
AWS Certified SysOps Administrator - Associate - (SOA-C02) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 1 Single Choice
As SysOps Administrator, you have created two configuration files for CloudWatch Agent configuration. The first configuration file collects a set of metrics and logs from all servers and the second configuration file collects metrics from certain applications. You have given the same name to both the files but stored these files in different file paths.
What is the outcome when the CloudWatch Agent is started with the first configuration file and then the second configuration file is appended to it?
Explanation

Click "Show Answer" to see the explanation here
Correct option:
The append command overwrites the information from the first configuration file instead of appending to it
You can set up the CloudWatch agent to use multiple configuration files. For example, you can use a common configuration file that collects a set of metrics and logs that you always want to collect from all servers in your infrastructure. You can then use additional configuration files that collect metrics from certain applications or in certain situations.
To set this up, first create the configuration files that you want to use. Any configuration files that will be used together on the same server must have different file names. You can store the configuration files on servers or in Parameter Store.
Start the CloudWatch agent using the fetch-config option and specify the first configuration file. To append the second configuration file to the running agent, use the same command but with the append-config option. All metrics and logs listed in either configuration file are collected.
Any configuration files appended to the configuration must have different file names from each other and from the initial configuration file. If you use append-config with a configuration file with the same file name as a configuration file that the agent is already using, the append command overwrites the information from the first configuration file instead of appending to it. This is true even if the two configuration files with the same file name are on different file paths.
Incorrect options:
Second configuration file parameters are added to the Agent already running with the first configuration file parameters
Two different Agents are started with different configurations, collecting the metrics and logs listed in either of the configuration files
A CloudWatch Agent can have only one configuration file and all required parameters are defined in this file alone
These three options contradict the explanation provided above, so these options are incorrect.
Reference:
Explanation
Correct option:
The append command overwrites the information from the first configuration file instead of appending to it
You can set up the CloudWatch agent to use multiple configuration files. For example, you can use a common configuration file that collects a set of metrics and logs that you always want to collect from all servers in your infrastructure. You can then use additional configuration files that collect metrics from certain applications or in certain situations.
To set this up, first create the configuration files that you want to use. Any configuration files that will be used together on the same server must have different file names. You can store the configuration files on servers or in Parameter Store.
Start the CloudWatch agent using the fetch-config option and specify the first configuration file. To append the second configuration file to the running agent, use the same command but with the append-config option. All metrics and logs listed in either configuration file are collected.
Any configuration files appended to the configuration must have different file names from each other and from the initial configuration file. If you use append-config with a configuration file with the same file name as a configuration file that the agent is already using, the append command overwrites the information from the first configuration file instead of appending to it. This is true even if the two configuration files with the same file name are on different file paths.
Incorrect options:
Second configuration file parameters are added to the Agent already running with the first configuration file parameters
Two different Agents are started with different configurations, collecting the metrics and logs listed in either of the configuration files
A CloudWatch Agent can have only one configuration file and all required parameters are defined in this file alone
These three options contradict the explanation provided above, so these options are incorrect.
Reference:
Question 2 Single Choice
A healthcare web application has been deployed on Amazon EC2 instances behind an Application Load Balancer (ALB). The application worked well in the development and test environments. In production, however, users are getting logged off and are being asked to log in several times in an hour.
How will you fix this issue and what precaution needs to be taken to avoid recurrence of the issue?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Enable Sticky Sessions on Application Load Balancer - Sticky sessions are a mechanism to route requests to the same target in a target group. This is useful for servers that maintain state information in order to provide a continuous experience to clients. To use sticky sessions, the clients must support cookies.
When a load balancer first receives a request from a client, it routes the request to a target, generates a cookie named AWSALB that encodes information about the selected target, encrypts the cookie, and includes the cookie in the response to the client. The client should include the cookie that it receives in subsequent requests to the load balancer. When the load balancer receives a request from a client that contains the cookie, if sticky sessions are enabled for the target group and the request goes to the same target group, the load balancer detects the cookie and routes the request to the same target. If the cookie is present but cannot be decoded, or if it refers to a target that was deregistered or is unhealthy, the load balancer selects a new target and updates the cookie with information about the new target.
You enable sticky sessions at the target group level. You can also set the duration for the stickiness of the load balancer-generated cookie in seconds. The duration is set with each request. Therefore, if the client sends a request before each duration period expires, the sticky session continues.
Incorrect options:
Use Slow Start Mode when registering the targets to ALB. This assures that the instances get enough time to warm up and hence will not lose the cached data - By default, a target starts to receive its full share of requests as soon as it is registered with a target group and passes an initial health check. Using slow start mode gives targets time to warm up before the load balancer sends them a full share of requests. However, this option cannot be used to address the given use-case.
Routing configuration of a Load Balancer is used to route traffic to targets. Use this configuration to set the protocol and port number to the correct one - By default, a load balancer routes requests to its targets using the protocol and port number that you specified when you created the target group. Alternatively, you can override the port used for routing traffic to a target when you register it with the target group. This, however, has nothing to do with users getting logged off every few minutes.
Enable logging on ALB and check the logs to see the error being generated - The current use case points at issues with session data and hence using sticky sessions is the right answer here.
Reference:
Explanation
Correct option:
Enable Sticky Sessions on Application Load Balancer - Sticky sessions are a mechanism to route requests to the same target in a target group. This is useful for servers that maintain state information in order to provide a continuous experience to clients. To use sticky sessions, the clients must support cookies.
When a load balancer first receives a request from a client, it routes the request to a target, generates a cookie named AWSALB that encodes information about the selected target, encrypts the cookie, and includes the cookie in the response to the client. The client should include the cookie that it receives in subsequent requests to the load balancer. When the load balancer receives a request from a client that contains the cookie, if sticky sessions are enabled for the target group and the request goes to the same target group, the load balancer detects the cookie and routes the request to the same target. If the cookie is present but cannot be decoded, or if it refers to a target that was deregistered or is unhealthy, the load balancer selects a new target and updates the cookie with information about the new target.
You enable sticky sessions at the target group level. You can also set the duration for the stickiness of the load balancer-generated cookie in seconds. The duration is set with each request. Therefore, if the client sends a request before each duration period expires, the sticky session continues.
Incorrect options:
Use Slow Start Mode when registering the targets to ALB. This assures that the instances get enough time to warm up and hence will not lose the cached data - By default, a target starts to receive its full share of requests as soon as it is registered with a target group and passes an initial health check. Using slow start mode gives targets time to warm up before the load balancer sends them a full share of requests. However, this option cannot be used to address the given use-case.
Routing configuration of a Load Balancer is used to route traffic to targets. Use this configuration to set the protocol and port number to the correct one - By default, a load balancer routes requests to its targets using the protocol and port number that you specified when you created the target group. Alternatively, you can override the port used for routing traffic to a target when you register it with the target group. This, however, has nothing to do with users getting logged off every few minutes.
Enable logging on ALB and check the logs to see the error being generated - The current use case points at issues with session data and hence using sticky sessions is the right answer here.
Reference:
Question 3 Single Choice
A media company stores all their articles on Amazon S3 buckets. As a security measure, they have server access logging enabled for all the buckets. The company is looking at a solution that can regularly check if logging is enabled for all the existing buckets and for any new ones they create. If the solution can also automate the remedy, it will be a perfect fit for their requirement.
Which of the following would you suggest to address the given use-case?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use AWS Config rules to check whether or not an S3 bucket has logging enabled, and carry out the necessary remediation if needed
AWS Config keeps track of the configuration of your AWS resources and their relationships to other resources. It can also evaluate those AWS resources for compliance. This service uses rules that can be configured to evaluate AWS resources against desired configurations.
For example, there are AWS Config rules that check whether or not your Amazon S3 buckets have logging enabled or your IAM users have an MFA device enabled. AWS Config rules use AWS Lambda functions to perform the compliance evaluations, and the Lambda functions return the compliance status of the evaluated resources as compliant or noncompliant. The non-compliant resources are remediated using the remediation action associated with the AWS Config rule. With the Auto-Remediation feature of AWS Config rules, the remediation action can be executed automatically when a resource is found non-compliant.
AWS Config Auto Remediation feature has auto remediate feature for any non-compliant S3 buckets using the following AWS Config rules:
s3-bucket-logging-enabled s3-bucket-server-side-encryption-enabled s3-bucket-public-read-prohibited s3-bucket-public-write-prohibited
These AWS Config rules act as controls to prevent any non-compliant S3 activities.
Incorrect options:
Create a Lambda function that will check the logging status of all the S3 buckets and raise an Amazon SNS notification, if a remedy is needed - AWS Lambda cannot poll by itself and needs a polling mechanism or a service to invoke it. Any logic written to self invoke in the same Lambda function will result in Lambda taking up all the resources available and running continuously, which will also become an expensive solution.
Enable AWS CloudTrail to track the logging information for all the S3 buckets. Currently, AWS does not provide an automatic remediation process, hence, use a Lambda function to rectify any aberrations found during the checks - As discussed above, remediation action is possible with AWS Config and hence is the right solution here.
Amazon S3 server access logging is checked by AWS Trusted Advisor, as part of the best practices check it performs. Configure a remedy action with Trusted Advisor for all the resources that fails this best practice check - AWS Trusted Advisor checks the configuration of Amazon Simple Storage Service (Amazon S3) buckets that have server access logging enabled. It recommends action after these checks but cannot automate a remedial action. Hence, Trusted advisor is not an optimal solution for the current scenario.
Reference:
https://aws.amazon.com/blogs/mt/aws-config-auto-remediation-s3-compliance/
Explanation
Correct option:
Use AWS Config rules to check whether or not an S3 bucket has logging enabled, and carry out the necessary remediation if needed
AWS Config keeps track of the configuration of your AWS resources and their relationships to other resources. It can also evaluate those AWS resources for compliance. This service uses rules that can be configured to evaluate AWS resources against desired configurations.
For example, there are AWS Config rules that check whether or not your Amazon S3 buckets have logging enabled or your IAM users have an MFA device enabled. AWS Config rules use AWS Lambda functions to perform the compliance evaluations, and the Lambda functions return the compliance status of the evaluated resources as compliant or noncompliant. The non-compliant resources are remediated using the remediation action associated with the AWS Config rule. With the Auto-Remediation feature of AWS Config rules, the remediation action can be executed automatically when a resource is found non-compliant.
AWS Config Auto Remediation feature has auto remediate feature for any non-compliant S3 buckets using the following AWS Config rules:
s3-bucket-logging-enabled s3-bucket-server-side-encryption-enabled s3-bucket-public-read-prohibited s3-bucket-public-write-prohibited
These AWS Config rules act as controls to prevent any non-compliant S3 activities.
Incorrect options:
Create a Lambda function that will check the logging status of all the S3 buckets and raise an Amazon SNS notification, if a remedy is needed - AWS Lambda cannot poll by itself and needs a polling mechanism or a service to invoke it. Any logic written to self invoke in the same Lambda function will result in Lambda taking up all the resources available and running continuously, which will also become an expensive solution.
Enable AWS CloudTrail to track the logging information for all the S3 buckets. Currently, AWS does not provide an automatic remediation process, hence, use a Lambda function to rectify any aberrations found during the checks - As discussed above, remediation action is possible with AWS Config and hence is the right solution here.
Amazon S3 server access logging is checked by AWS Trusted Advisor, as part of the best practices check it performs. Configure a remedy action with Trusted Advisor for all the resources that fails this best practice check - AWS Trusted Advisor checks the configuration of Amazon Simple Storage Service (Amazon S3) buckets that have server access logging enabled. It recommends action after these checks but cannot automate a remedial action. Hence, Trusted advisor is not an optimal solution for the current scenario.
Reference:
https://aws.amazon.com/blogs/mt/aws-config-auto-remediation-s3-compliance/
Question 4 Multiple Choice
A team noticed that it has accidentally deleted the AMI of Amazon EC2 instances belonging to the test environment. The team had configured backups via EBS snapshots for these instances.
Which of the following options would you suggest to recover/rebuild the accidentally deleted AMI? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Create a new AMI from Amazon EBS snapshots that were created as backups
Create a new AMI from Amazon EC2 instances that were launched before the deletion of AMI
It isn't possible to restore or recover a deleted or deregistered AMI. However, you can create a new, identical AMI using one of the following:
Amazon Elastic Block Store (Amazon EBS) snapshots that were created as backups: When you delete or deregister an Amazon EBS-backed AMI, any snapshots created for the volume of the instance during the AMI creation process are retained. If you accidentally delete the AMI, you can launch an identical AMI using one of the retained snapshots.
Amazon Elastic Compute Cloud (Amazon EC2) instances that were launched from the deleted AMI: If you deleted the AMI and the snapshots are also deleted, then you can recover the AMI from any existing EC2 instances launched using the deleted AMI. Unless you have selected the
No rebootoption on the instance, performing this step will reboot the instance.
Incorrect options:
AWS Support retains backups of AMIs. Write to the support team to get help for recovering the lost AMI - For security and privacy reasons, AWS Support doesn't have visibility or access to customer data. If you don't have backups of your deleted AMI, AWS Support can't recover it for you.
Recover the AMI from the current Amazon EC2 instances that were launched before the deletion of AMI
Recover the AMI from Amazon EBS snapshots that were created as backups before the deletion of AMI
As discussed above, it is not possible to restore or recover a deleted or deregistered AMI. The only option is to create a new, identical AMI as discussed above.
Reference:
https://aws.amazon.com/premiumsupport/knowledge-center/recover-ami-accidentally-deleted-ec2/
Explanation
Correct options:
Create a new AMI from Amazon EBS snapshots that were created as backups
Create a new AMI from Amazon EC2 instances that were launched before the deletion of AMI
It isn't possible to restore or recover a deleted or deregistered AMI. However, you can create a new, identical AMI using one of the following:
Amazon Elastic Block Store (Amazon EBS) snapshots that were created as backups: When you delete or deregister an Amazon EBS-backed AMI, any snapshots created for the volume of the instance during the AMI creation process are retained. If you accidentally delete the AMI, you can launch an identical AMI using one of the retained snapshots.
Amazon Elastic Compute Cloud (Amazon EC2) instances that were launched from the deleted AMI: If you deleted the AMI and the snapshots are also deleted, then you can recover the AMI from any existing EC2 instances launched using the deleted AMI. Unless you have selected the
No rebootoption on the instance, performing this step will reboot the instance.
Incorrect options:
AWS Support retains backups of AMIs. Write to the support team to get help for recovering the lost AMI - For security and privacy reasons, AWS Support doesn't have visibility or access to customer data. If you don't have backups of your deleted AMI, AWS Support can't recover it for you.
Recover the AMI from the current Amazon EC2 instances that were launched before the deletion of AMI
Recover the AMI from Amazon EBS snapshots that were created as backups before the deletion of AMI
As discussed above, it is not possible to restore or recover a deleted or deregistered AMI. The only option is to create a new, identical AMI as discussed above.
Reference:
https://aws.amazon.com/premiumsupport/knowledge-center/recover-ami-accidentally-deleted-ec2/
Question 5 Multiple Choice
A retail company has realized that their Amazon EBS volume backed EC2 instance is consistently over-utilized and needs an upgrade. A developer has connected with you to understand the key parameters to be considered when changing the instance type.
As a SysOps Administrator, which of the following would you identify as correct regarding the instance types for the given use-case? (Select three)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Resizing of an instance is only possible if the root device for your instance is an EBS volume - If the root device for your instance is an EBS volume, you can change the size of the instance simply by changing its instance type, which is known as resizing it. If the root device for your instance is an instance store volume, you must migrate your application to a new instance with the instance type that you need.
You must stop your Amazon EBS–backed instance before you can change its instance type. AWS moves the instance to new hardware; however, the instance ID does not change - You must stop your Amazon EBS–backed instance before you can change its instance type. When you stop and start an instance, AWS moves the instance to new hardware; however, the instance ID does not change.
If your instance is in an Auto Scaling group, the Amazon EC2 Auto Scaling service marks the stopped instance as unhealthy, and may terminate it and launch a replacement instance - If your instance is in an Auto Scaling group, the Amazon EC2 Auto Scaling service marks the stopped instance as unhealthy, and may terminate it and launch a replacement instance. To prevent this, you can suspend the scaling processes for the group while you're resizing your instance.
Incorrect options:
The new instance retains its public, private IPv4 addresses, any Elastic IP addresses, and any IPv6 addresses that were associated with the old instance - If your instance has a public IPv4 address, AWS releases the address and gives it a new public IPv4 address. The instance retains its private IPv4 addresses, any Elastic IP addresses, and any IPv6 addresses.
There is no downtime on the instance if you choose an instance of a compatible type since AWS starts the new instance and shifts the applications from current instance - AWS suggests that you plan for downtime while your instance is stopped. Stopping and resizing an instance may take a few minutes, and restarting your instance may take a variable amount of time depending on your application's startup scripts.
Resizing of an instance is possible if the root device is either EBS volume or an instance store volume. However, instance store volumes taking longer to start on the new instance, since cache data is lost on these instances - As discussed above, resizing of an instance is possible only if the root device for the instance is an EBS volume.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-resize.html
Explanation
Correct options:
Resizing of an instance is only possible if the root device for your instance is an EBS volume - If the root device for your instance is an EBS volume, you can change the size of the instance simply by changing its instance type, which is known as resizing it. If the root device for your instance is an instance store volume, you must migrate your application to a new instance with the instance type that you need.
You must stop your Amazon EBS–backed instance before you can change its instance type. AWS moves the instance to new hardware; however, the instance ID does not change - You must stop your Amazon EBS–backed instance before you can change its instance type. When you stop and start an instance, AWS moves the instance to new hardware; however, the instance ID does not change.
If your instance is in an Auto Scaling group, the Amazon EC2 Auto Scaling service marks the stopped instance as unhealthy, and may terminate it and launch a replacement instance - If your instance is in an Auto Scaling group, the Amazon EC2 Auto Scaling service marks the stopped instance as unhealthy, and may terminate it and launch a replacement instance. To prevent this, you can suspend the scaling processes for the group while you're resizing your instance.
Incorrect options:
The new instance retains its public, private IPv4 addresses, any Elastic IP addresses, and any IPv6 addresses that were associated with the old instance - If your instance has a public IPv4 address, AWS releases the address and gives it a new public IPv4 address. The instance retains its private IPv4 addresses, any Elastic IP addresses, and any IPv6 addresses.
There is no downtime on the instance if you choose an instance of a compatible type since AWS starts the new instance and shifts the applications from current instance - AWS suggests that you plan for downtime while your instance is stopped. Stopping and resizing an instance may take a few minutes, and restarting your instance may take a variable amount of time depending on your application's startup scripts.
Resizing of an instance is possible if the root device is either EBS volume or an instance store volume. However, instance store volumes taking longer to start on the new instance, since cache data is lost on these instances - As discussed above, resizing of an instance is possible only if the root device for the instance is an EBS volume.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-resize.html
Question 6 Multiple Choice
A firm uses Amazon EC2 instances for running its flagship application. With new business expansion plans, the firm is looking at a bigger footprint for its AWS infrastructure. The development team needs to share Amazon Machine Images (AMIs) across AZs, AWS accounts and Regions.
What are the key points to be considered before planning the expansion? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
You can only share AMIs that have unencrypted volumes and volumes that are encrypted with a customer-managed CMK - You can only share AMIs that have unencrypted volumes and volumes that are encrypted with a customer-managed CMK. If you share an AMI with encrypted volumes, you must also share any CMKs used to encrypt them.
You do not need to share the Amazon EBS snapshots that an AMI references in order to share the AMI - You do not need to share the Amazon EBS snapshots that an AMI references in order to share the AMI. Only the AMI itself needs to be shared; the system automatically provides the access to the referenced Amazon EBS snapshots for the launch.
Incorrect options:
You can only share AMIs that have unencrypted volumes and volumes that are encrypted with an AWS-managed CMK - You cannot share an AMI that has volumes that are encrypted with an AWS-managed CMK.
You need to share any CMKs used to encrypt snapshots and any Amazon EBS snapshots that the AMI references - You do not need to share the Amazon EBS snapshots that an AMI references in order to share the AMI.
AMIs are regional resources and can be shared across Regions - AMIs are a regional resource. Therefore, sharing an AMI makes it available in that Region. To make an AMI available in a different Region, copy the AMI to the Region and then share it. Sharing an AMI from different Regions is not available.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/sharingamis-explicit.html
Explanation
Correct options:
You can only share AMIs that have unencrypted volumes and volumes that are encrypted with a customer-managed CMK - You can only share AMIs that have unencrypted volumes and volumes that are encrypted with a customer-managed CMK. If you share an AMI with encrypted volumes, you must also share any CMKs used to encrypt them.
You do not need to share the Amazon EBS snapshots that an AMI references in order to share the AMI - You do not need to share the Amazon EBS snapshots that an AMI references in order to share the AMI. Only the AMI itself needs to be shared; the system automatically provides the access to the referenced Amazon EBS snapshots for the launch.
Incorrect options:
You can only share AMIs that have unencrypted volumes and volumes that are encrypted with an AWS-managed CMK - You cannot share an AMI that has volumes that are encrypted with an AWS-managed CMK.
You need to share any CMKs used to encrypt snapshots and any Amazon EBS snapshots that the AMI references - You do not need to share the Amazon EBS snapshots that an AMI references in order to share the AMI.
AMIs are regional resources and can be shared across Regions - AMIs are a regional resource. Therefore, sharing an AMI makes it available in that Region. To make an AMI available in a different Region, copy the AMI to the Region and then share it. Sharing an AMI from different Regions is not available.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/sharingamis-explicit.html
Question 7 Single Choice
An automobile company uses a hybrid environment to run its technology infrastructure using a mix of on-premises instances and AWS Cloud. The company has a few managed instances in Amazon VPC. The company wants to avoid using the internet for accessing AWS Systems Manager APIs from this VPC.
As a Systems Administrator, which of the following would you recommend to address this requirement?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
You can privately access AWS Systems Manager APIs from Amazon VPC by creating VPC Endpoint - A managed instance is any machine configured for AWS Systems Manager. You can configure EC2 instances or on-premises machines in a hybrid environment as managed instances.
You can improve the security posture of your managed instances (including managed instances in your hybrid environment) by configuring AWS Systems Manager to use an interface VPC endpoint in Amazon Virtual Private Cloud (Amazon VPC). An interface VPC endpoint (interface endpoint) enables you to connect to services powered by AWS PrivateLink, a technology that enables you to privately access Amazon EC2 and Systems Manager APIs by using private IP addresses. PrivateLink restricts all network traffic between your managed instances, Systems Manager, and Amazon EC2 to the Amazon network. This means that your managed instances don't have access to the Internet. If you use PrivateLink, you don't need an Internet gateway, a NAT device, or a virtual private gateway.
How to use AWS PrivateLink: 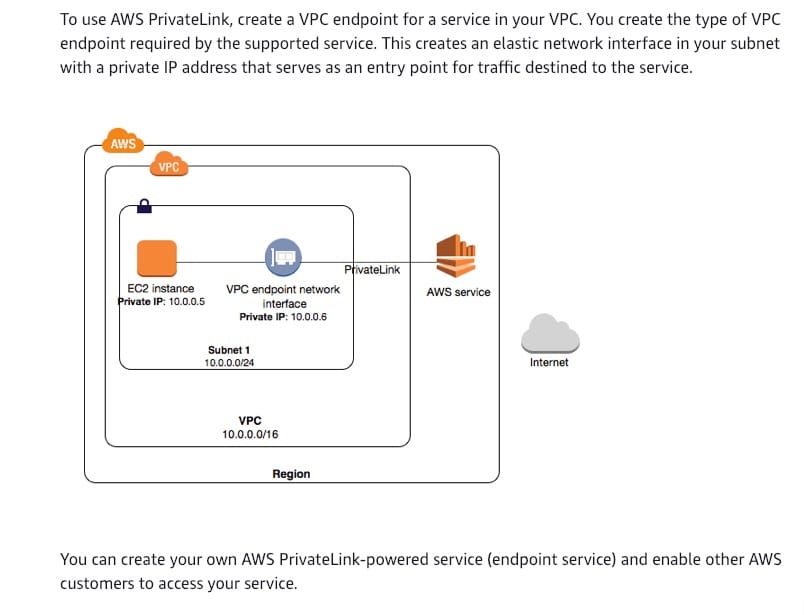 via - https://docs.aws.amazon.com/vpc/latest/userguide/how-it-works.html#what-is-privatelink
via - https://docs.aws.amazon.com/vpc/latest/userguide/how-it-works.html#what-is-privatelink
Incorrect options:
You can privately access AWS Systems Manager APIs from Amazon VPC by creating Internet Gateway
An internet gateway is a horizontally scaled, redundant, and highly available VPC component that allows communication between instances in your VPC and the internet. It, therefore, imposes no availability risks or bandwidth constraints on your network traffic. Internet Gateways must be deployed in a public subnet and the corresponding entry should be added to the route table.
You can privately access AWS Systems Manager APIs from Amazon VPC by creating NAT gateway
You can use a network address translation (NAT) gateway to enable instances in a private subnet to connect to the internet or other AWS services, but prevent the internet from initiating a connection with those instances.
You can privately access AWS Systems Manager APIs from Amazon VPC by creating VPN connection
By default, instances that you launch into an Amazon VPC can't communicate with your own (remote) network. You can enable access to your remote network from your VPC by creating an AWS Site-to-Site VPN (Site-to-Site VPN) connection, and configuring routing to pass traffic through the connection.
These three options contradict the explanation above, so these options are incorrect.
Reference:
https://docs.aws.amazon.com/systems-manager/latest/userguide/setup-create-vpc.html
Explanation
Correct option:
You can privately access AWS Systems Manager APIs from Amazon VPC by creating VPC Endpoint - A managed instance is any machine configured for AWS Systems Manager. You can configure EC2 instances or on-premises machines in a hybrid environment as managed instances.
You can improve the security posture of your managed instances (including managed instances in your hybrid environment) by configuring AWS Systems Manager to use an interface VPC endpoint in Amazon Virtual Private Cloud (Amazon VPC). An interface VPC endpoint (interface endpoint) enables you to connect to services powered by AWS PrivateLink, a technology that enables you to privately access Amazon EC2 and Systems Manager APIs by using private IP addresses. PrivateLink restricts all network traffic between your managed instances, Systems Manager, and Amazon EC2 to the Amazon network. This means that your managed instances don't have access to the Internet. If you use PrivateLink, you don't need an Internet gateway, a NAT device, or a virtual private gateway.
How to use AWS PrivateLink: via - https://docs.aws.amazon.com/vpc/latest/userguide/how-it-works.html#what-is-privatelink
Incorrect options:
You can privately access AWS Systems Manager APIs from Amazon VPC by creating Internet Gateway
An internet gateway is a horizontally scaled, redundant, and highly available VPC component that allows communication between instances in your VPC and the internet. It, therefore, imposes no availability risks or bandwidth constraints on your network traffic. Internet Gateways must be deployed in a public subnet and the corresponding entry should be added to the route table.
You can privately access AWS Systems Manager APIs from Amazon VPC by creating NAT gateway
You can use a network address translation (NAT) gateway to enable instances in a private subnet to connect to the internet or other AWS services, but prevent the internet from initiating a connection with those instances.
You can privately access AWS Systems Manager APIs from Amazon VPC by creating VPN connection
By default, instances that you launch into an Amazon VPC can't communicate with your own (remote) network. You can enable access to your remote network from your VPC by creating an AWS Site-to-Site VPN (Site-to-Site VPN) connection, and configuring routing to pass traffic through the connection.
These three options contradict the explanation above, so these options are incorrect.
Reference:
https://docs.aws.amazon.com/systems-manager/latest/userguide/setup-create-vpc.html
Question 8 Single Choice
As a SysOps Administrator, you maintain the development account of a large team that comprises of both developers and testers. The Development account has two IAM groups: Developers and Testers. Users in both groups have permission to work in the development account and access resources there. From time to time, a developer must update the live S3 Bucket in the production account.
How will you configure the permissions for developers to access the production environment?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Create a Role in production account, that defines the Development account as a trusted entity and specify a permissions policy that allows trusted users to update the bucket. Then, modify the IAM group policy in development account, so that testers are denied access to the newly created role. Developers can use the newly created role to access the live S3 buckets in production environment -
First, you use the AWS Management Console to establish trust between the production account and the development account. You start by creating an IAM role. When you create the role, you define the development account as a trusted entity and specify a permissions policy that allows trusted users to update the production bucket.
You need to then modify the IAM group policy for the Testers IAM group so that the Testers are explicitly denied access to the created role.
Finally, as a developer, you use the created role to update the bucket in the Production account.
Incorrect options:
Create a Role in development account, that defines the production account as a trusted entity and specify a permissions policy that allows trusted users to update the bucket. Then, modify the IAM group policy in development account, so that testers are denied access to the newly created role. Developers can use the newly created role to access the live S3 buckets in production environment - Role has to be created in production account since the resource to be accessed is in this account.
Use Inline policies to be sure that the permissions in a policy are not inadvertently assigned to an identity other than the one they're intended for - An inline policy is a policy that's embedded in an IAM identity (a user, group, or role). That is, the policy is an inherent part of the identity. You can create a policy and embed it in an identity, either when you create the identity or later.
Inline policies are useful if you want to maintain a strict one-to-one relationship between a policy and the identity that it's applied to. For example, you want to be sure that the permissions in a policy are not inadvertently assigned to an identity other than the one they're intended for. When you use an inline policy, the permissions in the policy cannot be inadvertently attached to the wrong identity.
Create a Role in Production account, that defines the Development account as a trusted entity and specify a permissions policy that allows trusted users to update the bucket. Developers can use the newly created role to access the live S3 buckets in production environment - This option does not deny access to Testers, so it is not correct.
References:
https://docs.aws.amazon.com/IAM/latest/UserGuide/tutorial_cross-account-with-roles.html
Explanation
Correct option:
Create a Role in production account, that defines the Development account as a trusted entity and specify a permissions policy that allows trusted users to update the bucket. Then, modify the IAM group policy in development account, so that testers are denied access to the newly created role. Developers can use the newly created role to access the live S3 buckets in production environment -
First, you use the AWS Management Console to establish trust between the production account and the development account. You start by creating an IAM role. When you create the role, you define the development account as a trusted entity and specify a permissions policy that allows trusted users to update the production bucket.
You need to then modify the IAM group policy for the Testers IAM group so that the Testers are explicitly denied access to the created role.
Finally, as a developer, you use the created role to update the bucket in the Production account.
Incorrect options:
Create a Role in development account, that defines the production account as a trusted entity and specify a permissions policy that allows trusted users to update the bucket. Then, modify the IAM group policy in development account, so that testers are denied access to the newly created role. Developers can use the newly created role to access the live S3 buckets in production environment - Role has to be created in production account since the resource to be accessed is in this account.
Use Inline policies to be sure that the permissions in a policy are not inadvertently assigned to an identity other than the one they're intended for - An inline policy is a policy that's embedded in an IAM identity (a user, group, or role). That is, the policy is an inherent part of the identity. You can create a policy and embed it in an identity, either when you create the identity or later.
Inline policies are useful if you want to maintain a strict one-to-one relationship between a policy and the identity that it's applied to. For example, you want to be sure that the permissions in a policy are not inadvertently assigned to an identity other than the one they're intended for. When you use an inline policy, the permissions in the policy cannot be inadvertently attached to the wrong identity.
Create a Role in Production account, that defines the Development account as a trusted entity and specify a permissions policy that allows trusted users to update the bucket. Developers can use the newly created role to access the live S3 buckets in production environment - This option does not deny access to Testers, so it is not correct.
References:
https://docs.aws.amazon.com/IAM/latest/UserGuide/tutorial_cross-account-with-roles.html
Question 9 Single Choice
A video streaming app uses Amazon Kinesis Data Streams for streaming data. The systems administration team needs to be informed of the shard capacity when it is reaching its limits.
How will you configure this requirement?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Monitor Trusted Advisor service check results with Amazon CloudWatch Events - AWS Trusted Advisor checks for service usage that is more than 80% of the service limit.
A partial list of Trusted Advisor service limit checks: 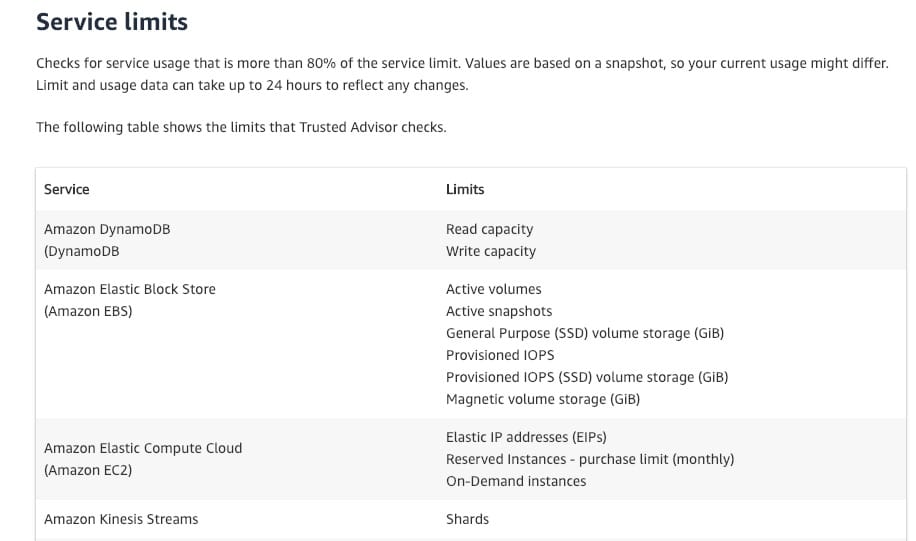 via - https://aws.amazon.com/premiumsupport/technology/trusted-advisor/best-practice-checklist/
via - https://aws.amazon.com/premiumsupport/technology/trusted-advisor/best-practice-checklist/
You can use Amazon CloudWatch Events to detect and react to changes in the status of Trusted Advisor checks. Then, based on the rules that you create, CloudWatch Events invokes one or more target actions when a status check changes to the value you specify in a rule. Depending on the type of status change, you might want to send notifications, capture status information, take corrective action, initiate events, or take other actions.
Incorrect options:
Configure Amazon CloudWatch Events to pick data from Amazon Inspector - Amazon Inspector is an automated security assessment service that helps you test the network accessibility of your Amazon EC2 instances and the security state of your applications running on the instances. Not the right service for the given requirement.
Use CloudWatch ServiceLens to monitor data on service limits of various AWS services - CloudWatch ServiceLens enhances the observability of your services and applications by enabling you to integrate traces, metrics, logs, and alarms into one place. So, ServiceLens can be used once we define the alarms in CloudWatch, not without it.
Configure Amazon CloudTrail to generate logs for the service limits. CloudTrail and CloudWatch are integrated and hence alarm can be generated for customized service checks - AWS CloudTrail is a service that enables governance, compliance, operational auditing, and risk auditing of your AWS account. With CloudTrail, you can log, continuously monitor, and retain account activity related to actions across your AWS infrastructure. CloudTrail however, does not monitor service limits.
References:
https://docs.aws.amazon.com/awssupport/latest/user/cloudwatch-events-ta.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/ServiceLens.html
https://aws.amazon.com/premiumsupport/technology/trusted-advisor/best-practice-checklist/
Explanation
Correct option:
Monitor Trusted Advisor service check results with Amazon CloudWatch Events - AWS Trusted Advisor checks for service usage that is more than 80% of the service limit.
A partial list of Trusted Advisor service limit checks: via - https://aws.amazon.com/premiumsupport/technology/trusted-advisor/best-practice-checklist/
You can use Amazon CloudWatch Events to detect and react to changes in the status of Trusted Advisor checks. Then, based on the rules that you create, CloudWatch Events invokes one or more target actions when a status check changes to the value you specify in a rule. Depending on the type of status change, you might want to send notifications, capture status information, take corrective action, initiate events, or take other actions.
Incorrect options:
Configure Amazon CloudWatch Events to pick data from Amazon Inspector - Amazon Inspector is an automated security assessment service that helps you test the network accessibility of your Amazon EC2 instances and the security state of your applications running on the instances. Not the right service for the given requirement.
Use CloudWatch ServiceLens to monitor data on service limits of various AWS services - CloudWatch ServiceLens enhances the observability of your services and applications by enabling you to integrate traces, metrics, logs, and alarms into one place. So, ServiceLens can be used once we define the alarms in CloudWatch, not without it.
Configure Amazon CloudTrail to generate logs for the service limits. CloudTrail and CloudWatch are integrated and hence alarm can be generated for customized service checks - AWS CloudTrail is a service that enables governance, compliance, operational auditing, and risk auditing of your AWS account. With CloudTrail, you can log, continuously monitor, and retain account activity related to actions across your AWS infrastructure. CloudTrail however, does not monitor service limits.
References:
https://docs.aws.amazon.com/awssupport/latest/user/cloudwatch-events-ta.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/ServiceLens.html
https://aws.amazon.com/premiumsupport/technology/trusted-advisor/best-practice-checklist/
Question 10 Single Choice
As a SysOps Administrator, you have been contacted by a team for troubleshooting a security issue they seem to be facing. A security check red flag is being raised for the security groups created by AWS Directory Services. The flag message says "Security Groups - Unrestricted Access."
How will you troubleshoot this issue?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Ignore or suppress the red flag since it is safe to do so, in this scenario - AWS Directory Services is a managed service that automatically creates an AWS security group in your VPC with network rules for traffic in and out of AWS managed domain controllers. The default inbound rules allow traffic from any source (0.0.0.0/0) to ports required by Active Directory. These rules do not introduce security vulnerabilities, as traffic to the domain controllers is limited to traffic from your VPC, other peered VPCs, or networks connected using AWS Direct Connect, AWS Transit Gateway or Virtual Private Network.
In addition, the ENIs the security group is attached to, do not and cannot have Elastic IPs attached to them, limiting inbound traffic to local VPC and VPC routed traffic.
Incorrect options:
The security group configurations have to be checked and edited to cater to AWS security standards
Use AWS Trusted Advisor to know the exact reason for this error and take action as recommended by the Trusted Advisor
AWS Directory Service might have been initiated from an account that does not have proper permissions. Check the permissions on the IAM roles and IAM users used to initiate the service
These three options contradict the explanation provided above, so these options are incorrect.
Reference:
Explanation
Correct option:
Ignore or suppress the red flag since it is safe to do so, in this scenario - AWS Directory Services is a managed service that automatically creates an AWS security group in your VPC with network rules for traffic in and out of AWS managed domain controllers. The default inbound rules allow traffic from any source (0.0.0.0/0) to ports required by Active Directory. These rules do not introduce security vulnerabilities, as traffic to the domain controllers is limited to traffic from your VPC, other peered VPCs, or networks connected using AWS Direct Connect, AWS Transit Gateway or Virtual Private Network.
In addition, the ENIs the security group is attached to, do not and cannot have Elastic IPs attached to them, limiting inbound traffic to local VPC and VPC routed traffic.
Incorrect options:
The security group configurations have to be checked and edited to cater to AWS security standards
Use AWS Trusted Advisor to know the exact reason for this error and take action as recommended by the Trusted Advisor
AWS Directory Service might have been initiated from an account that does not have proper permissions. Check the permissions on the IAM roles and IAM users used to initiate the service
These three options contradict the explanation provided above, so these options are incorrect.
Reference:


