverless architecture or advanced container orchestration.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/realtime-endpoints.html
https://aws.amazon.com/blogs/containers/deploy-generative-ai-models-on-amazon-eks/
Explanation
Correct options:
Deploy the real-time recommendation model using Amazon SageMaker endpoints to ensure low-latency, high-availability, and managed infrastructure for real-time inference
Real-time inference is ideal for inference workloads where you have real-time, interactive, low latency requirements. You can deploy your model to SageMaker hosting services and get an endpoint that can be used for inference. These endpoints are fully managed and support autoscaling.
This makes it an ideal choice for the recommendation model, which must provide fast responses to user interactions with minimal downtime.
Deploy the generative AI model using Amazon Elastic Kubernetes Service (Amazon EKS) to leverage containerized microservices for high scalability and control over the deployment environment
Amazon EKS is designed for containerized applications that need high scalability and flexibility. It is suitable for the generative AI model, which may require complex orchestration and scaling in response to varying demand, while giving you full control over the deployment environment.
via - https://aws.amazon.com/blogs/containers/deploy-generative-ai-models-on-amazon-eks/
Incorrect options:
Use AWS Lambda to deploy the fraud detection model, which requires rapid scaling and integration into an existing serverless architecture, minimizing infrastructure management - While AWS Lambda is excellent for serverless applications, it may not be the best choice for a fraud detection model if it requires continuous, low-latency processing or needs to handle very high throughput. Lambda is better suited for lightweight, event-driven tasks rather than long-running, complex inference jobs.
Choose Amazon Elastic Container Service (Amazon ECS) for the recommendation model, as it provides container orchestration for large-scale, batch processing workloads with tight integration into other AWS services - Amazon ECS is a good choice for containerized workloads but is generally more appropriate for batch processing or large-scale, stateless applications. It might not provide the low-latency and real-time capabilities needed for the recommendation model.
Deploy all models using Amazon SageMaker endpoints for consistency and ease of management, regardless of their individual requirements for scalability, latency, or integration - Deploying all models using Amazon SageMaker endpoints without considering their specific requirements for latency, scalability, and integration would be suboptimal. While SageMaker endpoints are highly versatile, they may not be the best fit for every use case, especially for models requiring serverless architecture or advanced container orchestration.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/realtime-endpoints.html
https://aws.amazon.com/blogs/containers/deploy-generative-ai-models-on-amazon-eks/


