
Microsoft Certified: Azure Database Administrator Associate - (DP-300) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 1 Single Choice
Identify the missing word(s) in the following sentence within the context of Microsoft Azure.
Database security can get complicated for applications with many users. In order to make it easier for both administrators and auditors, most database applications use role-based security.
Microsoft SQL Server contains several [?] within each database for which the permissions are predefined. Users can be added as members of one or more roles. These roles give their members a pre-defined set of permissions. These roles work the same within Azure SQL Database and SQL Server.
Explanation

Click "Show Answer" to see the explanation here
Database roles
Database security can get complicated for applications with many users. In order to make it easier for both administrators and auditors, most database applications use role-based security.
Roles are effectively security groups that share a common set of permissions. Combining permissions into a role allows a set of roles to be created for a given application.
Application roles
Application roles can be created within a SQL Server database or Azure SQL Database. Unlike database roles, users are not made members of an application role. An application role is activated by the user, by supplying the pre-configured password for the application role. Once the role is activated the permissions that are applied to the application role are applied to the user until that role is deactivated.
Built-in database roles
Microsoft SQL Server contains several fixed database roles within each database for which the permissions are predefined. Users can be added as members of one or more roles. These roles give their members a pre-defined set of permissions. These roles work the same within Azure SQL Database and SQL Server.
Users that need to create other users within the database can be granted membership in the role db_accessadmin. This role does not grant access to the schema of any of the tables, nor does it grant access to the data within the database.
Users that need to back up a database in a SQL Server or Managed Instance can be made members of the role db_backupoperator. The role db_backupoperator does not confer any permissions in an Azure SQL Database.
Users that need the ability to read from every table and view within the database can be made members of the role db_datareader.
Users that need the ability to INSERT, UPDATE, and DELETE data from every table and view within the database can be made members of the role db_datawriter.
Users who need the ability to create or modify objects within the database can be made members of the role db_ddladmin. Members of this role can change the definition of any object, of any type, but members of this role are not granted access to read or write any data within the databases.
The role db_denydatareader can be used for users who need to be prevented from reading data from any object in the database, when those users have been granted rights through other roles or directly.
The role db_denydatawriter can be used for users who need to be prevented from writing data to any object in the database, when those users have been granted rights through other roles or directly.
Users who need administrative access to the database can be made members of the role db_owner. Members of the db_owner role can perform any action within the database by default. However, unlike the actual database owner, who has the user name dbo, users in the db_owner role can be blocked from accessing data by placing them in other database roles, such as db_denydatareader, or by denying them access to objects. Membership in this database role should be limited to only trusted users.
Users who need to be able to grant access to other users within the database can be made members of the role db_securityadmin. Members of this role are not specifically granted access to the data within the database; however members of this role can grant themselves access to the tables within the database. Membership in this database role should be limited to only trusted users.
All users within a database are automatically members of the public role. By default, this role has no permissions granted to it. Permissions can be granted to the public role, but you should consider carefully whether that is really something you want to do. Granting permissions to the public role would grant these permissions to any user, including the guest account, if the guest account was enabled.
Explanation
Database roles
Database security can get complicated for applications with many users. In order to make it easier for both administrators and auditors, most database applications use role-based security.
Roles are effectively security groups that share a common set of permissions. Combining permissions into a role allows a set of roles to be created for a given application.
Application roles
Application roles can be created within a SQL Server database or Azure SQL Database. Unlike database roles, users are not made members of an application role. An application role is activated by the user, by supplying the pre-configured password for the application role. Once the role is activated the permissions that are applied to the application role are applied to the user until that role is deactivated.
Built-in database roles
Microsoft SQL Server contains several fixed database roles within each database for which the permissions are predefined. Users can be added as members of one or more roles. These roles give their members a pre-defined set of permissions. These roles work the same within Azure SQL Database and SQL Server.
Users that need to create other users within the database can be granted membership in the role db_accessadmin. This role does not grant access to the schema of any of the tables, nor does it grant access to the data within the database.
Users that need to back up a database in a SQL Server or Managed Instance can be made members of the role db_backupoperator. The role db_backupoperator does not confer any permissions in an Azure SQL Database.
Users that need the ability to read from every table and view within the database can be made members of the role db_datareader.
Users that need the ability to INSERT, UPDATE, and DELETE data from every table and view within the database can be made members of the role db_datawriter.
Users who need the ability to create or modify objects within the database can be made members of the role db_ddladmin. Members of this role can change the definition of any object, of any type, but members of this role are not granted access to read or write any data within the databases.
The role db_denydatareader can be used for users who need to be prevented from reading data from any object in the database, when those users have been granted rights through other roles or directly.
The role db_denydatawriter can be used for users who need to be prevented from writing data to any object in the database, when those users have been granted rights through other roles or directly.
Users who need administrative access to the database can be made members of the role db_owner. Members of the db_owner role can perform any action within the database by default. However, unlike the actual database owner, who has the user name dbo, users in the db_owner role can be blocked from accessing data by placing them in other database roles, such as db_denydatareader, or by denying them access to objects. Membership in this database role should be limited to only trusted users.
Users who need to be able to grant access to other users within the database can be made members of the role db_securityadmin. Members of this role are not specifically granted access to the data within the database; however members of this role can grant themselves access to the tables within the database. Membership in this database role should be limited to only trusted users.
All users within a database are automatically members of the public role. By default, this role has no permissions granted to it. Permissions can be granted to the public role, but you should consider carefully whether that is really something you want to do. Granting permissions to the public role would grant these permissions to any user, including the guest account, if the guest account was enabled.
Question 2 Single Choice
You need to migrate a set of databases that use distributed transactions from on-premises SQL Server. Which of the following options should you choose?
Explanation
Click "Show Answer" to see the explanation here
Azure SQL Managed Instance is the only offering here that supports cross-database transactions.
Azure SQL Managed Instance is the intelligent, scalable cloud database service that combines the broadest SQL Server database engine compatibility with all the benefits of a fully managed and evergreen platform as a service. SQL Managed Instance has near 100% compatibility with the latest SQL Server (Enterprise Edition) database engine, providing a native virtual network (VNet) implementation that addresses common security concerns, and a business model favorable for existing SQL Server customers. SQL Managed Instance allows existing SQL Server customers to lift and shift their on-premises applications to the cloud with minimal application and database changes. At the same time, SQL Managed Instance preserves all PaaS capabilities (automatic patching and version updates, automated backups, high availability) that drastically reduce management overhead and TCO.
Explanation
Azure SQL Managed Instance is the only offering here that supports cross-database transactions.
Azure SQL Managed Instance is the intelligent, scalable cloud database service that combines the broadest SQL Server database engine compatibility with all the benefits of a fully managed and evergreen platform as a service. SQL Managed Instance has near 100% compatibility with the latest SQL Server (Enterprise Edition) database engine, providing a native virtual network (VNet) implementation that addresses common security concerns, and a business model favorable for existing SQL Server customers. SQL Managed Instance allows existing SQL Server customers to lift and shift their on-premises applications to the cloud with minimal application and database changes. At the same time, SQL Managed Instance preserves all PaaS capabilities (automatic patching and version updates, automated backups, high availability) that drastically reduce management overhead and TCO.
Question 3 Single Choice
Consider SQL Server high availability and disaster recovery (HADR) architectures in Azure.
Which method is described below?
Will work with more than just SQL Server.
May meet RTO and possibly RPO.
Provided as part of the Azure platform.
Explanation
Click "Show Answer" to see the explanation here
SQL Server high availability and disaster recovery (HADR) architectures in Azure.
Disaster Recovery– Azure Site Recovery
For those who do not want to implement a SQL Server-based disaster solution, Azure Site Recovery is a potential option. However, most data professionals prefer a database-centric approach as it will generally have a lower RPO.
The image below, from the Microsoft documentation. shows where in the Azure portal you would configure replication for Azure Site Recovery.
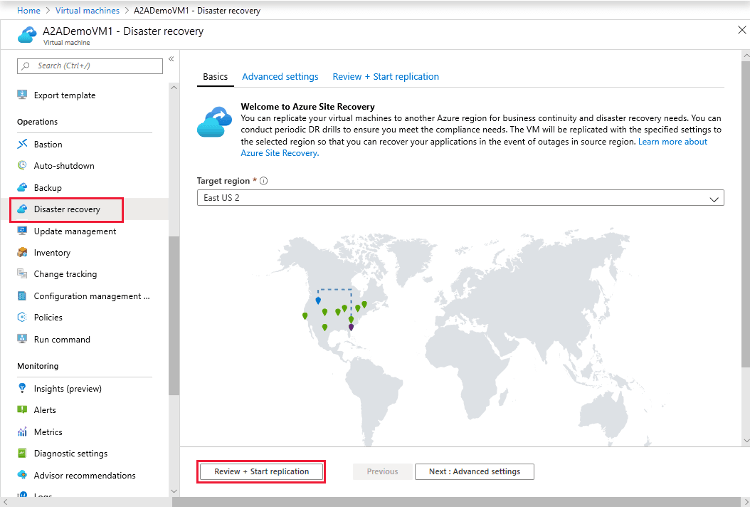
Why is this architecture worth considering?
Azure Site Recovery will work with more than just SQL Server.
Azure Site Recovery may meet RTO and possibly RPO.
Azure Site Recovery is provided as part of the Azure platform.
Explanation
SQL Server high availability and disaster recovery (HADR) architectures in Azure.
Disaster Recovery– Azure Site Recovery
For those who do not want to implement a SQL Server-based disaster solution, Azure Site Recovery is a potential option. However, most data professionals prefer a database-centric approach as it will generally have a lower RPO.
The image below, from the Microsoft documentation. shows where in the Azure portal you would configure replication for Azure Site Recovery.
Why is this architecture worth considering?
Azure Site Recovery will work with more than just SQL Server.
Azure Site Recovery may meet RTO and possibly RPO.
Azure Site Recovery is provided as part of the Azure platform.
Question 4 Single Choice
Scenario: You are working as a consultant at Advanced Idea Mechanics (A.I.M.) who is a privately funded think tank organized of a group of brilliant scientists whose sole dedication is to acquire and develop power through technological means. Their goal is to use this power to overthrow the governments of the world. They supply arms and technology to radicals and subversive organizations in order to foster a violent technological revolution of society while making a profit.
The company has 10,000 employees. Most employees are located in Europe. The company supports teams worldwide.
AIM has two main locations: the main office in London, England, and a manufacturing plant in Berlin, Germany.
At the moment, you are leading a Workgroup meeting with the IT Team where the topic of discussion is Temporal Tables.
What functionality do Temporal Tables provide with Azure SQL Database?
Explanation
Click "Show Answer" to see the explanation here
The Temporal Table feature allows you to use the history table to recover data that may have been deleted or updated.
Azure SQL Database allows you to track and analyze the changes to your data using a feature called Temporal Tables. This feature requires that the tables themselves be converted to be temporal, which means the table will have special properties and will also have a corresponding history table. The Temporal Table feature allows you to use the history table to recover data that may have been deleted or updated. Recovering data from the history table is a manual process involving Transact-SQL, but could be helpful in certain scenarios such as if a user accidentally deletes important data that the business needs.
Another method to increase availability for Azure SQL Database is to use active geo-replication. Active geo-replication creates a replica of the database in another region that is asynchronously kept up to date. That replica is also readable, similar to an AG in IaaS. Underneath the surface, Azure is using the same methods as an AG, which is why some of the terminology and functionality is similar(primary and secondary logical servers, read-only databases, etc.).
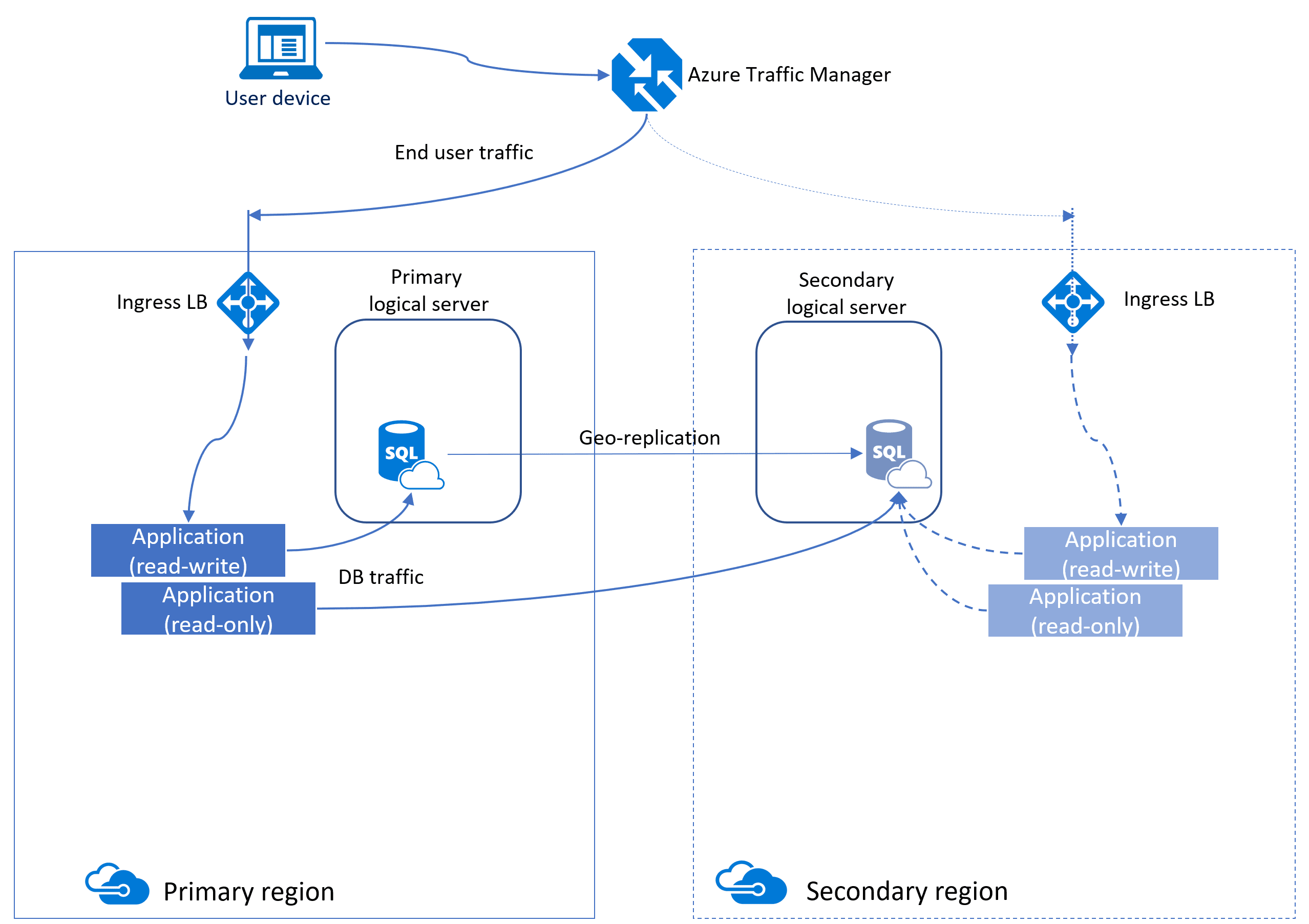
Auto-failover groups for Azure SQL Database and Azure SQL Database Managed Instance
An auto-failover group is an availability feature that can be used with both Azure SQL Database and Azure SQL Database Managed Instance. Autofailover groups let you manage how databases on an Azure SQL Database server or databases in Azure SQL Database Managed Instance are replicated to another region, and let you manage how failover could happen. The name assigned to the autofailover group must be unique within the *.database.windows.net domain. Azure SQL Database Managed Instance only supports one autofailover group.
Autofailover groups provide AG-like functionality called a listener, which allows both read-write and read-only activity. This functionality can be seen in the image below which is slightly different than the one for active geo-replication. There are two different kinds of listeners: one for read-write and one for read-only traffic. Behind the scenes in a failover, DNS is updated so clients will be able to point to the abstracted listener name and not need to know anything else. The database server containing the read-write copies is the primary, and the server that is receiving the transactions from the primary is a secondary.
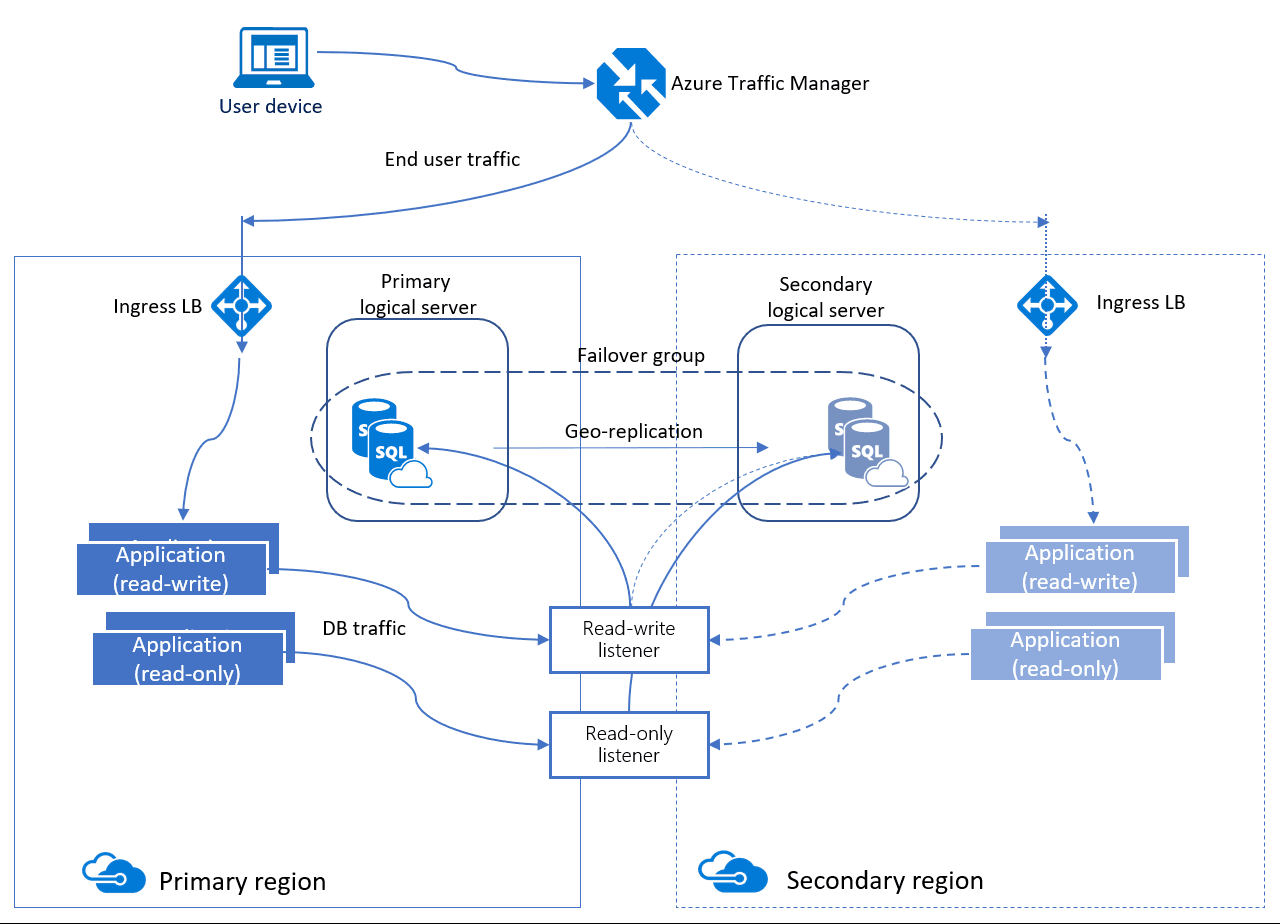
When it comes to fail over, autofailover groups have two different policies that can be configured.
Automatic – By default, when a failure occurs and it is determined that a failover must happen, the autofailover group will switch regions. The ability to fail over automatically can be disabled.
Read-Only – By default, if a failover occurs, the read-only listener is disabled to ensure performance of the new primary when the secondary is down. This behavior can be changed so that both types of traffic are enabled after a failover.
Failovers can be performed manually even if automatic failover is allowed. Depending on the type of failover, there could be data loss. Unplanned failovers could result in data loss if forced and the secondary is not fully synchronized with the primary. Configuring GracePeriodWithDataLossHours controls how long Azure waits before failing over. The default is one hour. If you have a tight RPO and cannot afford much data loss, set the value higher so Azure will wait longer before failing over, hopefully resulting in less data loss.
One autofailover group can contain one or more databases. The database size and edition will be the same on both the primary and secondary. The database is created automatically on the secondary through a process called seeding. Depending on the size of the database, this may take some time. Ensure that you plan accordingly and that you take into account things like the speed of the network.
Explanation
The Temporal Table feature allows you to use the history table to recover data that may have been deleted or updated.
Azure SQL Database allows you to track and analyze the changes to your data using a feature called Temporal Tables. This feature requires that the tables themselves be converted to be temporal, which means the table will have special properties and will also have a corresponding history table. The Temporal Table feature allows you to use the history table to recover data that may have been deleted or updated. Recovering data from the history table is a manual process involving Transact-SQL, but could be helpful in certain scenarios such as if a user accidentally deletes important data that the business needs.
Another method to increase availability for Azure SQL Database is to use active geo-replication. Active geo-replication creates a replica of the database in another region that is asynchronously kept up to date. That replica is also readable, similar to an AG in IaaS. Underneath the surface, Azure is using the same methods as an AG, which is why some of the terminology and functionality is similar(primary and secondary logical servers, read-only databases, etc.).
Auto-failover groups for Azure SQL Database and Azure SQL Database Managed Instance
An auto-failover group is an availability feature that can be used with both Azure SQL Database and Azure SQL Database Managed Instance. Autofailover groups let you manage how databases on an Azure SQL Database server or databases in Azure SQL Database Managed Instance are replicated to another region, and let you manage how failover could happen. The name assigned to the autofailover group must be unique within the *.database.windows.net domain. Azure SQL Database Managed Instance only supports one autofailover group.
Autofailover groups provide AG-like functionality called a listener, which allows both read-write and read-only activity. This functionality can be seen in the image below which is slightly different than the one for active geo-replication. There are two different kinds of listeners: one for read-write and one for read-only traffic. Behind the scenes in a failover, DNS is updated so clients will be able to point to the abstracted listener name and not need to know anything else. The database server containing the read-write copies is the primary, and the server that is receiving the transactions from the primary is a secondary.
When it comes to fail over, autofailover groups have two different policies that can be configured.
Automatic – By default, when a failure occurs and it is determined that a failover must happen, the autofailover group will switch regions. The ability to fail over automatically can be disabled.
Read-Only – By default, if a failover occurs, the read-only listener is disabled to ensure performance of the new primary when the secondary is down. This behavior can be changed so that both types of traffic are enabled after a failover.
Failovers can be performed manually even if automatic failover is allowed. Depending on the type of failover, there could be data loss. Unplanned failovers could result in data loss if forced and the secondary is not fully synchronized with the primary. Configuring GracePeriodWithDataLossHours controls how long Azure waits before failing over. The default is one hour. If you have a tight RPO and cannot afford much data loss, set the value higher so Azure will wait longer before failing over, hopefully resulting in less data loss.
One autofailover group can contain one or more databases. The database size and edition will be the same on both the primary and secondary. The database is created automatically on the secondary through a process called seeding. Depending on the size of the database, this may take some time. Ensure that you plan accordingly and that you take into account things like the speed of the network.
Question 5 Single Choice
Colloquially speaking, security principal assignment answers to a question ...
Explanation
Click "Show Answer" to see the explanation here
Security Principal assignment is an answer to the question “Who can do it?”
Explanation
Security Principal assignment is an answer to the question “Who can do it?”
Question 6 Single Choice
When securing a network for Azure SQL Database, there are four main choices. If you choose this option, you can connect to your database in SQL Database and several other platform as a service offerings by using a confidential endpoint. This means that it has an exclusive IP address within a specific virtual network.
Explanation
Click "Show Answer" to see the explanation here
Azure SQL Database
When you're securing your network for Azure SQL Database, you have four main choices:
Allow access to Azure services
Use firewall rules
Use virtual network rules
Use Azure Private Link
In addition to these main choices, you have the opportunity to block all public access (only with Private Link) and the option to force a minimum Transport Layer Security (TLS) version. The least secure method, but the easiest to configure, is to allow access to Azure services. The most secure method is to use Private Link.
Allow access to Azure services
During the deployment of Azure SQL Database, you have the option to set Allow Azure services and resources access to this server to Yes. If you choose this option, you're allowing any resource from any region or subscription the possibility to access your resource. This option makes it easy to get up and running and get Azure SQL Database connected to other services, such as Azure Virtual Machines, Azure App Service, or even Azure Cloud Shell, because you're allowing anything that comes through Azure to have the potential to connect.
Virtual Network Rules
If you want to use only firewall rules, setting this up can be complicated. It means that you'll have to specify a range of IP addresses for all your connections, which can sometimes have dynamic IP addresses. A much easier alternative is to use virtual network rules to establish and manage access from specific networks that contain VMs or other services that need to access the data.
If you configure access from a virtual network with a virtual network rule, any resources in that virtual network can access the Azure SQL Database logical server. This can simplify the challenge of configuring access to all static and dynamic IP addresses that need to access the data. By using virtual network rules, you can specify one or more virtual networks, encompassing all the resources within them. You can also start to apply virtual network technologies to connect networks across regions in both Azure and on-premises.
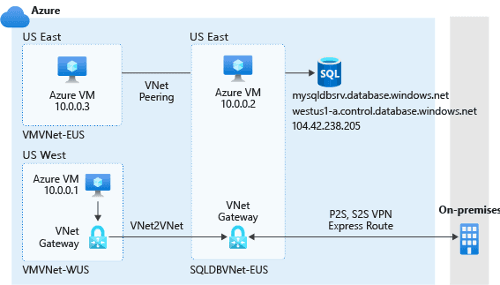
Private Link for an Azure SQL Database Instance
You've seen how to configure the most secure network by using your database in Azure SQL Database with the public endpoint, which is similar to the way that your Azure SQL managed instance is deployed. This method of securing a database in SQL Database has been used for years. However, in 2019, Azure began moving toward a concept of a private link, which is more like the way that Azure SQL Managed Instance is deployed. With Private Link, you can connect to your database in SQL Database and several other platform as a service offerings by using a private endpoint. This means that it has a private IP address within a specific virtual network.
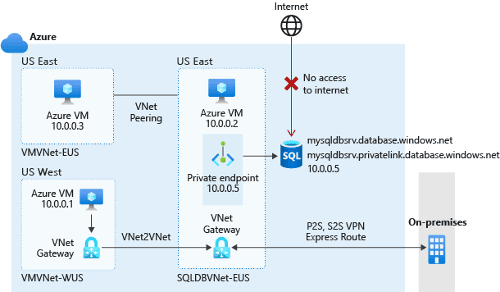
An Azure SQL Managed Instance
Although deploying an Azure SQL managed instance differs from deploying a database in SQL Database, it's easy to translate networking functionality at a high level from one to the other. For an Azure SQL managed instance, either before or during deployment, you must create a specific subnet, or logical grouping within a virtual network, with several requirements to host the managed instances. After they're deployed, they're already configured similar to a private endpoint in a database in SQL Database. By using standard networking practices, you must enable access to the virtual network where the managed instance lives. By default, you have a private endpoint and relatively private DNS hierarchy.
Explanation
Azure SQL Database
When you're securing your network for Azure SQL Database, you have four main choices:
Allow access to Azure services
Use firewall rules
Use virtual network rules
Use Azure Private Link
In addition to these main choices, you have the opportunity to block all public access (only with Private Link) and the option to force a minimum Transport Layer Security (TLS) version. The least secure method, but the easiest to configure, is to allow access to Azure services. The most secure method is to use Private Link.
Allow access to Azure services
During the deployment of Azure SQL Database, you have the option to set Allow Azure services and resources access to this server to Yes. If you choose this option, you're allowing any resource from any region or subscription the possibility to access your resource. This option makes it easy to get up and running and get Azure SQL Database connected to other services, such as Azure Virtual Machines, Azure App Service, or even Azure Cloud Shell, because you're allowing anything that comes through Azure to have the potential to connect.
Virtual Network Rules
If you want to use only firewall rules, setting this up can be complicated. It means that you'll have to specify a range of IP addresses for all your connections, which can sometimes have dynamic IP addresses. A much easier alternative is to use virtual network rules to establish and manage access from specific networks that contain VMs or other services that need to access the data.
If you configure access from a virtual network with a virtual network rule, any resources in that virtual network can access the Azure SQL Database logical server. This can simplify the challenge of configuring access to all static and dynamic IP addresses that need to access the data. By using virtual network rules, you can specify one or more virtual networks, encompassing all the resources within them. You can also start to apply virtual network technologies to connect networks across regions in both Azure and on-premises.
Private Link for an Azure SQL Database Instance
You've seen how to configure the most secure network by using your database in Azure SQL Database with the public endpoint, which is similar to the way that your Azure SQL managed instance is deployed. This method of securing a database in SQL Database has been used for years. However, in 2019, Azure began moving toward a concept of a private link, which is more like the way that Azure SQL Managed Instance is deployed. With Private Link, you can connect to your database in SQL Database and several other platform as a service offerings by using a private endpoint. This means that it has a private IP address within a specific virtual network.
An Azure SQL Managed Instance
Although deploying an Azure SQL managed instance differs from deploying a database in SQL Database, it's easy to translate networking functionality at a high level from one to the other. For an Azure SQL managed instance, either before or during deployment, you must create a specific subnet, or logical grouping within a virtual network, with several requirements to host the managed instances. After they're deployed, they're already configured similar to a private endpoint in a database in SQL Database. By using standard networking practices, you must enable access to the virtual network where the managed instance lives. By default, you have a private endpoint and relatively private DNS hierarchy.
Question 7 Single Choice
Scenario: You are working as a consultant at Advanced Idea Mechanics (A.I.M.) who is a privately funded think tank organized of a group of brilliant scientists whose sole dedication is to acquire and develop power through technological means. Their goal is to use this power to overthrow the governments of the world. They supply arms and technology to radicals and subversive organizations in order to foster a violent technological revolution of society while making a profit.
The company has 10,000 employees. Most employees are located in Europe. The company supports teams worldwide.
AIM has two main locations: the main office in London, England, and a manufacturing plant in Berlin, Germany.
At the moment, you are leading a Workgroup meeting with the IT Team where the topic of discussion is Azure configuration of AG properties.
Which of the following components needs to be configured in Azure for the listener in an AG to work properly?
Explanation
Click "Show Answer" to see the explanation here
The listener requires the creation of an Azure load balancer and has some additional configuration in the WSFC related to the load balancer.
For all availability configurations of availability groups (AGs), an underlying cluster is required, whether or not it uses AD DS. By the end of this unit, you will understand the considerations for deploying an AG in Azure.
Considerations for Always On availability groups in Azure
Configuring an AG is nearly the same in Azure as it is on premises as are most of the considerations, such as how to initialize secondary replicas. Most of the Azure-specific considerations were discussed earlier, such as needing an ILB. Same as the WSFC itself, you cannot reserve the listener’s IP address in Azure so you need to ensure something else does not come along and grab it otherwise there could be a conflict on the network, which in turn could cause availability headaches.
Do not place any permanent database on the ephemeral storage. All virtual machines (VMs) that are participating in an AG should have the same storage configuration. You must size disks appropriately for performance depending on the application workload.
Before an AG can be configured, the AG feature must be enabled. This can be done in SQL Server Configuration Manager as shown in the image below or via PowerShell with the cmdlet Enable-SqlAlwaysOn. Enabling the AG feature will require a stop and start of the SQL Server service.
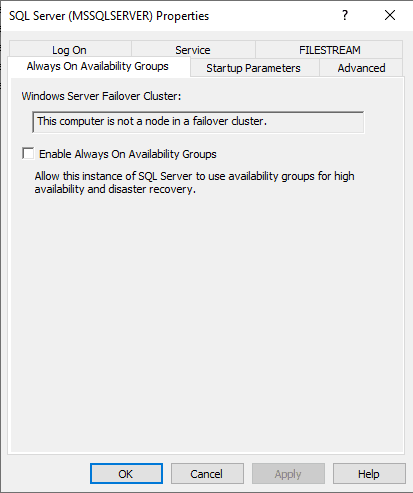
Create the Availability group
Creating an AG in Azure is the same as it is on premises. SQL Server Management Studio (SSMS), T-SQL, or PowerShell can be used.
The only difference is that whether or not you create the listener as part of the initial AG configuration, as the listener requires the creation of an Azure load balancer and has some additional configuration in the WSFC related to the load balancer.
Create an Internal Azure load balancer
Once the listener is created, an internal load balancer (ILB) must be used. Without configuring an ILB, applications, end users, administrators, and others cannot use the listener unless they were connected to the VM that hosts an AG’s primary replica.
You can use a basic or a standard load balancer depending on your preference or configuration. Deployments using Availability Zones require the use of a standard load balancer. The listener IP address and the port used for the listener are what is configured as part of the load balancer. A single load balancer supports more than one IP address, so depending on your standards, you may not need a different load balancer for each AG configured on those nodes.
Another consideration for the load balancer is the probe port. Without the probe port, the listener will not work properly as it is not enough just to create the load balancer. Each IP address that will use the load balancer requires a unique probe port. If there are going to be two listeners, there must be two probe ports. Probe ports are high numbers such as 59999.
The probe port is set on the IP address(es) associated with the listener with the following syntax:
- PowerShell
- Get-ClusterResource IPAddressResourceNameForListener | Set-ClusterParameter ProbePort PortNumber
Adding the probe port will require a stop and start of the IP address of the listener, which will also temporarily cause the AG to be brought offline, so it is best to get this configured before deploying in production.
If you have a multi-subnet configuration, a load balancer will need to be configured in each subnet (whether or not the other subnet is deployed to different region) and the probe port for that region associated with the IP resource for that subnet in the WSFC.
Without directly connecting to the listener, the only way to ensure that the listener is configured correctly is to use the PowerShell cmdlet Test-NetConnection with the specific port. The syntax is as follows:
- PowerShell
- Test-NetConnection NameOrIPAddress -Port PortNumber
You should run this command from somewhere other than the VM that is hosting the primary replica.
Some environments may also require that the IP address for the WSFC and selected ports (such as 445) must be accessible for administration or other purposes, which mean configuring those as part of the same or a different load balancer.
Once the load balancer is confirmed to be working, you can begin to test AG failover and connectivity to the AG via the listener.
Distributed availability groups
Planning for and configuring a distributed AG is the same on premises as it is in Azure, with any Azure-specific considerations for the individual AGs. The main difference between an on-premises configuration and an Azure configuration for a distributed AG is that as part of the load balancer configuration in each region, the endpoint port for the AG needs to be added. The default port is 5022.
Azure Site Recovery
Azure Site Recovery is an option that work with the Virtual Machine, whether or not SQL Server is running inside of it. It works with SQL Server but is not designed specifically to account for nuances that may be required when you have a specific RPO. The disks of a VM configured to use Azure Site Recovery are replicated to another region. This replication can be seen in the image below, noted by the “Data flow” arrow.
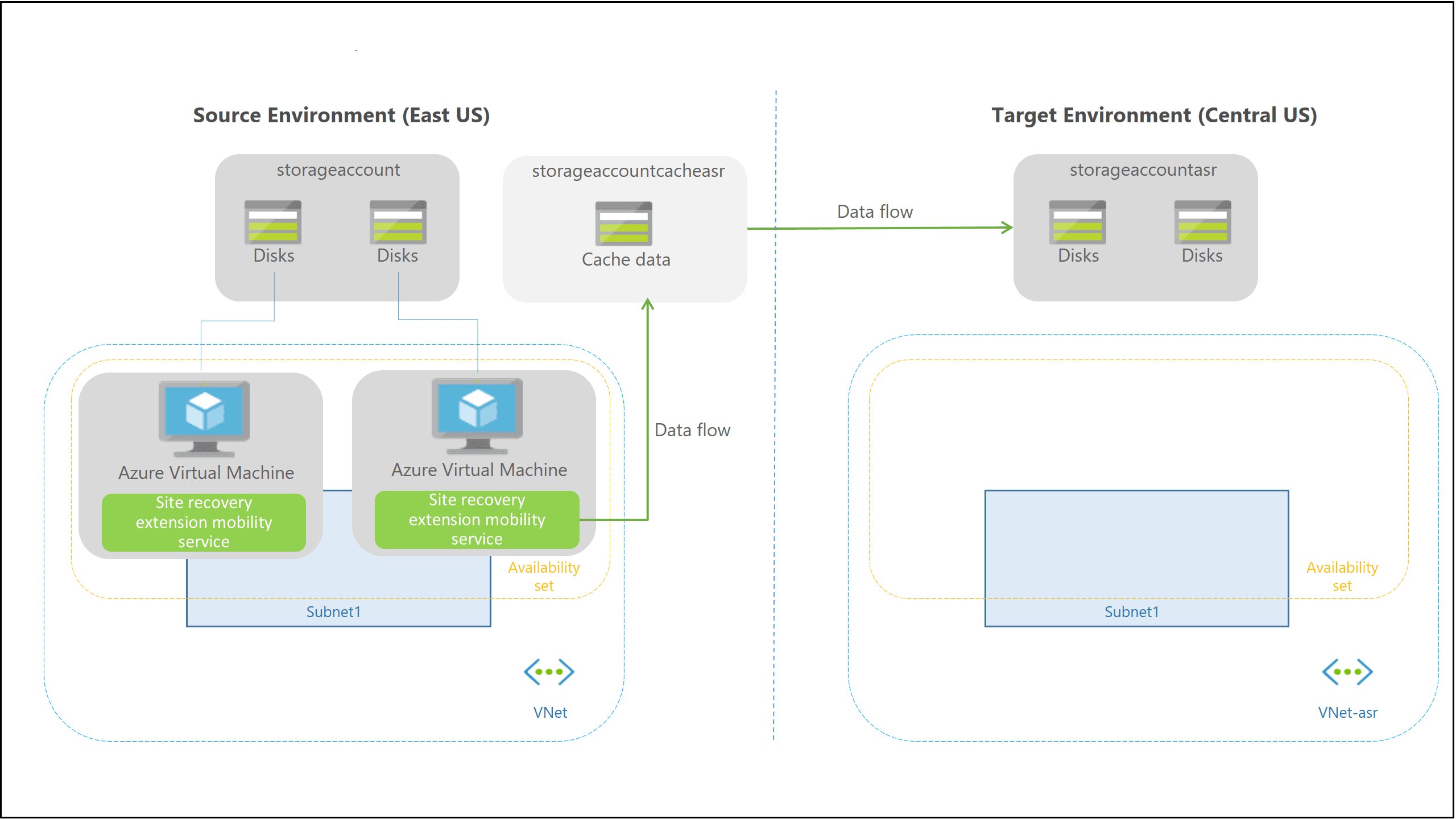
This means that all changes to a disk are replicated as soon as they occur, but this process knows nothing of database transactions. This is why recovering to a specific data point may not be possible with Azure Site Recovery in the same way it is for a SQL Server-centric solution such as when using an AG.
If it is not possible to deploy one of the in-guest options for IaaS solutions, Azure Site Recovery is a viable option to manage disaster recovery.
Additionally, Azure Site Recovery can potentially protect you against ransomware. If infected, you could roll the VM back to a point before the infection was introduced. That could also mean data loss from a SQL Server perspective, but some data loss, especially in this case, may be more than acceptable. Up and running is often better than down for hours, days, or weeks trying to remove ransomware from your network.
The key things to know when replication is enabled on a VM:
There is a Site Recovery Mobility extension configured on the VM.
Changes are sent continually unless Azure Site Recovery is unconfigured or replication is disabled
Crash consistent recovery points are generated every five minutes, and application-specific recovery points are generated according to what is configured in the replication policy.
For SQL Server, the ‘App consistent snapshot frequency’ value is what you may want to adjust to reduce your RPO. However, due to the nature of how Azure Site Recovery works – it is using Volume Shadow Service (VSS) – lowering this value could potentially cause problems for SQL Server since there is a brief freeze and thaw of I/O when the snapshots are taken. The impact of the freeze and thaw could be magnified if other options such as an AG are configured. Most will not encounter issues, but if Azure Site Recovery interferes with SQL Server, you may want to consider other availability options.
If multiple VMs are part of an overall solution, they can be replicated together to create a shared crash- and application-consistent recovery points. This is known as multi-VM consistency and will impact performance. Unless VMs must be restored in this way, it is recommended not to configure this option.
One major benefit of Azure Site Recovery is that you can test disaster recovery without needing to bring down production.
A consideration for Azure Site Recovery is that in the event of a failover to another region, the replica VMs are not protected when they are brought online. They will have to be reprotected.
Explanation
The listener requires the creation of an Azure load balancer and has some additional configuration in the WSFC related to the load balancer.
For all availability configurations of availability groups (AGs), an underlying cluster is required, whether or not it uses AD DS. By the end of this unit, you will understand the considerations for deploying an AG in Azure.
Considerations for Always On availability groups in Azure
Configuring an AG is nearly the same in Azure as it is on premises as are most of the considerations, such as how to initialize secondary replicas. Most of the Azure-specific considerations were discussed earlier, such as needing an ILB. Same as the WSFC itself, you cannot reserve the listener’s IP address in Azure so you need to ensure something else does not come along and grab it otherwise there could be a conflict on the network, which in turn could cause availability headaches.
Do not place any permanent database on the ephemeral storage. All virtual machines (VMs) that are participating in an AG should have the same storage configuration. You must size disks appropriately for performance depending on the application workload.
Before an AG can be configured, the AG feature must be enabled. This can be done in SQL Server Configuration Manager as shown in the image below or via PowerShell with the cmdlet Enable-SqlAlwaysOn. Enabling the AG feature will require a stop and start of the SQL Server service.
Create the Availability group
Creating an AG in Azure is the same as it is on premises. SQL Server Management Studio (SSMS), T-SQL, or PowerShell can be used.
The only difference is that whether or not you create the listener as part of the initial AG configuration, as the listener requires the creation of an Azure load balancer and has some additional configuration in the WSFC related to the load balancer.
Create an Internal Azure load balancer
Once the listener is created, an internal load balancer (ILB) must be used. Without configuring an ILB, applications, end users, administrators, and others cannot use the listener unless they were connected to the VM that hosts an AG’s primary replica.
You can use a basic or a standard load balancer depending on your preference or configuration. Deployments using Availability Zones require the use of a standard load balancer. The listener IP address and the port used for the listener are what is configured as part of the load balancer. A single load balancer supports more than one IP address, so depending on your standards, you may not need a different load balancer for each AG configured on those nodes.
Another consideration for the load balancer is the probe port. Without the probe port, the listener will not work properly as it is not enough just to create the load balancer. Each IP address that will use the load balancer requires a unique probe port. If there are going to be two listeners, there must be two probe ports. Probe ports are high numbers such as 59999.
The probe port is set on the IP address(es) associated with the listener with the following syntax:
- PowerShell
- Get-ClusterResource IPAddressResourceNameForListener | Set-ClusterParameter ProbePort PortNumber
Adding the probe port will require a stop and start of the IP address of the listener, which will also temporarily cause the AG to be brought offline, so it is best to get this configured before deploying in production.
If you have a multi-subnet configuration, a load balancer will need to be configured in each subnet (whether or not the other subnet is deployed to different region) and the probe port for that region associated with the IP resource for that subnet in the WSFC.
Without directly connecting to the listener, the only way to ensure that the listener is configured correctly is to use the PowerShell cmdlet Test-NetConnection with the specific port. The syntax is as follows:
- PowerShell
- Test-NetConnection NameOrIPAddress -Port PortNumber
You should run this command from somewhere other than the VM that is hosting the primary replica.
Some environments may also require that the IP address for the WSFC and selected ports (such as 445) must be accessible for administration or other purposes, which mean configuring those as part of the same or a different load balancer.
Once the load balancer is confirmed to be working, you can begin to test AG failover and connectivity to the AG via the listener.
Distributed availability groups
Planning for and configuring a distributed AG is the same on premises as it is in Azure, with any Azure-specific considerations for the individual AGs. The main difference between an on-premises configuration and an Azure configuration for a distributed AG is that as part of the load balancer configuration in each region, the endpoint port for the AG needs to be added. The default port is 5022.
Azure Site Recovery
Azure Site Recovery is an option that work with the Virtual Machine, whether or not SQL Server is running inside of it. It works with SQL Server but is not designed specifically to account for nuances that may be required when you have a specific RPO. The disks of a VM configured to use Azure Site Recovery are replicated to another region. This replication can be seen in the image below, noted by the “Data flow” arrow.
This means that all changes to a disk are replicated as soon as they occur, but this process knows nothing of database transactions. This is why recovering to a specific data point may not be possible with Azure Site Recovery in the same way it is for a SQL Server-centric solution such as when using an AG.
If it is not possible to deploy one of the in-guest options for IaaS solutions, Azure Site Recovery is a viable option to manage disaster recovery.
Additionally, Azure Site Recovery can potentially protect you against ransomware. If infected, you could roll the VM back to a point before the infection was introduced. That could also mean data loss from a SQL Server perspective, but some data loss, especially in this case, may be more than acceptable. Up and running is often better than down for hours, days, or weeks trying to remove ransomware from your network.
The key things to know when replication is enabled on a VM:
There is a Site Recovery Mobility extension configured on the VM.
Changes are sent continually unless Azure Site Recovery is unconfigured or replication is disabled
Crash consistent recovery points are generated every five minutes, and application-specific recovery points are generated according to what is configured in the replication policy.
For SQL Server, the ‘App consistent snapshot frequency’ value is what you may want to adjust to reduce your RPO. However, due to the nature of how Azure Site Recovery works – it is using Volume Shadow Service (VSS) – lowering this value could potentially cause problems for SQL Server since there is a brief freeze and thaw of I/O when the snapshots are taken. The impact of the freeze and thaw could be magnified if other options such as an AG are configured. Most will not encounter issues, but if Azure Site Recovery interferes with SQL Server, you may want to consider other availability options.
If multiple VMs are part of an overall solution, they can be replicated together to create a shared crash- and application-consistent recovery points. This is known as multi-VM consistency and will impact performance. Unless VMs must be restored in this way, it is recommended not to configure this option.
One major benefit of Azure Site Recovery is that you can test disaster recovery without needing to bring down production.
A consideration for Azure Site Recovery is that in the event of a failover to another region, the replica VMs are not protected when they are brought online. They will have to be reprotected.
Question 8 Single Choice
Identify the missing word(s) in the following sentence within the context of Microsoft Azure.
[?] is a feature in SQL Server and Azure SQL managed instance that allows you to granularly control how much CPU, physical IO, and memory resources can be used by an incoming request from an application. [?] is enabled at the instance level and allows you to define how connections are treated by using a classifier function, which subdivides sessions into workload group. Each workload group is configured to use a specific pool of system resources.
Explanation
Click "Show Answer" to see the explanation here
While some SQL Servers or Azure SQL managed instances only support one application’s databases (this configuration is commonly seen in mission critical applications), many servers support databases for multiple applications with differing performance requirements and different peak workload cycles. Balancing these differing requirements can be challenging to the administrator. One of the ways to balance server resources is to use Resource Governor, which was introduced to SQL Server 2008.
Resource Governor is a feature in SQL Server and Azure SQL managed instance that allows you to granularly control how much CPU, physical IO, and memory resources can be used by an incoming request from an application. Resource Governor is enabled at the instance level and allows you to define how connections are treated by using a classifier function, which subdivides sessions into workload group. Each workload group is configured to use a specific pool of system resources.
Resource pools
A resource pool represents physical resources available on the server. SQL Server always has two pools, default and internal, even when Resource Governor is not enabled. The internal pool is used by critical SQL Server functions and cannot be restricted. The default pool, and any resource pools you explicitly define, can be configured with limits on the resources it can use. You can specify the following limits for each non-internal pool:
Min/Max CPU percent
Cap of CPU percent
Min/Max memory percent
NUMA node affinity
Min/Max IOPs per volume
With the exception of min/max CPU percent, all of the other resource pool settings represent hard limits and cannot be exceeded. Min/Max CPU percentage will only apply when there is CPU contention. For example, if you have a maximum of 70%, if there is available CPU cycles the workload may use up to 100%. If there are other workloads running, the workload will be restricted to 70%.
https://docs.microsoft.com/en-us/system-center/scom/plan-resource-pool-design?view=sc-om-2019
Workload group
A workload group is a container for session requests based on their classification by the classifier function. Like resource pools there are two built-in groups, default and internal, and each workload group can only belong to one resource pool. However, a resource pool can host multiple workload groups. All connections go into the default workload group, unless they passed into another user-defined group by the classifier function. And by default, the default workload group uses the resources assigned to the default resource pool.
Classifier function
The classifier function is run at the time a connection is established to the SQL Server instance and classifies each connection into a given workload group. If the function returns a NULL, default, or the name of the non-existent workload group the session is transferred into the default workload group. Since the classifier is run at every connection, it should be tested for efficiency.
Resource Governor use cases
Resource Governor is used primarily in multi-tenant scenarios where a group of databases share a single SQL Server instance, and performance needs to be kept consistent for all users of the server. You can also use Resource Governor to limit the resources used by maintenance operations like consistency checks and index rebuilds, to try to guarantee sufficient resources for user queries during your maintenance windows.
Explanation
While some SQL Servers or Azure SQL managed instances only support one application’s databases (this configuration is commonly seen in mission critical applications), many servers support databases for multiple applications with differing performance requirements and different peak workload cycles. Balancing these differing requirements can be challenging to the administrator. One of the ways to balance server resources is to use Resource Governor, which was introduced to SQL Server 2008.
Resource Governor is a feature in SQL Server and Azure SQL managed instance that allows you to granularly control how much CPU, physical IO, and memory resources can be used by an incoming request from an application. Resource Governor is enabled at the instance level and allows you to define how connections are treated by using a classifier function, which subdivides sessions into workload group. Each workload group is configured to use a specific pool of system resources.
Resource pools
A resource pool represents physical resources available on the server. SQL Server always has two pools, default and internal, even when Resource Governor is not enabled. The internal pool is used by critical SQL Server functions and cannot be restricted. The default pool, and any resource pools you explicitly define, can be configured with limits on the resources it can use. You can specify the following limits for each non-internal pool:
Min/Max CPU percent
Cap of CPU percent
Min/Max memory percent
NUMA node affinity
Min/Max IOPs per volume
With the exception of min/max CPU percent, all of the other resource pool settings represent hard limits and cannot be exceeded. Min/Max CPU percentage will only apply when there is CPU contention. For example, if you have a maximum of 70%, if there is available CPU cycles the workload may use up to 100%. If there are other workloads running, the workload will be restricted to 70%.
https://docs.microsoft.com/en-us/system-center/scom/plan-resource-pool-design?view=sc-om-2019
Workload group
A workload group is a container for session requests based on their classification by the classifier function. Like resource pools there are two built-in groups, default and internal, and each workload group can only belong to one resource pool. However, a resource pool can host multiple workload groups. All connections go into the default workload group, unless they passed into another user-defined group by the classifier function. And by default, the default workload group uses the resources assigned to the default resource pool.
Classifier function
The classifier function is run at the time a connection is established to the SQL Server instance and classifies each connection into a given workload group. If the function returns a NULL, default, or the name of the non-existent workload group the session is transferred into the default workload group. Since the classifier is run at every connection, it should be tested for efficiency.
Resource Governor use cases
Resource Governor is used primarily in multi-tenant scenarios where a group of databases share a single SQL Server instance, and performance needs to be kept consistent for all users of the server. You can also use Resource Governor to limit the resources used by maintenance operations like consistency checks and index rebuilds, to try to guarantee sufficient resources for user queries during your maintenance windows.
Question 9 Single Choice
Scenario: Peter Parker is working at the Daily Bugle. The Daily Bugle is a provider for services and content delivery across the globe. It has requested Peter’s assistance in building a system that can handle thousands of writes per second to what is essentially an operational data mart.
The Daily Bugle also needs the ability to perform real-time analytics on the data, to determine trends and identify anomalies. It's currently doing that with common language runtime (CLR) applications. They are not looking for a data warehouse and to utilize large portions of the SQL surface area, but it needs to be able to scale where users live.
The Daily Bugle is also trying to determine which authentication methods to use in its hybrid environment. Although the main solution and application will live in Azure, the customer also needs to accommodate the following:
An application on a non-Azure machine that is domain-joined.
An older application that won't allow the change of the driver or connection string on a non-Azure machine.
Multiple users that run reports from SQL admin tools (SQL Server Management Studio, Azure Data Studio, PowerShell) on non-Azure machines that are not domain-joined.
Wherever possible, the Daily Bugle wants to eliminate hard-coding passwords or secrets in the connection strings and app configuration files. It also wants to eliminate using passwords in SQL tools or find a way to enhance that authentication.
Which authentication method would Peter recommend for the application on a non-Azure machine that is domain-joined?
Explanation
Click "Show Answer" to see the explanation here
Integrated authentication via Microsoft Entra ID is the authentication method that we recommend for apps running on domain-joined machines outside Azure, assuming the domain has been federated with Microsoft Entra ID. Alternatively, Peter can create an application identity for his application in Microsoft Entra ID, associate a certificate with the application identity, and modify his application to acquire a token for Azure SQL Database by providing a client ID and a certificate. Although the certificate must contain a private key and it must be deployed on the machine that's hosting his application, he at least avoids hard-coding an application secret in the application code or configuration. (He will need to configure the app with the certificate thumbprint.)
Microsoft Entra ID was previously known as Azure Active Directory (Azure AD).
Explanation
Integrated authentication via Microsoft Entra ID is the authentication method that we recommend for apps running on domain-joined machines outside Azure, assuming the domain has been federated with Microsoft Entra ID. Alternatively, Peter can create an application identity for his application in Microsoft Entra ID, associate a certificate with the application identity, and modify his application to acquire a token for Azure SQL Database by providing a client ID and a certificate. Although the certificate must contain a private key and it must be deployed on the machine that's hosting his application, he at least avoids hard-coding an application secret in the application code or configuration. (He will need to configure the app with the certificate thumbprint.)
Microsoft Entra ID was previously known as Azure Active Directory (Azure AD).
Question 10 Single Choice
Scenario: Damage Control is construction and repair company contracted by S.H.I.E.L.D. to help in the clean-up and repair after the super-villain attacks on New York City. It is headed up by Mac Porter, the company CEO.
You are a developer in the Damage Control IT team, and you are currently working with a serverless SQL Database. Your boss, Director Furry, has asked you to change the auto-pause setting.
Which of the following is correct regarding changing the auto-pause setting of the serverless SQL Database?
Explanation
Click "Show Answer" to see the explanation here
You can change the auto-pause setting at any time through the Azure portal.
Design Azure SQL Database for cloud-native applications
Azure SQL Database is a Platform as a Service (PaaS) that provides high scalability capabilities, and it can be a great solution for certain workloads, and requires minimal maintenance efforts.
Azure SQL Database is aimed at new application development as it gives developers a great deal of flexibility in building new application services, and granular deployment options at scale. SQL Database offers a low maintenance solution that can be a great option for certain workloads.
Purchasing model
SQL Database comes in two main purchasing models: vCore-based model and DTU-based model. Each purchasing model offers the following service tiers:
vCore-based
In this purchasing model, compute and storage resources are decoupled. It means you can scale storage and compute resources independently from one another. Here are listed the service tiers available:

DTU-based
In the DTU model, there are three service tiers available: Basic, Standard, and Premium. Compute and storage resources are dependent on the DTU level, and they provide a range of performance capabilities at a fixed storage limit, backup retention, and cost.
For example, if your database grows to the point it reaches the maximum storage limit, you would need to increase your DTU capacity, even if the compute utilization is low.
The scaling operation on SQL Database may incur in a brief connection interruption at the end of the scaling operation. There are two main changes that trigger this behavior:
Once you initiate a scaling operation that requires an internal failover.
When adding or removing databases to the elastic pool.
You can use a proper retry logic in your application to handle connection errors.
Azure SQL Managed Instance doesn't support DTU-based purchasing model.
Serverless compute tier
Despite its name, the serverless compute tier does require you to have a server with your database. The serverless option can best be thought of as an autoscaling and auto-pause solution for SQL Database. It is effective for lowering the costs in development and testing environments. For example, you can set up a minimum and a maximum vCores configuration for your database, where it will scale dynamically based on your workload.
The auto-pause delay feature allows you to define the period of time the database will be inactive before it is automatically paused. The auto-pause delay feature can be set up from 1 hour to seven days. Alternatively, auto-pause delay feature can be disabled.
The resume operation is triggered when the next attempt to access the database occurs, and only storage charges are applicable when the database is paused.

The image above shows where you can change the autoscaling and auto-pause properties for serverless compute tier.
Deployment model
There are two main deployment models when deploying SQL Database on Azure: single database and elastic pool. Elastic pools share resources with other databases part of the same pool, while single databases resources are managed independently.
SQL Database, like virtual machines, can be deployed using Azure Resource Manager templates, PowerShell, Azure CLI, or the Azure portal.
Single database
Single database is the simplest deployment model of Azure SQL Database. You manage each of your databases individually from scale and data size perspectives. Each database deployed in this model has its own dedicated resources, even if deployed to the same logical server.
You can monitor database resources utilization through Azure portal. This feature allows you to easily identify how the database is performing, as shown in the image below:

Elastic pool
Elastic pools allow you to allocate storage and compute resources to a group of databases, rather than having to manage resources for each database individually. Additionally, elastic pools are easier to scale than single databases, where scaling individual databases is no longer needed due to changes made to the elastic pool.
Elastic pools provide a cost-effective solution for software as a service application model, since resources are shared between all databases. You can configure resources based either on the DTU-based purchasing model or the vCore-based purchasing model.
Due to the nature of this feature, it is recommended to monitor your resources continually to identify concurrent performance spikes that could affect other databases part of the same elastic pool. Often, you may need to revisit your allocation strategy to make sure there's enough resource available for all databases sharing the same elastic pool.
Elastic pool is a good fit for multi-tenant architecture with low average utilization, where each tenant has its own copy of the database.
Network options
Azure SQL Database by default has a public internet endpoint. Access to this endpoint can be controlled via firewall rules, or limited to specific Azure networks, using features like Virtual Network endpoints or Private Link.
Backup and restore
Azure provides seamless backup and restore capabilities for SQL Database and SQL Managed Instance. Let's learn about some of the most important features.
Continuous backup
With SQL Database, you can increase administration efficiency by knowing that databases are backed up regularly, and that they are continuously copied to a read-access geo-redundant storage (RA-GRS).
Full backups are performed every week, differential backups every 12 to 24 hours, and transaction log backups every 5 to 10 minutes.
Geo-restore
As backups are geo-redundant by default for SQL Database and SQL Managed Instance, you can easily restore databases to a different geographical region, which is especially useful for less strict disaster recovery scenarios.
Backup storage is billed apart from regular database files storage. However, when provisioning a SQL Database, the backup storage is created with the maximum size of the data tier selected for your database at no extra cost.
The duration of a geo-restore operation can be affected by several underlying components including the size of the database, the number of transaction logs involved in a restore operation, and the amount of simultaneous restore requests being processed in the target region.
Geo-restore is available when the backup storage redundancy property is set to geo-redundant backup storage.
Point-in-time restore (PITR)
You can configure a specific point in time retention policy for each database running on a SQL Database offering. SQL Database retention period can be set from 1 up to 35 days. In fact, if not specified, the default configuration is seven days.
You can restore your databases to a specific point in time according to the retention defined, but PITR is only supported if you are restoring a database in the same server the backup was originated. You can use either Azure portal, Azure PowerShell, Azure CLI, or REST API to restore a SQL Database.
Long-term retention (LTR)
Long-term retention is useful for scenarios that require you to set the retention policy beyond what is offered by Azure. You can set a retention policy for up to 10 years, and this option is disabled by default.

In the image above, you can configure long-term retention policies through Azure portal. Once the database is selected, a new panel will open on the right side of the screen, where you can override the default properties.
Automatic Tuning
Automatic tuning is a built-in feature that relies on machine learning regression capabilities, and automatically identify tuning opportunities based on your query performance.
Automatic tuning currently includes the following features:
Identify Expensive Queries
Forcing Last Good Execution Plan
Adding Indexes
Removing Indexes
The Azure services use a combination of built-in advanced features to determine the best indexes for your query pattern. Initially, these indexes are tested on a copy of your database, and finally applied to your database.
All databases inherit configuration from their parent server, and you can easily disable this feature at any time.
Elastic query
Elastic query allows you to run T-SQL queries that bridge multiple databases in SQL Database. This feature is particularly useful for applications using three- and four-part names that cannot be changed. It also increases portability as it allows for migration.
Elastic queries support the following partitioning strategies:

Azure SQL Managed Instance doesn't support elastic queries.
Elastic job
The elastic job feature is the SQL Server Agent replacement for Azure SQL Database. To some extent, elastic job is equivalent to the Multi Server Administration feature available on an on-premises SQL Server instance.
You can execute T-SQL commands across several target deployments like SQL Databases, SQL Database elastic pools, and SQL Databases in shard maps. Database resources can run on different Azure subscriptions, and/or regions. The execution runs in parallel, which is useful when automating database maintenance tasks.
Azure SQL Managed Instance doesn't support elastic jobs.
SQL Data Sync
The Data Sync feature allows you to incrementally synchronize data across multiple databases running on SQL Database or on-premises SQL Server. Similarly, Data Sync is a good option if you need to offload intensive workloads in production with a separate database that can be used for analytics and/or ad hoc operations.
Data Sync is based on a hub topology, where you define one of the databases in the sync group to work as a hub database. The sync group can have multiple members, and you can only synchronize changes between the hub database and individual databases. Data Sync tracks changes using insert, update, and delete triggers through a historical table created on the user database.
When you create a sync group, it will ask you to provide a database responsible to store the sync group metadata. The metadata location can be either a new database or an existing database as long it resides in the same region as your sync group.

In the image above, you can specify sync group properties like the schedule synchronization, the conflict resolution option, and the use of a private link if needed.
Azure SQL Managed Instance doesn't support Data Sync feature.
Explanation
You can change the auto-pause setting at any time through the Azure portal.
Design Azure SQL Database for cloud-native applications
Azure SQL Database is a Platform as a Service (PaaS) that provides high scalability capabilities, and it can be a great solution for certain workloads, and requires minimal maintenance efforts.
Azure SQL Database is aimed at new application development as it gives developers a great deal of flexibility in building new application services, and granular deployment options at scale. SQL Database offers a low maintenance solution that can be a great option for certain workloads.
Purchasing model
SQL Database comes in two main purchasing models: vCore-based model and DTU-based model. Each purchasing model offers the following service tiers:
vCore-based
In this purchasing model, compute and storage resources are decoupled. It means you can scale storage and compute resources independently from one another. Here are listed the service tiers available:
DTU-based
In the DTU model, there are three service tiers available: Basic, Standard, and Premium. Compute and storage resources are dependent on the DTU level, and they provide a range of performance capabilities at a fixed storage limit, backup retention, and cost.
For example, if your database grows to the point it reaches the maximum storage limit, you would need to increase your DTU capacity, even if the compute utilization is low.
The scaling operation on SQL Database may incur in a brief connection interruption at the end of the scaling operation. There are two main changes that trigger this behavior:
Once you initiate a scaling operation that requires an internal failover.
When adding or removing databases to the elastic pool.
You can use a proper retry logic in your application to handle connection errors.
Azure SQL Managed Instance doesn't support DTU-based purchasing model.
Serverless compute tier
Despite its name, the serverless compute tier does require you to have a server with your database. The serverless option can best be thought of as an autoscaling and auto-pause solution for SQL Database. It is effective for lowering the costs in development and testing environments. For example, you can set up a minimum and a maximum vCores configuration for your database, where it will scale dynamically based on your workload.
The auto-pause delay feature allows you to define the period of time the database will be inactive before it is automatically paused. The auto-pause delay feature can be set up from 1 hour to seven days. Alternatively, auto-pause delay feature can be disabled.
The resume operation is triggered when the next attempt to access the database occurs, and only storage charges are applicable when the database is paused.
The image above shows where you can change the autoscaling and auto-pause properties for serverless compute tier.
Deployment model
There are two main deployment models when deploying SQL Database on Azure: single database and elastic pool. Elastic pools share resources with other databases part of the same pool, while single databases resources are managed independently.
SQL Database, like virtual machines, can be deployed using Azure Resource Manager templates, PowerShell, Azure CLI, or the Azure portal.
Single database
Single database is the simplest deployment model of Azure SQL Database. You manage each of your databases individually from scale and data size perspectives. Each database deployed in this model has its own dedicated resources, even if deployed to the same logical server.
You can monitor database resources utilization through Azure portal. This feature allows you to easily identify how the database is performing, as shown in the image below:
Elastic pool
Elastic pools allow you to allocate storage and compute resources to a group of databases, rather than having to manage resources for each database individually. Additionally, elastic pools are easier to scale than single databases, where scaling individual databases is no longer needed due to changes made to the elastic pool.
Elastic pools provide a cost-effective solution for software as a service application model, since resources are shared between all databases. You can configure resources based either on the DTU-based purchasing model or the vCore-based purchasing model.
Due to the nature of this feature, it is recommended to monitor your resources continually to identify concurrent performance spikes that could affect other databases part of the same elastic pool. Often, you may need to revisit your allocation strategy to make sure there's enough resource available for all databases sharing the same elastic pool.
Elastic pool is a good fit for multi-tenant architecture with low average utilization, where each tenant has its own copy of the database.
Network options
Azure SQL Database by default has a public internet endpoint. Access to this endpoint can be controlled via firewall rules, or limited to specific Azure networks, using features like Virtual Network endpoints or Private Link.
Backup and restore
Azure provides seamless backup and restore capabilities for SQL Database and SQL Managed Instance. Let's learn about some of the most important features.
Continuous backup
With SQL Database, you can increase administration efficiency by knowing that databases are backed up regularly, and that they are continuously copied to a read-access geo-redundant storage (RA-GRS).
Full backups are performed every week, differential backups every 12 to 24 hours, and transaction log backups every 5 to 10 minutes.
Geo-restore
As backups are geo-redundant by default for SQL Database and SQL Managed Instance, you can easily restore databases to a different geographical region, which is especially useful for less strict disaster recovery scenarios.
Backup storage is billed apart from regular database files storage. However, when provisioning a SQL Database, the backup storage is created with the maximum size of the data tier selected for your database at no extra cost.
The duration of a geo-restore operation can be affected by several underlying components including the size of the database, the number of transaction logs involved in a restore operation, and the amount of simultaneous restore requests being processed in the target region.
Geo-restore is available when the backup storage redundancy property is set to geo-redundant backup storage.
Point-in-time restore (PITR)
You can configure a specific point in time retention policy for each database running on a SQL Database offering. SQL Database retention period can be set from 1 up to 35 days. In fact, if not specified, the default configuration is seven days.
You can restore your databases to a specific point in time according to the retention defined, but PITR is only supported if you are restoring a database in the same server the backup was originated. You can use either Azure portal, Azure PowerShell, Azure CLI, or REST API to restore a SQL Database.
Long-term retention (LTR)
Long-term retention is useful for scenarios that require you to set the retention policy beyond what is offered by Azure. You can set a retention policy for up to 10 years, and this option is disabled by default.
In the image above, you can configure long-term retention policies through Azure portal. Once the database is selected, a new panel will open on the right side of the screen, where you can override the default properties.
Automatic Tuning
Automatic tuning is a built-in feature that relies on machine learning regression capabilities, and automatically identify tuning opportunities based on your query performance.
Automatic tuning currently includes the following features:
Identify Expensive Queries
Forcing Last Good Execution Plan
Adding Indexes
Removing Indexes
The Azure services use a combination of built-in advanced features to determine the best indexes for your query pattern. Initially, these indexes are tested on a copy of your database, and finally applied to your database.
All databases inherit configuration from their parent server, and you can easily disable this feature at any time.
Elastic query
Elastic query allows you to run T-SQL queries that bridge multiple databases in SQL Database. This feature is particularly useful for applications using three- and four-part names that cannot be changed. It also increases portability as it allows for migration.
Elastic queries support the following partitioning strategies:
Azure SQL Managed Instance doesn't support elastic queries.
Elastic job
The elastic job feature is the SQL Server Agent replacement for Azure SQL Database. To some extent, elastic job is equivalent to the Multi Server Administration feature available on an on-premises SQL Server instance.
You can execute T-SQL commands across several target deployments like SQL Databases, SQL Database elastic pools, and SQL Databases in shard maps. Database resources can run on different Azure subscriptions, and/or regions. The execution runs in parallel, which is useful when automating database maintenance tasks.
Azure SQL Managed Instance doesn't support elastic jobs.
SQL Data Sync
The Data Sync feature allows you to incrementally synchronize data across multiple databases running on SQL Database or on-premises SQL Server. Similarly, Data Sync is a good option if you need to offload intensive workloads in production with a separate database that can be used for analytics and/or ad hoc operations.
Data Sync is based on a hub topology, where you define one of the databases in the sync group to work as a hub database. The sync group can have multiple members, and you can only synchronize changes between the hub database and individual databases. Data Sync tracks changes using insert, update, and delete triggers through a historical table created on the user database.
When you create a sync group, it will ask you to provide a database responsible to store the sync group metadata. The metadata location can be either a new database or an existing database as long it resides in the same region as your sync group.
In the image above, you can specify sync group properties like the schedule synchronization, the conflict resolution option, and the use of a private link if needed.
Azure SQL Managed Instance doesn't support Data Sync feature.


