
AWS Certified Solutions Architect - Professional - (SAP-C02) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 1 Single Choice
The development team at a company needs to implement a client-side encryption mechanism for objects that will be stored in a new Amazon S3 bucket. The team created a CMK that is stored in AWS Key Management Service (AWS KMS) for this purpose. The team created the following IAM policy and attached it to an IAM role:
{ "Version": "2012-10-17", "Id": "key-policy-1", "Statement": [ { "Sid": "GetPut", "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": "arn:aws:s3:::ExampleBucket/*" }, { "Sid": "KMS", "Effect": "Allow", "Action": [ "kms:Decrypt", "kms:Encrypt" ], "Resource": "arn:aws:kms:us-west-1:111122223333:key/keyid-12345" } ] } The team was able to successfully get existing objects from the S3 bucket while testing. But any attempts to upload a new object resulted in an error. The error message stated that the action was forbidden.
Which IAM policy action should be added to the IAM policy to resolve the error?
Explanation

Click "Show Answer" to see the explanation here
Correct option:
kms:GenerateDataKey
GenerateDataKey returns a unique symmetric data key for use outside of AWS KMS. This operation returns a plaintext copy of the data key and a copy that is encrypted under a symmetric encryption KMS key that you specify. The bytes in the plaintext key are random; they are not related to the caller or the KMS key. You can use the plaintext key to encrypt your data outside of AWS KMS and store the encrypted data key with the encrypted data.
 via - https://docs.aws.amazon.com/kms/latest/APIReference/API_GenerateDataKey.html
via - https://docs.aws.amazon.com/kms/latest/APIReference/API_GenerateDataKey.html
Incorrect options:
kms:GetPublicKey - This option returns the public key of an asymmetric KMS key. Unlike the private key of an asymmetric KMS key, which never leaves AWS KMS unencrypted, callers with kms:GetPublicKey permission can download the public key of an asymmetric KMS key. It cannot be used for a client-side encryption mechanism.
kms:GetKeyPolicy - This option gets a key policy attached to the specified KMS key. It cannot be used for a client-side encryption mechanism.
kms:GetDataKey - This is a made-up option that serves as a distractor.
References:
https://docs.aws.amazon.com/kms/latest/APIReference/API_GenerateDataKey.html
https://docs.aws.amazon.com/kms/latest/APIReference/API_GetKeyPolicy.html
https://docs.aws.amazon.com/kms/latest/APIReference/API_GetPublicKey.html
Explanation
Correct option:
kms:GenerateDataKey
GenerateDataKey returns a unique symmetric data key for use outside of AWS KMS. This operation returns a plaintext copy of the data key and a copy that is encrypted under a symmetric encryption KMS key that you specify. The bytes in the plaintext key are random; they are not related to the caller or the KMS key. You can use the plaintext key to encrypt your data outside of AWS KMS and store the encrypted data key with the encrypted data.
via - https://docs.aws.amazon.com/kms/latest/APIReference/API_GenerateDataKey.html
Incorrect options:
kms:GetPublicKey - This option returns the public key of an asymmetric KMS key. Unlike the private key of an asymmetric KMS key, which never leaves AWS KMS unencrypted, callers with kms:GetPublicKey permission can download the public key of an asymmetric KMS key. It cannot be used for a client-side encryption mechanism.
kms:GetKeyPolicy - This option gets a key policy attached to the specified KMS key. It cannot be used for a client-side encryption mechanism.
kms:GetDataKey - This is a made-up option that serves as a distractor.
References:
https://docs.aws.amazon.com/kms/latest/APIReference/API_GenerateDataKey.html
https://docs.aws.amazon.com/kms/latest/APIReference/API_GetKeyPolicy.html
https://docs.aws.amazon.com/kms/latest/APIReference/API_GetPublicKey.html
Question 2 Single Choice
A SaaS company delivers a multi-tenant platform for healthcare record management using shared Amazon DynamoDB tables and AWS Lambda functions. Each healthcare provider (tenant) sends a unique provider_id as part of every request. The company wants to implement a tiered pricing model that bills each tenant based on their actual consumption of DynamoDB resources, including both read and write activity. The team already collects AWS Cost and Usage Reports (CUR) in a centralized billing account and wants to use this data to drive tenant-level chargebacks. They are looking for the most accurate, cost-effective, and low-maintenance approach for tracking and allocating DynamoDB usage costs per tenant.
Which solution best meets the company's requirements with the least operational effort?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Update Lambda function logic to log provider_id, estimated RCUs and WCUs per request, and metadata in structured JSON format to Amazon CloudWatch Logs. Schedule a separate Lambda function to process these logs, aggregate usage per tenant, and retrieve the total monthly DynamoDB spend via the AWS Cost Explorer API. Use the proportion of per-tenant usage to allocate DynamoDB costs accurately
This is the only option that offers both granularity and minimal operational effort. Here, the Lambda functions are instrumented to log structured JSON entries for each request, including the provider_id, RCUs, WCUs, and any relevant metadata. These logs are stored in Amazon CloudWatch Logs. A scheduled Lambda function is then used to parse the logs, aggregate the read/write usage for each tenant, and retrieve the total monthly DynamoDB charges via the AWS Cost Explorer API. The proportional usage per tenant is applied to the overall cost to calculate precise tenant-wise expenses. This method ensures high accuracy, supports long-term traceability through structured logs, leverages the CUR for total spend, and avoids the need for complex data pipelines or tagging hacks. It’s cost-effective, scalable, and aligns perfectly with the company’s goals.
Optimizing Cost Per Tenant Visibility in SaaS Solutions: 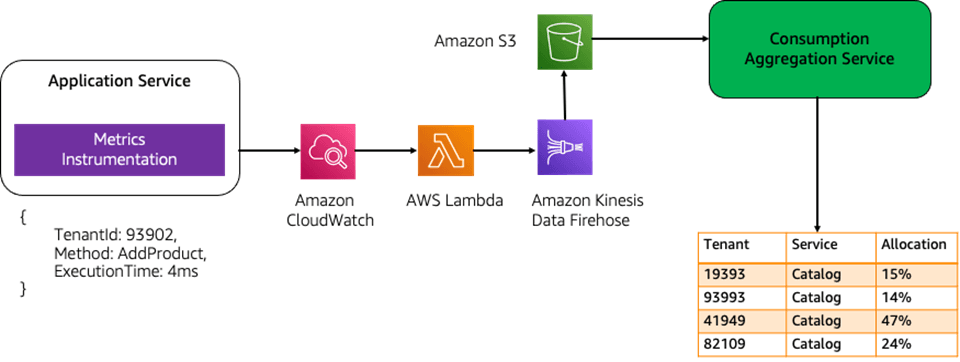 via - https://aws.amazon.com/blogs/apn/optimizing-cost-per-tenant-visibility-in-saas-solutions/
via - https://aws.amazon.com/blogs/apn/optimizing-cost-per-tenant-visibility-in-saas-solutions/
Incorrect options:
Enhance the Lambda functions to emit custom metrics to Amazon CloudWatch using the PutMetricData API. Track provider_id, estimated RCUs and WCUs per request, and create metric filters for each tenant. Use CloudWatch metric math and dashboards to aggregate usage. Combine this with DynamoDB pricing to estimate tenant-level cost - This approach suggests using the PutMetricData API in AWS Lambda to emit custom CloudWatch metrics for each tenant, with dimensions like provider_id, read capacity units (RCUs), and write capacity units (WCUs) consumed. CloudWatch dashboards and metric math can be configured to visualize tenant-specific usage patterns. While this method provides near real-time observability and minimal architectural changes, it is not ideal for long-term cost allocation and billing purposes. CloudWatch metrics are not integrated with AWS Cost and Usage Reports (CUR), making it difficult to validate historical billing data or maintain auditability. Additionally, there is added cost and complexity associated with storing and querying high-cardinality metrics over long retention periods. Hence, this solution lacks the robustness and long-term traceability needed for accurate chargeback.
Add cost allocation tags with provider_id to each DynamoDB table and activate the tag in the Billing and Cost Management console. Modify the Lambda functions to log the provider_id in CloudWatch Logs. Use the Cost and Usage Reports (CUR) to filter by tags and analyze tenant-level consumption and cost - This solution proposes assigning cost allocation tags with the key provider_id to DynamoDB tables and activating those tags in the AWS Billing and Cost Management console. The idea is to then use these tags within the CUR to analyze tenant-specific DynamoDB usage. However, this approach is flawed because all tenants share the same DynamoDB table, and AWS tagging is applied at the resource level, not at the per-request or per-tenant level. As a result, tagging the table does not distinguish between different tenants’ usage patterns. Logging provider_id in CloudWatch Logs does not influence cost allocation in CUR either. Therefore, while the approach sounds simple, it fundamentally fails to provide the tenant-level granularity that the billing system requires.
Enable DynamoDB Streams and configure a separate Lambda function to consume the stream, extracting the provider_id and size of each write. Aggregate write-based activity per tenant and map it against total DynamoDB spend - This option involves enabling DynamoDB Streams to capture write operations and using a separate Lambda function to extract the provider_id and relevant write metadata from each stream record. The data is then aggregated to estimate tenant-wise write activity, which is mapped to the total DynamoDB bill. While this method provides insight into write-heavy workloads, it has a critical flaw: it does not account for read activity, which is also a major component of DynamoDB billing. Consequently, tenants with significant read activity could be underbilled or overlooked entirely. Moreover, integrating Streams adds complexity and overhead, and the analysis is limited to write operations only. As such, this solution provides an incomplete and potentially inaccurate view of tenant costs, making it unsuitable for a fair and comprehensive billing model.
References:
https://aws.amazon.com/blogs/apn/optimizing-cost-per-tenant-visibility-in-saas-solutions/
https://aws.amazon.com/aws-cost-management/aws-cost-explorer/
https://docs.aws.amazon.com/lambda/latest/dg/monitoring-cloudwatchlogs.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publishingMetrics.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/using-metric-math.html
https://docs.aws.amazon.com/cur/latest/userguide/what-is-cur.html
Explanation
Correct option:
Update Lambda function logic to log provider_id, estimated RCUs and WCUs per request, and metadata in structured JSON format to Amazon CloudWatch Logs. Schedule a separate Lambda function to process these logs, aggregate usage per tenant, and retrieve the total monthly DynamoDB spend via the AWS Cost Explorer API. Use the proportion of per-tenant usage to allocate DynamoDB costs accurately
This is the only option that offers both granularity and minimal operational effort. Here, the Lambda functions are instrumented to log structured JSON entries for each request, including the provider_id, RCUs, WCUs, and any relevant metadata. These logs are stored in Amazon CloudWatch Logs. A scheduled Lambda function is then used to parse the logs, aggregate the read/write usage for each tenant, and retrieve the total monthly DynamoDB charges via the AWS Cost Explorer API. The proportional usage per tenant is applied to the overall cost to calculate precise tenant-wise expenses. This method ensures high accuracy, supports long-term traceability through structured logs, leverages the CUR for total spend, and avoids the need for complex data pipelines or tagging hacks. It’s cost-effective, scalable, and aligns perfectly with the company’s goals.
Optimizing Cost Per Tenant Visibility in SaaS Solutions: via - https://aws.amazon.com/blogs/apn/optimizing-cost-per-tenant-visibility-in-saas-solutions/
Incorrect options:
Enhance the Lambda functions to emit custom metrics to Amazon CloudWatch using the PutMetricData API. Track provider_id, estimated RCUs and WCUs per request, and create metric filters for each tenant. Use CloudWatch metric math and dashboards to aggregate usage. Combine this with DynamoDB pricing to estimate tenant-level cost - This approach suggests using the PutMetricData API in AWS Lambda to emit custom CloudWatch metrics for each tenant, with dimensions like provider_id, read capacity units (RCUs), and write capacity units (WCUs) consumed. CloudWatch dashboards and metric math can be configured to visualize tenant-specific usage patterns. While this method provides near real-time observability and minimal architectural changes, it is not ideal for long-term cost allocation and billing purposes. CloudWatch metrics are not integrated with AWS Cost and Usage Reports (CUR), making it difficult to validate historical billing data or maintain auditability. Additionally, there is added cost and complexity associated with storing and querying high-cardinality metrics over long retention periods. Hence, this solution lacks the robustness and long-term traceability needed for accurate chargeback.
Add cost allocation tags with provider_id to each DynamoDB table and activate the tag in the Billing and Cost Management console. Modify the Lambda functions to log the provider_id in CloudWatch Logs. Use the Cost and Usage Reports (CUR) to filter by tags and analyze tenant-level consumption and cost - This solution proposes assigning cost allocation tags with the key provider_id to DynamoDB tables and activating those tags in the AWS Billing and Cost Management console. The idea is to then use these tags within the CUR to analyze tenant-specific DynamoDB usage. However, this approach is flawed because all tenants share the same DynamoDB table, and AWS tagging is applied at the resource level, not at the per-request or per-tenant level. As a result, tagging the table does not distinguish between different tenants’ usage patterns. Logging provider_id in CloudWatch Logs does not influence cost allocation in CUR either. Therefore, while the approach sounds simple, it fundamentally fails to provide the tenant-level granularity that the billing system requires.
Enable DynamoDB Streams and configure a separate Lambda function to consume the stream, extracting the provider_id and size of each write. Aggregate write-based activity per tenant and map it against total DynamoDB spend - This option involves enabling DynamoDB Streams to capture write operations and using a separate Lambda function to extract the provider_id and relevant write metadata from each stream record. The data is then aggregated to estimate tenant-wise write activity, which is mapped to the total DynamoDB bill. While this method provides insight into write-heavy workloads, it has a critical flaw: it does not account for read activity, which is also a major component of DynamoDB billing. Consequently, tenants with significant read activity could be underbilled or overlooked entirely. Moreover, integrating Streams adds complexity and overhead, and the analysis is limited to write operations only. As such, this solution provides an incomplete and potentially inaccurate view of tenant costs, making it unsuitable for a fair and comprehensive billing model.
References:
https://aws.amazon.com/blogs/apn/optimizing-cost-per-tenant-visibility-in-saas-solutions/
https://aws.amazon.com/aws-cost-management/aws-cost-explorer/
https://docs.aws.amazon.com/lambda/latest/dg/monitoring-cloudwatchlogs.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publishingMetrics.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/using-metric-math.html
https://docs.aws.amazon.com/cur/latest/userguide/what-is-cur.html
Question 3 Single Choice
A company provides a web-based business-management platform for IT service companies across the globe to manage help desk, customer service, sales and marketing, and other critical business functions. More than 50,000 people use the company's platform, so the company must respond quickly to any reported problems. However, the company has issues with not having enough visibility into its systems to discover any issues. Multiple logs and monitoring systems are needed to understand the root cause of problems thereby taking hours to resolve. Even as the company is slowly moving towards serverless architecture using AWS Lambda/Amazon API Gateway/Amazon Elastic Container Service (Amazon ECS), the company wants to monitor the microservices and gain deeper insights into its serverless resources.
Which of the following will you recommend to address the given requirements?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use AWS X-Ray to analyze the microservices applications through request tracing. Configure Amazon CloudWatch for monitoring containers, latency, web server requests, and incoming load-balancer requests and create CloudWatch alarms to send out notifications if system latency is increasing
AWS X-Ray helps developers analyze and debug production, and distributed applications, such as those built using a microservices architecture.
Analyze and debug using X-Ray:  via - https://aws.amazon.com/xray/
via - https://aws.amazon.com/xray/
AWS X-Ray creates a map of services used by your application with trace data that you can use to drill into specific services or issues. This provides a view of connections between services in your application and aggregated data for each service, including average latency and failure rates.
X-Ray service map: 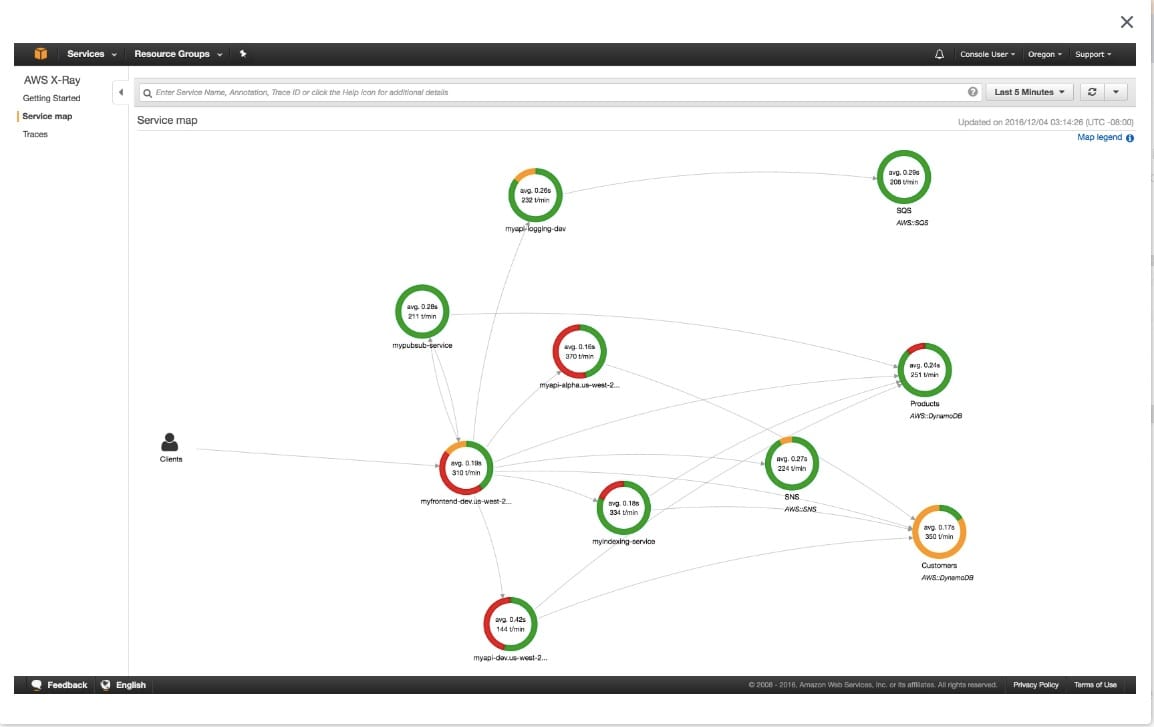 via - https://aws.amazon.com/xray/features/
via - https://aws.amazon.com/xray/features/
X-Ray Traces: 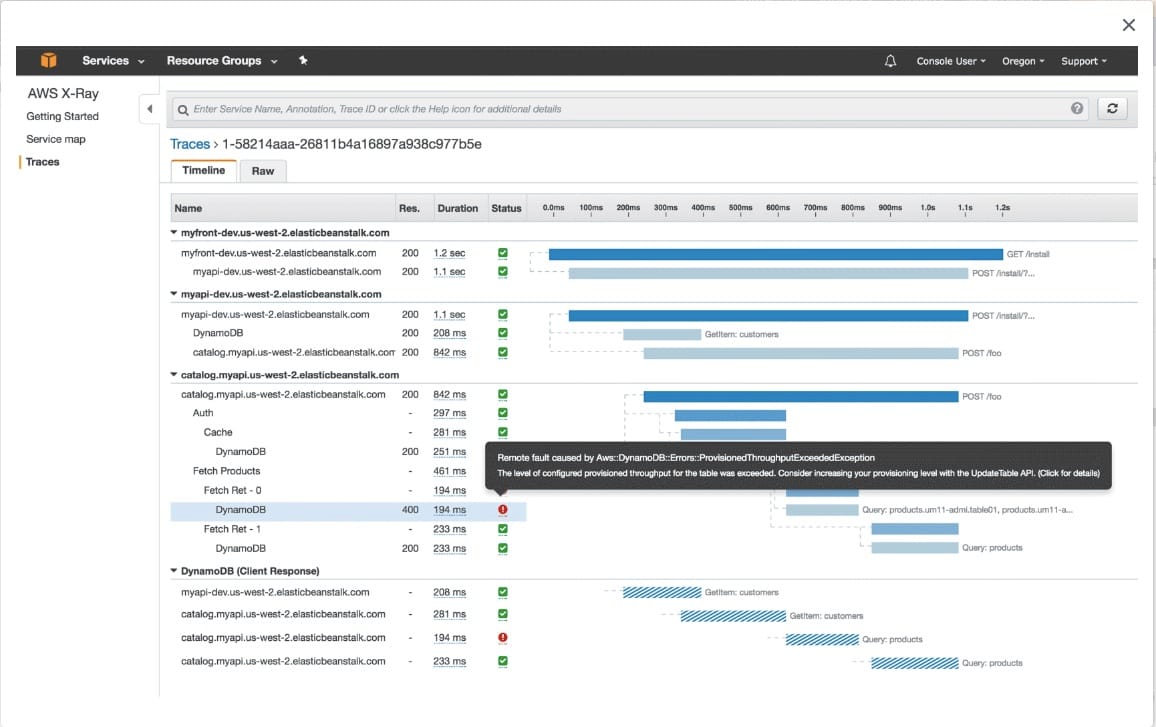 via - https://aws.amazon.com/xray/features/
via - https://aws.amazon.com/xray/features/
Amazon CloudWatch allows you to collect infrastructure metrics from more than 70 AWS services, such as Amazon Elastic Compute Cloud (Amazon EC2), Amazon DynamoDB, Amazon Simple Storage Service (Amazon S3), Amazon ECS, AWS Lambda, Amazon API Gateway, with no action on your part. For example, Amazon EC2 instances automatically publish CPU utilization, data transfer, and disk usage metrics to help you understand state changes. You can use built-in metrics for API Gateway to detect latency or use built-in metrics for AWS Lambda to detect errors or throttles. Likewise, Amazon CloudWatch also allows you to collect application metrics (such as user activity, error metrics or memory used) from your applications to monitor operational performance, troubleshoot issues, and spot trends.
Amazon CloudWatch for monitoring: 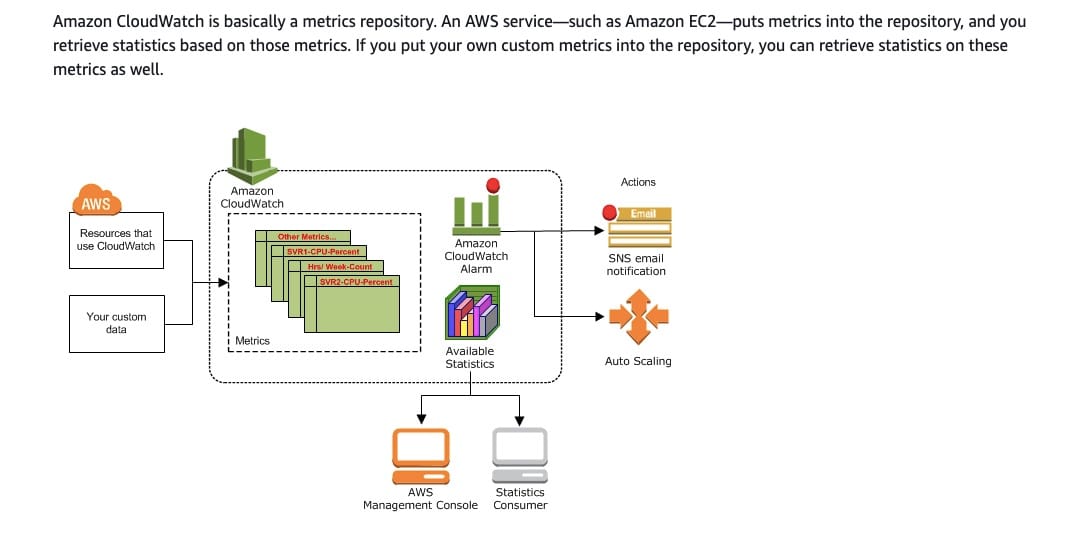 via - https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/cloudwatch_architecture.html
via - https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/cloudwatch_architecture.html
Incorrect options:
Use AWS X-Ray to analyze the microservices applications through request tracing. Configure Amazon EventBridge for monitoring containers, latency, web server requests, and incoming load-balancer requests and create alarms to send out notifications if system latency is increasing
Configure Amazon EventBridge for monitoring containers, latency, web server requests, and incoming load-balancer requests and create alarms to send out notifications if system latency is increasing. Use AWS Config to continually assesses, audit, and evaluate the configurations and relationships of your resources and trigger alarms when needed
Amazon EventBridge is a serverless event bus service that uses the Amazon CloudWatch Events API, but also includes more functionality, like the ability to ingest events from SaaS apps. EventBridge is designed to extend the event model beyond AWS, bringing data from software-as-a-service (SaaS) providers into your AWS environment. This means you can consume events from popular providers such as Zendesk, PagerDuty, and Auth0. You can use these in your applications with the same ease as any AWS-generated event.
For the given use case, you can use Cloudwatch for monitoring containers, latency, web server requests, and incoming load-balancer requests and create CloudWatch alarms to send out notifications if system latency is increasing. Therefore, both these options are incorrect.
Configure Amazon CloudWatch to monitor and analyze all microservices through request tracing. Enable CloudTrail to log all user activity - X-Ray can be used to monitor and analyze AWS microservices through request tracing, so this option is incorrect.
References:
https://aws.amazon.com/cloudwatch/features/
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/ContainerInsights.html
Explanation
Correct option:
Use AWS X-Ray to analyze the microservices applications through request tracing. Configure Amazon CloudWatch for monitoring containers, latency, web server requests, and incoming load-balancer requests and create CloudWatch alarms to send out notifications if system latency is increasing
AWS X-Ray helps developers analyze and debug production, and distributed applications, such as those built using a microservices architecture.
Analyze and debug using X-Ray: via - https://aws.amazon.com/xray/
AWS X-Ray creates a map of services used by your application with trace data that you can use to drill into specific services or issues. This provides a view of connections between services in your application and aggregated data for each service, including average latency and failure rates.
X-Ray service map: via - https://aws.amazon.com/xray/features/
X-Ray Traces: via - https://aws.amazon.com/xray/features/
Amazon CloudWatch allows you to collect infrastructure metrics from more than 70 AWS services, such as Amazon Elastic Compute Cloud (Amazon EC2), Amazon DynamoDB, Amazon Simple Storage Service (Amazon S3), Amazon ECS, AWS Lambda, Amazon API Gateway, with no action on your part. For example, Amazon EC2 instances automatically publish CPU utilization, data transfer, and disk usage metrics to help you understand state changes. You can use built-in metrics for API Gateway to detect latency or use built-in metrics for AWS Lambda to detect errors or throttles. Likewise, Amazon CloudWatch also allows you to collect application metrics (such as user activity, error metrics or memory used) from your applications to monitor operational performance, troubleshoot issues, and spot trends.
Amazon CloudWatch for monitoring: via - https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/cloudwatch_architecture.html
Incorrect options:
Use AWS X-Ray to analyze the microservices applications through request tracing. Configure Amazon EventBridge for monitoring containers, latency, web server requests, and incoming load-balancer requests and create alarms to send out notifications if system latency is increasing
Configure Amazon EventBridge for monitoring containers, latency, web server requests, and incoming load-balancer requests and create alarms to send out notifications if system latency is increasing. Use AWS Config to continually assesses, audit, and evaluate the configurations and relationships of your resources and trigger alarms when needed
Amazon EventBridge is a serverless event bus service that uses the Amazon CloudWatch Events API, but also includes more functionality, like the ability to ingest events from SaaS apps. EventBridge is designed to extend the event model beyond AWS, bringing data from software-as-a-service (SaaS) providers into your AWS environment. This means you can consume events from popular providers such as Zendesk, PagerDuty, and Auth0. You can use these in your applications with the same ease as any AWS-generated event.
For the given use case, you can use Cloudwatch for monitoring containers, latency, web server requests, and incoming load-balancer requests and create CloudWatch alarms to send out notifications if system latency is increasing. Therefore, both these options are incorrect.
Configure Amazon CloudWatch to monitor and analyze all microservices through request tracing. Enable CloudTrail to log all user activity - X-Ray can be used to monitor and analyze AWS microservices through request tracing, so this option is incorrect.
References:
https://aws.amazon.com/cloudwatch/features/
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/ContainerInsights.html
Question 4 Multiple Choice
A financial services company had a security incident recently and wants to review the security of its two-tier server architecture. The company wants to ensure that it follows the principle of least privilege while configuring the security groups for access between the EC2 instance-based app servers and RDS MySQL database servers. The security group for the EC2 instances as well as the security group for the MySQL database servers has no inbound and outbound rules configured currently.
As an AWS Certified Solutions Architect Professional, which of the following options would you recommend to adhere to the given requirements? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Create an outbound rule in the security group for the EC2 instance app servers using TCP protocol on port 3306. Set the destination as the security group for the MySQL DB servers
Create an inbound rule in the security group for the MySQL DB servers using TCP protocol on port 3306. Set the source as the security group for the EC2 instance app servers
A security group controls the traffic that is allowed to reach and leave the resources that it is associated with. For example, after you associate a security group with an EC2 instance, it controls the inbound and outbound traffic for the instance. Security groups are stateful. For example, if you send a request from an instance, the response traffic for that request is allowed to reach the instance regardless of the inbound security group rules. Responses to allowed inbound traffic are allowed to leave the instance, regardless of the outbound rules.
When you first create a security group, it has no inbound rules. Therefore, no inbound traffic is allowed until you add inbound rules to the security group. When you first create a security group, it has an outbound rule that allows all outbound traffic from the resource. You can remove the rule and add outbound rules that allow specific outbound traffic only. If your security group has no outbound rules, no outbound traffic is allowed.
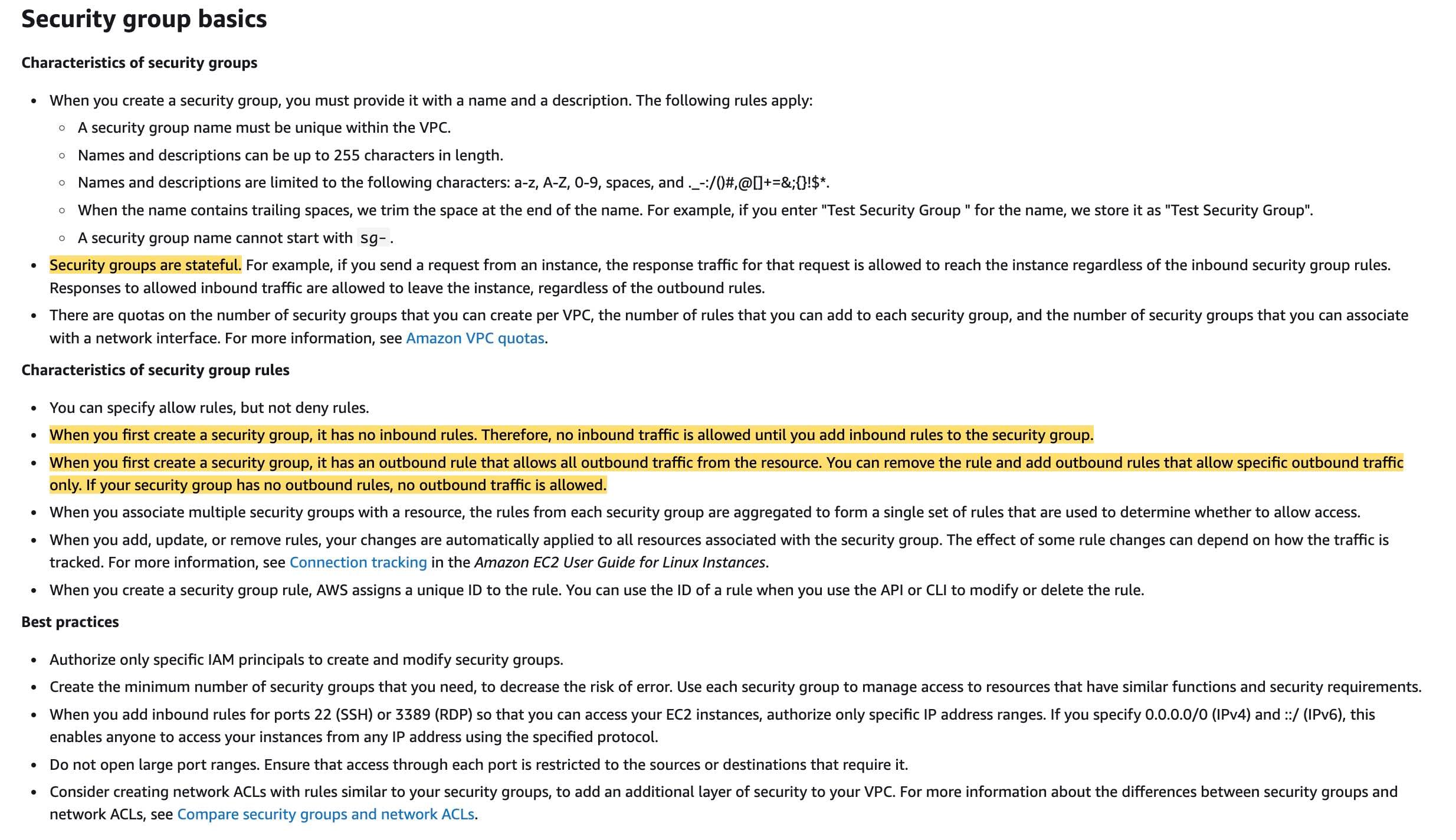 via - https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html
via - https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html
For the given use case, you need to set up an outbound rule in the security group for the EC2 instance app servers using TCP protocol on port 3306 and then select the destination as the security group for the MySQL DB servers. Further, you need to set up an inbound rule in the security group for the MySQL DB servers using TCP protocol on port 3306 and then select the source as the security group for the EC2 instance app servers. This combination would let the request be initiated from the EC2 instances and allowed into the DB servers. Since the security groups are stateful, the response from the DB servers would be allowed out of the DB servers (even though no outbound rules are configured in the DB security group) and further into the EC2 instances (even though no inbound rules are configured in the EC2 instance security group)
Incorrect options:
Create an outbound rule in the security group for the EC2 instance app servers using TCP protocol on the ephemeral port range. Set the destination as the security group for the MySQL DB servers - As explained above, you need to set up an outbound rule in the security group for the EC2 instance app servers using TCP protocol on port 3306 and NOT on the ephemeral port range because the MySQL DB is configured to process requests on port 3306. A common use-case for ephemeral ports: these are used in NACLs to handle response traffic. Consider a custom network ACL for a VPC that supports IPv4 only. It includes rules that allow HTTP and HTTPS traffic in (inbound rules 100 and 110). There's a corresponding outbound rule that enables responses to that inbound traffic (outbound rule 140, which covers ephemeral ports 32768-65535). So this option is incorrect.
 via - https://docs.aws.amazon.com/vpc/latest/userguide/vpc-network-acls.html#nacl-ephemeral-ports
via - https://docs.aws.amazon.com/vpc/latest/userguide/vpc-network-acls.html#nacl-ephemeral-ports
Create an outbound rule in the security group for the MySQL DB servers using TCP protocol on the ephemeral port range. Set the destination as the security group for the EC2 instance app servers
Create an outbound rule in the security group for the MySQL DB servers using TCP protocol on port 3306. Set the destination as the security group for the EC2 instance app servers
There is no need to create an outbound rule in the security group for the MySQL DB servers either on the ephemeral port range or port 3306 since the security groups are stateful therefore the response from the DB servers would be allowed out of the DB servers. Hence both these options are incorrect.
References:
https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html
https://docs.aws.amazon.com/vpc/latest/userguide/vpc-network-acls.html#nacl-ephemeral-ports
Explanation
Correct options:
Create an outbound rule in the security group for the EC2 instance app servers using TCP protocol on port 3306. Set the destination as the security group for the MySQL DB servers
Create an inbound rule in the security group for the MySQL DB servers using TCP protocol on port 3306. Set the source as the security group for the EC2 instance app servers
A security group controls the traffic that is allowed to reach and leave the resources that it is associated with. For example, after you associate a security group with an EC2 instance, it controls the inbound and outbound traffic for the instance. Security groups are stateful. For example, if you send a request from an instance, the response traffic for that request is allowed to reach the instance regardless of the inbound security group rules. Responses to allowed inbound traffic are allowed to leave the instance, regardless of the outbound rules.
When you first create a security group, it has no inbound rules. Therefore, no inbound traffic is allowed until you add inbound rules to the security group. When you first create a security group, it has an outbound rule that allows all outbound traffic from the resource. You can remove the rule and add outbound rules that allow specific outbound traffic only. If your security group has no outbound rules, no outbound traffic is allowed.
via - https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html
For the given use case, you need to set up an outbound rule in the security group for the EC2 instance app servers using TCP protocol on port 3306 and then select the destination as the security group for the MySQL DB servers. Further, you need to set up an inbound rule in the security group for the MySQL DB servers using TCP protocol on port 3306 and then select the source as the security group for the EC2 instance app servers. This combination would let the request be initiated from the EC2 instances and allowed into the DB servers. Since the security groups are stateful, the response from the DB servers would be allowed out of the DB servers (even though no outbound rules are configured in the DB security group) and further into the EC2 instances (even though no inbound rules are configured in the EC2 instance security group)
Incorrect options:
Create an outbound rule in the security group for the EC2 instance app servers using TCP protocol on the ephemeral port range. Set the destination as the security group for the MySQL DB servers - As explained above, you need to set up an outbound rule in the security group for the EC2 instance app servers using TCP protocol on port 3306 and NOT on the ephemeral port range because the MySQL DB is configured to process requests on port 3306. A common use-case for ephemeral ports: these are used in NACLs to handle response traffic. Consider a custom network ACL for a VPC that supports IPv4 only. It includes rules that allow HTTP and HTTPS traffic in (inbound rules 100 and 110). There's a corresponding outbound rule that enables responses to that inbound traffic (outbound rule 140, which covers ephemeral ports 32768-65535). So this option is incorrect.
via - https://docs.aws.amazon.com/vpc/latest/userguide/vpc-network-acls.html#nacl-ephemeral-ports
Create an outbound rule in the security group for the MySQL DB servers using TCP protocol on the ephemeral port range. Set the destination as the security group for the EC2 instance app servers
Create an outbound rule in the security group for the MySQL DB servers using TCP protocol on port 3306. Set the destination as the security group for the EC2 instance app servers
There is no need to create an outbound rule in the security group for the MySQL DB servers either on the ephemeral port range or port 3306 since the security groups are stateful therefore the response from the DB servers would be allowed out of the DB servers. Hence both these options are incorrect.
References:
https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html
https://docs.aws.amazon.com/vpc/latest/userguide/vpc-network-acls.html#nacl-ephemeral-ports
Question 5 Multiple Choice
Recently, an Amazon CloudFront distribution has been configured with an Amazon S3 bucket as the origin. However, users are getting an HTTP 307 Temporary Redirect response from Amazon S3.
What could be the reason for this behavior and how will you resolve the issue? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
When a new Amazon S3 bucket is created, it takes up to 24 hours before the bucket name propagates across all AWS Regions
CloudFront by default, forwards the requests to the default S3 endpoint. Change the origin domain name of the distribution to include the Regional endpoint of the bucket
After you create an Amazon S3 bucket, up to 24 hours can pass before the bucket name propagates across all AWS Regions. During this time, you might receive the 307 Temporary Redirect response for requests to Regional endpoints that aren't in the same Region as your bucket.
To avoid the 307 Temporary Redirect response, send requests only to the Regional endpoint in the same Region as your S3 bucket. If you're using an Amazon CloudFront distribution with an Amazon S3 origin, CloudFront forwards requests to the default S3 endpoint ( s3.amazonaws.com). The default S3 endpoint is in the us-east-1 Region. If you must access Amazon S3 within the first 24 hours of creating the bucket, you can change the origin domain name of the distribution. The domain name must include the Regional endpoint of the bucket. For example, if the bucket is in us-west-2, you can change the origin domain name from awsexamplebucketname.s3.amazonaws.com to awsexamplebucket.s3.us-west-2.amazonaws.com.
Incorrect options:
Enable Cross-Region replication for the S3 bucket so that CloudFront can retrieve the data immediately after the creation of the bucket - S3 Cross-Region Replication (CRR) is used to copy objects across Amazon S3 buckets in different AWS Regions. CRR can help you do the following - meet compliance requirements, minimize latency and increase operational efficiency. CRR however, cannot resolve the HTTP 307 error.
Configure CloudFront Cache-Control and Expires headers to a value of zero, to fetch new objects immediately from the S3 bucket - You can use the Cache-Control and Expires headers to control how long objects stay in the CloudFront cache. This option has been added as a distractor and is unrelated to the HTTP 307 error.
Enable Amazon S3 Transfer Acceleration to help CloudFront access data faster over long distances from the S3 bucket - Amazon S3 Transfer Acceleration is a bucket-level feature that enables fast, easy, and secure transfers of files over long distances between your client and an S3 bucket. Transfer Acceleration is designed to optimize transfer speeds from across the world into S3 buckets. This option has been added as a distractor and is unrelated to the HTTP 307 error.
Reference:
https://aws.amazon.com/premiumsupport/knowledge-center/s3-http-307-response/
Explanation
Correct options:
When a new Amazon S3 bucket is created, it takes up to 24 hours before the bucket name propagates across all AWS Regions
CloudFront by default, forwards the requests to the default S3 endpoint. Change the origin domain name of the distribution to include the Regional endpoint of the bucket
After you create an Amazon S3 bucket, up to 24 hours can pass before the bucket name propagates across all AWS Regions. During this time, you might receive the 307 Temporary Redirect response for requests to Regional endpoints that aren't in the same Region as your bucket.
To avoid the 307 Temporary Redirect response, send requests only to the Regional endpoint in the same Region as your S3 bucket. If you're using an Amazon CloudFront distribution with an Amazon S3 origin, CloudFront forwards requests to the default S3 endpoint ( s3.amazonaws.com). The default S3 endpoint is in the us-east-1 Region. If you must access Amazon S3 within the first 24 hours of creating the bucket, you can change the origin domain name of the distribution. The domain name must include the Regional endpoint of the bucket. For example, if the bucket is in us-west-2, you can change the origin domain name from awsexamplebucketname.s3.amazonaws.com to awsexamplebucket.s3.us-west-2.amazonaws.com.
Incorrect options:
Enable Cross-Region replication for the S3 bucket so that CloudFront can retrieve the data immediately after the creation of the bucket - S3 Cross-Region Replication (CRR) is used to copy objects across Amazon S3 buckets in different AWS Regions. CRR can help you do the following - meet compliance requirements, minimize latency and increase operational efficiency. CRR however, cannot resolve the HTTP 307 error.
Configure CloudFront Cache-Control and Expires headers to a value of zero, to fetch new objects immediately from the S3 bucket - You can use the Cache-Control and Expires headers to control how long objects stay in the CloudFront cache. This option has been added as a distractor and is unrelated to the HTTP 307 error.
Enable Amazon S3 Transfer Acceleration to help CloudFront access data faster over long distances from the S3 bucket - Amazon S3 Transfer Acceleration is a bucket-level feature that enables fast, easy, and secure transfers of files over long distances between your client and an S3 bucket. Transfer Acceleration is designed to optimize transfer speeds from across the world into S3 buckets. This option has been added as a distractor and is unrelated to the HTTP 307 error.
Reference:
https://aws.amazon.com/premiumsupport/knowledge-center/s3-http-307-response/
Question 6 Multiple Choice
A company uses Amazon FSx for Windows File Server with deployment type of Single-AZ 2 as its file storage service for its non-core functions. With a change in the company's policy that mandates high availability of data for all its functions, the company needs to change the existing configuration. The company also needs to monitor the file system activity as well as the end-user actions on the Amazon FSx file server.
Which solutions will you combine to implement these requirements? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Configure a new Amazon FSx for Windows file system with a deployment type of Multi-AZ. Transfer data to the newly created file system using the AWS DataSync service. Point all the file system users to the new location. You can test the failover of your Multi-AZ file system by modifying its throughput capacity
In a Multi-AZ deployment, Amazon FSx automatically provisions and maintains a standby file server in a different Availability Zone. Any changes written to disk in your file system are synchronously replicated across Availability Zones to the standby. If there is planned file system maintenance or unplanned service disruption, Amazon FSx automatically fails over to the secondary file server, allowing you to continue accessing your data without manual intervention. Multi-AZ file systems are recommended for most production workloads that require high availability of shared Windows file data.
To migrate your existing files to FSx for Windows File Server file systems, AWS recommends using AWS DataSync, an online data transfer service designed to simplify, automate, and accelerate copying large amounts of data to and from AWS storage services. DataSync copies data over the internet or AWS Direct Connect.
You can test the failover of your Multi-AZ file system by modifying its throughput capacity. When you modify your file system's throughput capacity, Amazon FSx switches out the file system's file server. Multi-AZ file systems automatically fail over to the secondary server while Amazon FSx replaces the preferred server file server first. Then the file system automatically fails back to the new primary server and Amazon FSx replaces the secondary file server.
 via - https://docs.aws.amazon.com/fsx/latest/WindowsGuide/high-availability-multiAZ.html
via - https://docs.aws.amazon.com/fsx/latest/WindowsGuide/high-availability-multiAZ.html
You can monitor storage capacity and file system activity using Amazon CloudWatch, and monitor end-user actions with file access auditing using Amazon CloudWatch Logs and Amazon Kinesis Data Firehose
You can monitor storage capacity and file system activity using Amazon CloudWatch. You can monitor end-user actions with file access auditing at any time (during or after the creation of a file system) via the AWS Management Console or the Amazon FSx CLI or API. You can also change the destination for publishing user access events by logging these events to CloudWatch Logs or streaming to Kinesis Data Firehose.
Incorrect options:
Configure a new Amazon FSx for Windows file system with a deployment type of Single-AZ 1. Transfer data to the newly created file system using the AWS DataSync service. Point all the file system users to the new location - With Single-AZ file systems, Amazon FSx automatically replicates your data within an Availability Zone (AZ) to protect it from component failure. It continuously monitors for hardware failures and automatically replaces infrastructure components in the event of a failure. Single-AZ 2 is the latest generation of Single-AZ file systems, and it supports both SSD and HDD storage. Single-AZ 1 file systems support SSD storage, Microsoft Distributed File System Replication (DFSR), and the use of custom DNS names. Single-AZ file systems will experience unavailability during file system maintenance, infrastructure component replacement, and when an Availability Zone is unavailable.
Multi-AZ file systems are recommended for most production workloads that require high availability of shared Windows file data. Single-AZ file systems offer a lower price point for workloads that don’t require the high availability of a Multi-AZ solution and that can recover from the most recent file system backup if data is lost.
You can monitor the file system activity using AWS CloudTrail and monitor end-user actions with file access auditing using Amazon CloudWatch Logs - This statement is incorrect. You can monitor storage capacity and file system activity using Amazon CloudWatch, monitor all Amazon FSx API calls using AWS CloudTrail, and monitor end-user actions with file access auditing using Amazon CloudWatch Logs and Amazon Kinesis Data Firehose.
Configure a new Amazon FSx for Windows file system with a deployment type of Multi-AZ. Transfer data to the newly created file system using the AWS DataSync service. Point all the file system users to the new location. You can test the failover of your Multi-AZ file system by modifying the elastic network interfaces associated with your file system - You must not modify or delete the elastic network interfaces associated with your file system. Modifying or deleting the network interface can cause a permanent loss of connection between your VPC and your file system. Therefore this option is incorrect.
References:
https://docs.aws.amazon.com/fsx/latest/WindowsGuide/high-availability-multiAZ.html
https://docs.aws.amazon.com/fsx/latest/WindowsGuide/migrate-files-fsx.html
https://aws.amazon.com/fsx/windows/faqs/
https://docs.aws.amazon.com/fsx/latest/WindowsGuide/limit-access-security-groups.html
Explanation
Correct options:
Configure a new Amazon FSx for Windows file system with a deployment type of Multi-AZ. Transfer data to the newly created file system using the AWS DataSync service. Point all the file system users to the new location. You can test the failover of your Multi-AZ file system by modifying its throughput capacity
In a Multi-AZ deployment, Amazon FSx automatically provisions and maintains a standby file server in a different Availability Zone. Any changes written to disk in your file system are synchronously replicated across Availability Zones to the standby. If there is planned file system maintenance or unplanned service disruption, Amazon FSx automatically fails over to the secondary file server, allowing you to continue accessing your data without manual intervention. Multi-AZ file systems are recommended for most production workloads that require high availability of shared Windows file data.
To migrate your existing files to FSx for Windows File Server file systems, AWS recommends using AWS DataSync, an online data transfer service designed to simplify, automate, and accelerate copying large amounts of data to and from AWS storage services. DataSync copies data over the internet or AWS Direct Connect.
You can test the failover of your Multi-AZ file system by modifying its throughput capacity. When you modify your file system's throughput capacity, Amazon FSx switches out the file system's file server. Multi-AZ file systems automatically fail over to the secondary server while Amazon FSx replaces the preferred server file server first. Then the file system automatically fails back to the new primary server and Amazon FSx replaces the secondary file server.
via - https://docs.aws.amazon.com/fsx/latest/WindowsGuide/high-availability-multiAZ.html
You can monitor storage capacity and file system activity using Amazon CloudWatch, and monitor end-user actions with file access auditing using Amazon CloudWatch Logs and Amazon Kinesis Data Firehose
You can monitor storage capacity and file system activity using Amazon CloudWatch. You can monitor end-user actions with file access auditing at any time (during or after the creation of a file system) via the AWS Management Console or the Amazon FSx CLI or API. You can also change the destination for publishing user access events by logging these events to CloudWatch Logs or streaming to Kinesis Data Firehose.
Incorrect options:
Configure a new Amazon FSx for Windows file system with a deployment type of Single-AZ 1. Transfer data to the newly created file system using the AWS DataSync service. Point all the file system users to the new location - With Single-AZ file systems, Amazon FSx automatically replicates your data within an Availability Zone (AZ) to protect it from component failure. It continuously monitors for hardware failures and automatically replaces infrastructure components in the event of a failure. Single-AZ 2 is the latest generation of Single-AZ file systems, and it supports both SSD and HDD storage. Single-AZ 1 file systems support SSD storage, Microsoft Distributed File System Replication (DFSR), and the use of custom DNS names. Single-AZ file systems will experience unavailability during file system maintenance, infrastructure component replacement, and when an Availability Zone is unavailable.
Multi-AZ file systems are recommended for most production workloads that require high availability of shared Windows file data. Single-AZ file systems offer a lower price point for workloads that don’t require the high availability of a Multi-AZ solution and that can recover from the most recent file system backup if data is lost.
You can monitor the file system activity using AWS CloudTrail and monitor end-user actions with file access auditing using Amazon CloudWatch Logs - This statement is incorrect. You can monitor storage capacity and file system activity using Amazon CloudWatch, monitor all Amazon FSx API calls using AWS CloudTrail, and monitor end-user actions with file access auditing using Amazon CloudWatch Logs and Amazon Kinesis Data Firehose.
Configure a new Amazon FSx for Windows file system with a deployment type of Multi-AZ. Transfer data to the newly created file system using the AWS DataSync service. Point all the file system users to the new location. You can test the failover of your Multi-AZ file system by modifying the elastic network interfaces associated with your file system - You must not modify or delete the elastic network interfaces associated with your file system. Modifying or deleting the network interface can cause a permanent loss of connection between your VPC and your file system. Therefore this option is incorrect.
References:
https://docs.aws.amazon.com/fsx/latest/WindowsGuide/high-availability-multiAZ.html
https://docs.aws.amazon.com/fsx/latest/WindowsGuide/migrate-files-fsx.html
https://aws.amazon.com/fsx/windows/faqs/
https://docs.aws.amazon.com/fsx/latest/WindowsGuide/limit-access-security-groups.html
Question 7 Multiple Choice
A social learning platform allows students to connect with other students as well as experts and professionals from academic, research institutes and industry. The engineering team at the company manages 5 Amazon EC2 instances that make read-heavy database requests to the Amazon RDS for PostgreSQL DB cluster. As an AWS Certified Solutions Architect Professional, you have been asked to make the database cluster resilient from a disaster recovery perspective.
Which of the following features will help you prepare for database disaster recovery? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use cross-Region Read Replicas
In addition to using Read Replicas to reduce the load on your source DB instance, you can also use Read Replicas to implement a DR solution for your production DB environment. If the source DB instance fails, you can promote your Read Replica to a standalone source server. Read Replicas can also be created in a different Region than the source database. Using a cross-Region Read Replica can help ensure that you get back up and running if you experience a regional availability issue.
Enable the automated backup feature of Amazon RDS in a multi-AZ deployment that creates backups in a single or multiple AWS Region(s)
Amazon RDS provides high availability and failover support for DB instances using Multi-AZ deployments. Amazon RDS uses several different technologies to provide failover support. Multi-AZ deployments for MariaDB, MySQL, Oracle, and PostgreSQL DB instances use Amazon's failover technology.
The automated backup feature of Amazon RDS enables point-in-time recovery for your database instance. Amazon RDS will backup your database and transaction logs and store both for a user-specified retention period. If it’s a Multi-AZ configuration, backups occur on the standby to reduce I/O impact on the primary. Amazon RDS supports single Region or cross-Region automated backups.
Incorrect options:
Use RAID 1 configuration for the RDS DB cluster - This option has been added as a distractor. RAID configuration options can only be used for EC2 instance–hosted databases. By using EBS storage volumes with EC2 instances, you can configure volumes with any RAID levels. For example, for greater I/O performance, you can opt for RAID 0, which can stripe multiple volumes together. RAID 1 can be used for data redundancy because it mirrors two volumes together.
Use RDS Provisioned IOPS (SSD) Storage in place of General Purpose (SSD) Storage - Amazon RDS Provisioned IOPS Storage is an SSD-backed storage option designed to deliver fast, predictable, and consistent I/O performance. This storage type enhances the performance of the RDS database, but this isn't a disaster recovery option.
Use database cloning feature of the RDS DB cluster - This option has been added as a distractor. Database cloning is only available for Aurora and not for RDS.
References:
https://aws.amazon.com/rds/features/
https://aws.amazon.com/blogs/database/implementing-a-disaster-recovery-strategy-with-amazon-rds/
Explanation
Correct option:
Use cross-Region Read Replicas
In addition to using Read Replicas to reduce the load on your source DB instance, you can also use Read Replicas to implement a DR solution for your production DB environment. If the source DB instance fails, you can promote your Read Replica to a standalone source server. Read Replicas can also be created in a different Region than the source database. Using a cross-Region Read Replica can help ensure that you get back up and running if you experience a regional availability issue.
Enable the automated backup feature of Amazon RDS in a multi-AZ deployment that creates backups in a single or multiple AWS Region(s)
Amazon RDS provides high availability and failover support for DB instances using Multi-AZ deployments. Amazon RDS uses several different technologies to provide failover support. Multi-AZ deployments for MariaDB, MySQL, Oracle, and PostgreSQL DB instances use Amazon's failover technology.
The automated backup feature of Amazon RDS enables point-in-time recovery for your database instance. Amazon RDS will backup your database and transaction logs and store both for a user-specified retention period. If it’s a Multi-AZ configuration, backups occur on the standby to reduce I/O impact on the primary. Amazon RDS supports single Region or cross-Region automated backups.
Incorrect options:
Use RAID 1 configuration for the RDS DB cluster - This option has been added as a distractor. RAID configuration options can only be used for EC2 instance–hosted databases. By using EBS storage volumes with EC2 instances, you can configure volumes with any RAID levels. For example, for greater I/O performance, you can opt for RAID 0, which can stripe multiple volumes together. RAID 1 can be used for data redundancy because it mirrors two volumes together.
Use RDS Provisioned IOPS (SSD) Storage in place of General Purpose (SSD) Storage - Amazon RDS Provisioned IOPS Storage is an SSD-backed storage option designed to deliver fast, predictable, and consistent I/O performance. This storage type enhances the performance of the RDS database, but this isn't a disaster recovery option.
Use database cloning feature of the RDS DB cluster - This option has been added as a distractor. Database cloning is only available for Aurora and not for RDS.
References:
https://aws.amazon.com/rds/features/
https://aws.amazon.com/blogs/database/implementing-a-disaster-recovery-strategy-with-amazon-rds/
Question 8 Multiple Choice
An e-commerce company is investigating user reports of its Java-based web application errors on the day of the Thanksgiving sale. The development team recovered the logs created by the EC2 instance-hosted web servers and reviewed Aurora DB cluster performance metrics. Some of the web servers were terminated before logs could be collected and the Aurora metrics were inadequate for query performance analysis.
Which of the following steps would you recommend to make the monitoring process more reliable to troubleshoot any future events due to traffic spikes? (Select three)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Configure the Aurora MySQL DB cluster to publish slow query and error logs to Amazon CloudWatch Logs
You can configure your Aurora MySQL DB cluster to publish general, slow, audit, and error log data to a log group in Amazon CloudWatch Logs. With CloudWatch Logs, you can perform real-time analysis of the log data, and use CloudWatch to create alarms and view metrics. You can use CloudWatch Logs to store your log records in highly durable storage.
To publish logs to CloudWatch Logs, the respective logs must be enabled. Error logs are enabled by default, but you must enable the other types of logs explicitly. The slow query logs and error logs can be used to identify the root cause behind the given issue.
Install and configure an Amazon CloudWatch Logs agent on the EC2 instances to send the application logs to CloudWatch Logs
You can collect metrics and logs from Amazon EC2 instances and on-premises servers with the CloudWatch agent. The unified CloudWatch agent enables you to collect internal system-level metrics from Amazon EC2 instances across operating systems. The metrics can include in-guest metrics, in addition to the metrics for EC2 instances. You can collect logs from Amazon EC2 instances and on-premises servers, running either Linux or Windows Server. The application logs (via the CloudWatch logs) can be used to identify the root cause behind the given issue.
Set up the AWS X-Ray SDK to trace incoming HTTP requests on the EC2 instances as well as set up tracing of SQL queries with the X-Ray SDK for Java
You can use the X-Ray SDK to trace incoming HTTP requests that your application serves on an EC2 instance. Use a Filter to instrument incoming HTTP requests. When you add the X-Ray servlet filter to your application, the X-Ray SDK for Java creates a segment for each sampled request. This segment includes timing, method, and disposition of the HTTP request. You can also instrument your SQL database queries by adding the X-Ray SDK for Java JDBC interceptor to your data source configuration. X-Ray tracing for the HTTP requests as well as the SQL queries can help in identifying the root cause behind the given issue.
Incorrect options:
Use CloudTrail and configure a trail to deliver Amazon Aurora query activity to an Amazon S3 bucket. Process and analyze these real-time log streams using Amazon Kinesis Data Streams - You can use CloudTrail to view, search, download, archive, analyze, and respond to account activity across your AWS infrastructure. You can identify who or what took which action, what resources were acted upon, when the event occurred, and other details to help you analyze and respond to activity in your AWS account. CloudTrail provides a record of actions taken by a user, role, or AWS service in Amazon Aurora. However, CloudTrail does not capture any query activity in Aurora, so this option is incorrect.
Enable detailed monitoring for Amazon EC2 instances to send data points to CloudWatch every minute. Track the metric 'CPUUtilization' to know when the auto-scaling process can kick in - Tracking the 'CPUUtilization' parameter is irrelevant to the given use case as it would not point to the root cause behind the given issue.
Enable Aurora lab mode which will then publish all logs and activity on Aurora DB to CloudWatch logs - Aurora lab mode is used to enable Aurora features that are available in the current Aurora database version but are not enabled by default. These features are tested in development/test environments. Aurora lab mode is not relevant for capturing the log activity of Aurora DB. This option has been added as a distractor.
References:
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/Install-CloudWatch-Agent.html
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Integrating.CloudWatch.html
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/viewing_metrics_with_cloudwatch.html
https://docs.aws.amazon.com/xray/latest/devguide/xray-sdk-java-filters.html
https://docs.aws.amazon.com/xray/latest/devguide/xray-sdk-java-sqlclients.html
Explanation
Correct options:
Configure the Aurora MySQL DB cluster to publish slow query and error logs to Amazon CloudWatch Logs
You can configure your Aurora MySQL DB cluster to publish general, slow, audit, and error log data to a log group in Amazon CloudWatch Logs. With CloudWatch Logs, you can perform real-time analysis of the log data, and use CloudWatch to create alarms and view metrics. You can use CloudWatch Logs to store your log records in highly durable storage.
To publish logs to CloudWatch Logs, the respective logs must be enabled. Error logs are enabled by default, but you must enable the other types of logs explicitly. The slow query logs and error logs can be used to identify the root cause behind the given issue.
Install and configure an Amazon CloudWatch Logs agent on the EC2 instances to send the application logs to CloudWatch Logs
You can collect metrics and logs from Amazon EC2 instances and on-premises servers with the CloudWatch agent. The unified CloudWatch agent enables you to collect internal system-level metrics from Amazon EC2 instances across operating systems. The metrics can include in-guest metrics, in addition to the metrics for EC2 instances. You can collect logs from Amazon EC2 instances and on-premises servers, running either Linux or Windows Server. The application logs (via the CloudWatch logs) can be used to identify the root cause behind the given issue.
Set up the AWS X-Ray SDK to trace incoming HTTP requests on the EC2 instances as well as set up tracing of SQL queries with the X-Ray SDK for Java
You can use the X-Ray SDK to trace incoming HTTP requests that your application serves on an EC2 instance. Use a Filter to instrument incoming HTTP requests. When you add the X-Ray servlet filter to your application, the X-Ray SDK for Java creates a segment for each sampled request. This segment includes timing, method, and disposition of the HTTP request. You can also instrument your SQL database queries by adding the X-Ray SDK for Java JDBC interceptor to your data source configuration. X-Ray tracing for the HTTP requests as well as the SQL queries can help in identifying the root cause behind the given issue.
Incorrect options:
Use CloudTrail and configure a trail to deliver Amazon Aurora query activity to an Amazon S3 bucket. Process and analyze these real-time log streams using Amazon Kinesis Data Streams - You can use CloudTrail to view, search, download, archive, analyze, and respond to account activity across your AWS infrastructure. You can identify who or what took which action, what resources were acted upon, when the event occurred, and other details to help you analyze and respond to activity in your AWS account. CloudTrail provides a record of actions taken by a user, role, or AWS service in Amazon Aurora. However, CloudTrail does not capture any query activity in Aurora, so this option is incorrect.
Enable detailed monitoring for Amazon EC2 instances to send data points to CloudWatch every minute. Track the metric 'CPUUtilization' to know when the auto-scaling process can kick in - Tracking the 'CPUUtilization' parameter is irrelevant to the given use case as it would not point to the root cause behind the given issue.
Enable Aurora lab mode which will then publish all logs and activity on Aurora DB to CloudWatch logs - Aurora lab mode is used to enable Aurora features that are available in the current Aurora database version but are not enabled by default. These features are tested in development/test environments. Aurora lab mode is not relevant for capturing the log activity of Aurora DB. This option has been added as a distractor.
References:
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/Install-CloudWatch-Agent.html
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Integrating.CloudWatch.html
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/viewing_metrics_with_cloudwatch.html
https://docs.aws.amazon.com/xray/latest/devguide/xray-sdk-java-filters.html
https://docs.aws.amazon.com/xray/latest/devguide/xray-sdk-java-sqlclients.html
Question 9 Single Choice
A financial services company wants to set up an AWS WAF-based solution to manage AWS WAF rules across multiple AWS accounts that are structured under different Organization Units (OUs) in AWS Organizations. The solution should automatically update and remediate noncompliant AWS WAF rules in all accounts. The solution should also facilitate adding or removing accounts or OUs from managed AWS WAF rule sets as needed.
Which of the following solutions is the most operationally efficient to address the given use case?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Create an AWS Organizations organization-wide AWS Config rule that mandates all resources in the selected OUs to be associated with the AWS WAF rules. Configure automated remediation actions by using AWS Systems Manager Automation documents to fix non-compliant resources. Set up AWS WAF rules by using an AWS CloudFormation stack set to target the same OUs where the AWS Config rule is applied
AWS Config allows you to manage AWS Config rules across all AWS accounts within an organization. You can:
Centrally create, update, and delete AWS Config rules across all accounts in your organization.
Deploy a common set of AWS Config rules across all accounts and specify accounts where AWS Config rules should not be created.
Use the APIs from the management account in AWS Organizations to enforce governance by ensuring that the underlying AWS Config rules are not modifiable by your organization’s member accounts.
If a new account joins an organization, the rule or conformance pack is deployed to that account. When an account leaves an organization, the rule or conformance pack is removed.
 via - https://docs.aws.amazon.com/config/latest/developerguide/config-rule-multi-account-deployment.html
via - https://docs.aws.amazon.com/config/latest/developerguide/config-rule-multi-account-deployment.html
AWS Config allows you to remediate noncompliant resources that are evaluated by AWS Config Rules. AWS Config applies remediation using AWS Systems Manager Automation documents. These documents define the actions to be performed on noncompliant AWS resources evaluated by AWS Config Rules. You can associate SSM documents by using AWS Management Console or by using APIs. To apply remediation on non-compliant resources, you can either choose the remediation action you want to associate from a prepopulated list or create your own custom remediation actions using SSM documents. AWS Config provides a recommended list of remediation actions in the AWS Management Console.
AWS CloudFormation StackSets extends the capability of CloudFormation stacks by enabling you to create, update, or delete stacks across multiple accounts and AWS Regions with a single operation. Using an administrator account, you define and manage an AWS CloudFormation template, and use the template as the basis for provisioning stacks into selected target accounts across specified AWS Regions.
Incorrect options:
Use AWS Firewall Manager to manage AWS WAF rules across accounts in the organization. Leverage AWS Systems Manager Parameter Store to store account numbers and OUs. Update AWS Systems Manager Parameter Store as needed to add or remove accounts or OUs. Create cross-account IAM roles in member accounts with permissions to create and update AWS WAF rules. Create a Lambda function to assume IAM roles in the management account to create and update AWS WAF rules in the member accounts - This option involves significant manual work every time an account is added/removed from the organization. You need to update the items in Systems Manager Parameter Store and further update the Lambda to assume the role for the new account. Hence this option is incorrect.
Use AWS Control Tower to manage AWS WAF rules across accounts in the organization. Leverage AWS Secrets Manager to store account numbers and OUs. Update AWS Secrets Manager as needed to add or remove accounts or OUs. Create cross-account IAM roles in member accounts with permissions to create and update AWS WAF rules. Create a Lambda function to assume IAM roles in the management account to create and update AWS WAF rules in the member accounts - This option involves significant manual work every time an account is added/removed from the organization. You need to update the items in Secrets Manager and further update the Lambda to assume the role for the new account. Hence this option is incorrect.
Use AWS Security Hub to manage AWS WAF rules across accounts in the organization. Leverage AWS KMS to store account numbers and OUs. Update AWS KMS as needed to add or remove accounts or OUs. Create IAM users in member accounts. Allow AWS Firewall Manager in the management account to use the access key and secret access key to create and update AWS WAF rules in the member accounts - This option has been added as a distractor. You cannot use AWS Security Hub to manage AWS WAF rules across accounts in the organization, rather you need to use AWS Firewall Manager to accomplish this. AWS KMS is a managed service that helps you more easily create and control the keys used for cryptographic operations. The service provides a highly available key generation, storage, management, and auditing solution for you to encrypt or digitally sign data within your own applications or control the encryption of data across AWS services. You cannot use AWS KMS to store account numbers and OUs.
References:
https://docs.aws.amazon.com/config/latest/developerguide/config-rule-multi-account-deployment.html
https://docs.aws.amazon.com/config/latest/developerguide/remediation.html
https://aws.amazon.com/premiumsupport/knowledge-center/lambda-function-assume-iam-role/
Explanation
Correct option:
Create an AWS Organizations organization-wide AWS Config rule that mandates all resources in the selected OUs to be associated with the AWS WAF rules. Configure automated remediation actions by using AWS Systems Manager Automation documents to fix non-compliant resources. Set up AWS WAF rules by using an AWS CloudFormation stack set to target the same OUs where the AWS Config rule is applied
AWS Config allows you to manage AWS Config rules across all AWS accounts within an organization. You can:
Centrally create, update, and delete AWS Config rules across all accounts in your organization.
Deploy a common set of AWS Config rules across all accounts and specify accounts where AWS Config rules should not be created.
Use the APIs from the management account in AWS Organizations to enforce governance by ensuring that the underlying AWS Config rules are not modifiable by your organization’s member accounts.
If a new account joins an organization, the rule or conformance pack is deployed to that account. When an account leaves an organization, the rule or conformance pack is removed.
via - https://docs.aws.amazon.com/config/latest/developerguide/config-rule-multi-account-deployment.html
AWS Config allows you to remediate noncompliant resources that are evaluated by AWS Config Rules. AWS Config applies remediation using AWS Systems Manager Automation documents. These documents define the actions to be performed on noncompliant AWS resources evaluated by AWS Config Rules. You can associate SSM documents by using AWS Management Console or by using APIs. To apply remediation on non-compliant resources, you can either choose the remediation action you want to associate from a prepopulated list or create your own custom remediation actions using SSM documents. AWS Config provides a recommended list of remediation actions in the AWS Management Console.
AWS CloudFormation StackSets extends the capability of CloudFormation stacks by enabling you to create, update, or delete stacks across multiple accounts and AWS Regions with a single operation. Using an administrator account, you define and manage an AWS CloudFormation template, and use the template as the basis for provisioning stacks into selected target accounts across specified AWS Regions.
Incorrect options:
Use AWS Firewall Manager to manage AWS WAF rules across accounts in the organization. Leverage AWS Systems Manager Parameter Store to store account numbers and OUs. Update AWS Systems Manager Parameter Store as needed to add or remove accounts or OUs. Create cross-account IAM roles in member accounts with permissions to create and update AWS WAF rules. Create a Lambda function to assume IAM roles in the management account to create and update AWS WAF rules in the member accounts - This option involves significant manual work every time an account is added/removed from the organization. You need to update the items in Systems Manager Parameter Store and further update the Lambda to assume the role for the new account. Hence this option is incorrect.
Use AWS Control Tower to manage AWS WAF rules across accounts in the organization. Leverage AWS Secrets Manager to store account numbers and OUs. Update AWS Secrets Manager as needed to add or remove accounts or OUs. Create cross-account IAM roles in member accounts with permissions to create and update AWS WAF rules. Create a Lambda function to assume IAM roles in the management account to create and update AWS WAF rules in the member accounts - This option involves significant manual work every time an account is added/removed from the organization. You need to update the items in Secrets Manager and further update the Lambda to assume the role for the new account. Hence this option is incorrect.
Use AWS Security Hub to manage AWS WAF rules across accounts in the organization. Leverage AWS KMS to store account numbers and OUs. Update AWS KMS as needed to add or remove accounts or OUs. Create IAM users in member accounts. Allow AWS Firewall Manager in the management account to use the access key and secret access key to create and update AWS WAF rules in the member accounts - This option has been added as a distractor. You cannot use AWS Security Hub to manage AWS WAF rules across accounts in the organization, rather you need to use AWS Firewall Manager to accomplish this. AWS KMS is a managed service that helps you more easily create and control the keys used for cryptographic operations. The service provides a highly available key generation, storage, management, and auditing solution for you to encrypt or digitally sign data within your own applications or control the encryption of data across AWS services. You cannot use AWS KMS to store account numbers and OUs.
References:
https://docs.aws.amazon.com/config/latest/developerguide/config-rule-multi-account-deployment.html
https://docs.aws.amazon.com/config/latest/developerguide/remediation.html
https://aws.amazon.com/premiumsupport/knowledge-center/lambda-function-assume-iam-role/
Question 10 Multiple Choice
A retail company is introducing multiple business units as part of its expansion plans. To implement this change, the company will be building several new business-unit-specific workloads by leveraging a variety of AWS services. The company wants to track the expenses of each business unit and limit the spending to a pre-defined threshold. In addition, the solution should allow the security team to identify and respond to threats as quickly as possible for all the workloads across the business units. Also, workload accounts may need to be pulled off into a temporary holding area due to resource audit reasons.
Which of the following can be combined to build a solution for the given requirements? (Select three)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Use AWS Organizations to set up a multi-account environment. Organize the accounts into the following Organizational Units (OUs): Security, Infrastructure, Workloads, Suspended and Exceptions - AWS categorizes the Security OU and the Infrastructure OU as foundational. The foundational OUs contain accounts, workloads, and other AWS resources that provide common security and infrastructure capabilities to secure and support your overall AWS environment.
The Suspended OU is used as a temporary holding area for accounts that are required to have their use suspended either temporarily or permanently.
The Exceptions OU houses an account that requires an exception to the security policies that are applied to your Workloads OU.
AWS recommended OUs and accounts:  via - https://docs.aws.amazon.com/whitepapers/latest/organizing-your-aws-environment/recommended-ous-and-accounts.html
via - https://docs.aws.amazon.com/whitepapers/latest/organizing-your-aws-environment/recommended-ous-and-accounts.html
Configure an AWS Budget alert to move an AWS account to Exceptions OU if the account reaches a predefined budget threshold. Use Service Control Policies (SCPs) to limit/block resource usage in the Exceptions OU. Configure a Suspended OU to hold workload accounts with retired resources. Use Service Control Policies (SCPs) to limit/block resource usage in the Suspended OU - AWS Budgets provides the capability to configure cost-saving controls, or actions, that run either automatically on your behalf or by using a workflow approval process. You can use actions to define an explicit response that you want to take when a budget exceeds its action threshold. You can trigger these alerts on actual or forecasted cost and usage budgets.
For the given scenario, the management account can move the member account to restrictive OU (Exceptions OU) after the budget threshold for the member account is met.
Using AWS Budgets actions to move an AWS account to an OU:  via - https://aws.amazon.com/blogs/mt/manage-cost-overruns-part-1/
via - https://aws.amazon.com/blogs/mt/manage-cost-overruns-part-1/
Designate an account within the AWS Organizations organization to be the GuardDuty delegated administrator. Create an SNS topic in this account. Subscribe the security team to the topic so that the security team can receive alerts from GuardDuty via SNS
When you use GuardDuty with an AWS Organizations organization, you can designate any account within the organization to be the GuardDuty delegated administrator. Only the organization management account can designate GuardDuty delegated administrators.
An account that is designated as a delegated administrator becomes a GuardDuty administrator account, has GuardDuty automatically enabled in the designated Region and is granted permission to enable and manage GuardDuty for all accounts in the organization within that Region. The other accounts in the organization can be viewed and added as GuardDuty member accounts associated with the delegated administrator account.
For the given use case, you can set up an SNS topic in this account and then subscribe the security team to the topic so that the security team can receive alerts from GuardDuty.
Incorrect options:
Use AWS Organizations to set up a multi-account environment. Organize the accounts into the following Service Control Policies (SCPs): Security, Infrastructure, Workloads, Suspended, and Exceptions. Grant necessary permissions to the accounts by using the SCP guardrails - Service control policies (SCPs) are a type of organization policy that you can use to manage permissions in your organization. SCPs offer central control over the maximum available permissions for all accounts in your organization. SCPs alone are not sufficient to grant permissions to the accounts in your organization. No permissions are granted by an SCP. You cannot organize AWS accounts into Service Control Policies (SCPs). You organize AWS accounts into Organization Units by using AWS Organizations.
Configure an AWS Cost Explorer alert to move an AWS account to Exceptions OU if the account reaches a predefined budget threshold. Use Service Control Policies (SCPs) to limit/block resource usage in the Exceptions OU. Configure a Suspended OU to hold workload accounts with retired resources. Use Service Control Policies (SCPs) to limit/block resource usage in the Suspended OU - AWS Cost Explorer lets you explore your AWS costs and usage at both a high level and at a detailed level of analysis, empowering you to dive deeper using several filtering dimensions (e.g., AWS Service, Region, Member Account, etc.). It is not possible to define actionable alerts in AWS Cost Explorer.
Configure GuardDuty in all member accounts within the AWS Organizations organization. Create an SNS topic in each account. Subscribe the security team to the topic so that the security team can receive alerts from GuardDuty via SNS - It is inefficient and cumbersome to configure GuardDuty in all member accounts within the AWS Organizations organization. It's better to centrally manage GuardDuty for all AWS accounts by using a GuardDuty delegated administrator account within the AWS Organizations organization.
References:
https://docs.aws.amazon.com/whitepapers/latest/organizing-your-aws-environment/suspended-ou.html
https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_scps.html
https://docs.aws.amazon.com/guardduty/latest/ug/guardduty_organizations.html
Explanation
Correct options:
Use AWS Organizations to set up a multi-account environment. Organize the accounts into the following Organizational Units (OUs): Security, Infrastructure, Workloads, Suspended and Exceptions - AWS categorizes the Security OU and the Infrastructure OU as foundational. The foundational OUs contain accounts, workloads, and other AWS resources that provide common security and infrastructure capabilities to secure and support your overall AWS environment.
The Suspended OU is used as a temporary holding area for accounts that are required to have their use suspended either temporarily or permanently.
The Exceptions OU houses an account that requires an exception to the security policies that are applied to your Workloads OU.
AWS recommended OUs and accounts: via - https://docs.aws.amazon.com/whitepapers/latest/organizing-your-aws-environment/recommended-ous-and-accounts.html
Configure an AWS Budget alert to move an AWS account to Exceptions OU if the account reaches a predefined budget threshold. Use Service Control Policies (SCPs) to limit/block resource usage in the Exceptions OU. Configure a Suspended OU to hold workload accounts with retired resources. Use Service Control Policies (SCPs) to limit/block resource usage in the Suspended OU - AWS Budgets provides the capability to configure cost-saving controls, or actions, that run either automatically on your behalf or by using a workflow approval process. You can use actions to define an explicit response that you want to take when a budget exceeds its action threshold. You can trigger these alerts on actual or forecasted cost and usage budgets.
For the given scenario, the management account can move the member account to restrictive OU (Exceptions OU) after the budget threshold for the member account is met.
Using AWS Budgets actions to move an AWS account to an OU: via - https://aws.amazon.com/blogs/mt/manage-cost-overruns-part-1/
Designate an account within the AWS Organizations organization to be the GuardDuty delegated administrator. Create an SNS topic in this account. Subscribe the security team to the topic so that the security team can receive alerts from GuardDuty via SNS
When you use GuardDuty with an AWS Organizations organization, you can designate any account within the organization to be the GuardDuty delegated administrator. Only the organization management account can designate GuardDuty delegated administrators.
An account that is designated as a delegated administrator becomes a GuardDuty administrator account, has GuardDuty automatically enabled in the designated Region and is granted permission to enable and manage GuardDuty for all accounts in the organization within that Region. The other accounts in the organization can be viewed and added as GuardDuty member accounts associated with the delegated administrator account.
For the given use case, you can set up an SNS topic in this account and then subscribe the security team to the topic so that the security team can receive alerts from GuardDuty.
Incorrect options:
Use AWS Organizations to set up a multi-account environment. Organize the accounts into the following Service Control Policies (SCPs): Security, Infrastructure, Workloads, Suspended, and Exceptions. Grant necessary permissions to the accounts by using the SCP guardrails - Service control policies (SCPs) are a type of organization policy that you can use to manage permissions in your organization. SCPs offer central control over the maximum available permissions for all accounts in your organization. SCPs alone are not sufficient to grant permissions to the accounts in your organization. No permissions are granted by an SCP. You cannot organize AWS accounts into Service Control Policies (SCPs). You organize AWS accounts into Organization Units by using AWS Organizations.
Configure an AWS Cost Explorer alert to move an AWS account to Exceptions OU if the account reaches a predefined budget threshold. Use Service Control Policies (SCPs) to limit/block resource usage in the Exceptions OU. Configure a Suspended OU to hold workload accounts with retired resources. Use Service Control Policies (SCPs) to limit/block resource usage in the Suspended OU - AWS Cost Explorer lets you explore your AWS costs and usage at both a high level and at a detailed level of analysis, empowering you to dive deeper using several filtering dimensions (e.g., AWS Service, Region, Member Account, etc.). It is not possible to define actionable alerts in AWS Cost Explorer.
Configure GuardDuty in all member accounts within the AWS Organizations organization. Create an SNS topic in each account. Subscribe the security team to the topic so that the security team can receive alerts from GuardDuty via SNS - It is inefficient and cumbersome to configure GuardDuty in all member accounts within the AWS Organizations organization. It's better to centrally manage GuardDuty for all AWS accounts by using a GuardDuty delegated administrator account within the AWS Organizations organization.
References:
https://docs.aws.amazon.com/whitepapers/latest/organizing-your-aws-environment/suspended-ou.html
https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_scps.html
https://docs.aws.amazon.com/guardduty/latest/ug/guardduty_organizations.html


