Certified Associate Developer for Apache Spark Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 11 Single Choice
Which of the following statements about RDDs is incorrect?
Explanation

Click "Show Answer" to see the explanation here
An RDD consists of a single partition.
Quite the opposite: Spark partitions RDDs and distributes the partitions across multiple nodes.
Explanation
An RDD consists of a single partition.
Quite the opposite: Spark partitions RDDs and distributes the partitions across multiple nodes.
Question 12 Single Choice
Which of the elements that are labeled with a circle and a number contain an error or are misrepresented?

Explanation
Click "Show Answer" to see the explanation here
1
Correct – This should just read "API" or "DataFrame API". The DataFrame is not part of the SQL API. To make a DataFrame accessible via SQL, you first need to create a DataFrame view. That view can then be accessed via SQL.
4
Although "K_38_INU" looks odd, it is a completely valid name for a DataFrame column.
6
No, StringType is a correct type.
7
Although a StringType may not be the most efficient way to store a phone number, there is nothing fundamentally wrong with using this type here.
8
Correct – TreeType is not a type that Spark supports.
9
No, Spark DataFrames support ArrayType variables. In this case, the variable would represent a sequence of elements with type LongType, which is also a valid type for Spark DataFrames.
10
There is nothing wrong with this row.
More info: Data Types - Spark 3.1.1 Documentation
Explanation
1
Correct – This should just read "API" or "DataFrame API". The DataFrame is not part of the SQL API. To make a DataFrame accessible via SQL, you first need to create a DataFrame view. That view can then be accessed via SQL.
4
Although "K_38_INU" looks odd, it is a completely valid name for a DataFrame column.
6
No, StringType is a correct type.
7
Although a StringType may not be the most efficient way to store a phone number, there is nothing fundamentally wrong with using this type here.
8
Correct – TreeType is not a type that Spark supports.
9
No, Spark DataFrames support ArrayType variables. In this case, the variable would represent a sequence of elements with type LongType, which is also a valid type for Spark DataFrames.
10
There is nothing wrong with this row.
More info: Data Types - Spark 3.1.1 Documentation
Question 13 Single Choice
Which of the following describes characteristics of the Spark UI?
Explanation
Click "Show Answer" to see the explanation here
There is a place in the Spark UI that shows the property spark.executor.memory.
Correct, you can see Spark properties such as spark.executor.memory in the Environment tab.
Some of the tabs in the Spark UI are named Jobs, Stages, Storage, DAGs, Executors, and SQL.
Wrong – Jobs, Stages, Storage, Executors, and SQL are all tabs in the Spark UI. DAGs can be inspected in the "Jobs" tab in the job details or in the Stages or SQL tab, but are not a separate tab.
Via the Spark UI, workloads can be manually distributed across distributors.
No, the Spark UI is meant for inspecting the inner workings of Spark which ultimately helps understand, debug, and optimize Spark transactions.
Via the Spark UI, stage execution speed can be modified.
No, see above.
The Scheduler tab shows how jobs that are run in parallel by multiple users are distributed across the cluster.
No, there is no Scheduler tab.
Explanation
There is a place in the Spark UI that shows the property spark.executor.memory.
Correct, you can see Spark properties such as spark.executor.memory in the Environment tab.
Some of the tabs in the Spark UI are named Jobs, Stages, Storage, DAGs, Executors, and SQL.
Wrong – Jobs, Stages, Storage, Executors, and SQL are all tabs in the Spark UI. DAGs can be inspected in the "Jobs" tab in the job details or in the Stages or SQL tab, but are not a separate tab.
Via the Spark UI, workloads can be manually distributed across distributors.
No, the Spark UI is meant for inspecting the inner workings of Spark which ultimately helps understand, debug, and optimize Spark transactions.
Via the Spark UI, stage execution speed can be modified.
No, see above.
The Scheduler tab shows how jobs that are run in parallel by multiple users are distributed across the cluster.
No, there is no Scheduler tab.
Question 14 Single Choice
Which of the following is a viable way to improve Spark's performance when dealing with large amounts of data, given that there is only a single application running on the cluster?
Explanation
Click "Show Answer" to see the explanation here
Decrease values for the properties spark.default.parallelism and spark.sql.partitions
No, these values need to be increased.
Increase values for the properties spark.sql.parallelism and spark.sql.partitions
Wrong, there is no property spark.sql.parallelism.
Increase values for the properties spark.sql.parallelism and spark.sql.shuffle.partitions
See above.
Increase values for the properties spark.dynamicAllocation.maxExecutors, spark.default.parallelism, and spark.sql.shuffle.partitions
The property spark.dynamicAllocation.maxExecutors is only in effect if dynamic allocation is enabled, using the spark.dynamicAllocation.enabled property. It is disabled by default. Dynamic allocation can be useful when running multiple applications on the same cluster in parallel. However, in this case there is only a single application running on the cluster, so enabling dynamic allocation would not yield a performance benefit.
More info: Practical Spark Tips For Data Scientists | Experfy.com and Basics of Apache Spark Configuration Settings | by Halil Ertan | Towards Data Science
Explanation
Decrease values for the properties spark.default.parallelism and spark.sql.partitions
No, these values need to be increased.
Increase values for the properties spark.sql.parallelism and spark.sql.partitions
Wrong, there is no property spark.sql.parallelism.
Increase values for the properties spark.sql.parallelism and spark.sql.shuffle.partitions
See above.
Increase values for the properties spark.dynamicAllocation.maxExecutors, spark.default.parallelism, and spark.sql.shuffle.partitions
The property spark.dynamicAllocation.maxExecutors is only in effect if dynamic allocation is enabled, using the spark.dynamicAllocation.enabled property. It is disabled by default. Dynamic allocation can be useful when running multiple applications on the same cluster in parallel. However, in this case there is only a single application running on the cluster, so enabling dynamic allocation would not yield a performance benefit.
More info: Practical Spark Tips For Data Scientists | Experfy.com and Basics of Apache Spark Configuration Settings | by Halil Ertan | Towards Data Science
Question 15 Single Choice
Which of the following describes a shuffle?
Explanation
Click "Show Answer" to see the explanation here
A shuffle is a process that compares data between partitions.
This is correct. During a shuffle, data is compared between partitions because shuffling includes the process of sorting. For sorting, data need to be compared. Since per definition, more than one partition is involved in a shuffle, it can be said that data is compared across partitions. You can read more about the technical details of sorting in the blog post linked below.
A shuffle is a Spark operation that results from DataFrame.coalesce().
No. DataFrame.coalesce() does not result in a shuffle.
A shuffle is a process that allocates partitions to executors.
This is incorrect. A shuffle is not allocating partitions to executors, this happens in a different process in Spark.
A shuffle is a process that is executed during a broadcast hash join.
No, broadcast hash joins avoid shuffles and yield performance benefits if at least one of the two tables is small in size (<= 10 MB by default). Broadcast hash joins can avoid shuffles because instead of exchanging partitions between executors, they broadcast a small table to all executors that then perform the rest of the join operation locally.
A shuffle is a process that compares data across executors.
No, in a shuffle, data is compared across partitions, and not executors.
More info:
- Spark Repartition & Coalesce - Explained
- Spark Architecture: Shuffle | Distributed Systems Architecture
Explanation
A shuffle is a process that compares data between partitions.
This is correct. During a shuffle, data is compared between partitions because shuffling includes the process of sorting. For sorting, data need to be compared. Since per definition, more than one partition is involved in a shuffle, it can be said that data is compared across partitions. You can read more about the technical details of sorting in the blog post linked below.
A shuffle is a Spark operation that results from DataFrame.coalesce().
No. DataFrame.coalesce() does not result in a shuffle.
A shuffle is a process that allocates partitions to executors.
This is incorrect. A shuffle is not allocating partitions to executors, this happens in a different process in Spark.
A shuffle is a process that is executed during a broadcast hash join.
No, broadcast hash joins avoid shuffles and yield performance benefits if at least one of the two tables is small in size (<= 10 MB by default). Broadcast hash joins can avoid shuffles because instead of exchanging partitions between executors, they broadcast a small table to all executors that then perform the rest of the join operation locally.
A shuffle is a process that compares data across executors.
No, in a shuffle, data is compared across partitions, and not executors.
More info:
- Spark Repartition & Coalesce - Explained
- Spark Architecture: Shuffle | Distributed Systems Architecture
Question 16 Single Choice
Which of the following describes Spark's Adaptive Query Execution?
Explanation
Click "Show Answer" to see the explanation here
Adaptive Query Execution features include dynamically coalescing shuffle partitions, dynamically injecting scan filters, and dynamically optimizing skew joins.
This is almost correct. All of these features, except for dynamically injecting scan filters, are part of Adaptive Query Execution. Dynamically injecting scan filters for join operations to limit the amount of data to be considered in a query is part of Dynamic Partition Pruning and not of Adaptive Query Execution.
Adaptive Query Execution reoptimizes queries at execution points.
No, Adaptive Query Execution reoptimizes queries continuously during query execution, not just at specific points.
Adaptive Query Execution is enabled in Spark by default.
No, Adaptive Query Execution is disabled in Spark needs to be enabled through the spark.sql.adaptive.enabled property.
Adaptive Query Execution applies to all kinds of queries.
No, Adaptive Query Execution applies only to queries that are not streaming queries and that contain at least one exchange (typically expressed through a join, aggregate, or window operator) or one subquery.
More info: How to Speed up SQL Queries with Adaptive Query Execution, Learning Spark, 2nd Edition, Chapter 12
Explanation
Adaptive Query Execution features include dynamically coalescing shuffle partitions, dynamically injecting scan filters, and dynamically optimizing skew joins.
This is almost correct. All of these features, except for dynamically injecting scan filters, are part of Adaptive Query Execution. Dynamically injecting scan filters for join operations to limit the amount of data to be considered in a query is part of Dynamic Partition Pruning and not of Adaptive Query Execution.
Adaptive Query Execution reoptimizes queries at execution points.
No, Adaptive Query Execution reoptimizes queries continuously during query execution, not just at specific points.
Adaptive Query Execution is enabled in Spark by default.
No, Adaptive Query Execution is disabled in Spark needs to be enabled through the spark.sql.adaptive.enabled property.
Adaptive Query Execution applies to all kinds of queries.
No, Adaptive Query Execution applies only to queries that are not streaming queries and that contain at least one exchange (typically expressed through a join, aggregate, or window operator) or one subquery.
More info: How to Speed up SQL Queries with Adaptive Query Execution, Learning Spark, 2nd Edition, Chapter 12
Question 17 Single Choice
The code block displayed below contains an error. The code block is intended to join DataFrame itemsDf with the larger DataFrame transactionsDf on column itemId. Find the error.
Code block:
transactionsDf.join(itemsDf, "itemId", how="broadcast")
Explanation
Click "Show Answer" to see the explanation here
broadcast is not a valid join type.
Correct! The code block should read transactionsDf.join(broadcast(itemsDf), "itemId"). This would imply an inner join (this is the default in DataFrame.join()), but since the join type is not given in the question, this would be a valid choice.
The larger DataFrame transactionsDf is being broadcasted, rather than the smaller DataFrame itemsDf.
This option does not apply here, since the syntax around broadcasting is incorrect.
Spark will only perform the broadcast operation if this behavior has been enabled on the Spark cluster.
No, it is enabled by default, since the spark.sql.autoBroadcastJoinThreshold property is set to 10 MB by default. If that property would be set to -1, then broadcast joining would be disabled. More info: Performance Tuning - Spark 3.1.1 Documentation
The join method should be replaced by the broadcast method.
No, DataFrame has no broadcast() method.
The syntax is wrong, how= should be removed from the code block.
No, having the keyword argument how= is totally acceptable.
Explanation
broadcast is not a valid join type.
Correct! The code block should read transactionsDf.join(broadcast(itemsDf), "itemId"). This would imply an inner join (this is the default in DataFrame.join()), but since the join type is not given in the question, this would be a valid choice.
The larger DataFrame transactionsDf is being broadcasted, rather than the smaller DataFrame itemsDf.
This option does not apply here, since the syntax around broadcasting is incorrect.
Spark will only perform the broadcast operation if this behavior has been enabled on the Spark cluster.
No, it is enabled by default, since the spark.sql.autoBroadcastJoinThreshold property is set to 10 MB by default. If that property would be set to -1, then broadcast joining would be disabled. More info: Performance Tuning - Spark 3.1.1 Documentation
The join method should be replaced by the broadcast method.
No, DataFrame has no broadcast() method.
The syntax is wrong, how= should be removed from the code block.
No, having the keyword argument how= is totally acceptable.
Question 18 Single Choice
Which of the following code blocks efficiently converts DataFrame transactionsDf from 12 into 24 partitions?
Explanation
Click "Show Answer" to see the explanation here
transactionsDf.coalesce(24)
No, the coalesce() method can only reduce, but not increase the number of partitions.
transactionsDf.repartition()
No, repartition() requires a numPartitions argument.
transactionsDf.repartition("itemId", 24)
No, here the cols and numPartitions argument have been mixed up. If the code block would be transactionsDf.repartition(24, "itemId"), this would be a valid solution.
transactionsDf.repartition(24, boost=True)
No, there is no boost argument in the repartition() method.
Explanation
transactionsDf.coalesce(24)
No, the coalesce() method can only reduce, but not increase the number of partitions.
transactionsDf.repartition()
No, repartition() requires a numPartitions argument.
transactionsDf.repartition("itemId", 24)
No, here the cols and numPartitions argument have been mixed up. If the code block would be transactionsDf.repartition(24, "itemId"), this would be a valid solution.
transactionsDf.repartition(24, boost=True)
No, there is no boost argument in the repartition() method.
Question 19 Single Choice
Which of the following code blocks removes all rows in the 6-column DataFrame transactionsDf that have missing data in at least 3 columns?
Explanation
Click "Show Answer" to see the explanation here
transactionsDf.dropna(thresh=4)
Correct. Note that by only working with the thresh keyword argument, the first how keyword argument is ignored. Also, figuring out which value to set for thresh can be difficult, especially when under pressure in the exam. Here, I recommend you use the notes to create a "simulation" of what different values for thresh would do to a DataFrame. Here is an explanatory image why thresh=4 is the correct answer to the question:
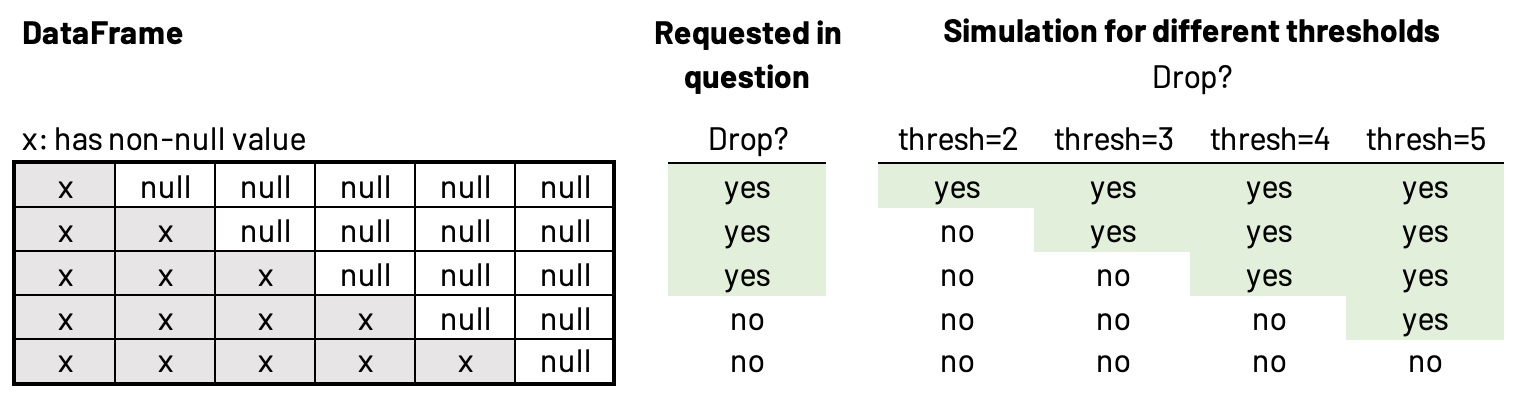
transactionsDf.dropna(thresh=2)
Almost right. See the comment about thresh for the correct answer above.
transactionsDf.dropna("any")
No, this would remove all rows that have at least one missing value.
transactionsDf.drop.na("",2)
No, drop.na is not a proper DataFrame method.
transactionsDf.dropna("",4)
No, this does not work and will throw an error in Spark because Spark cannot understand the first argument.
More info: pyspark.sql.DataFrame.dropna — PySpark 3.0.0 documentation
Explanation
transactionsDf.dropna(thresh=4)
Correct. Note that by only working with the thresh keyword argument, the first how keyword argument is ignored. Also, figuring out which value to set for thresh can be difficult, especially when under pressure in the exam. Here, I recommend you use the notes to create a "simulation" of what different values for thresh would do to a DataFrame. Here is an explanatory image why thresh=4 is the correct answer to the question:
transactionsDf.dropna(thresh=2)
Almost right. See the comment about thresh for the correct answer above.
transactionsDf.dropna("any")
No, this would remove all rows that have at least one missing value.
transactionsDf.drop.na("",2)
No, drop.na is not a proper DataFrame method.
transactionsDf.dropna("",4)
No, this does not work and will throw an error in Spark because Spark cannot understand the first argument.
More info: pyspark.sql.DataFrame.dropna — PySpark 3.0.0 documentation
Question 20 Single Choice
The code block displayed below contains an error. The code block should create DataFrame itemsAttributesDf which has columns itemId and attribute and lists every attribute from the attributes column in DataFrame itemsDf next to the itemId of the respective row in itemsDf. Find the error.
A sample of DataFrame itemsDf is below.
- +------+-----------------------------+-------------------+
- |itemId|attributes |supplier |
- +------+-----------------------------+-------------------+
- |1 |[blue, winter, cozy] |Sports Company Inc.|
- |2 |[red, summer, fresh, cooling]|YetiX |
- |3 |[green, summer, travel] |Sports Company Inc.|
- +------+-----------------------------+-------------------+
Code block:
itemsAttributesDf = itemsDf.explode("attributes").alias("attribute").select("attribute", "itemId")
Explanation
Click "Show Answer" to see the explanation here
The correct code block looks like this:
- from pyspark.sql.functions import explode
- itemsAttributesDf = itemsDf.select("itemId", explode("attributes").alias("attribute"))
Then, the first couple of rows of itemAttributesDf look like this:
- +------+---------+
- |itemId|attribute|
- +------+---------+
- | 1| blue|
- | 1| winter|
- | 1| cozy|
- | 2| red|
- +------+---------+
- only showing top 4 rows
explode() is not a method of DataFrame. explode() should be used inside the select() method instead.
This is correct.
The split() method should be used inside the select() method instead of the explode() method.
No, the split() method is used to split strings into parts. However, column attributs is an array of strings. In this case, the explode() method is appropriate.
Since itemId is the index, it does not need to be an argument to the select() method.
No, itemId still needs to be selected, whether it is used as an index or not.
The explode() method expects a Column object rather than a string.
No, a string works just fine here. This being said, there are some valid alternatives to passing in a string:
- itemsAttributesDf = itemsDf.select("itemId", explode(col("attributes")).alias("attribute"))
- itemsAttributesDf = itemsDf.select("itemId", explode(itemsDf.attributes).alias("attribute"))
- itemsAttributesDf = itemsDf.select("itemId", explode(itemsDf['attributes']).alias("attribute"))
The alias() method needs to be called after the select() method.
No.
More info: pyspark.sql.functions.explode — PySpark 3.0.0 documentation
Explanation
The correct code block looks like this:
- from pyspark.sql.functions import explode
- itemsAttributesDf = itemsDf.select("itemId", explode("attributes").alias("attribute"))
Then, the first couple of rows of itemAttributesDf look like this:
- +------+---------+
- |itemId|attribute|
- +------+---------+
- | 1| blue|
- | 1| winter|
- | 1| cozy|
- | 2| red|
- +------+---------+
- only showing top 4 rows
explode() is not a method of DataFrame. explode() should be used inside the select() method instead.
This is correct.
The split() method should be used inside the select() method instead of the explode() method.
No, the split() method is used to split strings into parts. However, column attributs is an array of strings. In this case, the explode() method is appropriate.
Since itemId is the index, it does not need to be an argument to the select() method.
No, itemId still needs to be selected, whether it is used as an index or not.
The explode() method expects a Column object rather than a string.
No, a string works just fine here. This being said, there are some valid alternatives to passing in a string:
- itemsAttributesDf = itemsDf.select("itemId", explode(col("attributes")).alias("attribute"))
- itemsAttributesDf = itemsDf.select("itemId", explode(itemsDf.attributes).alias("attribute"))
- itemsAttributesDf = itemsDf.select("itemId", explode(itemsDf['attributes']).alias("attribute"))
The alias() method needs to be called after the select() method.
No.
More info: pyspark.sql.functions.explode — PySpark 3.0.0 documentation


