
AWS Certified Solutions Architect - Associate - (SAA-C03) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 1 Multiple Choice
A company manages a multi-tier social media application that runs on Amazon Elastic Compute Cloud (Amazon EC2) instances behind an Application Load Balancer. The instances run in an Amazon EC2 Auto Scaling group across multiple Availability Zones (AZs) and use an Amazon Aurora database. As an AWS Certified Solutions Architect – Associate, you have been tasked to make the application more resilient to periodic spikes in request rates.
Which of the following solutions would you recommend for the given use-case? (Select two)
Explanation

Click "Show Answer" to see the explanation here
Correct options:
You can use Amazon Aurora replicas and Amazon CloudFront distribution to make the application more resilient to spikes in request rates.
Use Amazon Aurora Replica
Amazon Aurora Replicas have two main purposes. You can issue queries to them to scale the read operations for your application. You typically do so by connecting to the reader endpoint of the cluster. That way, Aurora can spread the load for read-only connections across as many Aurora Replicas as you have in the cluster. Amazon Aurora Replicas also help to increase availability. If the writer instance in a cluster becomes unavailable, Aurora automatically promotes one of the reader instances to take its place as the new writer. Up to 15 Aurora Replicas can be distributed across the Availability Zones (AZs) that a DB cluster spans within an AWS Region.
Use Amazon CloudFront distribution in front of the Application Load Balancer
Amazon CloudFront is a fast content delivery network (CDN) service that securely delivers data, videos, applications, and APIs to customers globally with low latency, high transfer speeds, all within a developer-friendly environment. CloudFront points of presence (POPs) (edge locations) make sure that popular content can be served quickly to your viewers. Amazon CloudFront also has regional edge caches that bring more of your content closer to your viewers, even when the content is not popular enough to stay at a POP, to help improve performance for that content.
Amazon CloudFront offers an origin failover feature to help support your data resiliency needs. Amazon CloudFront is a global service that delivers your content through a worldwide network of data centers called edge locations or points of presence (POPs). If your content is not already cached in an edge location, Amazon CloudFront retrieves it from an origin that you've identified as the source for the definitive version of the content.
Incorrect options:
Use AWS Shield - AWS Shield is a managed Distributed Denial of Service (DDoS) protection service that safeguards applications running on AWS. AWS Shield provides always-on detection and automatic inline mitigations that minimize application downtime and latency. There are two tiers of AWS Shield - Standard and Advanced. AWS Shield cannot be used to improve application resiliency to handle spikes in traffic.
Use AWS Global Accelerator - AWS Global Accelerator is a service that improves the availability and performance of your applications with local or global users. It provides static IP addresses that act as a fixed entry point to your application endpoints in a single or multiple AWS Regions, such as your Application Load Balancers, Network Load Balancers or Amazon EC2 instances. Amazon Global Accelerator is a good fit for non-HTTP use cases, such as gaming (UDP), IoT (MQTT), or Voice over IP, as well as for HTTP use cases that specifically require static IP addresses or deterministic, fast regional failover. Since Amazon CloudFront is better for improving application resiliency to handle spikes in traffic, so this option is ruled out.
Use AWS Direct Connect - AWS Direct Connect lets you establish a dedicated network connection between your network and one of the AWS Direct Connect locations. Using industry-standard 802.1q VLANs, this dedicated connection can be partitioned into multiple virtual interfaces. AWS Direct Connect does not involve the Internet; instead, it uses dedicated, private network connections between your intranet and Amazon VPC. AWS Direct Connect cannot be used to improve application resiliency to handle spikes in traffic.
References:
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/disaster-recovery-resiliency.html
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Replication.html
https://aws.amazon.com/global-accelerator/faqs/
https://docs.aws.amazon.com/global-accelerator/latest/dg/disaster-recovery-resiliency.html
Explanation
Correct options:
You can use Amazon Aurora replicas and Amazon CloudFront distribution to make the application more resilient to spikes in request rates.
Use Amazon Aurora Replica
Amazon Aurora Replicas have two main purposes. You can issue queries to them to scale the read operations for your application. You typically do so by connecting to the reader endpoint of the cluster. That way, Aurora can spread the load for read-only connections across as many Aurora Replicas as you have in the cluster. Amazon Aurora Replicas also help to increase availability. If the writer instance in a cluster becomes unavailable, Aurora automatically promotes one of the reader instances to take its place as the new writer. Up to 15 Aurora Replicas can be distributed across the Availability Zones (AZs) that a DB cluster spans within an AWS Region.
Use Amazon CloudFront distribution in front of the Application Load Balancer
Amazon CloudFront is a fast content delivery network (CDN) service that securely delivers data, videos, applications, and APIs to customers globally with low latency, high transfer speeds, all within a developer-friendly environment. CloudFront points of presence (POPs) (edge locations) make sure that popular content can be served quickly to your viewers. Amazon CloudFront also has regional edge caches that bring more of your content closer to your viewers, even when the content is not popular enough to stay at a POP, to help improve performance for that content.
Amazon CloudFront offers an origin failover feature to help support your data resiliency needs. Amazon CloudFront is a global service that delivers your content through a worldwide network of data centers called edge locations or points of presence (POPs). If your content is not already cached in an edge location, Amazon CloudFront retrieves it from an origin that you've identified as the source for the definitive version of the content.
Incorrect options:
Use AWS Shield - AWS Shield is a managed Distributed Denial of Service (DDoS) protection service that safeguards applications running on AWS. AWS Shield provides always-on detection and automatic inline mitigations that minimize application downtime and latency. There are two tiers of AWS Shield - Standard and Advanced. AWS Shield cannot be used to improve application resiliency to handle spikes in traffic.
Use AWS Global Accelerator - AWS Global Accelerator is a service that improves the availability and performance of your applications with local or global users. It provides static IP addresses that act as a fixed entry point to your application endpoints in a single or multiple AWS Regions, such as your Application Load Balancers, Network Load Balancers or Amazon EC2 instances. Amazon Global Accelerator is a good fit for non-HTTP use cases, such as gaming (UDP), IoT (MQTT), or Voice over IP, as well as for HTTP use cases that specifically require static IP addresses or deterministic, fast regional failover. Since Amazon CloudFront is better for improving application resiliency to handle spikes in traffic, so this option is ruled out.
Use AWS Direct Connect - AWS Direct Connect lets you establish a dedicated network connection between your network and one of the AWS Direct Connect locations. Using industry-standard 802.1q VLANs, this dedicated connection can be partitioned into multiple virtual interfaces. AWS Direct Connect does not involve the Internet; instead, it uses dedicated, private network connections between your intranet and Amazon VPC. AWS Direct Connect cannot be used to improve application resiliency to handle spikes in traffic.
References:
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/disaster-recovery-resiliency.html
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Replication.html
https://aws.amazon.com/global-accelerator/faqs/
https://docs.aws.amazon.com/global-accelerator/latest/dg/disaster-recovery-resiliency.html
Question 2 Multiple Choice
An IT consultant is helping the owner of a medium-sized business set up an AWS account. What are the security recommendations he must follow while creating the AWS account root user? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Create a strong password for the AWS account root user
Enable Multi Factor Authentication (MFA) for the AWS account root user account
Here are some of the best practices while creating an AWS account root user:
1) Use a strong password to help protect account-level access to the AWS Management Console. 2) Never share your AWS account root user password or access keys with anyone. 3) If you do have an access key for your AWS account root user, delete it. If you must keep it, rotate (change) the access key regularly. You should not encrypt the access keys and save them on Amazon S3. 4) If you don't already have an access key for your AWS account root user, don't create one unless you absolutely need to. 5) Enable AWS multi-factor authentication (MFA) on your AWS account root user account.
AWS Root Account Security Best Practices: 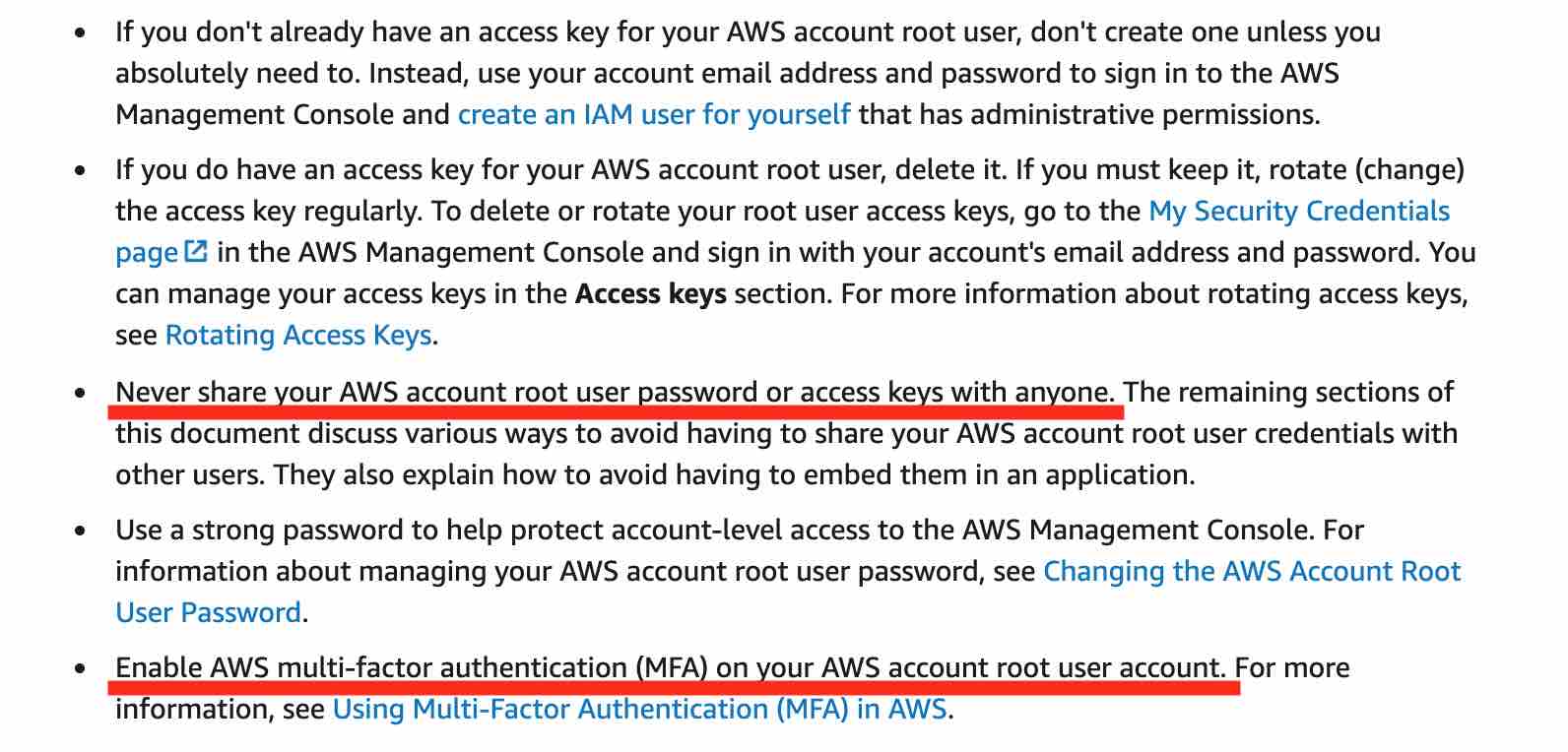 via - https://docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html
via - https://docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html
Incorrect options:
Encrypt the access keys and save them on Amazon S3 - AWS recommends that if you don't already have an access key for your AWS account root user, don't create one unless you absolutely need to. Even an encrypted access key for the root user poses a significant security risk. Therefore, this option is incorrect.
Create AWS account root user access keys and share those keys only with the business owner - AWS recommends that if you don't already have an access key for your AWS account root user, don't create one unless you absolutely need to. Hence, this option is incorrect.
Send an email to the business owner with details of the login username and password for the AWS root user. This will help the business owner to troubleshoot any login issues in future - AWS recommends that you should never share your AWS account root user password or access keys with anyone. Sending an email with AWS account root user credentials creates a security risk as it can be misused by anyone reading the email. Hence, this option is incorrect.
Reference:
https://docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html#create-iam-users
Explanation
Correct options:
Create a strong password for the AWS account root user
Enable Multi Factor Authentication (MFA) for the AWS account root user account
Here are some of the best practices while creating an AWS account root user:
1) Use a strong password to help protect account-level access to the AWS Management Console. 2) Never share your AWS account root user password or access keys with anyone. 3) If you do have an access key for your AWS account root user, delete it. If you must keep it, rotate (change) the access key regularly. You should not encrypt the access keys and save them on Amazon S3. 4) If you don't already have an access key for your AWS account root user, don't create one unless you absolutely need to. 5) Enable AWS multi-factor authentication (MFA) on your AWS account root user account.
AWS Root Account Security Best Practices: via - https://docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html
Incorrect options:
Encrypt the access keys and save them on Amazon S3 - AWS recommends that if you don't already have an access key for your AWS account root user, don't create one unless you absolutely need to. Even an encrypted access key for the root user poses a significant security risk. Therefore, this option is incorrect.
Create AWS account root user access keys and share those keys only with the business owner - AWS recommends that if you don't already have an access key for your AWS account root user, don't create one unless you absolutely need to. Hence, this option is incorrect.
Send an email to the business owner with details of the login username and password for the AWS root user. This will help the business owner to troubleshoot any login issues in future - AWS recommends that you should never share your AWS account root user password or access keys with anyone. Sending an email with AWS account root user credentials creates a security risk as it can be misused by anyone reading the email. Hence, this option is incorrect.
Reference:
https://docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html#create-iam-users
Question 3 Multiple Choice
The IT department at a consulting firm is conducting a training workshop for new developers. As part of an evaluation exercise on Amazon S3, the new developers were asked to identify the invalid storage class lifecycle transitions for objects stored on Amazon S3.
Can you spot the INVALID lifecycle transitions from the options below? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
As the question wants to know about the INVALID lifecycle transitions, the following options are the correct answers -
Amazon S3 Intelligent-Tiering => Amazon S3 Standard
Amazon S3 One Zone-IA => Amazon S3 Standard-IA
Following are the unsupported life cycle transitions for S3 storage classes - Any storage class to the Amazon S3 Standard storage class. Any storage class to the Reduced Redundancy storage class. The Amazon S3 Intelligent-Tiering storage class to the Amazon S3 Standard-IA storage class. The Amazon S3 One Zone-IA storage class to the Amazon S3 Standard-IA or Amazon S3 Intelligent-Tiering storage classes.
Incorrect options:
Amazon S3 Standard => Amazon S3 Intelligent-Tiering
Amazon S3 Standard-IA => Amazon S3 Intelligent-Tiering
Amazon S3 Standard-IA => Amazon S3 One Zone-IA
Here are the supported life cycle transitions for S3 storage classes - The S3 Standard storage class to any other storage class. Any storage class to the S3 Glacier or S3 Glacier Deep Archive storage classes. The S3 Standard-IA storage class to the S3 Intelligent-Tiering or S3 One Zone-IA storage classes. The S3 Intelligent-Tiering storage class to the S3 One Zone-IA storage class. The S3 Glacier storage class to the S3 Glacier Deep Archive storage class.
Amazon S3 supports a waterfall model for transitioning between storage classes, as shown in the diagram below: 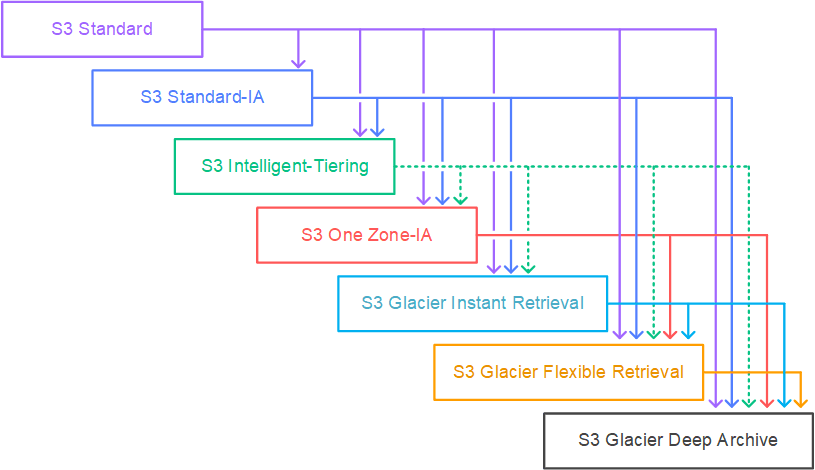 via - https://docs.aws.amazon.com/AmazonS3/latest/userguide/lifecycle-transition-general-considerations.html
via - https://docs.aws.amazon.com/AmazonS3/latest/userguide/lifecycle-transition-general-considerations.html
Reference:
Explanation
Correct options:
As the question wants to know about the INVALID lifecycle transitions, the following options are the correct answers -
Amazon S3 Intelligent-Tiering => Amazon S3 Standard
Amazon S3 One Zone-IA => Amazon S3 Standard-IA
Following are the unsupported life cycle transitions for S3 storage classes - Any storage class to the Amazon S3 Standard storage class. Any storage class to the Reduced Redundancy storage class. The Amazon S3 Intelligent-Tiering storage class to the Amazon S3 Standard-IA storage class. The Amazon S3 One Zone-IA storage class to the Amazon S3 Standard-IA or Amazon S3 Intelligent-Tiering storage classes.
Incorrect options:
Amazon S3 Standard => Amazon S3 Intelligent-Tiering
Amazon S3 Standard-IA => Amazon S3 Intelligent-Tiering
Amazon S3 Standard-IA => Amazon S3 One Zone-IA
Here are the supported life cycle transitions for S3 storage classes - The S3 Standard storage class to any other storage class. Any storage class to the S3 Glacier or S3 Glacier Deep Archive storage classes. The S3 Standard-IA storage class to the S3 Intelligent-Tiering or S3 One Zone-IA storage classes. The S3 Intelligent-Tiering storage class to the S3 One Zone-IA storage class. The S3 Glacier storage class to the S3 Glacier Deep Archive storage class.
Amazon S3 supports a waterfall model for transitioning between storage classes, as shown in the diagram below: via - https://docs.aws.amazon.com/AmazonS3/latest/userguide/lifecycle-transition-general-considerations.html
Reference:
Question 4 Single Choice
The engineering team at a Spanish professional football club has built a notification system for its website using Amazon Simple Notification Service (Amazon SNS) notifications which are then handled by an AWS Lambda function for end-user delivery. During the off-season, the notification systems need to handle about 100 requests per second. During the peak football season, the rate touches about 5000 requests per second and it is noticed that a significant number of the notifications are not being delivered to the end-users on the website.
As a solutions architect, which of the following would you suggest as the BEST possible solution to this issue?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Amazon SNS message deliveries to AWS Lambda have crossed the account concurrency quota for AWS Lambda, so the team needs to contact AWS support to raise the account limit
Amazon Simple Notification Service (Amazon SNS) is a highly available, durable, secure, fully managed pub/sub messaging service that enables you to decouple microservices, distributed systems, and serverless applications.
How Amazon SNS Works: 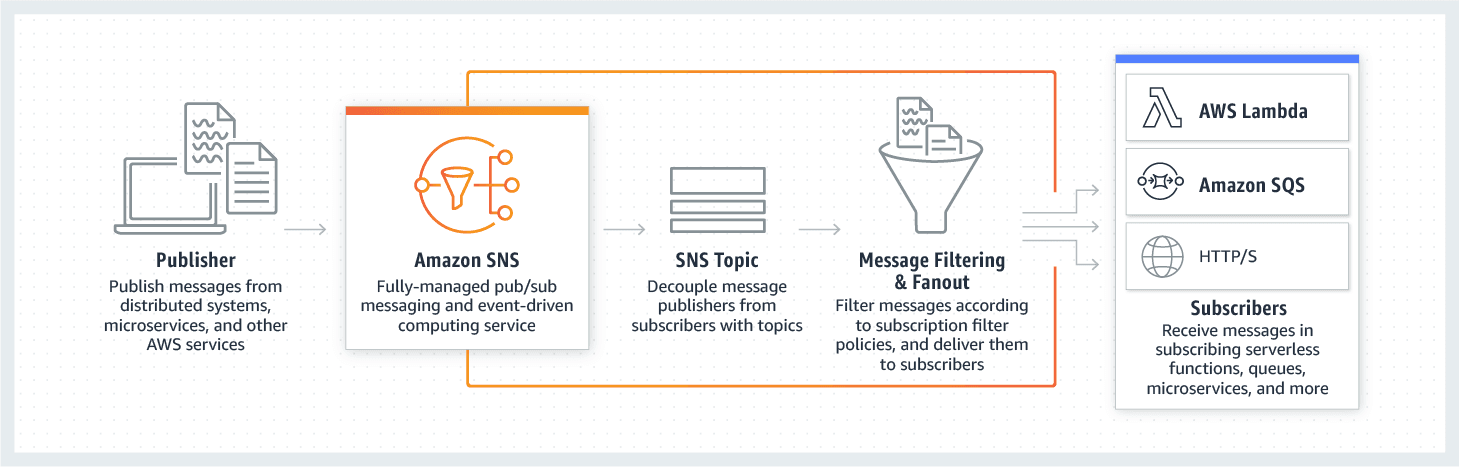 via - https://aws.amazon.com/sns/
via - https://aws.amazon.com/sns/
With AWS Lambda, you can run code without provisioning or managing servers. You pay only for the compute time that you consume—there’s no charge when your code isn’t running.
AWS Lambda currently supports 1000 concurrent executions per AWS account per region. If your Amazon SNS message deliveries to AWS Lambda contribute to crossing these concurrency quotas, your Amazon SNS message deliveries will be throttled. You need to contact AWS support to raise the account limit. Therefore this option is correct.
Incorrect options:
Amazon SNS has hit a scalability limit, so the team needs to contact AWS support to raise the account limit - Amazon SNS leverages the proven AWS cloud to dynamically scale with your application. You don't need to contact AWS support, as SNS is a fully managed service, taking care of the heavy lifting related to capacity planning, provisioning, monitoring, and patching. Therefore, this option is incorrect.
The engineering team needs to provision more servers running the Amazon SNS service
The engineering team needs to provision more servers running the AWS Lambda service
As both AWS Lambda and Amazon SNS are serverless and fully managed services, the engineering team cannot provision more servers. Both of these options are incorrect.
References:
Explanation
Correct option:
Amazon SNS message deliveries to AWS Lambda have crossed the account concurrency quota for AWS Lambda, so the team needs to contact AWS support to raise the account limit
Amazon Simple Notification Service (Amazon SNS) is a highly available, durable, secure, fully managed pub/sub messaging service that enables you to decouple microservices, distributed systems, and serverless applications.
How Amazon SNS Works: via - https://aws.amazon.com/sns/
With AWS Lambda, you can run code without provisioning or managing servers. You pay only for the compute time that you consume—there’s no charge when your code isn’t running.
AWS Lambda currently supports 1000 concurrent executions per AWS account per region. If your Amazon SNS message deliveries to AWS Lambda contribute to crossing these concurrency quotas, your Amazon SNS message deliveries will be throttled. You need to contact AWS support to raise the account limit. Therefore this option is correct.
Incorrect options:
Amazon SNS has hit a scalability limit, so the team needs to contact AWS support to raise the account limit - Amazon SNS leverages the proven AWS cloud to dynamically scale with your application. You don't need to contact AWS support, as SNS is a fully managed service, taking care of the heavy lifting related to capacity planning, provisioning, monitoring, and patching. Therefore, this option is incorrect.
The engineering team needs to provision more servers running the Amazon SNS service
The engineering team needs to provision more servers running the AWS Lambda service
As both AWS Lambda and Amazon SNS are serverless and fully managed services, the engineering team cannot provision more servers. Both of these options are incorrect.
References:
Question 5 Single Choice
An e-commerce company is looking for a solution with high availability, as it plans to migrate its flagship application to a fleet of Amazon Elastic Compute Cloud (Amazon EC2) instances. The solution should allow for content-based routing as part of the architecture.
As a Solutions Architect, which of the following will you suggest for the company?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use an Application Load Balancer for distributing traffic to the Amazon EC2 instances spread across different Availability Zones (AZs). Configure Auto Scaling group to mask any failure of an instance
The Application Load Balancer (ALB) is best suited for load balancing HTTP and HTTPS traffic and provides advanced request routing targeted at the delivery of modern application architectures, including microservices and containers. Operating at the individual request level (Layer 7), the Application Load Balancer routes traffic to targets within Amazon Virtual Private Cloud (Amazon VPC) based on the content of the request.
This is the correct option since the question has a specific requirement for content-based routing which can be configured via the Application Load Balancer. Different Availability Zones (AZs) provide high availability to the overall architecture and Auto Scaling group will help mask any instance failures.
More info on Application Load Balancer: 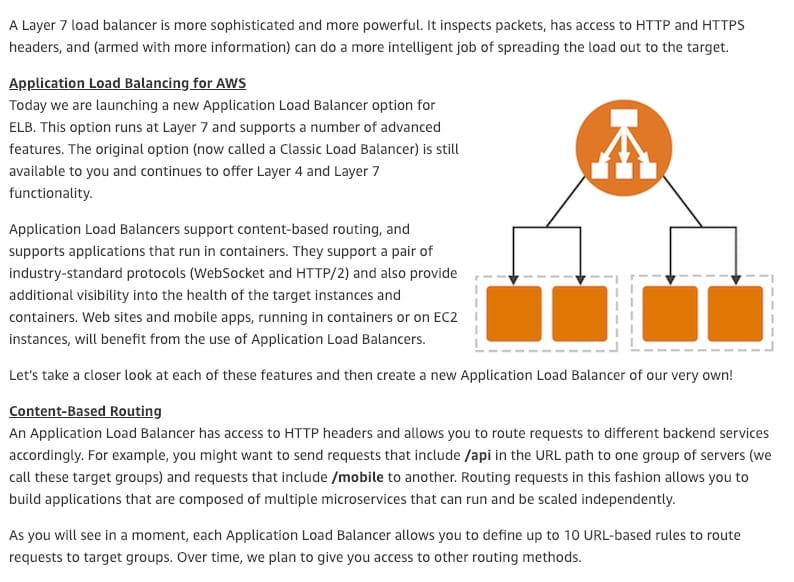 via - https://aws.amazon.com/blogs/aws/new-aws-application-load-balancer/
via - https://aws.amazon.com/blogs/aws/new-aws-application-load-balancer/
Incorrect options:
Use a Network Load Balancer for distributing traffic to the Amazon EC2 instances spread across different Availability Zones (AZs). Configure a Private IP address to mask any failure of an instance - Network Load Balancer cannot facilitate content-based routing so this option is incorrect.
Use an Auto Scaling group for distributing traffic to the Amazon EC2 instances spread across different Availability Zones (AZs). Configure an elastic IP address (EIP) to mask any failure of an instance
Use an Auto Scaling group for distributing traffic to the Amazon EC2 instances spread across different Availability Zones (AZs). Configure a Public IP address to mask any failure of an instance
Both these options are incorrect as you cannot use the Auto Scaling group to distribute traffic to the Amazon EC2 instances.
An elastic IP address (EIP) is a static, public, IPv4 address allocated to your AWS account. With an Elastic IP address, you can mask the failure of an instance or software by rapidly remapping the address to another instance in your account. Elastic IPs do not change and remain allocated to your account until you delete them.
More info on Elastic Load Balancing (ELB):  via - https://docs.aws.amazon.com/whitepapers/latest/fault-tolerant-components/fault-tolerant-components.pdf
via - https://docs.aws.amazon.com/whitepapers/latest/fault-tolerant-components/fault-tolerant-components.pdf
You can span your Auto Scaling group across multiple Availability Zones (AZs) within an AWS Region and then attaching a load balancer to distribute incoming traffic across those zones.
 via - https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-add-availability-zone.html
via - https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-add-availability-zone.html
References:
https://aws.amazon.com/blogs/aws/new-aws-application-load-balancer/
https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-add-availability-zone.html
Explanation
Correct option:
Use an Application Load Balancer for distributing traffic to the Amazon EC2 instances spread across different Availability Zones (AZs). Configure Auto Scaling group to mask any failure of an instance
The Application Load Balancer (ALB) is best suited for load balancing HTTP and HTTPS traffic and provides advanced request routing targeted at the delivery of modern application architectures, including microservices and containers. Operating at the individual request level (Layer 7), the Application Load Balancer routes traffic to targets within Amazon Virtual Private Cloud (Amazon VPC) based on the content of the request.
This is the correct option since the question has a specific requirement for content-based routing which can be configured via the Application Load Balancer. Different Availability Zones (AZs) provide high availability to the overall architecture and Auto Scaling group will help mask any instance failures.
More info on Application Load Balancer: via - https://aws.amazon.com/blogs/aws/new-aws-application-load-balancer/
Incorrect options:
Use a Network Load Balancer for distributing traffic to the Amazon EC2 instances spread across different Availability Zones (AZs). Configure a Private IP address to mask any failure of an instance - Network Load Balancer cannot facilitate content-based routing so this option is incorrect.
Use an Auto Scaling group for distributing traffic to the Amazon EC2 instances spread across different Availability Zones (AZs). Configure an elastic IP address (EIP) to mask any failure of an instance
Use an Auto Scaling group for distributing traffic to the Amazon EC2 instances spread across different Availability Zones (AZs). Configure a Public IP address to mask any failure of an instance
Both these options are incorrect as you cannot use the Auto Scaling group to distribute traffic to the Amazon EC2 instances.
An elastic IP address (EIP) is a static, public, IPv4 address allocated to your AWS account. With an Elastic IP address, you can mask the failure of an instance or software by rapidly remapping the address to another instance in your account. Elastic IPs do not change and remain allocated to your account until you delete them.
More info on Elastic Load Balancing (ELB): via - https://docs.aws.amazon.com/whitepapers/latest/fault-tolerant-components/fault-tolerant-components.pdf
You can span your Auto Scaling group across multiple Availability Zones (AZs) within an AWS Region and then attaching a load balancer to distribute incoming traffic across those zones.
via - https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-add-availability-zone.html
References:
https://aws.amazon.com/blogs/aws/new-aws-application-load-balancer/
https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-add-availability-zone.html
Question 6 Single Choice
A company is in the process of migrating its on-premises SMB file shares to AWS so the company can get out of the business of managing multiple file servers across dozens of offices. The company has 200 terabytes of data in its file servers. The existing on-premises applications and native Windows workloads should continue to have low latency access to this data which needs to be stored on a file system service without any disruptions after the migration. The company also wants any new applications deployed on AWS to have access to this migrated data.
Which of the following is the best solution to meet this requirement?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use Amazon FSx File Gateway to provide low-latency, on-premises access to fully managed file shares in Amazon FSx for Windows File Server. The applications deployed on AWS can access this data directly from Amazon FSx in AWS
For user or team file shares, and file-based application migrations, Amazon FSx File Gateway provides low-latency, on-premises access to fully managed file shares in Amazon FSx for Windows File Server. For applications deployed on AWS, you may access your file shares directly from Amazon FSx in AWS.
For your native Windows workloads and users, or your SMB clients, Amazon FSx for Windows File Server provides all of the benefits of a native Windows SMB environment that is fully managed and secured and scaled like any other AWS service. You get detailed reporting, replication, backup, failover, and support for native Windows tools like DFS and Active Directory.
Amazon FSx File Gateway: 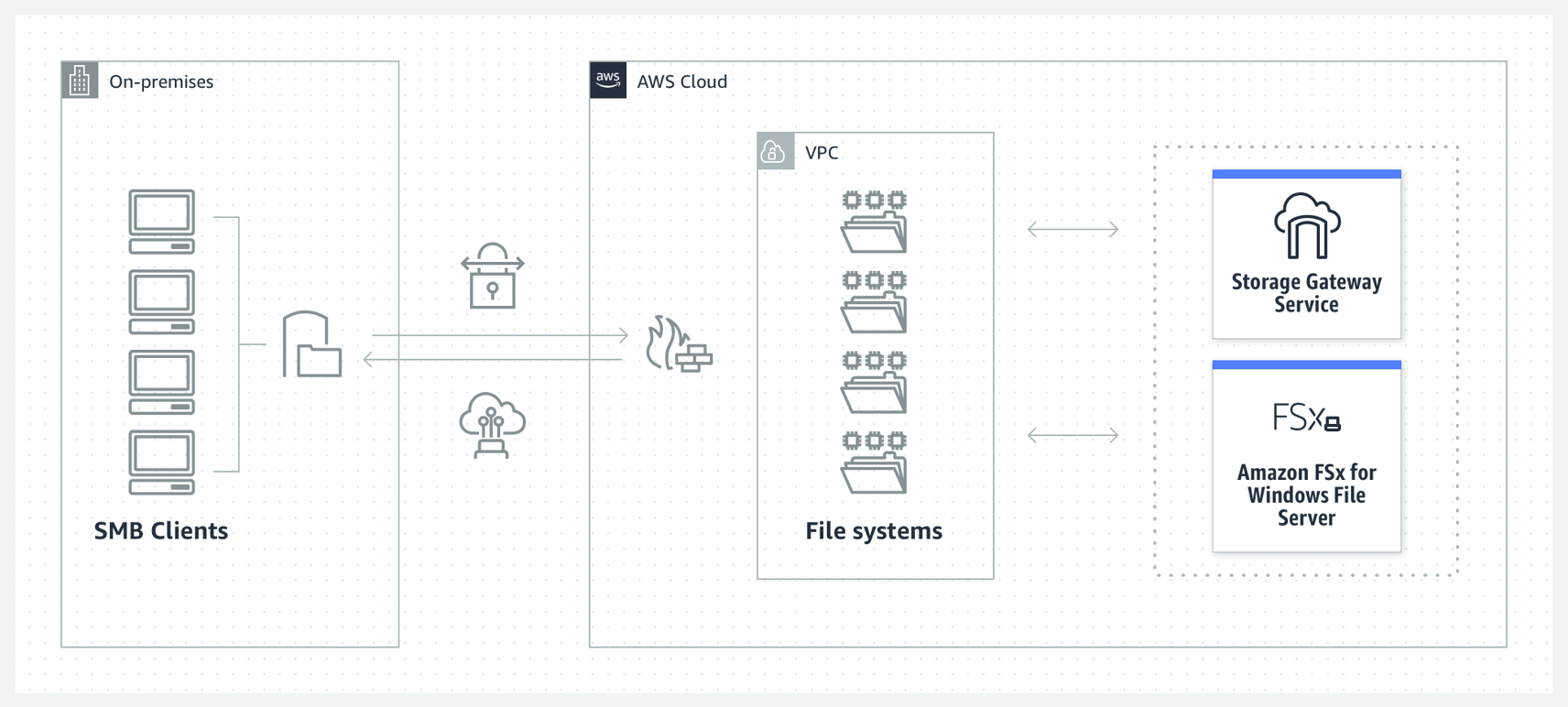 via - https://aws.amazon.com/storagegateway/file/
via - https://aws.amazon.com/storagegateway/file/
Incorrect options:
Use Amazon Storage Gateway’s File Gateway to provide low-latency, on-premises access to fully managed file shares in Amazon FSx for Windows File Server. The applications deployed on AWS can access this data directly from Amazon FSx in AWS - When you need to access S3 using a file system protocol, you should use File Gateway. You get a local cache in the gateway that provides high throughput and low latency over SMB.
AWS Storage Gateway’s File Gateway does not support file shares in Amazon FSx for Windows File Server, so this option is incorrect.
AWS Storage Gateway’s File Gateway: 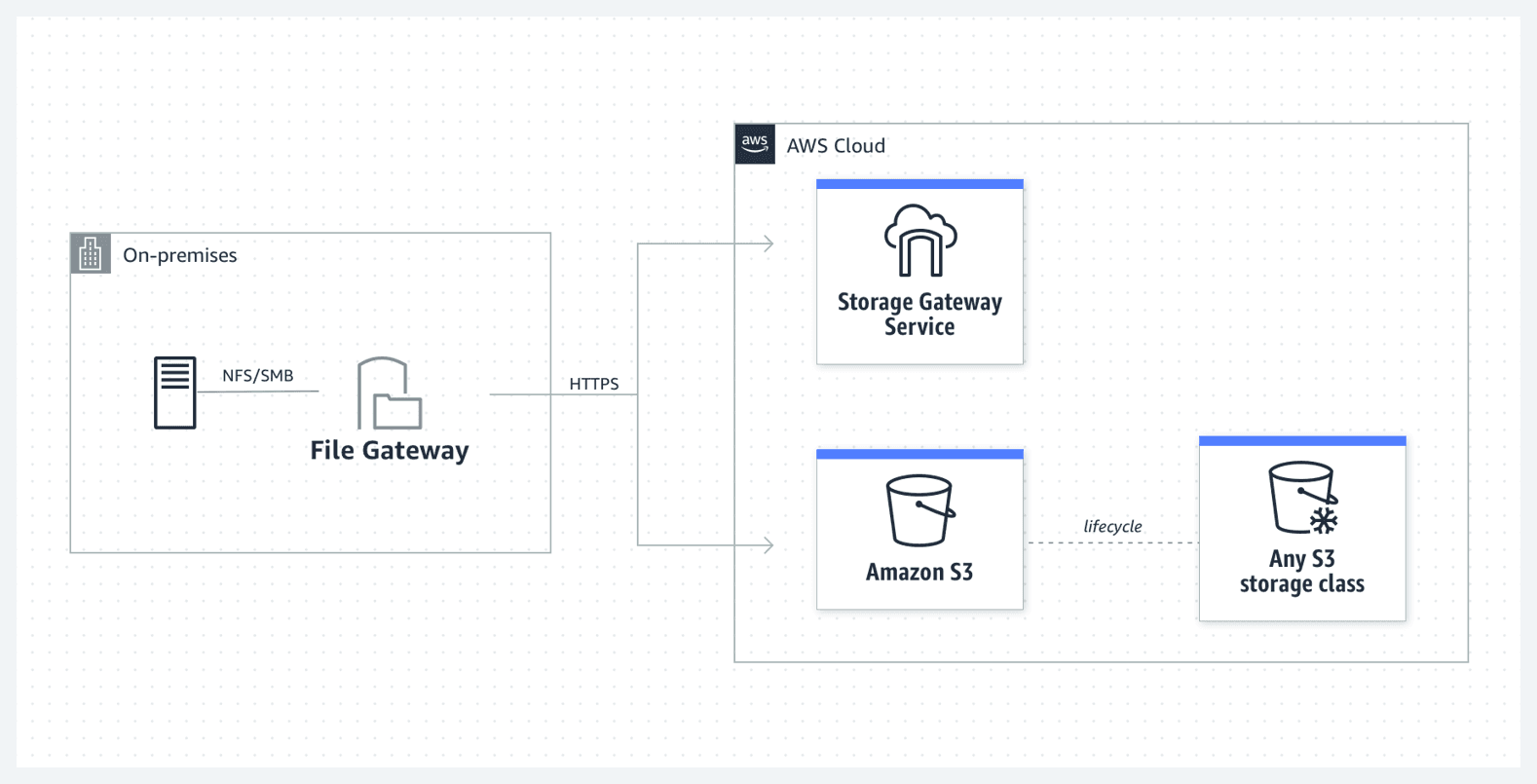
Use AWS Storage Gateway’s File Gateway to provide low-latency, on-premises access to fully managed file shares in Amazon S3. The applications deployed on AWS can access this data directly from Amazon S3 - When you need to access S3 using a file system protocol, you should use File Gateway. You get a local cache in the gateway that provides high throughput and low latency over SMB.
The given use case requires low latency access to data which needs to be stored on a file system service after migration. Since S3 is an object storage service, so this option is incorrect.
Use Amazon FSx File Gateway to provide low-latency, on-premises access to fully managed file shares in Amazon EFS. The applications deployed on AWS can access this data directly from Amazon EFS - Amazon FSx File Gateway provides access to fully managed file shares in Amazon FSx for Windows File Server and it does not support EFS. You should also note that EFS uses the Network File System version 4 (NFS v4) protocol and it does not support SMB protocol. Therefore this option is incorrect for the given use case.
References:
https://aws.amazon.com/storagegateway/file/fsx/
Explanation
Correct option:
Use Amazon FSx File Gateway to provide low-latency, on-premises access to fully managed file shares in Amazon FSx for Windows File Server. The applications deployed on AWS can access this data directly from Amazon FSx in AWS
For user or team file shares, and file-based application migrations, Amazon FSx File Gateway provides low-latency, on-premises access to fully managed file shares in Amazon FSx for Windows File Server. For applications deployed on AWS, you may access your file shares directly from Amazon FSx in AWS.
For your native Windows workloads and users, or your SMB clients, Amazon FSx for Windows File Server provides all of the benefits of a native Windows SMB environment that is fully managed and secured and scaled like any other AWS service. You get detailed reporting, replication, backup, failover, and support for native Windows tools like DFS and Active Directory.
Amazon FSx File Gateway: via - https://aws.amazon.com/storagegateway/file/
Incorrect options:
Use Amazon Storage Gateway’s File Gateway to provide low-latency, on-premises access to fully managed file shares in Amazon FSx for Windows File Server. The applications deployed on AWS can access this data directly from Amazon FSx in AWS - When you need to access S3 using a file system protocol, you should use File Gateway. You get a local cache in the gateway that provides high throughput and low latency over SMB.
AWS Storage Gateway’s File Gateway does not support file shares in Amazon FSx for Windows File Server, so this option is incorrect.
AWS Storage Gateway’s File Gateway:
Use AWS Storage Gateway’s File Gateway to provide low-latency, on-premises access to fully managed file shares in Amazon S3. The applications deployed on AWS can access this data directly from Amazon S3 - When you need to access S3 using a file system protocol, you should use File Gateway. You get a local cache in the gateway that provides high throughput and low latency over SMB.
The given use case requires low latency access to data which needs to be stored on a file system service after migration. Since S3 is an object storage service, so this option is incorrect.
Use Amazon FSx File Gateway to provide low-latency, on-premises access to fully managed file shares in Amazon EFS. The applications deployed on AWS can access this data directly from Amazon EFS - Amazon FSx File Gateway provides access to fully managed file shares in Amazon FSx for Windows File Server and it does not support EFS. You should also note that EFS uses the Network File System version 4 (NFS v4) protocol and it does not support SMB protocol. Therefore this option is incorrect for the given use case.
References:
https://aws.amazon.com/storagegateway/file/fsx/
Question 7 Multiple Choice
The engineering team at an in-home fitness company is evaluating multiple in-memory data stores with the ability to power its on-demand, live leaderboard. The company's leaderboard requires high availability, low latency, and real-time processing to deliver customizable user data for the community of users working out together virtually from the comfort of their home.
As a solutions architect, which of the following solutions would you recommend? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Power the on-demand, live leaderboard using Amazon ElastiCache for Redis as it meets the in-memory, high availability, low latency requirements
Amazon ElastiCache for Redis is a blazing fast in-memory data store that provides sub-millisecond latency to power internet-scale real-time applications. Amazon ElastiCache for Redis is a great choice for real-time transactional and analytical processing use cases such as caching, chat/messaging, gaming leaderboards, geospatial, machine learning, media streaming, queues, real-time analytics, and session store. ElastiCache for Redis can be used to power the live leaderboard, so this option is correct.
Amazon ElastiCache for Redis Overview: 
Power the on-demand, live leaderboard using Amazon DynamoDB with DynamoDB Accelerator (DAX) as it meets the in-memory, high availability, low latency requirements
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It's a fully managed, multiregion, multimaster, durable database with built-in security, backup and restore, and in-memory caching for internet-scale applications. DAX is a DynamoDB-compatible caching service that enables you to benefit from fast in-memory performance for demanding applications. So DynamoDB with DAX can be used to power the live leaderboard.
Incorrect options:
Power the on-demand, live leaderboard using Amazon Neptune as it meets the in-memory, high availability, low latency requirements - Amazon Neptune is a fast, reliable, fully-managed graph database service that makes it easy to build and run applications that work with highly connected datasets. Neptune is not an in-memory database, so this option is not correct.
Power the on-demand, live leaderboard using Amazon DynamoDB as it meets the in-memory, high availability, low latency requirements - DynamoDB is not an in-memory database, so this option is not correct.
Power the on-demand, live leaderboard using Amazon RDS for Aurora as it meets the in-memory, high availability, low latency requirements - Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud, that combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open source databases. Amazon Aurora features a distributed, fault-tolerant, self-healing storage system that auto-scales up to 128TB per database instance. Aurora is not an in-memory database, so this option is not correct.
References:
https://aws.amazon.com/elasticache/
Explanation
Correct options:
Power the on-demand, live leaderboard using Amazon ElastiCache for Redis as it meets the in-memory, high availability, low latency requirements
Amazon ElastiCache for Redis is a blazing fast in-memory data store that provides sub-millisecond latency to power internet-scale real-time applications. Amazon ElastiCache for Redis is a great choice for real-time transactional and analytical processing use cases such as caching, chat/messaging, gaming leaderboards, geospatial, machine learning, media streaming, queues, real-time analytics, and session store. ElastiCache for Redis can be used to power the live leaderboard, so this option is correct.
Amazon ElastiCache for Redis Overview:
Power the on-demand, live leaderboard using Amazon DynamoDB with DynamoDB Accelerator (DAX) as it meets the in-memory, high availability, low latency requirements
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It's a fully managed, multiregion, multimaster, durable database with built-in security, backup and restore, and in-memory caching for internet-scale applications. DAX is a DynamoDB-compatible caching service that enables you to benefit from fast in-memory performance for demanding applications. So DynamoDB with DAX can be used to power the live leaderboard.
Incorrect options:
Power the on-demand, live leaderboard using Amazon Neptune as it meets the in-memory, high availability, low latency requirements - Amazon Neptune is a fast, reliable, fully-managed graph database service that makes it easy to build and run applications that work with highly connected datasets. Neptune is not an in-memory database, so this option is not correct.
Power the on-demand, live leaderboard using Amazon DynamoDB as it meets the in-memory, high availability, low latency requirements - DynamoDB is not an in-memory database, so this option is not correct.
Power the on-demand, live leaderboard using Amazon RDS for Aurora as it meets the in-memory, high availability, low latency requirements - Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud, that combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open source databases. Amazon Aurora features a distributed, fault-tolerant, self-healing storage system that auto-scales up to 128TB per database instance. Aurora is not an in-memory database, so this option is not correct.
References:
https://aws.amazon.com/elasticache/
Question 8 Single Choice
A technology blogger wants to write a review on the comparative pricing for various storage types available on AWS Cloud. The blogger has created a test file of size 1 gigabytes with some random data. Next he copies this test file into AWS S3 Standard storage class, provisions an Amazon EBS volume (General Purpose SSD (gp2)) with 100 gigabytes of provisioned storage and copies the test file into the Amazon EBS volume, and lastly copies the test file into an Amazon EFS Standard Storage filesystem. At the end of the month, he analyses the bill for costs incurred on the respective storage types for the test file.
What is the correct order of the storage charges incurred for the test file on these three storage types?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Cost of test file storage on Amazon S3 Standard < Cost of test file storage on Amazon EFS < Cost of test file storage on Amazon EBS
With Amazon EBS Elastic Volumes, you pay only for the resources that you use. The Amazon EFS Standard Storage pricing is $0.30 per GB per month. Therefore the cost for storing the test file on EFS is $0.30 for the month.
For Amazon EBS General Purpose SSD (gp2) volumes, the charges are $0.10 per GB-month of provisioned storage. Therefore, for a provisioned storage of 100GB for this use-case, the monthly cost on EBS is $0.10*100 = $10. This cost is irrespective of how much storage is actually consumed by the test file.
For S3 Standard storage, the pricing is $0.023 per GB per month. Therefore, the monthly storage cost on S3 for the test file is $0.023.
Therefore this is the correct option.
Incorrect options:
Cost of test file storage on Amazon S3 Standard < Cost of test file storage on Amazon EBS < Cost of test file storage on Amazon EFS
Cost of test file storage on Amazon EFS < Cost of test file storage on Amazon S3 Standard < Cost of test file storage on Amazon EBS
Cost of test file storage on Amazon EBS < Cost of test file storage on Amazon S3 Standard < Cost of test file storage on Amazon EFS
Following the computations shown earlier in the explanation, these three options are incorrect.
References:
https://aws.amazon.com/ebs/pricing/
https://aws.amazon.com/s3/pricing/(https://aws.amazon.com/s3/pricing/)
Explanation
Correct option:
Cost of test file storage on Amazon S3 Standard < Cost of test file storage on Amazon EFS < Cost of test file storage on Amazon EBS
With Amazon EBS Elastic Volumes, you pay only for the resources that you use. The Amazon EFS Standard Storage pricing is $0.30 per GB per month. Therefore the cost for storing the test file on EFS is $0.30 for the month.
For Amazon EBS General Purpose SSD (gp2) volumes, the charges are $0.10 per GB-month of provisioned storage. Therefore, for a provisioned storage of 100GB for this use-case, the monthly cost on EBS is $0.10*100 = $10. This cost is irrespective of how much storage is actually consumed by the test file.
For S3 Standard storage, the pricing is $0.023 per GB per month. Therefore, the monthly storage cost on S3 for the test file is $0.023.
Therefore this is the correct option.
Incorrect options:
Cost of test file storage on Amazon S3 Standard < Cost of test file storage on Amazon EBS < Cost of test file storage on Amazon EFS
Cost of test file storage on Amazon EFS < Cost of test file storage on Amazon S3 Standard < Cost of test file storage on Amazon EBS
Cost of test file storage on Amazon EBS < Cost of test file storage on Amazon S3 Standard < Cost of test file storage on Amazon EFS
Following the computations shown earlier in the explanation, these three options are incorrect.
References:
https://aws.amazon.com/ebs/pricing/
https://aws.amazon.com/s3/pricing/(https://aws.amazon.com/s3/pricing/)
Question 9 Single Choice
A research group runs its flagship application on a fleet of Amazon EC2 instances for a specialized task that must deliver high random I/O performance. Each instance in the fleet would have access to a dataset that is replicated across the instances by the application itself. Because of the resilient application architecture, the specialized task would continue to be processed even if any instance goes down, as the underlying application would ensure the replacement instance has access to the required dataset.
Which of the following options is the MOST cost-optimal and resource-efficient solution to build this fleet of Amazon EC2 instances?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use Instance Store based Amazon EC2 instances
An instance store provides temporary block-level storage for your instance. This storage is located on disks that are physically attached to the host instance. Instance store is ideal for the temporary storage of information that changes frequently such as buffers, caches, scratch data, and other temporary content, or for data that is replicated across a fleet of instances, such as a load-balanced pool of web servers. Instance store volumes are included as part of the instance's usage cost.
As Instance Store based volumes provide high random I/O performance at low cost (as the storage is part of the instance's usage cost) and the resilient architecture can adjust for the loss of any instance, therefore you should use Instance Store based Amazon EC2 instances for this use-case.
Amazon EC2 Instance Store Overview: 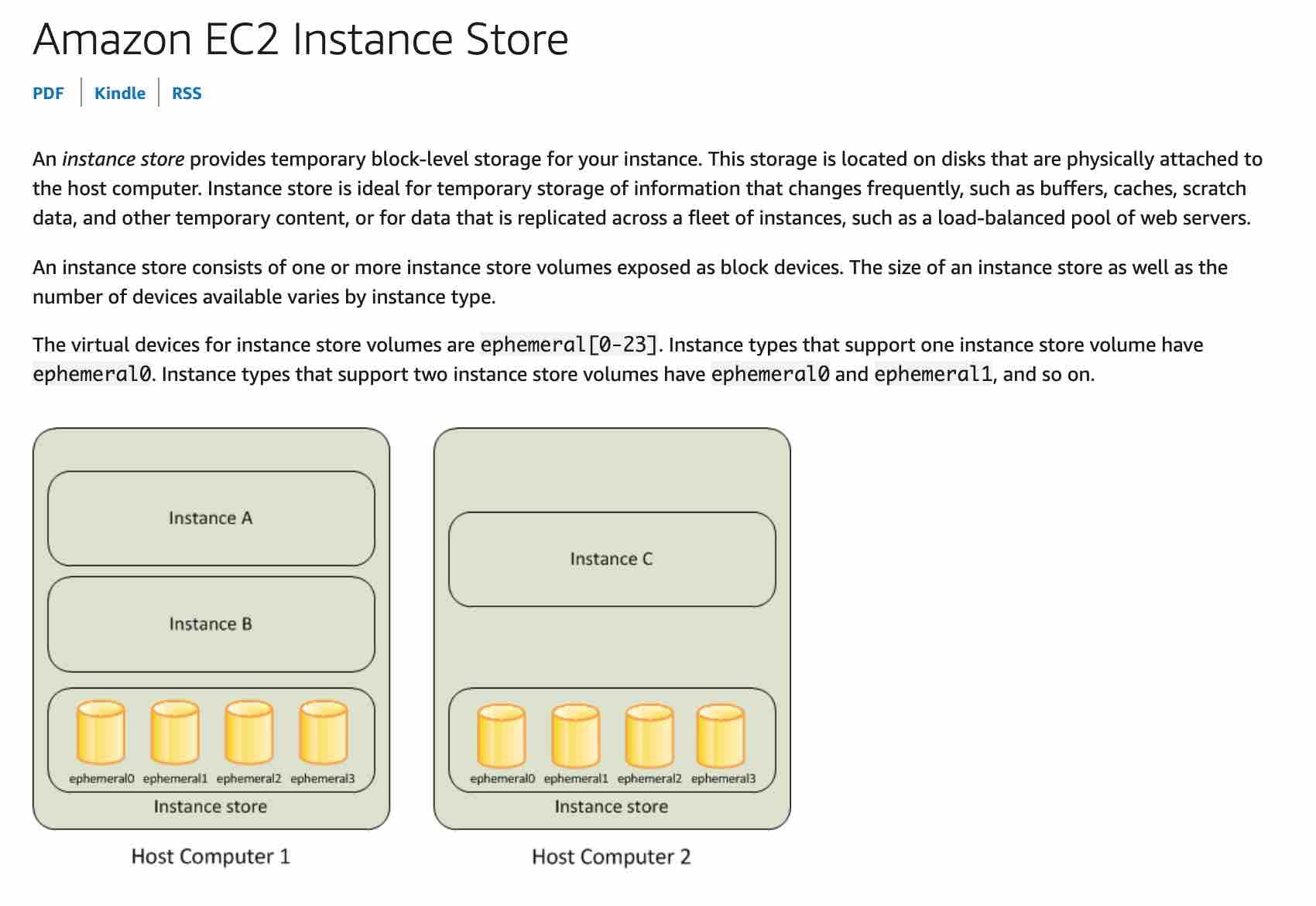 via - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/InstanceStorage.html
via - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/InstanceStorage.html
Incorrect options:
Use Amazon Elastic Block Store (Amazon EBS) based EC2 instances - Amazon Elastic Block Store (Amazon EBS) based volumes would need to use provisioned IOPS (io1) as the storage type and that would incur additional costs. As we are looking for the most cost-optimal solution, this option is ruled out.
Use Amazon EC2 instances with Amazon EFS mount points - Using Amazon Elastic File System (Amazon EFS) implies that extra resources would have to be provisioned (compared to using instance store where the storage is located on disks that are physically attached to the host instance itself). As we are looking for the most resource-efficient solution, this option is also ruled out.
Use Amazon EC2 instances with access to Amazon S3 based storage - Using Amazon EC2 instances with access to Amazon S3 based storage does not deliver high random I/O performance, this option is just added as a distractor.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/InstanceStorage.html
Explanation
Correct option:
Use Instance Store based Amazon EC2 instances
An instance store provides temporary block-level storage for your instance. This storage is located on disks that are physically attached to the host instance. Instance store is ideal for the temporary storage of information that changes frequently such as buffers, caches, scratch data, and other temporary content, or for data that is replicated across a fleet of instances, such as a load-balanced pool of web servers. Instance store volumes are included as part of the instance's usage cost.
As Instance Store based volumes provide high random I/O performance at low cost (as the storage is part of the instance's usage cost) and the resilient architecture can adjust for the loss of any instance, therefore you should use Instance Store based Amazon EC2 instances for this use-case.
Amazon EC2 Instance Store Overview: via - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/InstanceStorage.html
Incorrect options:
Use Amazon Elastic Block Store (Amazon EBS) based EC2 instances - Amazon Elastic Block Store (Amazon EBS) based volumes would need to use provisioned IOPS (io1) as the storage type and that would incur additional costs. As we are looking for the most cost-optimal solution, this option is ruled out.
Use Amazon EC2 instances with Amazon EFS mount points - Using Amazon Elastic File System (Amazon EFS) implies that extra resources would have to be provisioned (compared to using instance store where the storage is located on disks that are physically attached to the host instance itself). As we are looking for the most resource-efficient solution, this option is also ruled out.
Use Amazon EC2 instances with access to Amazon S3 based storage - Using Amazon EC2 instances with access to Amazon S3 based storage does not deliver high random I/O performance, this option is just added as a distractor.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/InstanceStorage.html
Question 10 Multiple Choice
A news network uses Amazon Simple Storage Service (Amazon S3) to aggregate the raw video footage from its reporting teams across the US. The news network has recently expanded into new geographies in Europe and Asia. The technical teams at the overseas branch offices have reported huge delays in uploading large video files to the destination Amazon S3 bucket.
Which of the following are the MOST cost-effective options to improve the file upload speed into Amazon S3 (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Use Amazon S3 Transfer Acceleration (Amazon S3TA) to enable faster file uploads into the destination S3 bucket
Amazon S3 Transfer Acceleration enables fast, easy, and secure transfers of files over long distances between your client and an S3 bucket. Amazon S3TA takes advantage of Amazon CloudFront’s globally distributed edge locations. As the data arrives at an edge location, data is routed to Amazon S3 over an optimized network path.
Use multipart uploads for faster file uploads into the destination Amazon S3 bucket
Multipart upload allows you to upload a single object as a set of parts. Each part is a contiguous portion of the object's data. You can upload these object parts independently and in any order. If transmission of any part fails, you can retransmit that part without affecting other parts. After all parts of your object are uploaded, Amazon S3 assembles these parts and creates the object. In general, when your object size reaches 100 MB, you should consider using multipart uploads instead of uploading the object in a single operation. Multipart upload provides improved throughput, therefore it facilitates faster file uploads.
Incorrect options:
Create multiple AWS Direct Connect connections between the AWS Cloud and branch offices in Europe and Asia. Use the direct connect connections for faster file uploads into Amazon S3 - AWS Direct Connect is a cloud service solution that makes it easy to establish a dedicated network connection from your premises to AWS. AWS Direct Connect lets you establish a dedicated network connection between your network and one of the AWS Direct Connect locations. Direct connect takes significant time (several months) to be provisioned and is an overkill for the given use-case.
Create multiple AWS Site-to-Site VPN connections between the AWS Cloud and branch offices in Europe and Asia. Use these VPN connections for faster file uploads into Amazon S3 - AWS Site-to-Site VPN enables you to securely connect your on-premises network or branch office site to your Amazon Virtual Private Cloud (Amazon VPC). You can securely extend your data center or branch office network to the cloud with an AWS Site-to-Site VPN connection. A VPC VPN Connection utilizes IPSec to establish encrypted network connectivity between your intranet and Amazon VPC over the Internet. VPN Connections are a good solution if you have low to modest bandwidth requirements and can tolerate the inherent variability in Internet-based connectivity. Site-to-site VPN will not help in accelerating the file transfer speeds into S3 for the given use-case.
Use AWS Global Accelerator for faster file uploads into the destination Amazon S3 bucket - AWS Global Accelerator is a service that improves the availability and performance of your applications with local or global users. It provides static IP addresses that act as a fixed entry point to your application endpoints in a single or multiple AWS Regions, such as your Application Load Balancers, Network Load Balancers or Amazon EC2 instances. AWS Global Accelerator will not help in accelerating the file transfer speeds into S3 for the given use-case.
References:
https://docs.aws.amazon.com/AmazonS3/latest/dev/transfer-acceleration.html
https://docs.aws.amazon.com/AmazonS3/latest/dev/uploadobjusingmpu.html
Explanation
Correct options:
Use Amazon S3 Transfer Acceleration (Amazon S3TA) to enable faster file uploads into the destination S3 bucket
Amazon S3 Transfer Acceleration enables fast, easy, and secure transfers of files over long distances between your client and an S3 bucket. Amazon S3TA takes advantage of Amazon CloudFront’s globally distributed edge locations. As the data arrives at an edge location, data is routed to Amazon S3 over an optimized network path.
Use multipart uploads for faster file uploads into the destination Amazon S3 bucket
Multipart upload allows you to upload a single object as a set of parts. Each part is a contiguous portion of the object's data. You can upload these object parts independently and in any order. If transmission of any part fails, you can retransmit that part without affecting other parts. After all parts of your object are uploaded, Amazon S3 assembles these parts and creates the object. In general, when your object size reaches 100 MB, you should consider using multipart uploads instead of uploading the object in a single operation. Multipart upload provides improved throughput, therefore it facilitates faster file uploads.
Incorrect options:
Create multiple AWS Direct Connect connections between the AWS Cloud and branch offices in Europe and Asia. Use the direct connect connections for faster file uploads into Amazon S3 - AWS Direct Connect is a cloud service solution that makes it easy to establish a dedicated network connection from your premises to AWS. AWS Direct Connect lets you establish a dedicated network connection between your network and one of the AWS Direct Connect locations. Direct connect takes significant time (several months) to be provisioned and is an overkill for the given use-case.
Create multiple AWS Site-to-Site VPN connections between the AWS Cloud and branch offices in Europe and Asia. Use these VPN connections for faster file uploads into Amazon S3 - AWS Site-to-Site VPN enables you to securely connect your on-premises network or branch office site to your Amazon Virtual Private Cloud (Amazon VPC). You can securely extend your data center or branch office network to the cloud with an AWS Site-to-Site VPN connection. A VPC VPN Connection utilizes IPSec to establish encrypted network connectivity between your intranet and Amazon VPC over the Internet. VPN Connections are a good solution if you have low to modest bandwidth requirements and can tolerate the inherent variability in Internet-based connectivity. Site-to-site VPN will not help in accelerating the file transfer speeds into S3 for the given use-case.
Use AWS Global Accelerator for faster file uploads into the destination Amazon S3 bucket - AWS Global Accelerator is a service that improves the availability and performance of your applications with local or global users. It provides static IP addresses that act as a fixed entry point to your application endpoints in a single or multiple AWS Regions, such as your Application Load Balancers, Network Load Balancers or Amazon EC2 instances. AWS Global Accelerator will not help in accelerating the file transfer speeds into S3 for the given use-case.
References:
https://docs.aws.amazon.com/AmazonS3/latest/dev/transfer-acceleration.html
https://docs.aws.amazon.com/AmazonS3/latest/dev/uploadobjusingmpu.html


