
AWS Certified Solutions Architect - Associate - (SAA-C03) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 11 Multiple Choice
One of the biggest football leagues in Europe has granted the distribution rights for live streaming its matches in the USA to a silicon valley based streaming services company. As per the terms of distribution, the company must make sure that only users from the USA are able to live stream the matches on their platform. Users from other countries in the world must be denied access to these live-streamed matches.
Which of the following options would allow the company to enforce these streaming restrictions? (Select two)
Explanation

Click "Show Answer" to see the explanation here
Correct options:
Use Amazon Route 53 based geolocation routing policy to restrict distribution of content to only the locations in which you have distribution rights
Geolocation routing lets you choose the resources that serve your traffic based on the geographic location of your users, meaning the location that DNS queries originate from. For example, you might want all queries from Europe to be routed to an ELB load balancer in the Frankfurt region. You can also use geolocation routing to restrict the distribution of content to only the locations in which you have distribution rights.
Use georestriction to prevent users in specific geographic locations from accessing content that you're distributing through a Amazon CloudFront web distribution
You can use georestriction, also known as geo-blocking, to prevent users in specific geographic locations from accessing content that you're distributing through a Amazon CloudFront web distribution. When a user requests your content, Amazon CloudFront typically serves the requested content regardless of where the user is located. If you need to prevent users in specific countries from accessing your content, you can use the CloudFront geo restriction feature to do one of the following: Allow your users to access your content only if they're in one of the countries on a whitelist of approved countries. Prevent your users from accessing your content if they're in one of the countries on a blacklist of banned countries. So this option is also correct.
Amazon Route 53 Routing Policy Overview:  via - https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/routing-policy.html
via - https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/routing-policy.html
Incorrect options:
Use Amazon Route 53 based latency-based routing policy to restrict distribution of content to only the locations in which you have distribution rights - Use latency-based routing when you have resources in multiple AWS Regions and you want to route traffic to the region that provides the lowest latency. To use latency-based routing, you create latency records for your resources in multiple AWS Regions. When Amazon Route 53 receives a DNS query for your domain or subdomain (example.com or acme.example.com), it determines which AWS Regions you've created latency records for, determines which region gives the user the lowest latency, and then selects a latency record for that region. Route 53 responds with the value from the selected record, such as the IP address for a web server.
Use Amazon Route 53 based weighted routing policy to restrict distribution of content to only the locations in which you have distribution rights - Weighted routing lets you associate multiple resources with a single domain name (example.com) or subdomain name (acme.example.com) and choose how much traffic is routed to each resource. This can be useful for a variety of purposes, including load balancing and testing new versions of the software.
Use Amazon Route 53 based failover routing policy to restrict distribution of content to only the locations in which you have distribution rights - Failover routing lets you route traffic to a resource when the resource is healthy or to a different resource when the first resource is unhealthy. The primary and secondary records can route traffic to anything from an Amazon S3 bucket that is configured as a website to a complex tree of records.
Weighted routing or failover routing or latency routing cannot be used to restrict the distribution of content to only the locations in which you have distribution rights. So all three options above are incorrect.
References:
https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/routing-policy.html#routing-policy-geo
https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/routing-policy.html#routing-policy-geo
https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/routing-policy.html#routing-policy-geo
Explanation
Correct options:
Use Amazon Route 53 based geolocation routing policy to restrict distribution of content to only the locations in which you have distribution rights
Geolocation routing lets you choose the resources that serve your traffic based on the geographic location of your users, meaning the location that DNS queries originate from. For example, you might want all queries from Europe to be routed to an ELB load balancer in the Frankfurt region. You can also use geolocation routing to restrict the distribution of content to only the locations in which you have distribution rights.
Use georestriction to prevent users in specific geographic locations from accessing content that you're distributing through a Amazon CloudFront web distribution
You can use georestriction, also known as geo-blocking, to prevent users in specific geographic locations from accessing content that you're distributing through a Amazon CloudFront web distribution. When a user requests your content, Amazon CloudFront typically serves the requested content regardless of where the user is located. If you need to prevent users in specific countries from accessing your content, you can use the CloudFront geo restriction feature to do one of the following: Allow your users to access your content only if they're in one of the countries on a whitelist of approved countries. Prevent your users from accessing your content if they're in one of the countries on a blacklist of banned countries. So this option is also correct.
Amazon Route 53 Routing Policy Overview: via - https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/routing-policy.html
Incorrect options:
Use Amazon Route 53 based latency-based routing policy to restrict distribution of content to only the locations in which you have distribution rights - Use latency-based routing when you have resources in multiple AWS Regions and you want to route traffic to the region that provides the lowest latency. To use latency-based routing, you create latency records for your resources in multiple AWS Regions. When Amazon Route 53 receives a DNS query for your domain or subdomain (example.com or acme.example.com), it determines which AWS Regions you've created latency records for, determines which region gives the user the lowest latency, and then selects a latency record for that region. Route 53 responds with the value from the selected record, such as the IP address for a web server.
Use Amazon Route 53 based weighted routing policy to restrict distribution of content to only the locations in which you have distribution rights - Weighted routing lets you associate multiple resources with a single domain name (example.com) or subdomain name (acme.example.com) and choose how much traffic is routed to each resource. This can be useful for a variety of purposes, including load balancing and testing new versions of the software.
Use Amazon Route 53 based failover routing policy to restrict distribution of content to only the locations in which you have distribution rights - Failover routing lets you route traffic to a resource when the resource is healthy or to a different resource when the first resource is unhealthy. The primary and secondary records can route traffic to anything from an Amazon S3 bucket that is configured as a website to a complex tree of records.
Weighted routing or failover routing or latency routing cannot be used to restrict the distribution of content to only the locations in which you have distribution rights. So all three options above are incorrect.
References:
https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/routing-policy.html#routing-policy-geo
https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/routing-policy.html#routing-policy-geo
https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/routing-policy.html#routing-policy-geo
Question 12 Single Choice
While consolidating logs for the weekly reporting, a development team at an e-commerce company noticed that an unusually large number of illegal AWS application programming interface (API) queries were made sometime during the week. Due to the off-season, there was no visible impact on the systems. However, this event led the management team to seek an automated solution that can trigger near-real-time warnings in case such an event recurs.
Which of the following represents the best solution for the given scenario?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Create an Amazon CloudWatch metric filter that processes AWS CloudTrail logs having API call details and looks at any errors by factoring in all the error codes that need to be tracked. Create an alarm based on this metric's rate to send an Amazon SNS notification to the required team
AWS CloudTrail log data can be ingested into Amazon CloudWatch to monitor and identify your AWS account activity against security threats, and create a governance framework for security best practices. You can analyze log trail event data in CloudWatch using features such as Logs Insight, Contributor Insights, Metric filters, and CloudWatch Alarms.
AWS CloudTrail integrates with the Amazon CloudWatch service to publish the API calls being made to resources or services in the AWS account. The published event has invaluable information that can be used for compliance, auditing, and governance of your AWS accounts. Below we introduce several features available in CloudWatch to monitor API activity, analyze the logs at scale, and take action when malicious activity is discovered, without provisioning your infrastructure.
For the AWS Cloudtrail logs available in Amazon CloudWatch Logs, you can begin searching and filtering the log data by creating one or more metric filters. Use these metric filters to turn log data into numerical CloudWatch metrics that you can graph or set a CloudWatch Alarm on.
Note: AWS CloudTrail Insights helps AWS users identify and respond to unusual activity associated with write API calls by continuously analyzing CloudTrail management events.
Insights events are logged when AWS CloudTrail detects unusual write management API activity in your account. If you have AWS CloudTrail Insights enabled and CloudTrail detects unusual activity, Insights events are delivered to the destination Amazon S3 bucket for your trail. You can also see the type of insight and the incident time when you view Insights events on the CloudTrail console. Unlike other types of events captured in a CloudTrail trail, Insights events are logged only when CloudTrail detects changes in your account's API usage that differ significantly from the account's typical usage patterns.
Incorrect options:
Configure AWS CloudTrail to stream event data to Amazon Kinesis. Use Amazon Kinesis stream-level metrics in the Amazon CloudWatch to trigger an AWS Lambda function that will trigger an error workflow - AWS CloudTrail cannot stream data to Amazon Kinesis. Amazon S3 buckets and Amazon CloudWatch logs are the only destinations possible.
Run Amazon Athena SQL queries against AWS CloudTrail log files stored in Amazon S3 buckets. Use Amazon QuickSight to generate reports for managerial dashboards - Generating reports and visualizations help in understanding and analyzing patterns but is not useful as a near-real-time automatic solution for the given problem.
AWS Trusted Advisor publishes metrics about check results to Amazon CloudWatch. Create an alarm to track status changes for checks in the Service Limits category for the APIs. The alarm will then notify when the service quota is reached or exceeded - When AWS Trusted Advisor refreshes your checks, Trusted Advisor publishes metrics about your check results to Amazon CloudWatch. You can view the metrics in CloudWatch. You can also create alarms to detect status changes to Trusted Advisor checks and status changes for resources, and service quota usage (formerly referred to as limits). The alarm will then notify you when you reach or exceed a service quota for your AWS account. However, the alarm is triggered only when the service limit is reached. We need a solution that raises an alarm when the number of API calls randomly increases or an abnormal pattern is detected. Hence, this option is not the right fit for the given use case.
References:
https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-concepts.html
https://docs.aws.amazon.com/awssupport/latest/user/cloudwatch-metrics-ta.html
Explanation
Correct option:
Create an Amazon CloudWatch metric filter that processes AWS CloudTrail logs having API call details and looks at any errors by factoring in all the error codes that need to be tracked. Create an alarm based on this metric's rate to send an Amazon SNS notification to the required team
AWS CloudTrail log data can be ingested into Amazon CloudWatch to monitor and identify your AWS account activity against security threats, and create a governance framework for security best practices. You can analyze log trail event data in CloudWatch using features such as Logs Insight, Contributor Insights, Metric filters, and CloudWatch Alarms.
AWS CloudTrail integrates with the Amazon CloudWatch service to publish the API calls being made to resources or services in the AWS account. The published event has invaluable information that can be used for compliance, auditing, and governance of your AWS accounts. Below we introduce several features available in CloudWatch to monitor API activity, analyze the logs at scale, and take action when malicious activity is discovered, without provisioning your infrastructure.
For the AWS Cloudtrail logs available in Amazon CloudWatch Logs, you can begin searching and filtering the log data by creating one or more metric filters. Use these metric filters to turn log data into numerical CloudWatch metrics that you can graph or set a CloudWatch Alarm on.
Note: AWS CloudTrail Insights helps AWS users identify and respond to unusual activity associated with write API calls by continuously analyzing CloudTrail management events.
Insights events are logged when AWS CloudTrail detects unusual write management API activity in your account. If you have AWS CloudTrail Insights enabled and CloudTrail detects unusual activity, Insights events are delivered to the destination Amazon S3 bucket for your trail. You can also see the type of insight and the incident time when you view Insights events on the CloudTrail console. Unlike other types of events captured in a CloudTrail trail, Insights events are logged only when CloudTrail detects changes in your account's API usage that differ significantly from the account's typical usage patterns.
Incorrect options:
Configure AWS CloudTrail to stream event data to Amazon Kinesis. Use Amazon Kinesis stream-level metrics in the Amazon CloudWatch to trigger an AWS Lambda function that will trigger an error workflow - AWS CloudTrail cannot stream data to Amazon Kinesis. Amazon S3 buckets and Amazon CloudWatch logs are the only destinations possible.
Run Amazon Athena SQL queries against AWS CloudTrail log files stored in Amazon S3 buckets. Use Amazon QuickSight to generate reports for managerial dashboards - Generating reports and visualizations help in understanding and analyzing patterns but is not useful as a near-real-time automatic solution for the given problem.
AWS Trusted Advisor publishes metrics about check results to Amazon CloudWatch. Create an alarm to track status changes for checks in the Service Limits category for the APIs. The alarm will then notify when the service quota is reached or exceeded - When AWS Trusted Advisor refreshes your checks, Trusted Advisor publishes metrics about your check results to Amazon CloudWatch. You can view the metrics in CloudWatch. You can also create alarms to detect status changes to Trusted Advisor checks and status changes for resources, and service quota usage (formerly referred to as limits). The alarm will then notify you when you reach or exceed a service quota for your AWS account. However, the alarm is triggered only when the service limit is reached. We need a solution that raises an alarm when the number of API calls randomly increases or an abnormal pattern is detected. Hence, this option is not the right fit for the given use case.
References:
https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-concepts.html
https://docs.aws.amazon.com/awssupport/latest/user/cloudwatch-metrics-ta.html
Question 13 Single Choice
An ivy-league university is assisting NASA to find potential landing sites for exploration vehicles of unmanned missions to our neighboring planets. The university uses High Performance Computing (HPC) driven application architecture to identify these landing sites.
Which of the following Amazon EC2 instance topologies should this application be deployed on?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
The Amazon EC2 instances should be deployed in a cluster placement group so that the underlying workload can benefit from low network latency and high network throughput
The key thing to understand in this question is that HPC workloads need to achieve low-latency network performance necessary for tightly-coupled node-to-node communication that is typical of HPC applications. Cluster placement groups pack instances close together inside an Availability Zone. These are recommended for applications that benefit from low network latency, high network throughput, or both. Therefore this option is the correct answer.
Cluster Placement Group:  via - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
via - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
Incorrect options:
The Amazon EC2 instances should be deployed in a partition placement group so that distributed workloads can be handled effectively - A partition placement group spreads your instances across logical partitions such that groups of instances in one partition do not share the underlying hardware with groups of instances in different partitions. This strategy is typically used by large distributed and replicated workloads, such as Hadoop, Cassandra, and Kafka. A partition placement group can have a maximum of seven partitions per Availability Zone. Since a partition placement group can have partitions in multiple Availability Zones in the same region, therefore instances will not have low-latency network performance. Hence the partition placement group is not the right fit for HPC applications.
Partition Placement Group: 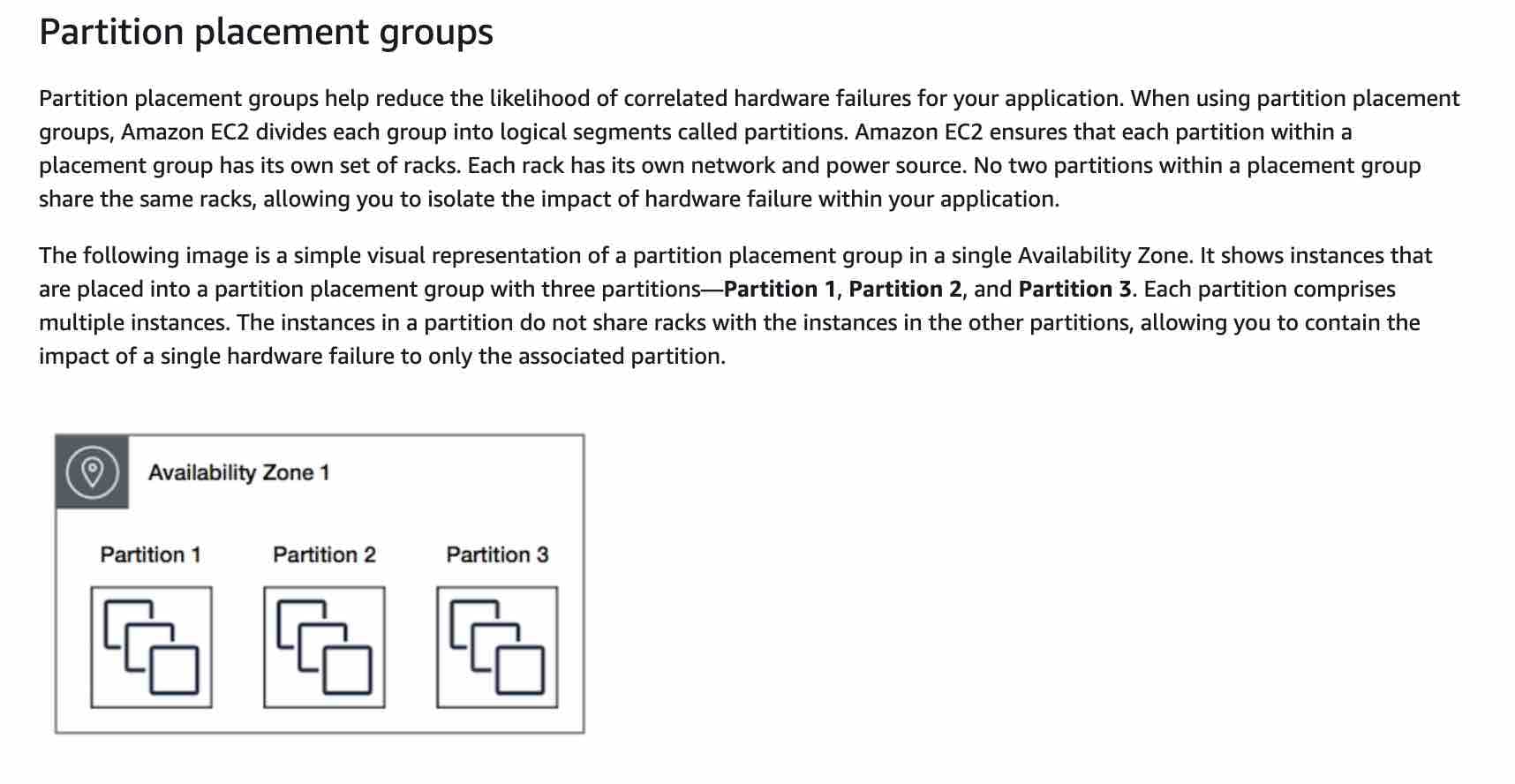 via - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
via - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
The Amazon EC2 instances should be deployed in a spread placement group so that there are no correlated failures - A spread placement group is a group of instances that are each placed on distinct racks, with each rack having its own network and power source. The instances are placed across distinct underlying hardware to reduce correlated failures. You can have a maximum of seven running instances per Availability Zone per group. Since a spread placement group can span multiple Availability Zones in the same Region, therefore instances will not have low-latency network performance. Hence spread placement group is not the right fit for HPC applications.
Spread Placement Group:  via - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
via - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
The Amazon EC2 instances should be deployed in an Auto Scaling group so that application meets high availability requirements - An Auto Scaling group contains a collection of Amazon EC2 instances that are treated as a logical grouping for the purposes of automatic scaling. You do not use Auto Scaling groups per se to meet HPC requirements.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
Explanation
Correct option:
The Amazon EC2 instances should be deployed in a cluster placement group so that the underlying workload can benefit from low network latency and high network throughput
The key thing to understand in this question is that HPC workloads need to achieve low-latency network performance necessary for tightly-coupled node-to-node communication that is typical of HPC applications. Cluster placement groups pack instances close together inside an Availability Zone. These are recommended for applications that benefit from low network latency, high network throughput, or both. Therefore this option is the correct answer.
Cluster Placement Group: via - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
Incorrect options:
The Amazon EC2 instances should be deployed in a partition placement group so that distributed workloads can be handled effectively - A partition placement group spreads your instances across logical partitions such that groups of instances in one partition do not share the underlying hardware with groups of instances in different partitions. This strategy is typically used by large distributed and replicated workloads, such as Hadoop, Cassandra, and Kafka. A partition placement group can have a maximum of seven partitions per Availability Zone. Since a partition placement group can have partitions in multiple Availability Zones in the same region, therefore instances will not have low-latency network performance. Hence the partition placement group is not the right fit for HPC applications.
Partition Placement Group: via - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
The Amazon EC2 instances should be deployed in a spread placement group so that there are no correlated failures - A spread placement group is a group of instances that are each placed on distinct racks, with each rack having its own network and power source. The instances are placed across distinct underlying hardware to reduce correlated failures. You can have a maximum of seven running instances per Availability Zone per group. Since a spread placement group can span multiple Availability Zones in the same Region, therefore instances will not have low-latency network performance. Hence spread placement group is not the right fit for HPC applications.
Spread Placement Group: via - https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
The Amazon EC2 instances should be deployed in an Auto Scaling group so that application meets high availability requirements - An Auto Scaling group contains a collection of Amazon EC2 instances that are treated as a logical grouping for the purposes of automatic scaling. You do not use Auto Scaling groups per se to meet HPC requirements.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/placement-groups.html
Question 14 Single Choice
A new DevOps engineer has just joined a development team and wants to understand the replication capabilities for Amazon RDS Multi-AZ deployment as well as Amazon RDS Read-replicas.
Which of the following correctly summarizes these capabilities for the given database?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Multi-AZ follows synchronous replication and spans at least two Availability Zones (AZs) within a single region. Read replicas follow asynchronous replication and can be within an Availability Zone (AZ), Cross-AZ, or Cross-Region
Amazon RDS Multi-AZ deployments provide enhanced availability and durability for RDS database (DB) instances, making them a natural fit for production database workloads. When you provision a Multi-AZ DB Instance, Amazon RDS automatically creates a primary DB Instance and synchronously replicates the data to a standby instance in a different Availability Zone (AZ). Multi-AZ spans at least two Availability Zones (AZs) within a single region.
Amazon RDS Read Replicas provide enhanced performance and durability for RDS database (DB) instances. They make it easy to elastically scale out beyond the capacity constraints of a single DB instance for read-heavy database workloads. For the MySQL, MariaDB, PostgreSQL, Oracle, and SQL Server database engines, Amazon RDS creates a second DB instance using a snapshot of the source DB instance. It then uses the engines' native asynchronous replication to update the read replica whenever there is a change to the source DB instance.
Amazon RDS replicates all databases in the source DB instance. Read replicas can be within an Availability Zone (AZ), Cross-AZ, or Cross-Region.
Exam Alert:
Please review this comparison vis-a-vis Multi-AZ vs Read Replica for Amazon RDS: 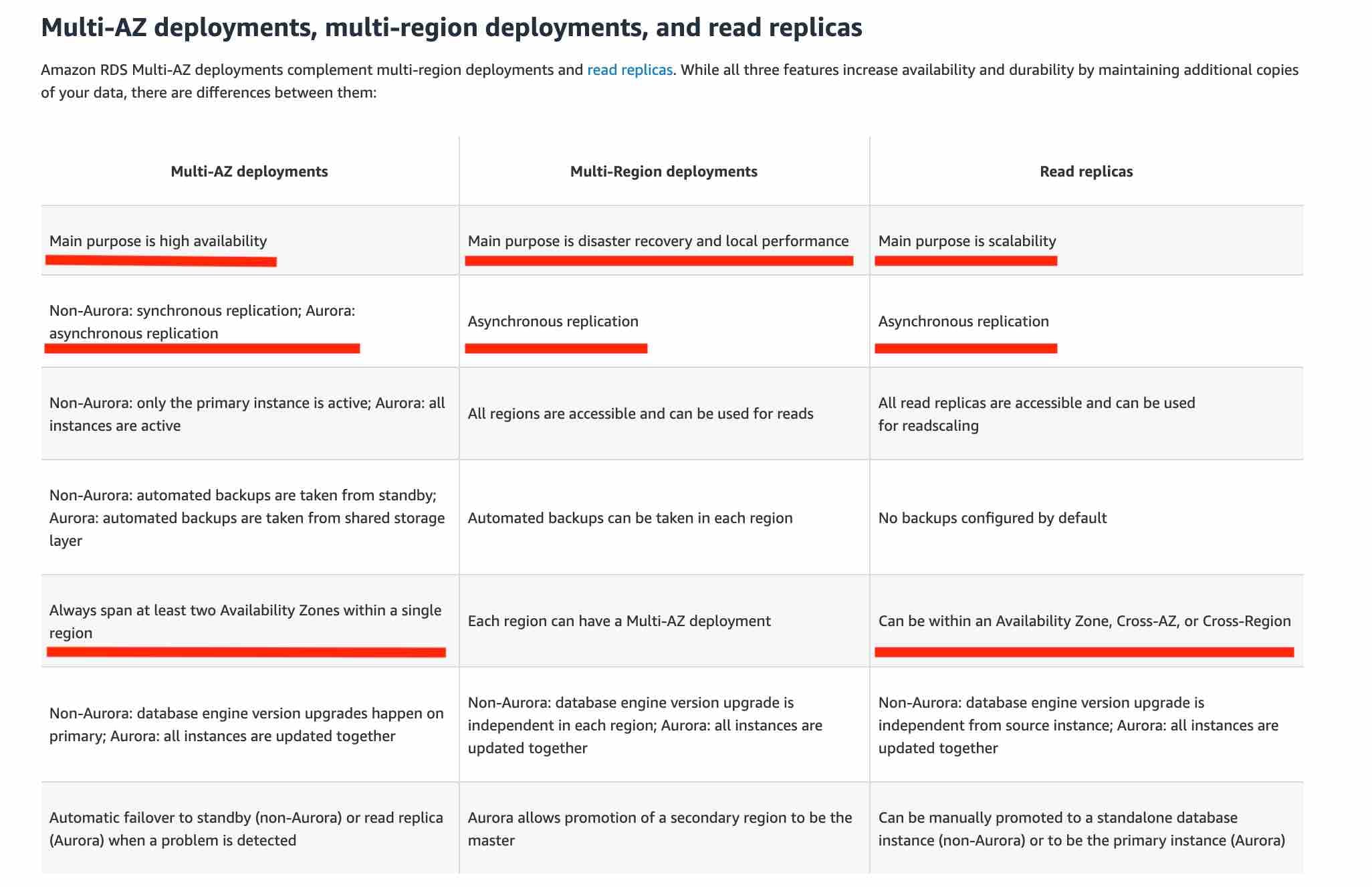 via - https://aws.amazon.com/rds/features/multi-az/
via - https://aws.amazon.com/rds/features/multi-az/
Incorrect Options:
Multi-AZ follows asynchronous replication and spans one Availability Zone (AZ) within a single region. Read replicas follow synchronous replication and can be within an Availability Zone (AZ), Cross-AZ, or Cross-Region
Multi-AZ follows asynchronous replication and spans at least two Availability Zones (AZs) within a single region. Read replicas follow synchronous replication and can be within an Availability Zone (AZ), Cross-AZ, or Cross-Region
Multi-AZ follows asynchronous replication and spans at least two Availability Zones (AZs) within a single region. Read replicas follow asynchronous replication and can be within an Availability Zone (AZ), Cross-AZ, or Cross-Region
These three options contradict the earlier details provided in the explanation. To summarize, Multi-AZ deployment follows synchronous replication for Amazon RDS. Hence these options are incorrect.
References:
Explanation
Correct option:
Multi-AZ follows synchronous replication and spans at least two Availability Zones (AZs) within a single region. Read replicas follow asynchronous replication and can be within an Availability Zone (AZ), Cross-AZ, or Cross-Region
Amazon RDS Multi-AZ deployments provide enhanced availability and durability for RDS database (DB) instances, making them a natural fit for production database workloads. When you provision a Multi-AZ DB Instance, Amazon RDS automatically creates a primary DB Instance and synchronously replicates the data to a standby instance in a different Availability Zone (AZ). Multi-AZ spans at least two Availability Zones (AZs) within a single region.
Amazon RDS Read Replicas provide enhanced performance and durability for RDS database (DB) instances. They make it easy to elastically scale out beyond the capacity constraints of a single DB instance for read-heavy database workloads. For the MySQL, MariaDB, PostgreSQL, Oracle, and SQL Server database engines, Amazon RDS creates a second DB instance using a snapshot of the source DB instance. It then uses the engines' native asynchronous replication to update the read replica whenever there is a change to the source DB instance.
Amazon RDS replicates all databases in the source DB instance. Read replicas can be within an Availability Zone (AZ), Cross-AZ, or Cross-Region.
Exam Alert:
Please review this comparison vis-a-vis Multi-AZ vs Read Replica for Amazon RDS: via - https://aws.amazon.com/rds/features/multi-az/
Incorrect Options:
Multi-AZ follows asynchronous replication and spans one Availability Zone (AZ) within a single region. Read replicas follow synchronous replication and can be within an Availability Zone (AZ), Cross-AZ, or Cross-Region
Multi-AZ follows asynchronous replication and spans at least two Availability Zones (AZs) within a single region. Read replicas follow synchronous replication and can be within an Availability Zone (AZ), Cross-AZ, or Cross-Region
Multi-AZ follows asynchronous replication and spans at least two Availability Zones (AZs) within a single region. Read replicas follow asynchronous replication and can be within an Availability Zone (AZ), Cross-AZ, or Cross-Region
These three options contradict the earlier details provided in the explanation. To summarize, Multi-AZ deployment follows synchronous replication for Amazon RDS. Hence these options are incorrect.
References:
Question 15 Single Choice
A gaming company is developing a mobile game that streams score updates to a backend processor and then publishes results on a leaderboard. The company has hired you as an AWS Certified Solutions Architect Associate to design a solution that can handle major traffic spikes, process the mobile game updates in the order of receipt, and store the processed updates in a highly available database. The company wants to minimize the management overhead required to maintain the solution.
Which of the following will you recommend to meet these requirements?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Push score updates to Amazon Kinesis Data Streams which uses an AWS Lambda function to process these updates and then store these processed updates in Amazon DynamoDB
To help ingest real-time data or streaming data at large scales, you can use Amazon Kinesis Data Streams (KDS). KDS can continuously capture gigabytes of data per second from hundreds of thousands of sources. The data collected is available in milliseconds, enabling real-time analytics. KDS provides ordering of records, as well as the ability to read and/or replay records in the same order to multiple Amazon Kinesis Applications.
AWS Lambda integrates natively with Kinesis Data Streams. The polling, checkpointing, and error handling complexities are abstracted when you use this native integration. The processed data can then be configured to be saved in Amazon DynamoDB.
Incorrect options:
Push score updates to an Amazon Simple Queue Service (Amazon SQS) queue which uses a fleet of Amazon EC2 instances (with Auto Scaling) to process these updates in the Amazon SQS queue and then store these processed updates in an Amazon RDS MySQL database
Push score updates to Amazon Kinesis Data Streams which uses a fleet of Amazon EC2 instances (with Auto Scaling) to process the updates in Amazon Kinesis Data Streams and then store these processed updates in Amazon DynamoDB
Push score updates to an Amazon Simple Notification Service (Amazon SNS) topic, subscribe an AWS Lambda function to this Amazon SNS topic to process the updates and then store these processed updates in a SQL database running on Amazon EC2 instance
These three options use Amazon EC2 instances as part of the solution architecture. The use-case seeks to minimize the management overhead required to maintain the solution. However, Amazon EC2 instances involve several maintenance activities such as managing the guest operating system and software deployed to the guest operating system, including updates and security patches, etc. Hence these options are incorrect.
Reference:
Explanation
Correct option:
Push score updates to Amazon Kinesis Data Streams which uses an AWS Lambda function to process these updates and then store these processed updates in Amazon DynamoDB
To help ingest real-time data or streaming data at large scales, you can use Amazon Kinesis Data Streams (KDS). KDS can continuously capture gigabytes of data per second from hundreds of thousands of sources. The data collected is available in milliseconds, enabling real-time analytics. KDS provides ordering of records, as well as the ability to read and/or replay records in the same order to multiple Amazon Kinesis Applications.
AWS Lambda integrates natively with Kinesis Data Streams. The polling, checkpointing, and error handling complexities are abstracted when you use this native integration. The processed data can then be configured to be saved in Amazon DynamoDB.
Incorrect options:
Push score updates to an Amazon Simple Queue Service (Amazon SQS) queue which uses a fleet of Amazon EC2 instances (with Auto Scaling) to process these updates in the Amazon SQS queue and then store these processed updates in an Amazon RDS MySQL database
Push score updates to Amazon Kinesis Data Streams which uses a fleet of Amazon EC2 instances (with Auto Scaling) to process the updates in Amazon Kinesis Data Streams and then store these processed updates in Amazon DynamoDB
Push score updates to an Amazon Simple Notification Service (Amazon SNS) topic, subscribe an AWS Lambda function to this Amazon SNS topic to process the updates and then store these processed updates in a SQL database running on Amazon EC2 instance
These three options use Amazon EC2 instances as part of the solution architecture. The use-case seeks to minimize the management overhead required to maintain the solution. However, Amazon EC2 instances involve several maintenance activities such as managing the guest operating system and software deployed to the guest operating system, including updates and security patches, etc. Hence these options are incorrect.
Reference:
Question 16 Single Choice
A biotechnology firm runs genomics data analysis workloads using AWS Lambda functions deployed inside a VPC in their central AWS account. The input data for these workloads consists of large files stored in an Amazon Elastic File System (Amazon EFS) that resides in a separate AWS account managed by a research partner. The firm wants the Lambda function in their account to access the shared EFS storage directly. The access pattern and file volume are expected to grow as additional research datasets are added over time, so the solution must be scalable and cost-efficient, and should require minimal operational overhead.
Which solution best meets these requirements in the MOST cost-effective way?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use Amazon EFS resource policies to allow cross-account access to the file system from the central account. Attach the EFS mount target to a shared VPC or peered VPC, and mount the file system in the Lambda function configuration using an EFS access point
This solution uses native AWS support for cross-account access to EFS via resource policies, combined with EFS access points and VPC-level networking (VPC peering or shared VPC). The Lambda function in the central account can mount the file system directly using the EFS mount target and access point as if it were in the same account. This method supports automatic scaling, secure access, and avoids any need for data duplication or proxy functions. It is the most cost-effective and operationally efficient solution.
Incorrect options:
Set up an Amazon S3 bucket in the research partner’s account and periodically copy EFS contents into the bucket using scheduled AWS DataSync jobs. Use Amazon S3 Access Points to expose the data to the Lambda function in the central account, allowing access via S3 API calls instead of file system mounts - While this approach enables cross-account access to data using Amazon S3 Access Points, it introduces significant storage duplication and recurring transfer costs. EFS contents must be periodically copied to S3 using AWS DataSync, which adds operational complexity and delay. This solution also does not support real-time or low-latency file system operations, which may be required by the workloads.
Create a second Lambda function in the research partner's account that mounts the EFS file system locally. Have the main Lambda function in the central account invoke this secondary Lambda via Amazon API Gateway for data access and computation. Use IAM cross-account permissions to allow invocation - This option introduces additional latency and architectural complexity by involving a proxy Lambda function in a separate account, which acts as an intermediary for file access. It breaks the direct file system access model, limits performance, and requires managing a custom API layer. It also increases operational overhead, and any scaling of the secondary function will incur further compute cost and complexity.
Package the genomic input data as a Lambda layer and publish it in the research partner's account. Share the layer across accounts by modifying its resource policy and attach the layer to the Lambda function in the central account to access the data during execution - Lambda layers are designed for shared code and dependencies, not for large or dynamic datasets like genomic files. There are strict size limits (250 MB unzipped) on Lambda layers, and they are immutable once published. Sharing large or growing data sets via Lambda layers is infeasible and not scalable. This method is both cost-ineffective and technically unsuitable for the given use case.
References:
https://docs.aws.amazon.com/efs/latest/ug/whatisefs.html
https://docs.aws.amazon.com/efs/latest/ug/efs-access-points.html
https://docs.aws.amazon.com/datasync/latest/userguide/what-is-datasync.html
https://docs.aws.amazon.com/lambda/latest/dg/chapter-layers.html
https://docs.aws.amazon.com/lambda/latest/dg/adding-layers.html
Explanation
Correct option:
Use Amazon EFS resource policies to allow cross-account access to the file system from the central account. Attach the EFS mount target to a shared VPC or peered VPC, and mount the file system in the Lambda function configuration using an EFS access point
This solution uses native AWS support for cross-account access to EFS via resource policies, combined with EFS access points and VPC-level networking (VPC peering or shared VPC). The Lambda function in the central account can mount the file system directly using the EFS mount target and access point as if it were in the same account. This method supports automatic scaling, secure access, and avoids any need for data duplication or proxy functions. It is the most cost-effective and operationally efficient solution.
Incorrect options:
Set up an Amazon S3 bucket in the research partner’s account and periodically copy EFS contents into the bucket using scheduled AWS DataSync jobs. Use Amazon S3 Access Points to expose the data to the Lambda function in the central account, allowing access via S3 API calls instead of file system mounts - While this approach enables cross-account access to data using Amazon S3 Access Points, it introduces significant storage duplication and recurring transfer costs. EFS contents must be periodically copied to S3 using AWS DataSync, which adds operational complexity and delay. This solution also does not support real-time or low-latency file system operations, which may be required by the workloads.
Create a second Lambda function in the research partner's account that mounts the EFS file system locally. Have the main Lambda function in the central account invoke this secondary Lambda via Amazon API Gateway for data access and computation. Use IAM cross-account permissions to allow invocation - This option introduces additional latency and architectural complexity by involving a proxy Lambda function in a separate account, which acts as an intermediary for file access. It breaks the direct file system access model, limits performance, and requires managing a custom API layer. It also increases operational overhead, and any scaling of the secondary function will incur further compute cost and complexity.
Package the genomic input data as a Lambda layer and publish it in the research partner's account. Share the layer across accounts by modifying its resource policy and attach the layer to the Lambda function in the central account to access the data during execution - Lambda layers are designed for shared code and dependencies, not for large or dynamic datasets like genomic files. There are strict size limits (250 MB unzipped) on Lambda layers, and they are immutable once published. Sharing large or growing data sets via Lambda layers is infeasible and not scalable. This method is both cost-ineffective and technically unsuitable for the given use case.
References:
https://docs.aws.amazon.com/efs/latest/ug/whatisefs.html
https://docs.aws.amazon.com/efs/latest/ug/efs-access-points.html
https://docs.aws.amazon.com/datasync/latest/userguide/what-is-datasync.html
https://docs.aws.amazon.com/lambda/latest/dg/chapter-layers.html
https://docs.aws.amazon.com/lambda/latest/dg/adding-layers.html
Question 17 Single Choice
A logistics company is building a multi-tier application to track the location of its trucks during peak operating hours. The company wants these data points to be accessible in real-time in its analytics platform via a REST API. The company has hired you as an AWS Certified Solutions Architect Associate to build a multi-tier solution to store and retrieve this location data for analysis.
Which of the following options addresses the given use case?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Leverage Amazon API Gateway with Amazon Kinesis Data Analytics
You can use Kinesis Data Analytics to transform and analyze streaming data in real-time with Apache Flink. Kinesis Data Analytics enables you to quickly build end-to-end stream processing applications for log analytics, clickstream analytics, Internet of Things (IoT), ad tech, gaming, etc. The four most common use cases are streaming extract-transform-load (ETL), continuous metric generation, responsive real-time analytics, and interactive querying of data streams. Kinesis Data Analytics for Apache Flink applications provides your application 50 GB of running application storage per Kinesis Processing Unit (KPU).
Amazon API Gateway is a fully managed service that allows you to publish, maintain, monitor, and secure APIs at any scale. Amazon API Gateway offers two options to create RESTful APIs, HTTP APIs and REST APIs, as well as an option to create WebSocket APIs.
Amazon API Gateway:  via - https://aws.amazon.com/blogs/aws/amazon-rds-custom-for-oracle-new-control-capabilities-in-database-environment/
via - https://aws.amazon.com/blogs/aws/amazon-rds-custom-for-oracle-new-control-capabilities-in-database-environment/
For the given use case, you can use Amazon API Gateway to create a REST API that handles incoming requests having location data from the trucks and sends it to the Kinesis Data Analytics application on the back end.
Amazon Kinesis Data Analytics: 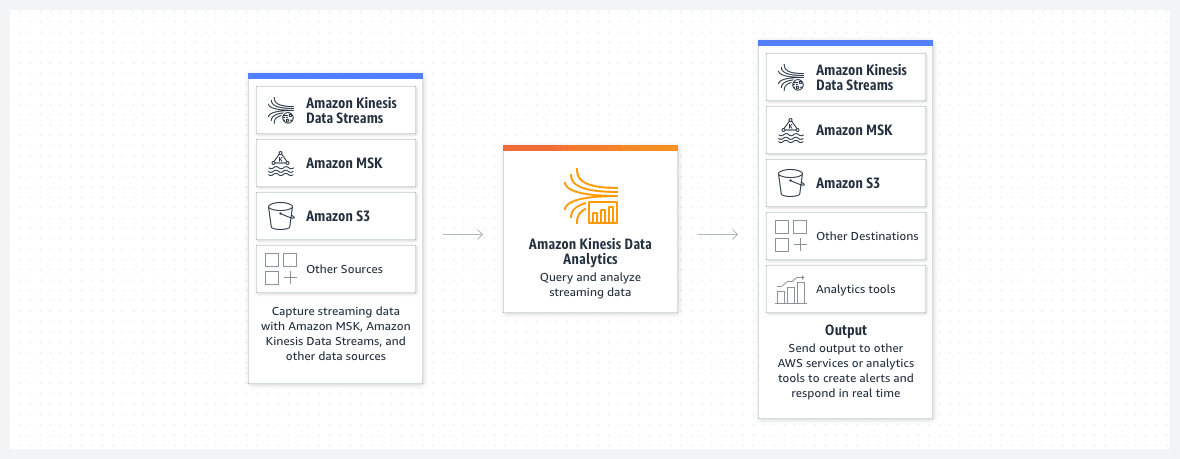 via - https://aws.amazon.com/kinesis/data-analytics/
via - https://aws.amazon.com/kinesis/data-analytics/
Incorrect options:
Leverage Amazon Athena with Amazon S3 - Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena cannot be used to build a REST API to consume data from the source. So this option is incorrect.
Leverage Amazon QuickSight with Amazon Redshift - QuickSight is a cloud-native, serverless business intelligence service. Quicksight cannot be used to build a REST API to consume data from the source. Redshift is a fully managed AWS cloud data warehouse. So this option is incorrect.
Leverage Amazon API Gateway with AWS Lambda - You cannot use Lambda to store and retrieve the location data for analysis, so this option is incorrect.
References:
Explanation
Correct option:
Leverage Amazon API Gateway with Amazon Kinesis Data Analytics
You can use Kinesis Data Analytics to transform and analyze streaming data in real-time with Apache Flink. Kinesis Data Analytics enables you to quickly build end-to-end stream processing applications for log analytics, clickstream analytics, Internet of Things (IoT), ad tech, gaming, etc. The four most common use cases are streaming extract-transform-load (ETL), continuous metric generation, responsive real-time analytics, and interactive querying of data streams. Kinesis Data Analytics for Apache Flink applications provides your application 50 GB of running application storage per Kinesis Processing Unit (KPU).
Amazon API Gateway is a fully managed service that allows you to publish, maintain, monitor, and secure APIs at any scale. Amazon API Gateway offers two options to create RESTful APIs, HTTP APIs and REST APIs, as well as an option to create WebSocket APIs.
Amazon API Gateway: via - https://aws.amazon.com/blogs/aws/amazon-rds-custom-for-oracle-new-control-capabilities-in-database-environment/
For the given use case, you can use Amazon API Gateway to create a REST API that handles incoming requests having location data from the trucks and sends it to the Kinesis Data Analytics application on the back end.
Amazon Kinesis Data Analytics: via - https://aws.amazon.com/kinesis/data-analytics/
Incorrect options:
Leverage Amazon Athena with Amazon S3 - Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena cannot be used to build a REST API to consume data from the source. So this option is incorrect.
Leverage Amazon QuickSight with Amazon Redshift - QuickSight is a cloud-native, serverless business intelligence service. Quicksight cannot be used to build a REST API to consume data from the source. Redshift is a fully managed AWS cloud data warehouse. So this option is incorrect.
Leverage Amazon API Gateway with AWS Lambda - You cannot use Lambda to store and retrieve the location data for analysis, so this option is incorrect.
References:
Question 18 Single Choice
The payroll department at a company initiates several computationally intensive workloads on Amazon EC2 instances at a designated hour on the last day of every month. The payroll department has noticed a trend of severe performance lag during this hour. The engineering team has figured out a solution by using Auto Scaling Group for these Amazon EC2 instances and making sure that 10 Amazon EC2 instances are available during this peak usage hour. For normal operations only 2 Amazon EC2 instances are enough to cater to the workload.
As a solutions architect, which of the following steps would you recommend to implement the solution?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Configure your Auto Scaling group by creating a scheduled action that kicks-off at the designated hour on the last day of the month. Set the desired capacity of instances to 10. This causes the scale-out to happen before peak traffic kicks in at the designated hour
Scheduled scaling allows you to set your own scaling schedule. For example, let's say that every week the traffic to your web application starts to increase on Wednesday, remains high on Thursday, and starts to decrease on Friday. You can plan your scaling actions based on the predictable traffic patterns of your web application. Scaling actions are performed automatically as a function of time and date.
A scheduled action sets the minimum, maximum, and desired sizes to what is specified by the scheduled action at the time specified by the scheduled action. For the given use case, the correct solution is to set the desired capacity to 10. When we want to specify a range of instances, then we must use min and max values.
Incorrect options:
Configure your Auto Scaling group by creating a scheduled action that kicks-off at the designated hour on the last day of the month. Set the min count as well as the max count of instances to 10. This causes the scale-out to happen before peak traffic kicks in at the designated hour - As mentioned earlier in the explanation, only when we want to specify a range of instances, then we must use min and max values. As the given use-case requires exactly 10 instances to be available during the peak hour, so we must set the desired capacity to 10. Hence this option is incorrect.
Configure your Auto Scaling group by creating a target tracking policy and setting the instance count to 10 at the designated hour. This causes the scale-out to happen before peak traffic kicks in at the designated hour
Configure your Auto Scaling group by creating a simple tracking policy and setting the instance count to 10 at the designated hour. This causes the scale-out to happen before peak traffic kicks in at the designated hour
Target tracking policy or simple tracking policy cannot be used to effect a scaling action at a certain designated hour. Both these options have been added as distractors.
Reference:
https://docs.aws.amazon.com/autoscaling/ec2/userguide/schedule_time.html
Explanation
Correct option:
Configure your Auto Scaling group by creating a scheduled action that kicks-off at the designated hour on the last day of the month. Set the desired capacity of instances to 10. This causes the scale-out to happen before peak traffic kicks in at the designated hour
Scheduled scaling allows you to set your own scaling schedule. For example, let's say that every week the traffic to your web application starts to increase on Wednesday, remains high on Thursday, and starts to decrease on Friday. You can plan your scaling actions based on the predictable traffic patterns of your web application. Scaling actions are performed automatically as a function of time and date.
A scheduled action sets the minimum, maximum, and desired sizes to what is specified by the scheduled action at the time specified by the scheduled action. For the given use case, the correct solution is to set the desired capacity to 10. When we want to specify a range of instances, then we must use min and max values.
Incorrect options:
Configure your Auto Scaling group by creating a scheduled action that kicks-off at the designated hour on the last day of the month. Set the min count as well as the max count of instances to 10. This causes the scale-out to happen before peak traffic kicks in at the designated hour - As mentioned earlier in the explanation, only when we want to specify a range of instances, then we must use min and max values. As the given use-case requires exactly 10 instances to be available during the peak hour, so we must set the desired capacity to 10. Hence this option is incorrect.
Configure your Auto Scaling group by creating a target tracking policy and setting the instance count to 10 at the designated hour. This causes the scale-out to happen before peak traffic kicks in at the designated hour
Configure your Auto Scaling group by creating a simple tracking policy and setting the instance count to 10 at the designated hour. This causes the scale-out to happen before peak traffic kicks in at the designated hour
Target tracking policy or simple tracking policy cannot be used to effect a scaling action at a certain designated hour. Both these options have been added as distractors.
Reference:
https://docs.aws.amazon.com/autoscaling/ec2/userguide/schedule_time.html
Question 19 Single Choice
The product team at a startup has figured out a market need to support both stateful and stateless client-server communications via the application programming interface (APIs) developed using its platform. You have been hired by the startup as a solutions architect to build a solution to fulfill this market need using Amazon API Gateway.
Which of the following would you identify as correct?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Amazon API Gateway creates RESTful APIs that enable stateless client-server communication and Amazon API Gateway also creates WebSocket APIs that adhere to the WebSocket protocol, which enables stateful, full-duplex communication between client and server
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. APIs act as the front door for applications to access data, business logic, or functionality from your backend services. Using API Gateway, you can create RESTful APIs and WebSocket APIs that enable real-time two-way communication applications.
How Amazon API Gateway Works: 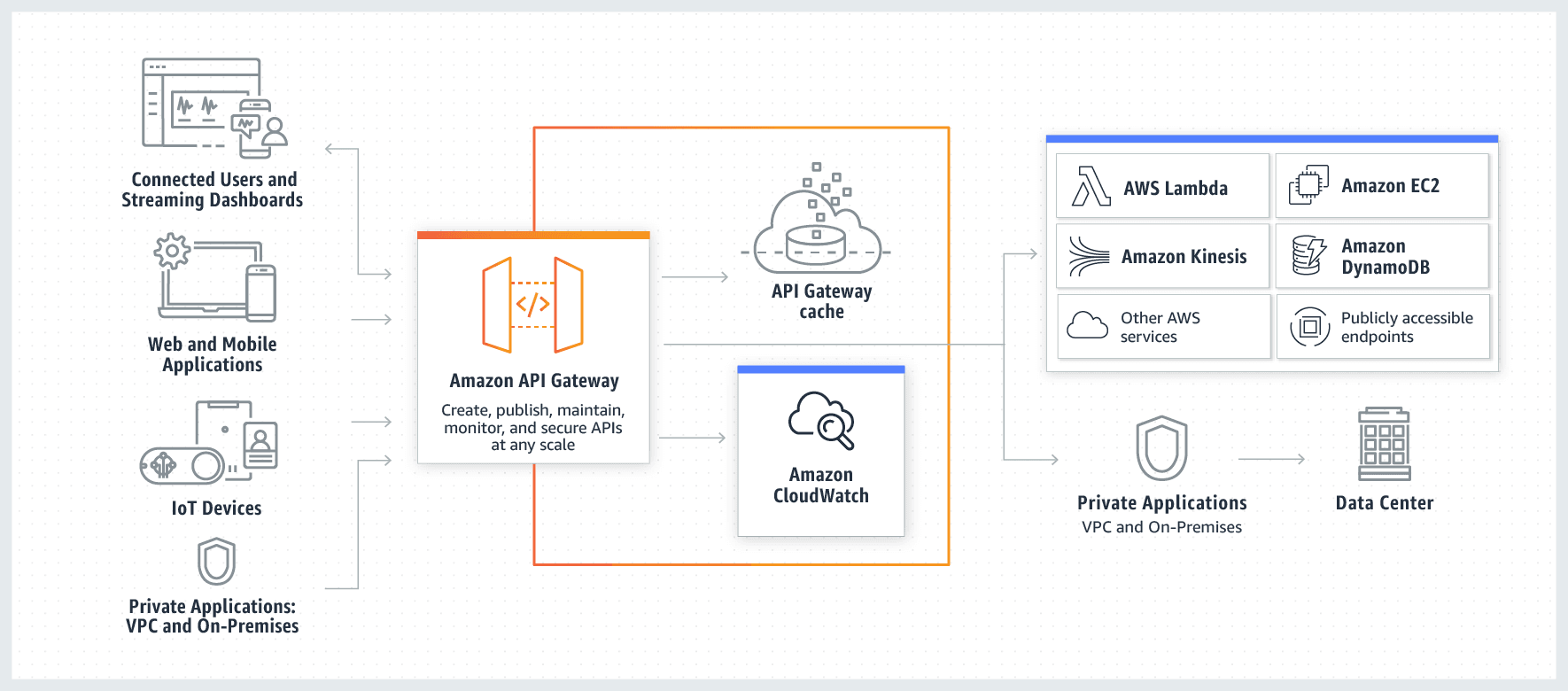 via - https://aws.amazon.com/api-gateway/
via - https://aws.amazon.com/api-gateway/
Amazon API Gateway creates RESTful APIs that:
Are HTTP-based.
Enable stateless client-server communication.
Implement standard HTTP methods such as GET, POST, PUT, PATCH, and DELETE.
Amazon API Gateway creates WebSocket APIs that:
Adhere to the WebSocket protocol, which enables stateful, full-duplex communication between client and server. Route incoming messages based on message content.
So Amazon API Gateway supports stateless RESTful APIs as well as stateful WebSocket APIs. Therefore this option is correct.
Incorrect options:
Amazon API Gateway creates RESTful APIs that enable stateful client-server communication and Amazon API Gateway also creates WebSocket APIs that adhere to the WebSocket protocol, which enables stateful, full-duplex communication between client and server
Amazon API Gateway creates RESTful APIs that enable stateless client-server communication and Amazon API Gateway also creates WebSocket APIs that adhere to the WebSocket protocol, which enables stateless, full-duplex communication between client and server
Amazon API Gateway creates RESTful APIs that enable stateful client-server communication and Amazon API Gateway also creates WebSocket APIs that adhere to the WebSocket protocol, which enables stateless, full-duplex communication between client and server
These three options contradict the earlier details provided in the explanation. To summarize, Amazon API Gateway supports stateless RESTful APIs and stateful WebSocket APIs. Hence these options are incorrect.
Reference:
https://docs.aws.amazon.com/apigateway/latest/developerguide/welcome.html
Explanation
Correct option:
Amazon API Gateway creates RESTful APIs that enable stateless client-server communication and Amazon API Gateway also creates WebSocket APIs that adhere to the WebSocket protocol, which enables stateful, full-duplex communication between client and server
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. APIs act as the front door for applications to access data, business logic, or functionality from your backend services. Using API Gateway, you can create RESTful APIs and WebSocket APIs that enable real-time two-way communication applications.
How Amazon API Gateway Works: via - https://aws.amazon.com/api-gateway/
Amazon API Gateway creates RESTful APIs that:
Are HTTP-based.
Enable stateless client-server communication.
Implement standard HTTP methods such as GET, POST, PUT, PATCH, and DELETE.
Amazon API Gateway creates WebSocket APIs that:
Adhere to the WebSocket protocol, which enables stateful, full-duplex communication between client and server. Route incoming messages based on message content.
So Amazon API Gateway supports stateless RESTful APIs as well as stateful WebSocket APIs. Therefore this option is correct.
Incorrect options:
Amazon API Gateway creates RESTful APIs that enable stateful client-server communication and Amazon API Gateway also creates WebSocket APIs that adhere to the WebSocket protocol, which enables stateful, full-duplex communication between client and server
Amazon API Gateway creates RESTful APIs that enable stateless client-server communication and Amazon API Gateway also creates WebSocket APIs that adhere to the WebSocket protocol, which enables stateless, full-duplex communication between client and server
Amazon API Gateway creates RESTful APIs that enable stateful client-server communication and Amazon API Gateway also creates WebSocket APIs that adhere to the WebSocket protocol, which enables stateless, full-duplex communication between client and server
These three options contradict the earlier details provided in the explanation. To summarize, Amazon API Gateway supports stateless RESTful APIs and stateful WebSocket APIs. Hence these options are incorrect.
Reference:
https://docs.aws.amazon.com/apigateway/latest/developerguide/welcome.html
Question 20 Multiple Choice
A company uses Amazon S3 buckets for storing sensitive customer data. The company has defined different retention periods for different objects present in the Amazon S3 buckets, based on the compliance requirements. But, the retention rules do not seem to work as expected.
Which of the following options represent a valid configuration for setting up retention periods for objects in Amazon S3 buckets? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
When you apply a retention period to an object version explicitly, you specify a Retain Until Date for the object version
You can place a retention period on an object version either explicitly or through a bucket default setting. When you apply a retention period to an object version explicitly, you specify a Retain Until Date for the object version. Amazon S3 stores the Retain Until Date setting in the object version's metadata and protects the object version until the retention period expires.
Different versions of a single object can have different retention modes and periods
Like all other Object Lock settings, retention periods apply to individual object versions. Different versions of a single object can have different retention modes and periods.
For example, suppose that you have an object that is 15 days into a 30-day retention period, and you PUT an object into Amazon S3 with the same name and a 60-day retention period. In this case, your PUT succeeds, and Amazon S3 creates a new version of the object with a 60-day retention period. The older version maintains its original retention period and becomes deletable in 15 days.
Incorrect options:
You cannot place a retention period on an object version through a bucket default setting - You can place a retention period on an object version either explicitly or through a bucket default setting.
When you use bucket default settings, you specify a Retain Until Date for the object version - When you use bucket default settings, you don't specify a Retain Until Date. Instead, you specify a duration, in either days or years, for which every object version placed in the bucket should be protected.
The bucket default settings will override any explicit retention mode or period you request on an object version - If your request to place an object version in a bucket contains an explicit retention mode and period, those settings override any bucket default settings for that object version.
Reference:
https://docs.aws.amazon.com/AmazonS3/latest/dev/object-lock-overview.html
Explanation
Correct options:
When you apply a retention period to an object version explicitly, you specify a Retain Until Date for the object version
You can place a retention period on an object version either explicitly or through a bucket default setting. When you apply a retention period to an object version explicitly, you specify a Retain Until Date for the object version. Amazon S3 stores the Retain Until Date setting in the object version's metadata and protects the object version until the retention period expires.
Different versions of a single object can have different retention modes and periods
Like all other Object Lock settings, retention periods apply to individual object versions. Different versions of a single object can have different retention modes and periods.
For example, suppose that you have an object that is 15 days into a 30-day retention period, and you PUT an object into Amazon S3 with the same name and a 60-day retention period. In this case, your PUT succeeds, and Amazon S3 creates a new version of the object with a 60-day retention period. The older version maintains its original retention period and becomes deletable in 15 days.
Incorrect options:
You cannot place a retention period on an object version through a bucket default setting - You can place a retention period on an object version either explicitly or through a bucket default setting.
When you use bucket default settings, you specify a Retain Until Date for the object version - When you use bucket default settings, you don't specify a Retain Until Date. Instead, you specify a duration, in either days or years, for which every object version placed in the bucket should be protected.
The bucket default settings will override any explicit retention mode or period you request on an object version - If your request to place an object version in a bucket contains an explicit retention mode and period, those settings override any bucket default settings for that object version.
Reference:
https://docs.aws.amazon.com/AmazonS3/latest/dev/object-lock-overview.html


