
AWS Certified Solutions Architect - Professional - (SAP-C02) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 11 Single Choice
A team has recently created a secret using AWS Secrets Manager to access their private Amazon Relational Database Service (Amazon RDS) instance. When the team tried to rotate the AWS Secrets Manager secret in an Amazon Virtual Private Cloud (Amazon VPC), the operation failed. On analyzing the Amazon CloudWatch Logs, the team realized that the AWS Lambda task timed out.
Which of the following solutions needs to be implemented for rotating the secret successfully?
Explanation

Click "Show Answer" to see the explanation here
Correct option:
Configure an Amazon VPC interface endpoint to access your Secrets Manager Lambda rotation function and private Amazon Relational Database Service (Amazon RDS) instance
Secrets Manager can't rotate secrets for AWS services running in Amazon VPC private subnets because these subnets don't have internet access. To rotate the keys successfully you need to configure an Amazon VPC interface endpoint to access your Secrets Manager Lambda function and private Amazon Relational Database Service (Amazon RDS) instance.
Steps that need to be followed: 1. Create security groups for the Secrets Manager VPC endpoint, Amazon RDS instance, and the Lambda rotation function 2. Add rules to Amazon VPC endpoint and Amazon RDS instance security groups 3. Attach security groups to AWS resources 4. Create an Amazon VPC interface endpoint for the Secrets Manager service and associate it with a security group 5. Verify that the Secrets Manager can rotate the secret
Incorrect options:
Configure an Amazon VPC interface endpoint for the Lambda service to enable access for your Secrets Manager Lambda rotation function and private Amazon Relational Database Service (Amazon RDS) instance - As explained above, you need to create an Amazon VPC interface endpoint for the Secrets Manager and not for the Lambda service. This option has been added as a distractor.
Interface VPC endpoints support traffic only over HTTP. If this is incorrectly configured, the AWS Lambda function can timeout - This statement is incorrect. Interface VPC endpoints support traffic only over TCP.
Your Lambda rotation function might be based on an older template that doesn't support SSL/TLS. To support connections that use SSL/TLS, you must recreate your Lambda rotation function - Rotation functions for Amazon RDS (except Amazon RDS for Oracle) and Amazon DocumentDB automatically use SSL/TLS to connect to your database if it's available. If you set up secret rotation before December 20, 2021, then your rotation function might be based on an older template that doesn't support SSL/TLS. To support connections that use SSL/TLS, you must recreate your rotation function. If this is the issue then the following error crops up ": setSecret: Unable to log into the database with previous, current, or the pending secret of secret".
References:
https://aws.amazon.com/premiumsupport/knowledge-center/rotate-secrets-manager-secret-vpc/
https://aws.amazon.com/premiumsupport/knowledge-center/rotate-secret-db-ssl/
Explanation
Correct option:
Configure an Amazon VPC interface endpoint to access your Secrets Manager Lambda rotation function and private Amazon Relational Database Service (Amazon RDS) instance
Secrets Manager can't rotate secrets for AWS services running in Amazon VPC private subnets because these subnets don't have internet access. To rotate the keys successfully you need to configure an Amazon VPC interface endpoint to access your Secrets Manager Lambda function and private Amazon Relational Database Service (Amazon RDS) instance.
Steps that need to be followed: 1. Create security groups for the Secrets Manager VPC endpoint, Amazon RDS instance, and the Lambda rotation function 2. Add rules to Amazon VPC endpoint and Amazon RDS instance security groups 3. Attach security groups to AWS resources 4. Create an Amazon VPC interface endpoint for the Secrets Manager service and associate it with a security group 5. Verify that the Secrets Manager can rotate the secret
Incorrect options:
Configure an Amazon VPC interface endpoint for the Lambda service to enable access for your Secrets Manager Lambda rotation function and private Amazon Relational Database Service (Amazon RDS) instance - As explained above, you need to create an Amazon VPC interface endpoint for the Secrets Manager and not for the Lambda service. This option has been added as a distractor.
Interface VPC endpoints support traffic only over HTTP. If this is incorrectly configured, the AWS Lambda function can timeout - This statement is incorrect. Interface VPC endpoints support traffic only over TCP.
Your Lambda rotation function might be based on an older template that doesn't support SSL/TLS. To support connections that use SSL/TLS, you must recreate your Lambda rotation function - Rotation functions for Amazon RDS (except Amazon RDS for Oracle) and Amazon DocumentDB automatically use SSL/TLS to connect to your database if it's available. If you set up secret rotation before December 20, 2021, then your rotation function might be based on an older template that doesn't support SSL/TLS. To support connections that use SSL/TLS, you must recreate your rotation function. If this is the issue then the following error crops up ": setSecret: Unable to log into the database with previous, current, or the pending secret of secret".
References:
https://aws.amazon.com/premiumsupport/knowledge-center/rotate-secrets-manager-secret-vpc/
https://aws.amazon.com/premiumsupport/knowledge-center/rotate-secret-db-ssl/
Question 12 Single Choice
A company has its flagship application fronted by an Application Load Balancer that is targeting several EC2 Linux instances running in an Auto Scaling group in a private subnet. AWS Systems Manager Agent is installed on all the EC2 instances. The company recently released a new version of the application, however, some of the EC2 instances are now being marked as unhealthy and are being terminated, thereby causing the application to run at reduced capacity. You have been tasked to ascertain the root cause by analyzing Amazon CloudWatch logs that are collected from the application, but you find that the logs are inconclusive.
Which of the following options would you propose to get access to an EC2 instance to troubleshoot the issue?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Suspend the Auto Scaling group's Terminate process. Use Session Manager to log in to an instance that is marked as unhealthy and analyze the system logs to figure out the root cause
The Terminate process removes instances from the Auto Scaling group when the group scales in, or when Amazon EC2 Auto Scaling chooses to terminate instances for other reasons, such as when an instance is terminated for exceeding its maximum lifetime duration or failing a health check. You need to suspend the Terminate process which will allow you to get access to the instance without it being terminated even if it is marked as unhealthy. You should note that another way to prevent Amazon EC2 Auto Scaling from terminating unhealthy instances, is to suspend the ReplaceUnhealthy process. You can then leverage the Session Manager to log in to the instance that is marked as unhealthy and analyze the system logs to figure out the root cause.
 via -
via -  via -
via - Incorrect options:
Suspend the Auto Scaling group's HealthCheck process. Use EC2 instance connect to log in to an instance that is marked as unhealthy and analyze the system logs to figure out the root cause - The HealthCheck process checks the health of the instances and marks an instance as unhealthy if Amazon EC2 or Elastic Load Balancing tells Amazon EC2 Auto Scaling that the instance is unhealthy. This process can override the health status of an instance that you set manually. If you suspend the HealthCheck process, then none of the instances would be marked as unhealthy. Therefore, you cannot suspend the HealthCheck process for the given use case, since you must identify the root cause behind some of the instances being marked as unhealthy.
Suspend the Auto Scaling group's Launch process. Use Session Manager to log in to an instance that is marked as unhealthy and analyze the system logs to figure out the root cause - The Launch process adds instances to the Auto Scaling group when the group scales out, or when Amazon EC2 Auto Scaling chooses to launch instances for other reasons, such as when it adds instances to a warm pool. Suspending the Launch process will not help in identifying the root cause behind some instances being marked as unhealthy as those instances would still be terminated.
Enable EC2 instance termination protection. Use Session Manager to log In to an instance that is marked as unhealthy and analyze the system logs to figure out the root cause - Enabling EC2 instance termination (DisableApiTermination attribute) does not prevent Amazon EC2 Auto Scaling from terminating an instance.
References:
https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-suspend-resume-processes.html
Explanation
Correct option:
Suspend the Auto Scaling group's Terminate process. Use Session Manager to log in to an instance that is marked as unhealthy and analyze the system logs to figure out the root cause
The Terminate process removes instances from the Auto Scaling group when the group scales in, or when Amazon EC2 Auto Scaling chooses to terminate instances for other reasons, such as when an instance is terminated for exceeding its maximum lifetime duration or failing a health check. You need to suspend the Terminate process which will allow you to get access to the instance without it being terminated even if it is marked as unhealthy. You should note that another way to prevent Amazon EC2 Auto Scaling from terminating unhealthy instances, is to suspend the ReplaceUnhealthy process. You can then leverage the Session Manager to log in to the instance that is marked as unhealthy and analyze the system logs to figure out the root cause.
Incorrect options:
Suspend the Auto Scaling group's HealthCheck process. Use EC2 instance connect to log in to an instance that is marked as unhealthy and analyze the system logs to figure out the root cause - The HealthCheck process checks the health of the instances and marks an instance as unhealthy if Amazon EC2 or Elastic Load Balancing tells Amazon EC2 Auto Scaling that the instance is unhealthy. This process can override the health status of an instance that you set manually. If you suspend the HealthCheck process, then none of the instances would be marked as unhealthy. Therefore, you cannot suspend the HealthCheck process for the given use case, since you must identify the root cause behind some of the instances being marked as unhealthy.
Suspend the Auto Scaling group's Launch process. Use Session Manager to log in to an instance that is marked as unhealthy and analyze the system logs to figure out the root cause - The Launch process adds instances to the Auto Scaling group when the group scales out, or when Amazon EC2 Auto Scaling chooses to launch instances for other reasons, such as when it adds instances to a warm pool. Suspending the Launch process will not help in identifying the root cause behind some instances being marked as unhealthy as those instances would still be terminated.
Enable EC2 instance termination protection. Use Session Manager to log In to an instance that is marked as unhealthy and analyze the system logs to figure out the root cause - Enabling EC2 instance termination (DisableApiTermination attribute) does not prevent Amazon EC2 Auto Scaling from terminating an instance.
References:
https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-suspend-resume-processes.html
Question 13 Single Choice
A company is migrating its two-tier legacy application (using MongoDB as a key-value database) from its on-premises data center to AWS. The company has mandated that the EC2 instances must be hosted in a private subnet with no internet access. In addition, all connectivity between the EC2 instance-hosted application and the database must be encrypted. The database must be able to scale to meet traffic spikes from any bursty or unpredictable workloads.
Which do you recommend?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Set up new Amazon DynamoDB tables for the application with on-demand capacity. Use a gateway VPC endpoint for DynamoDB so that the application can have a private and encrypted connection to the DynamoDB tables
With provisioned capacity, you pay for the provision of read and write capacity units for your DynamoDB tables. Whereas with DynamoDB on-demand you pay per request for the data reads and writes that your application performs on your tables.
With on-demand capacity mode, DynamoDB charges you for the data reads and writes your application performs on your tables. You do not need to specify how much read and write throughput you expect your application to perform because DynamoDB instantly accommodates your workloads as they ramp up or down.
With provisioned capacity mode, you specify the number of reads and writes per second that you expect your application to require, and you are billed based on that. Furthermore, if you can forecast your capacity requirements you can also reserve a portion of DynamoDB provisioned capacity and optimize your costs even further. With provisioned capacity, you can also use auto-scaling to automatically adjust your table’s capacity based on the specified utilization rate to ensure application performance, and also potentially reduce costs. To configure auto-scaling in DynamoDB, set the minimum and maximum levels of read and write capacity in addition to the target utilization percentage.
It is important to note that DynamoDB auto scaling modifies provisioned throughput settings only when the actual workload stays elevated or depressed for a sustained period of several minutes. This applies to scaling up or down the provisioned capacity of a DynamoDB table. In the case that you have an occasional usage spike, auto-scaling might not be able to react in time. This sometimes can be mitigated by DynamoDB burst capacity where DynamoDB reserves a portion of the unused provisioned capacity for later bursts of throughput. The burst capacity is limited though and these extra capacity units can be consumed quickly.
This means that provisioned capacity is probably best for you if you have relatively predictable application traffic, run applications whose traffic is consistent, and ramps up or down gradually.
Whereas on-demand capacity mode is probably best when you have new tables with unknown workloads, unpredictable application traffic, and also if you only want to pay exactly for what you use. The on-demand pricing model is ideal for bursty, new, or unpredictable workloads whose traffic can spike in seconds or minutes, and when under-provisioned capacity would impact the user experience.
Incorrect options:
Set up a new Amazon DocumentDB (with MongoDB compatibility) cluster for the application with provisioned capacity with auto-scaling enabled. Use an interface VPC endpoint for DocumentDB so that the application can have a private and encrypted connection to the DocumentDB tables
Set up a new Amazon DocumentDB (with MongoDB compatibility) cluster for the application with on-demand capacity. Use a gateway VPC endpoint for DocumentDB so that the application can have a private and encrypted connection to the DocumentDB tables
Amazon DocumentDB (with MongoDB compatibility) clusters are deployed within an Amazon Virtual Private Cloud (Amazon VPC). They can be accessed directly by Amazon EC2 instances or other AWS services that are deployed in the same Amazon VPC. Additionally, Amazon DocumentDB can be accessed by EC2 instances or other AWS services in different VPCs in the same AWS Region or other Regions via VPC peering. Therefore, neither the interface nor gateway VPC endpoint is supported for DocumentDB. So both these options are incorrect.
Set up new Amazon DynamoDB tables for the application with on-demand capacity. Use an interface VPC endpoint for DynamoDB so that the application can have a private and encrypted connection to the DynamoDB tables - Only gateway VPC endpoint is supported for DynamoDB, so this option is incorrect.
References:
https://docs.aws.amazon.com/wellarchitected/latest/serverless-applications-lens/capacity.html
https://docs.aws.amazon.com/documentdb/latest/developerguide/connect-from-outside-a-vpc.html
Explanation
Correct option:
Set up new Amazon DynamoDB tables for the application with on-demand capacity. Use a gateway VPC endpoint for DynamoDB so that the application can have a private and encrypted connection to the DynamoDB tables
With provisioned capacity, you pay for the provision of read and write capacity units for your DynamoDB tables. Whereas with DynamoDB on-demand you pay per request for the data reads and writes that your application performs on your tables.
With on-demand capacity mode, DynamoDB charges you for the data reads and writes your application performs on your tables. You do not need to specify how much read and write throughput you expect your application to perform because DynamoDB instantly accommodates your workloads as they ramp up or down.
With provisioned capacity mode, you specify the number of reads and writes per second that you expect your application to require, and you are billed based on that. Furthermore, if you can forecast your capacity requirements you can also reserve a portion of DynamoDB provisioned capacity and optimize your costs even further. With provisioned capacity, you can also use auto-scaling to automatically adjust your table’s capacity based on the specified utilization rate to ensure application performance, and also potentially reduce costs. To configure auto-scaling in DynamoDB, set the minimum and maximum levels of read and write capacity in addition to the target utilization percentage.
It is important to note that DynamoDB auto scaling modifies provisioned throughput settings only when the actual workload stays elevated or depressed for a sustained period of several minutes. This applies to scaling up or down the provisioned capacity of a DynamoDB table. In the case that you have an occasional usage spike, auto-scaling might not be able to react in time. This sometimes can be mitigated by DynamoDB burst capacity where DynamoDB reserves a portion of the unused provisioned capacity for later bursts of throughput. The burst capacity is limited though and these extra capacity units can be consumed quickly.
This means that provisioned capacity is probably best for you if you have relatively predictable application traffic, run applications whose traffic is consistent, and ramps up or down gradually.
Whereas on-demand capacity mode is probably best when you have new tables with unknown workloads, unpredictable application traffic, and also if you only want to pay exactly for what you use. The on-demand pricing model is ideal for bursty, new, or unpredictable workloads whose traffic can spike in seconds or minutes, and when under-provisioned capacity would impact the user experience.
Incorrect options:
Set up a new Amazon DocumentDB (with MongoDB compatibility) cluster for the application with provisioned capacity with auto-scaling enabled. Use an interface VPC endpoint for DocumentDB so that the application can have a private and encrypted connection to the DocumentDB tables
Set up a new Amazon DocumentDB (with MongoDB compatibility) cluster for the application with on-demand capacity. Use a gateway VPC endpoint for DocumentDB so that the application can have a private and encrypted connection to the DocumentDB tables
Amazon DocumentDB (with MongoDB compatibility) clusters are deployed within an Amazon Virtual Private Cloud (Amazon VPC). They can be accessed directly by Amazon EC2 instances or other AWS services that are deployed in the same Amazon VPC. Additionally, Amazon DocumentDB can be accessed by EC2 instances or other AWS services in different VPCs in the same AWS Region or other Regions via VPC peering. Therefore, neither the interface nor gateway VPC endpoint is supported for DocumentDB. So both these options are incorrect.
Set up new Amazon DynamoDB tables for the application with on-demand capacity. Use an interface VPC endpoint for DynamoDB so that the application can have a private and encrypted connection to the DynamoDB tables - Only gateway VPC endpoint is supported for DynamoDB, so this option is incorrect.
References:
https://docs.aws.amazon.com/wellarchitected/latest/serverless-applications-lens/capacity.html
https://docs.aws.amazon.com/documentdb/latest/developerguide/connect-from-outside-a-vpc.html
Question 14 Single Choice
A team uses an Amazon S3 bucket to store the client data. After updating the S3 bucket with a few file deletes and some new file additions, the team has just realized that these changes have not been propagated to the AWS Storage Gateway file share.
What is the underlying issue? Which method can be used to resolve it?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Storage Gateway doesn't automatically update the cache when you upload a file directly to Amazon S3. Perform a RefreshCache operation to see the changes on the file share
Storage Gateway updates the file share cache automatically when you write files to the cache locally using the file share. However, Storage Gateway doesn't automatically update the cache when you upload a file directly to Amazon S3. When you do this, you must perform a RefreshCache operation to see the changes on the file share. If you have more than one file share, then you must run the RefreshCache operation on each file share.
You can refresh the cache using the Storage Gateway console and the AWS Command Line Interface (AWS CLI).
Incorrect options:
Uploading files from your file gateway to Amazon S3 when S3 Versioning is enabled results in cache update issues. Disable versioning on the S3 bucket - Carefully consider the use of S3 Versioning and Cross-Region Replication (CRR) in Amazon S3 when you're uploading data from your file gateway. Uploading files from your file gateway to Amazon S3 when S3 Versioning is enabled results in at least two versions of an S3 object. This option is not relevant to the given issue and has just been added as a distractor.
Storage Gateway doesn't automatically update the cache when you upload a file directly to Amazon S3. Perform a ResetCache operation to see the changes on the file share - 'ResetCache', resets all cache disks that have encountered an error, and make the disks available for reconfiguration as cache storage. When a cache is reset, the gateway loses its cache storage. At this point, you can reconfigure the disks as cache disks. This operation is only supported in the cached volume and tape gateway types.
Configure correct permissions in Amazon S3 bucket policy to allow automatic refresh of cache - This statement is incorrect and has just been added as a distractor.
References:
https://docs.aws.amazon.com/filegateway/latest/files3/GettingStartedCreateFileShare.html
https://aws.amazon.com/premiumsupport/knowledge-center/storage-gateway-s3-changes-not-showing/
https://docs.aws.amazon.com/filegateway/latest/files3/refresh-cache.html
https://docs.aws.amazon.com/storagegateway/latest/APIReference/API_RefreshCache.html
Explanation
Correct option:
Storage Gateway doesn't automatically update the cache when you upload a file directly to Amazon S3. Perform a RefreshCache operation to see the changes on the file share
Storage Gateway updates the file share cache automatically when you write files to the cache locally using the file share. However, Storage Gateway doesn't automatically update the cache when you upload a file directly to Amazon S3. When you do this, you must perform a RefreshCache operation to see the changes on the file share. If you have more than one file share, then you must run the RefreshCache operation on each file share.
You can refresh the cache using the Storage Gateway console and the AWS Command Line Interface (AWS CLI).
Incorrect options:
Uploading files from your file gateway to Amazon S3 when S3 Versioning is enabled results in cache update issues. Disable versioning on the S3 bucket - Carefully consider the use of S3 Versioning and Cross-Region Replication (CRR) in Amazon S3 when you're uploading data from your file gateway. Uploading files from your file gateway to Amazon S3 when S3 Versioning is enabled results in at least two versions of an S3 object. This option is not relevant to the given issue and has just been added as a distractor.
Storage Gateway doesn't automatically update the cache when you upload a file directly to Amazon S3. Perform a ResetCache operation to see the changes on the file share - 'ResetCache', resets all cache disks that have encountered an error, and make the disks available for reconfiguration as cache storage. When a cache is reset, the gateway loses its cache storage. At this point, you can reconfigure the disks as cache disks. This operation is only supported in the cached volume and tape gateway types.
Configure correct permissions in Amazon S3 bucket policy to allow automatic refresh of cache - This statement is incorrect and has just been added as a distractor.
References:
https://docs.aws.amazon.com/filegateway/latest/files3/GettingStartedCreateFileShare.html
https://aws.amazon.com/premiumsupport/knowledge-center/storage-gateway-s3-changes-not-showing/
https://docs.aws.amazon.com/filegateway/latest/files3/refresh-cache.html
https://docs.aws.amazon.com/storagegateway/latest/APIReference/API_RefreshCache.html
Question 15 Single Choice
An e-commerce company manages its flagship application on a load-balanced EC2 instance fleet for web hosting, database API services, and business logic. This tightly coupled architecture makes it inflexible for new feature additions while also making the architecture less scalable.
Which of the following options can be used to decouple the architecture, improve scalability and provide the ability to track the failed orders?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Configure Amazon S3 for hosting the web application while using AWS AppSync for database access services. Use Amazon Simple Queue Service (Amazon SQS) for queuing orders and AWS Lambda for business logic. Use Amazon SQS dead-letter queue for tracking and re-processing failed orders
Amazon S3 can be configured to host a web application.
AWS AppSync creates serverless GraphQL and Pub/Sub APIs that simplify application development through a single endpoint to securely query, update, or publish data. AWS AppSync creates serverless GraphQL and Pub/Sub APIs that simplify application development through a single endpoint to securely query, update, or publish data.
How AWS AppSync works: 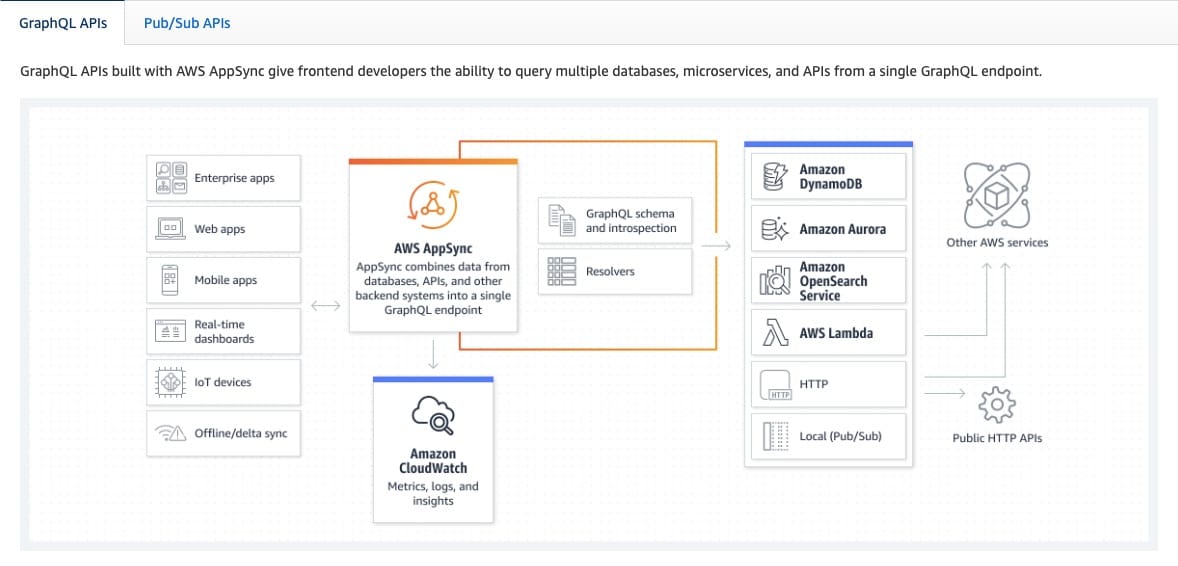 via - https://aws.amazon.com/appsync/
via - https://aws.amazon.com/appsync/
Amazon SQS supports dead-letter queues (DLQ), which other queues (source queues) can target for messages that can't be processed (consumed) successfully. Dead-letter queues are useful for debugging your application or messaging system because they let you isolate unconsumed messages to determine why their processing doesn't succeed.
SQS dead-letter queues: 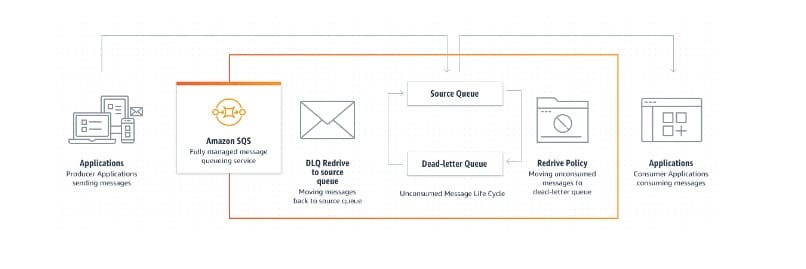 via - https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-dead-letter-queues.html
via - https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-dead-letter-queues.html
Incorrect options:
Configure Amazon CloudFront for hosting the website and Amazon API Gateway for database API services. Use Amazon Simple Queue Service (Amazon SQS) for order queuing and AWS Lambda for business logic. Use Amazon SQS long polling for retaining failed orders - You cannot use Amazon CloudFront for hosting a website as the website is hosted on the Cloudfront distribution's underlying origin (such as S3 or an EC2 instance). You cannot use Amazon SQS long polling for retaining failed orders. When the wait time for the ReceiveMessage API action is greater than 0, long polling is in effect. Long polling helps reduce the cost of using Amazon SQS by eliminating the number of empty responses and false empty responses. Long polling is a configurable parameter of SQS queues and not a temporary storage space to hold failed orders.
Use Amazon Lightsail for web hosting with AWS AppSync for database API services. Use Simple Queue Service (Amazon SQS) for order queuing. Use Amazon Elastic Container Service (Amazon ECS) for business logic and use the visibility timeout parameter of Amazon SQS to retain the failed orders - You cannot use the visibility timeout parameter of Amazon SQS to retain the failed orders. Immediately after a message is received in an SQS queue, it remains in the queue. To prevent other consumers from processing the message again, Amazon SQS sets a visibility timeout, a period during which Amazon SQS prevents other consumers from receiving and processing the message. Visibility timeout is a configurable parameter of SQS queues and not a temporary storage space to hold failed orders.
Use AWS Elastic Beanstalk for hosting the web application and Amazon API Gateway for database API services. Use Kinesis Data Streams for queuing orders and AWS Lambda to build business logic. Configure an Amazon S3 bucket for retaining failed orders on an hourly basis - Amazon Kinesis Streams allows real-time processing of streaming big data and the ability to read and replay records to multiple Amazon Kinesis Applications. Amazon SQS offers a reliable, highly-scalable hosted queue for storing messages as they travel between applications or microservices. It moves data between distributed application components and helps you decouple these components.
You should not use S3 to retain failed orders on an hourly basis. This would result in too many small objects (1 object for each failed order) on S3 which need to be written and read multiple times. In addition, it would be cumbersome to keep track of the failed orders and do the root cause analysis. You could run SQL queries via Athena on this underlying data in S3. However, it would turn out to be costly and inefficient while querying small objects via Athena. Therefore, this use case is an anti-pattern for S3.
References:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/WebsiteHosting.html
https://aws.amazon.com/appsync/
https://aws.amazon.com/sqs/faqs/
https://aws.amazon.com/blogs/big-data/top-10-performance-tuning-tips-for-amazon-athena/
https://docs.aws.amazon.com/AmazonS3/latest/userguide/optimizing-performance-design-patterns.html
Explanation
Correct option:
Configure Amazon S3 for hosting the web application while using AWS AppSync for database access services. Use Amazon Simple Queue Service (Amazon SQS) for queuing orders and AWS Lambda for business logic. Use Amazon SQS dead-letter queue for tracking and re-processing failed orders
Amazon S3 can be configured to host a web application.
AWS AppSync creates serverless GraphQL and Pub/Sub APIs that simplify application development through a single endpoint to securely query, update, or publish data. AWS AppSync creates serverless GraphQL and Pub/Sub APIs that simplify application development through a single endpoint to securely query, update, or publish data.
How AWS AppSync works: via - https://aws.amazon.com/appsync/
Amazon SQS supports dead-letter queues (DLQ), which other queues (source queues) can target for messages that can't be processed (consumed) successfully. Dead-letter queues are useful for debugging your application or messaging system because they let you isolate unconsumed messages to determine why their processing doesn't succeed.
SQS dead-letter queues: via - https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-dead-letter-queues.html
Incorrect options:
Configure Amazon CloudFront for hosting the website and Amazon API Gateway for database API services. Use Amazon Simple Queue Service (Amazon SQS) for order queuing and AWS Lambda for business logic. Use Amazon SQS long polling for retaining failed orders - You cannot use Amazon CloudFront for hosting a website as the website is hosted on the Cloudfront distribution's underlying origin (such as S3 or an EC2 instance). You cannot use Amazon SQS long polling for retaining failed orders. When the wait time for the ReceiveMessage API action is greater than 0, long polling is in effect. Long polling helps reduce the cost of using Amazon SQS by eliminating the number of empty responses and false empty responses. Long polling is a configurable parameter of SQS queues and not a temporary storage space to hold failed orders.
Use Amazon Lightsail for web hosting with AWS AppSync for database API services. Use Simple Queue Service (Amazon SQS) for order queuing. Use Amazon Elastic Container Service (Amazon ECS) for business logic and use the visibility timeout parameter of Amazon SQS to retain the failed orders - You cannot use the visibility timeout parameter of Amazon SQS to retain the failed orders. Immediately after a message is received in an SQS queue, it remains in the queue. To prevent other consumers from processing the message again, Amazon SQS sets a visibility timeout, a period during which Amazon SQS prevents other consumers from receiving and processing the message. Visibility timeout is a configurable parameter of SQS queues and not a temporary storage space to hold failed orders.
Use AWS Elastic Beanstalk for hosting the web application and Amazon API Gateway for database API services. Use Kinesis Data Streams for queuing orders and AWS Lambda to build business logic. Configure an Amazon S3 bucket for retaining failed orders on an hourly basis - Amazon Kinesis Streams allows real-time processing of streaming big data and the ability to read and replay records to multiple Amazon Kinesis Applications. Amazon SQS offers a reliable, highly-scalable hosted queue for storing messages as they travel between applications or microservices. It moves data between distributed application components and helps you decouple these components.
You should not use S3 to retain failed orders on an hourly basis. This would result in too many small objects (1 object for each failed order) on S3 which need to be written and read multiple times. In addition, it would be cumbersome to keep track of the failed orders and do the root cause analysis. You could run SQL queries via Athena on this underlying data in S3. However, it would turn out to be costly and inefficient while querying small objects via Athena. Therefore, this use case is an anti-pattern for S3.
References:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/WebsiteHosting.html
https://aws.amazon.com/appsync/
https://aws.amazon.com/sqs/faqs/
https://aws.amazon.com/blogs/big-data/top-10-performance-tuning-tips-for-amazon-athena/
https://docs.aws.amazon.com/AmazonS3/latest/userguide/optimizing-performance-design-patterns.html
Question 16 Multiple Choice
A multi-national company operates hundreds of AWS accounts and the CTO wants to rationalize the operational costs. The CTO has mandated a centralized process for purchasing new Reserved Instances (RIs) or modifying existing RIs. Whereas earlier the business units (BUs) would directly purchase or modify RIs in their own AWS accounts independently, now all BUs must be denied independent purchase and the BUs must submit requests to a dedicated central team for purchasing RIs.
As an AWS Certified Solutions Architect Professional, which of the following solutions would you combine to enforce the new process most efficiently? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Make sure that all AWS accounts are assigned organizational units (OUs) within an AWS Organizations structure operating in all features mode
AWS Organizations has two available feature sets:
All features – This feature set is the preferred way to work with AWS Organizations, and it includes Consolidating Billing features. When you create an organization, enabling all features is the default. With all features enabled, you can use the advanced account management features available in AWS Organizations such as integration with supported AWS services and organization management policies. Policies in AWS Organizations enable you to apply additional types of management to the AWS accounts in your organization. You can use policies when all features are enabled in your organization. Service control policies (SCPs) offer central control over the maximum available permissions for all of the accounts in your organization.
Consolidated Billing features – All organizations support this subset of features, which provides basic management tools that you can use to centrally manage the accounts in your organization. You cannot leverage SCPs in this feature mode.
Set up a Service Control Policy (SCP) that contains a deny rule to the ec2:PurchaseReservedInstancesOffering and ec2:ModifyReservedInstances actions. Attach the SCP to each organizational unit (OU) of the AWS Organizations structure
Service control policies (SCPs) are a type of organizational policy that you can use to manage permissions in your organization. SCPs offer central control over the maximum available permissions for all accounts in your organization. SCPs help you to ensure your accounts stay within your organization’s access control guidelines. SCPs alone are not sufficient to grant permissions to the accounts in your organization. No permissions are granted by an SCP. An SCP defines a guardrail or sets limits, on the actions that the account's administrator can delegate to the IAM users and roles in the affected accounts. The administrator must still attach identity-based or resource-based policies to IAM users or roles, or the resources in your accounts to actually grant permissions. SCPs don't affect users or roles in the management account. They affect only the member accounts in your organization.
For the given use case, you can set up an SCP that contains a deny rule to the ec2:PurchaseReservedInstancesOffering and ec2:ModifyReservedInstances actions.
Incorrect options:
Make sure that all AWS accounts are assigned organizational units (OUs) within an AWS Organizations structure operating in the consolidated billing features mode - You cannot leverage SCPs in this feature mode, so this option is incorrect.
Leverage AWS Config to notify on the attachment of an IAM policy that allows access to the ec2:PurchaseReservedInstancesOffering and ec2:ModifyReservedInstances actions - AWS Config cannot prevent the attachment of an IAM policy that allows access to the ec2:PurchaseReservedInstancesOffering and ec2:ModifyReservedInstances actions. So this option is incorrect for the given requirements.
Set up an IAM policy in each AWS account with a deny rule to the ec2:PurchaseReservedInstancesOffering and ec2:ModifyReservedInstances actions - This is a cumbersome and inefficient solution to prevent each of the member AWS accounts from purchasing the RIs. This is not the best fit solution.
References:
https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_org_support-all-features.html
https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies.html
https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_scps.html
Explanation
Correct options:
Make sure that all AWS accounts are assigned organizational units (OUs) within an AWS Organizations structure operating in all features mode
AWS Organizations has two available feature sets:
All features – This feature set is the preferred way to work with AWS Organizations, and it includes Consolidating Billing features. When you create an organization, enabling all features is the default. With all features enabled, you can use the advanced account management features available in AWS Organizations such as integration with supported AWS services and organization management policies. Policies in AWS Organizations enable you to apply additional types of management to the AWS accounts in your organization. You can use policies when all features are enabled in your organization. Service control policies (SCPs) offer central control over the maximum available permissions for all of the accounts in your organization.
Consolidated Billing features – All organizations support this subset of features, which provides basic management tools that you can use to centrally manage the accounts in your organization. You cannot leverage SCPs in this feature mode.
Set up a Service Control Policy (SCP) that contains a deny rule to the ec2:PurchaseReservedInstancesOffering and ec2:ModifyReservedInstances actions. Attach the SCP to each organizational unit (OU) of the AWS Organizations structure
Service control policies (SCPs) are a type of organizational policy that you can use to manage permissions in your organization. SCPs offer central control over the maximum available permissions for all accounts in your organization. SCPs help you to ensure your accounts stay within your organization’s access control guidelines. SCPs alone are not sufficient to grant permissions to the accounts in your organization. No permissions are granted by an SCP. An SCP defines a guardrail or sets limits, on the actions that the account's administrator can delegate to the IAM users and roles in the affected accounts. The administrator must still attach identity-based or resource-based policies to IAM users or roles, or the resources in your accounts to actually grant permissions. SCPs don't affect users or roles in the management account. They affect only the member accounts in your organization.
For the given use case, you can set up an SCP that contains a deny rule to the ec2:PurchaseReservedInstancesOffering and ec2:ModifyReservedInstances actions.
Incorrect options:
Make sure that all AWS accounts are assigned organizational units (OUs) within an AWS Organizations structure operating in the consolidated billing features mode - You cannot leverage SCPs in this feature mode, so this option is incorrect.
Leverage AWS Config to notify on the attachment of an IAM policy that allows access to the ec2:PurchaseReservedInstancesOffering and ec2:ModifyReservedInstances actions - AWS Config cannot prevent the attachment of an IAM policy that allows access to the ec2:PurchaseReservedInstancesOffering and ec2:ModifyReservedInstances actions. So this option is incorrect for the given requirements.
Set up an IAM policy in each AWS account with a deny rule to the ec2:PurchaseReservedInstancesOffering and ec2:ModifyReservedInstances actions - This is a cumbersome and inefficient solution to prevent each of the member AWS accounts from purchasing the RIs. This is not the best fit solution.
References:
https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_org_support-all-features.html
https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies.html
https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_scps.html
Question 17 Multiple Choice
The security team at a company has put forth a requirement to track the external IP address when a customer or a third party uploads files to the Amazon Simple Storage Service (Amazon S3) bucket owned by the company.
How will you track the external IP address used for each upload? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Enable Amazon S3 server access logging to capture all bucket-level and object-level events
Enable AWS CloudTrail data events to enable object-level logging for S3 bucket
To find the IP addresses for object-level requests to Amazon S3 (uploads and downloads), you must first enable one of the following logging methods:
Amazon S3 server access logging captures all bucket-level and object-level events. These logs use a format similar to Apache web server logs. After you enable server access logging, review the logs to find the IP addresses used with each upload to your bucket.
AWS CloudTrail data events capture the last 90 days of bucket-level events (for example, PutBucketPolicy and DeleteBucketPolicy), and you can enable object-level logging. These logs use a JSON format. After you enable object-level logging with data events, review the logs to find the IP addresses used with each upload to your bucket. It might take a few hours for AWS CloudTrail to start creating logs.
Incorrect options:
Enable VPC Flow Logs to capture all object-level events occurring on the S3 bucket - VPC Flow Logs is a feature that enables you to capture information about the IP traffic going to and from network interfaces in your VPC, so it does not apply to S3. Flow log data can be published to Amazon CloudWatch Logs or Amazon S3.
Enable AWS Systems Manager Agent (SSM Agent) that writes information about executions, commands, scheduled actions on all AWS resources - AWS Systems Manager Agent (SSM Agent) writes information about executions, commands, scheduled actions, errors, and health statuses to log files on each managed node. You can view log files by manually connecting to a managed node, or you can automatically send logs to Amazon CloudWatch Logs. AWS Systems Manager Agent (SSM Agent) is Amazon software that runs on Amazon Elastic Compute Cloud (Amazon EC2) instances, edge devices, and on-premises servers and virtual machines (VMs), so it does not apply to S3.
CloudWatch Logs centrally maintain the logs from all of your systems, applications, and AWS services that you use. Use these logs to capture the IP address at the object level for the S3 bucket - You can use Amazon CloudWatch Logs to monitor, store, and access your log files from Amazon Elastic Compute Cloud (Amazon EC2) instances, AWS CloudTrail, Route 53, and other sources. CloudWatch Logs enables you to see all of your logs, regardless of their source, as a single and consistent flow of events ordered by time, and you can query them and sort them based on other dimensions, group them by specific fields, create custom computations with a powerful query language, and visualize log data in dashboards. CloudWatch Logs cannot be used to track the external IP address used for uploads to S3.
Reference:
https://aws.amazon.com/premiumsupport/knowledge-center/external-ip-address-s3-bucket/
Explanation
Correct options:
Enable Amazon S3 server access logging to capture all bucket-level and object-level events
Enable AWS CloudTrail data events to enable object-level logging for S3 bucket
To find the IP addresses for object-level requests to Amazon S3 (uploads and downloads), you must first enable one of the following logging methods:
Amazon S3 server access logging captures all bucket-level and object-level events. These logs use a format similar to Apache web server logs. After you enable server access logging, review the logs to find the IP addresses used with each upload to your bucket.
AWS CloudTrail data events capture the last 90 days of bucket-level events (for example, PutBucketPolicy and DeleteBucketPolicy), and you can enable object-level logging. These logs use a JSON format. After you enable object-level logging with data events, review the logs to find the IP addresses used with each upload to your bucket. It might take a few hours for AWS CloudTrail to start creating logs.
Incorrect options:
Enable VPC Flow Logs to capture all object-level events occurring on the S3 bucket - VPC Flow Logs is a feature that enables you to capture information about the IP traffic going to and from network interfaces in your VPC, so it does not apply to S3. Flow log data can be published to Amazon CloudWatch Logs or Amazon S3.
Enable AWS Systems Manager Agent (SSM Agent) that writes information about executions, commands, scheduled actions on all AWS resources - AWS Systems Manager Agent (SSM Agent) writes information about executions, commands, scheduled actions, errors, and health statuses to log files on each managed node. You can view log files by manually connecting to a managed node, or you can automatically send logs to Amazon CloudWatch Logs. AWS Systems Manager Agent (SSM Agent) is Amazon software that runs on Amazon Elastic Compute Cloud (Amazon EC2) instances, edge devices, and on-premises servers and virtual machines (VMs), so it does not apply to S3.
CloudWatch Logs centrally maintain the logs from all of your systems, applications, and AWS services that you use. Use these logs to capture the IP address at the object level for the S3 bucket - You can use Amazon CloudWatch Logs to monitor, store, and access your log files from Amazon Elastic Compute Cloud (Amazon EC2) instances, AWS CloudTrail, Route 53, and other sources. CloudWatch Logs enables you to see all of your logs, regardless of their source, as a single and consistent flow of events ordered by time, and you can query them and sort them based on other dimensions, group them by specific fields, create custom computations with a powerful query language, and visualize log data in dashboards. CloudWatch Logs cannot be used to track the external IP address used for uploads to S3.
Reference:
https://aws.amazon.com/premiumsupport/knowledge-center/external-ip-address-s3-bucket/
Question 18 Single Choice
A data analytics company uses Amazon S3 as the data lake to store the input data that is ingested from the IoT field devices on an hourly basis. The ingested data has attributes such as the device type, ID of the device, the status of the device, the timestamp of the event, the source IP address, etc. The data runs into millions of records per day and the company wants to run complex analytical queries on this data daily for product improvements for each device type.
Which is the most optimal way to save this data to get the best performance from the millions of data points processed daily?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Store the data in Apache ORC, partitioned by date and sorted by device type of the device - Apache Parquet and ORC are columnar storage formats that are optimized for fast retrieval of data and used in AWS analytical applications.
By partitioning your data, you can restrict the amount of data scanned by each query, thus improving performance and reducing cost. You can partition your data by any key. A common practice is to partition the data based on time, often leading to a multi-level partitioning scheme. For example, a customer who has data coming in every hour might decide to partition by year, month, date, and hour. Another customer, who has data coming from many different sources but that is loaded only once per day, might partition by a data source identifier and date.
For the given use case, as the company does daily analysis, so it only needs to look at the data generated for a given date. Hence partitioning by date offers significant performance and cost advantages. Since the company also wants to analyze product improvements for each device type, it is better to keep the data sorted by device type, so it allows for faster query execution.
Incorrect options:
Store the data in Apache Parquet, partitioned by device type and sorted by date - Apache Parquet is a columnar storage format that is optimized for fast retrieval of data and used in AWS analytical applications. However, partitioning by device type is incorrect for this use case, and partitioning by date is optimal.
Store the data in compressed .csv, partitioned by date and sorted by the status of the device
Store the data in compressed .csv, partitioned by date and sorted by device type
Both the above options are not columnar storage formats, they are row-based formats that are not optimal for big data retrievals for complex analytical queries.
Reference:
https://docs.aws.amazon.com/athena/latest/ug/partitions.html
Explanation
Correct option:
Store the data in Apache ORC, partitioned by date and sorted by device type of the device - Apache Parquet and ORC are columnar storage formats that are optimized for fast retrieval of data and used in AWS analytical applications.
By partitioning your data, you can restrict the amount of data scanned by each query, thus improving performance and reducing cost. You can partition your data by any key. A common practice is to partition the data based on time, often leading to a multi-level partitioning scheme. For example, a customer who has data coming in every hour might decide to partition by year, month, date, and hour. Another customer, who has data coming from many different sources but that is loaded only once per day, might partition by a data source identifier and date.
For the given use case, as the company does daily analysis, so it only needs to look at the data generated for a given date. Hence partitioning by date offers significant performance and cost advantages. Since the company also wants to analyze product improvements for each device type, it is better to keep the data sorted by device type, so it allows for faster query execution.
Incorrect options:
Store the data in Apache Parquet, partitioned by device type and sorted by date - Apache Parquet is a columnar storage format that is optimized for fast retrieval of data and used in AWS analytical applications. However, partitioning by device type is incorrect for this use case, and partitioning by date is optimal.
Store the data in compressed .csv, partitioned by date and sorted by the status of the device
Store the data in compressed .csv, partitioned by date and sorted by device type
Both the above options are not columnar storage formats, they are row-based formats that are not optimal for big data retrievals for complex analytical queries.
Reference:
https://docs.aws.amazon.com/athena/latest/ug/partitions.html
Question 19 Single Choice
A bioinformatics company leverages multiple open source tools to manage data analysis workflows running on its on-premises servers to process biological data which is generated and stored on a Network Attached Storage (NAS). The existing workflow receives around 100 GB of input biological data for each job run and individual jobs can take several hours to process the data. The CTO at the company wants to re-architect its proprietary analytics workflow on AWS to meet the workload demands and reduce the turnaround time from months to days. The company has provisioned a high-speed AWS Direct Connect connection. The final result needs to be stored in Amazon S3. The company is expecting approximately 20 job requests each day.
Which of the following options would you recommend for the given use case?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Leverage AWS DataSync to transfer the biological data to Amazon S3. Use S3 events to trigger an AWS Lambda function that starts an AWS Step Functions workflow for orchestrating an AWS Batch job that processes the biological data
AWS DataSync is an online data movement and discovery service that simplifies and accelerates data migrations to AWS as well as moving data between on-premises storage, edge locations, other clouds, and AWS Storage. You can use DataSync to migrate active data to AWS, archive data to free up on-premises storage capacity, replicate data to AWS for business continuity, or transfer data to the cloud for analysis and processing.
For data transfer between on-premises and AWS Storage services, a single DataSync task is capable of fully utilizing a 10 Gbps network link. Since each workflow job consumes around 100GB of data and the company sees approximately 20 runs every day, DataSync can easily handle such active data transfer workloads. For the given use case, you can then configure an S3 event to trigger an AWS Lambda function that starts an AWS Step Functions workflow for orchestrating an AWS Batch job that processes the biological data.
 via - https://aws.amazon.com/datasync/faqs/
via - https://aws.amazon.com/datasync/faqs/
 via - https://aws.amazon.com/datasync/faqs/
via - https://aws.amazon.com/datasync/faqs/
Incorrect options:
Leverage AWS Data Pipeline to transfer the biological data to Amazon S3. Use S3 events to trigger an AWS Step Functions workflow for orchestrating an AWS Batch job that processes the biological data - You cannot trigger an AWS Step Function directly from an S3 event, so this option is incorrect.
Leverage AWS Data Pipeline to transfer the biological data to Amazon S3. Use S3 events to trigger an Amazon EC2 Auto Scaling group to launch custom-AMI EC2 instances to process the biological data - You cannot trigger an Amazon EC2 Auto Scaling group directly from an S3 event, so this option is incorrect.
Leverage AWS Storage Gateway file gateway to transfer the biological data to Amazon S3. Use S3 events to trigger an AWS Lambda function that starts an AWS Step Functions workflow for orchestrating an AWS Batch job that processes the biological data - You should use AWS DataSync to migrate existing or active data to Amazon S3 and use the File Gateway configuration of AWS Storage Gateway to retain access to the migrated data and for ongoing updates from your on-premises file-based applications. Since the data processing workflow/application is being migrated from on-premises to AWS Cloud, you no longer have any on-premises applications that need to access the processed data from AWS Cloud. So this option is incorrect.
References:
Explanation
Correct option:
Leverage AWS DataSync to transfer the biological data to Amazon S3. Use S3 events to trigger an AWS Lambda function that starts an AWS Step Functions workflow for orchestrating an AWS Batch job that processes the biological data
AWS DataSync is an online data movement and discovery service that simplifies and accelerates data migrations to AWS as well as moving data between on-premises storage, edge locations, other clouds, and AWS Storage. You can use DataSync to migrate active data to AWS, archive data to free up on-premises storage capacity, replicate data to AWS for business continuity, or transfer data to the cloud for analysis and processing.
For data transfer between on-premises and AWS Storage services, a single DataSync task is capable of fully utilizing a 10 Gbps network link. Since each workflow job consumes around 100GB of data and the company sees approximately 20 runs every day, DataSync can easily handle such active data transfer workloads. For the given use case, you can then configure an S3 event to trigger an AWS Lambda function that starts an AWS Step Functions workflow for orchestrating an AWS Batch job that processes the biological data.
via - https://aws.amazon.com/datasync/faqs/
via - https://aws.amazon.com/datasync/faqs/
Incorrect options:
Leverage AWS Data Pipeline to transfer the biological data to Amazon S3. Use S3 events to trigger an AWS Step Functions workflow for orchestrating an AWS Batch job that processes the biological data - You cannot trigger an AWS Step Function directly from an S3 event, so this option is incorrect.
Leverage AWS Data Pipeline to transfer the biological data to Amazon S3. Use S3 events to trigger an Amazon EC2 Auto Scaling group to launch custom-AMI EC2 instances to process the biological data - You cannot trigger an Amazon EC2 Auto Scaling group directly from an S3 event, so this option is incorrect.
Leverage AWS Storage Gateway file gateway to transfer the biological data to Amazon S3. Use S3 events to trigger an AWS Lambda function that starts an AWS Step Functions workflow for orchestrating an AWS Batch job that processes the biological data - You should use AWS DataSync to migrate existing or active data to Amazon S3 and use the File Gateway configuration of AWS Storage Gateway to retain access to the migrated data and for ongoing updates from your on-premises file-based applications. Since the data processing workflow/application is being migrated from on-premises to AWS Cloud, you no longer have any on-premises applications that need to access the processed data from AWS Cloud. So this option is incorrect.
References:
Question 20 Single Choice
A retail company offers its services to the customers via APIs that leverage Amazon API Gateway and Lambda functions. The company also has a legacy API hosted on an Amazon EC2 instance that is used by the company's supply chain partners. The security and audit team at the company has raised concerns over the use of these APIs and wants a solution to secure them all from any vulnerabilities, DDoS attacks, and malicious exploits.
Which of the following options would you use to address the security requirements of the company?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use AWS Web Application Firewall (WAF) as the first line of defense to protect the API Gateway APIs against malicious exploits and DDoS attacks. Install Amazon Inspector on the EC2 instance to check for vulnerabilities. Configure Amazon GuardDuty to monitor any malicious attempts to access the APIs illegally
AWS WAF is a web application firewall that helps protect web applications and APIs from attacks. It enables you to configure a set of rules (called a web access control list (web ACL)) that allow, block, or count web requests based on customizable web security rules and conditions that you define. You can protect the following resource types:
- Amazon CloudFront distribution
- Amazon API Gateway REST API
- Application Load Balancer
- AWS AppSync GraphQL API
- Amazon Cognito user pool
You can use AWS WAF to protect your API Gateway API from common web exploits, such as SQL injection and cross-site scripting (XSS) attacks. These could affect API availability and performance, compromise security, or consume excessive resources. For example, you can create rules to allow or block requests from specified IP address ranges, requests from CIDR blocks, requests that originate from a specific country or region, requests that contain malicious SQL code, or requests that contain malicious scripts.
DDoS attacks are attempts by an attacker to disrupt the availability of targeted systems. For infrastructure layer attacks, you can use AWS services such as Amazon CloudFront and Elastic Load Balancing (ELB) to provide automatic DDoS protection. For application layer attacks, you can use AWS WAF as the primary mitigation. AWS WAF web access control lists (web ACLs) minimize the effects of a DDoS attack at the application layer.
How WAF works: 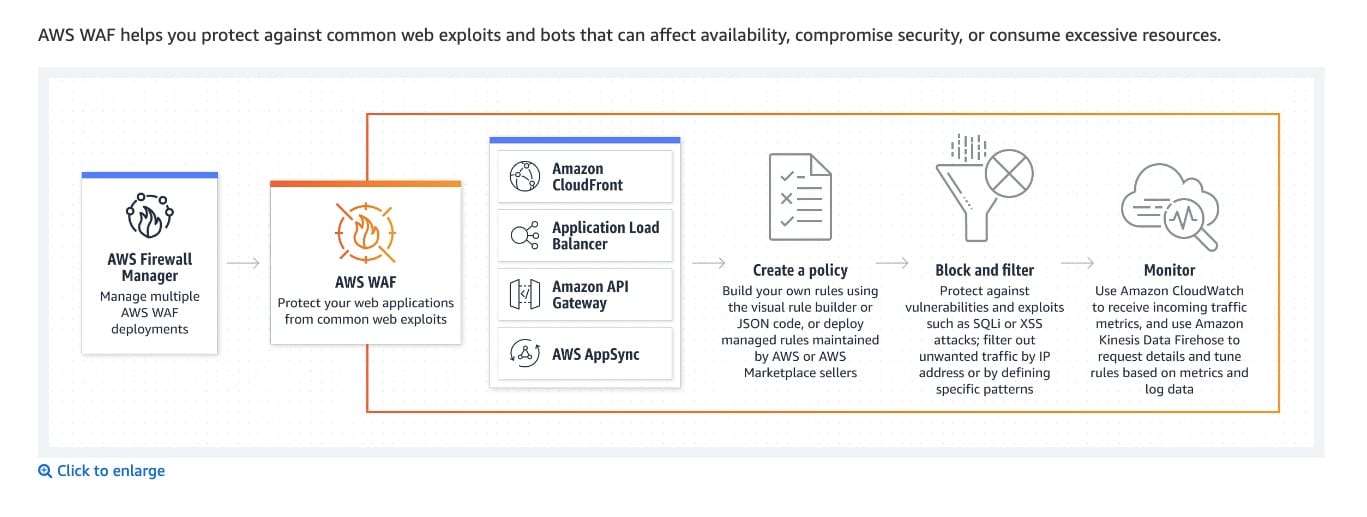 via - https://aws.amazon.com/waf/
via - https://aws.amazon.com/waf/
GuardDuty is an intelligent threat detection service that continuously monitors your AWS accounts, Amazon Elastic Compute Cloud (EC2) instances, Amazon Elastic Kubernetes Service (EKS) clusters, and data stored in Amazon Simple Storage Service (S3) for malicious activity without the use of security software or agents. If potential malicious activity, such as anomalous behavior, credential exfiltration, or command and control infrastructure (C2) communication is detected, GuardDuty generates detailed security findings that can be used for security visibility and assisting in remediation. GuardDuty can monitor reconnaissance activities by an attacker such as unusual API activity, intra-VPC port scanning, unusual patterns of failed login requests, or unblocked port probing from a known bad IP.
How GuardDuty works: 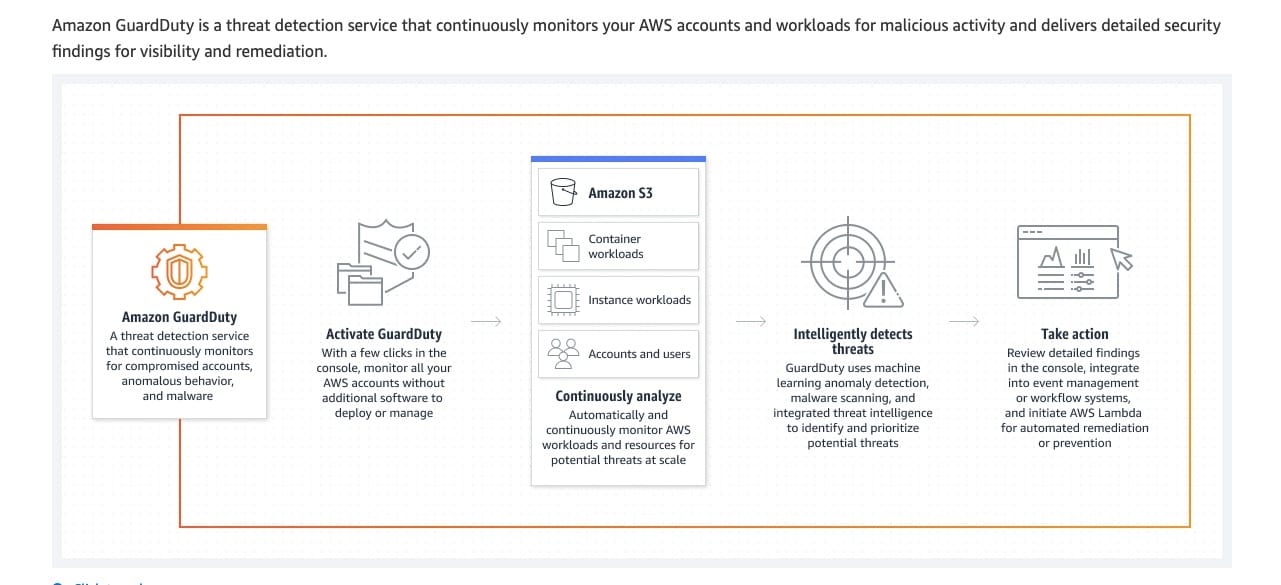 via - https://aws.amazon.com/guardduty/
via - https://aws.amazon.com/guardduty/
Amazon Inspector is an automated vulnerability management service that continually scans Amazon Elastic Compute Cloud (EC2) and container workloads for software vulnerabilities and unintended network exposure.
How Amazon Inspector works: 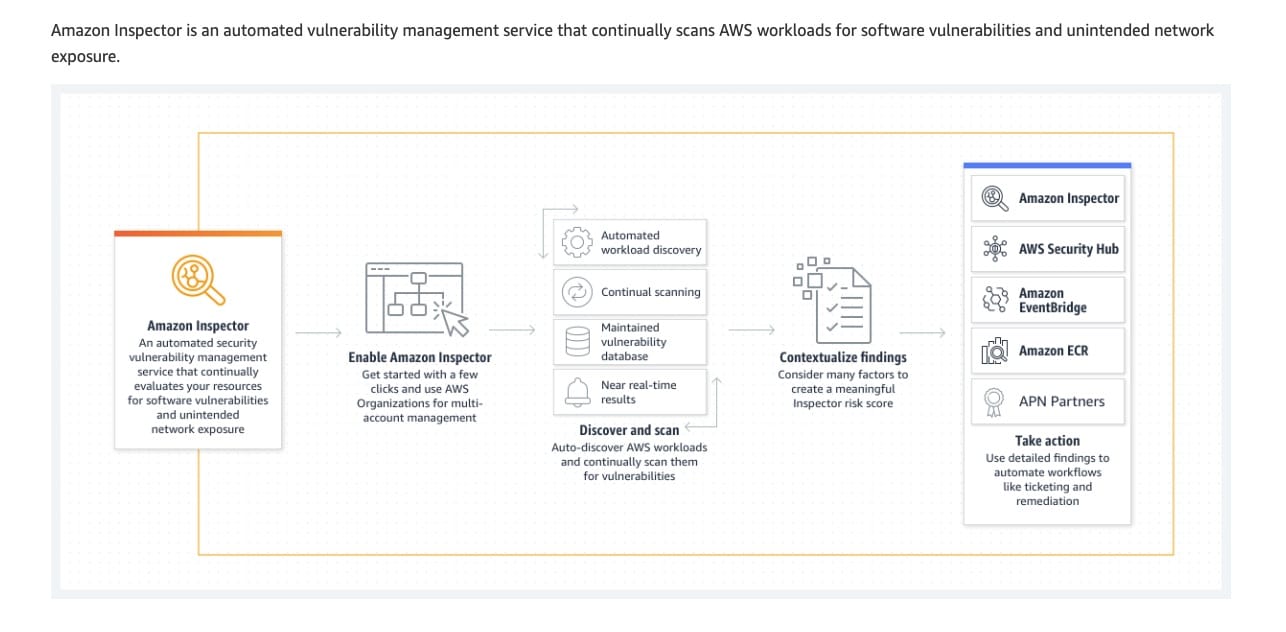 via - https://aws.amazon.com/inspector
via - https://aws.amazon.com/inspector
Incorrect options:
Configure Amazon CloudFront in front of the APIs to protect against malicious exploits and DDoS attacks. Install Amazon GuardDuty on the EC2 instances to assess any vulnerabilities - This statement is incorrect. GuardDuty cannot assess vulnerabilities in the EC2 instances. Amazon Inspector is the automated vulnerability management service that continually scans Amazon Elastic Compute Cloud (EC2) and container workloads for software vulnerabilities and unintended network exposure.
Enable AWS Network Firewall on API Gateway as well as the Amazon EC2 instances to check for vulnerabilities and protect against DDoS attacks as well as malicious exploits - AWS Network Firewall is a managed service that makes it easy to deploy essential network protections for all of your Amazon Virtual Private Clouds (VPCs). AWS Network Firewall works with AWS Firewall Manager to centrally manage security policies and automatically enforce mandatory security policies across existing and newly created accounts and VPCs. This service works at the VPC level and not at the API Gateway or the EC2 instance level.
How AWS Network Firewall works: 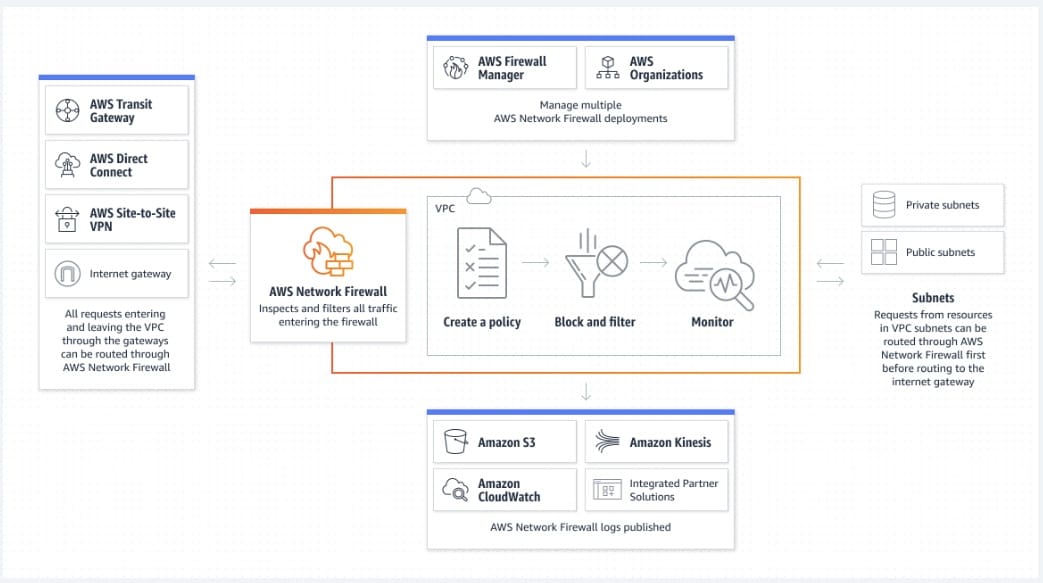 via - https://aws.amazon.com/network-firewall/
via - https://aws.amazon.com/network-firewall/
Use AWS Web Application Firewall (WAF) as the first line of defense to protect the API Gateway APIs against malicious exploits and DDoS attacks. Install Amazon Inspector on the EC2 instance to check for vulnerabilities. Configure Amazon GuardDuty to block any malicious attempts to access the APIs illegally - GuardDuty cannot block any malicious attempts to access the APIs illegally. Rather, it can only monitor/detect such attempts.
References:
https://aws.amazon.com/guardduty/faqs/
https://aws.amazon.com/premiumsupport/knowledge-center/waf-mitigate-ddos-attacks/
Explanation
Correct option:
Use AWS Web Application Firewall (WAF) as the first line of defense to protect the API Gateway APIs against malicious exploits and DDoS attacks. Install Amazon Inspector on the EC2 instance to check for vulnerabilities. Configure Amazon GuardDuty to monitor any malicious attempts to access the APIs illegally
AWS WAF is a web application firewall that helps protect web applications and APIs from attacks. It enables you to configure a set of rules (called a web access control list (web ACL)) that allow, block, or count web requests based on customizable web security rules and conditions that you define. You can protect the following resource types:
- Amazon CloudFront distribution
- Amazon API Gateway REST API
- Application Load Balancer
- AWS AppSync GraphQL API
- Amazon Cognito user pool
You can use AWS WAF to protect your API Gateway API from common web exploits, such as SQL injection and cross-site scripting (XSS) attacks. These could affect API availability and performance, compromise security, or consume excessive resources. For example, you can create rules to allow or block requests from specified IP address ranges, requests from CIDR blocks, requests that originate from a specific country or region, requests that contain malicious SQL code, or requests that contain malicious scripts.
DDoS attacks are attempts by an attacker to disrupt the availability of targeted systems. For infrastructure layer attacks, you can use AWS services such as Amazon CloudFront and Elastic Load Balancing (ELB) to provide automatic DDoS protection. For application layer attacks, you can use AWS WAF as the primary mitigation. AWS WAF web access control lists (web ACLs) minimize the effects of a DDoS attack at the application layer.
How WAF works: via - https://aws.amazon.com/waf/
GuardDuty is an intelligent threat detection service that continuously monitors your AWS accounts, Amazon Elastic Compute Cloud (EC2) instances, Amazon Elastic Kubernetes Service (EKS) clusters, and data stored in Amazon Simple Storage Service (S3) for malicious activity without the use of security software or agents. If potential malicious activity, such as anomalous behavior, credential exfiltration, or command and control infrastructure (C2) communication is detected, GuardDuty generates detailed security findings that can be used for security visibility and assisting in remediation. GuardDuty can monitor reconnaissance activities by an attacker such as unusual API activity, intra-VPC port scanning, unusual patterns of failed login requests, or unblocked port probing from a known bad IP.
How GuardDuty works: via - https://aws.amazon.com/guardduty/
Amazon Inspector is an automated vulnerability management service that continually scans Amazon Elastic Compute Cloud (EC2) and container workloads for software vulnerabilities and unintended network exposure.
How Amazon Inspector works: via - https://aws.amazon.com/inspector
Incorrect options:
Configure Amazon CloudFront in front of the APIs to protect against malicious exploits and DDoS attacks. Install Amazon GuardDuty on the EC2 instances to assess any vulnerabilities - This statement is incorrect. GuardDuty cannot assess vulnerabilities in the EC2 instances. Amazon Inspector is the automated vulnerability management service that continually scans Amazon Elastic Compute Cloud (EC2) and container workloads for software vulnerabilities and unintended network exposure.
Enable AWS Network Firewall on API Gateway as well as the Amazon EC2 instances to check for vulnerabilities and protect against DDoS attacks as well as malicious exploits - AWS Network Firewall is a managed service that makes it easy to deploy essential network protections for all of your Amazon Virtual Private Clouds (VPCs). AWS Network Firewall works with AWS Firewall Manager to centrally manage security policies and automatically enforce mandatory security policies across existing and newly created accounts and VPCs. This service works at the VPC level and not at the API Gateway or the EC2 instance level.
How AWS Network Firewall works: via - https://aws.amazon.com/network-firewall/
Use AWS Web Application Firewall (WAF) as the first line of defense to protect the API Gateway APIs against malicious exploits and DDoS attacks. Install Amazon Inspector on the EC2 instance to check for vulnerabilities. Configure Amazon GuardDuty to block any malicious attempts to access the APIs illegally - GuardDuty cannot block any malicious attempts to access the APIs illegally. Rather, it can only monitor/detect such attempts.
References:
https://aws.amazon.com/guardduty/faqs/
https://aws.amazon.com/premiumsupport/knowledge-center/waf-mitigate-ddos-attacks/


