
Microsoft Certified: Azure Database Administrator Associate - (DP-300) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 11 Single Choice
Identify the missing word(s) in the following sentence within the context of Microsoft Azure.
In addition to high availability scenarios, Always On Availability Groups can be used for[?]. You can implement up to nine replicas of a database across Azure regions, and stretch this architecture even further using Distributed Availability Groups. Availability Groups ensure that a viable copy of your database(s) is in another location beyond the primary region.
Explanation

Click "Show Answer" to see the explanation here
While the Azure platform offers 99.9% up time by default, disasters can still occur and affect application uptime. It's important that you have a proper disaster recovery plan in place when you are performing any type of migration. Azure offers us several methods to ensure that your SQL Server on a virtual machine is protected in case of a disaster. There are two components to this protection. First, there are Azure platform options like geo-replicated storage for backups and Azure Site Recovery, which is an all-encompassing disaster recovery solution for all of your workloads. Second, there are SQL Server specific offerings like Availability Groups and backups.
Native SQL Server backups
Backups are considered the life blood of any database administrator and it's not any different when working with a cloud solution. With SQL Server on an Azure virtual machine, you have granular control of when backups occur and where they're stored. You can use SQL agent jobs to back up directly to a URL linked to Azure blob storage. Azure provides the option to use geo-redundant storage (GRS) or read-access geo-redundant storage (RA-GRS) to ensure that your backup files are stored safely across the geographic landscape.
Additionally as part of the Azure SQL VM service provider, you can have your backups automatically managed by the platform.
Azure Backup for SQL Server
The Azure Backup solution requires an agent to be installed on the virtual machine. The agent then communicates with an Azure service that manages automatic backups of your SQL Server databases. Azure Backup also provides a central location that you can use to manage and monitor the backups to ensure meeting any specified RPO/RTO metrics.
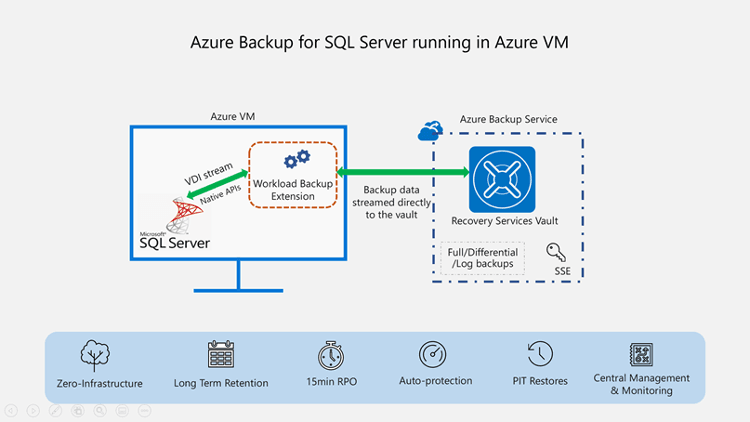
As shown above, the Azure Backup solution is a comprehensive, enterprise backup solution that provides long-term data retention, automated management, and additional data protection. This option costs more than simply performing your own backups, or using the Azure resource provider for SQL Server, but does offer a more complete backup feature set.
Availability Groups
In addition to the high availability scenarios described above, Always On Availability Groups can be used for disaster recovery purposes. You can implement up to nine replicas of a database across Azure regions, and stretch this architecture even further using Distributed Availability Groups. Availability Groups ensure that a viable copy of your database(s) is in another location beyond the primary region. By doing so, you help to ensure that your data ecosystem is protected against natural disasters as well as some human made ones.
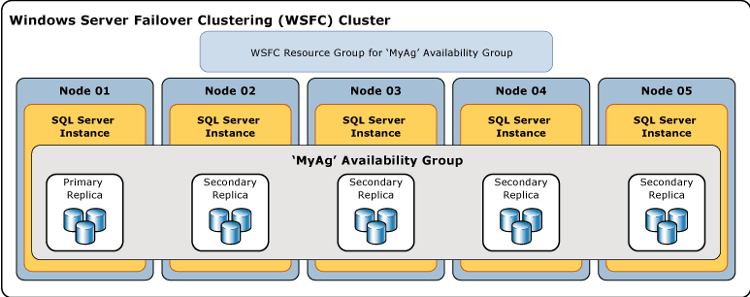
The image above shows a logical diagram of an Always On Availability Group, running on a Windows Server Failover Cluster. There are one primary and four secondary replicas. In this scenario all five replicas could be synchronous, or some combination of synchronous and asynchronous replicas. Keep in mind that the unit of failover is the group of databases and not the instance. While a failover cluster instance provides HA at an instance level, it doesn't provide disaster recovery.
Azure Site Recovery
Azure Site Recovery is a low-cost solution that will perform block level replication of your Azure virtual machine. This service offers various options, including the ability to test and verify your disaster recovery strategy. This solution is best used for stateless environments (for example, web servers) versus transactional database virtual machines. Azure Site Recovery is supported for use with SQL Server, but keep in mind that you will need to set a higher recovery point which means potential loss. In this case, your RTO will essentially be your RPO.
Explanation
While the Azure platform offers 99.9% up time by default, disasters can still occur and affect application uptime. It's important that you have a proper disaster recovery plan in place when you are performing any type of migration. Azure offers us several methods to ensure that your SQL Server on a virtual machine is protected in case of a disaster. There are two components to this protection. First, there are Azure platform options like geo-replicated storage for backups and Azure Site Recovery, which is an all-encompassing disaster recovery solution for all of your workloads. Second, there are SQL Server specific offerings like Availability Groups and backups.
Native SQL Server backups
Backups are considered the life blood of any database administrator and it's not any different when working with a cloud solution. With SQL Server on an Azure virtual machine, you have granular control of when backups occur and where they're stored. You can use SQL agent jobs to back up directly to a URL linked to Azure blob storage. Azure provides the option to use geo-redundant storage (GRS) or read-access geo-redundant storage (RA-GRS) to ensure that your backup files are stored safely across the geographic landscape.
Additionally as part of the Azure SQL VM service provider, you can have your backups automatically managed by the platform.
Azure Backup for SQL Server
The Azure Backup solution requires an agent to be installed on the virtual machine. The agent then communicates with an Azure service that manages automatic backups of your SQL Server databases. Azure Backup also provides a central location that you can use to manage and monitor the backups to ensure meeting any specified RPO/RTO metrics.
As shown above, the Azure Backup solution is a comprehensive, enterprise backup solution that provides long-term data retention, automated management, and additional data protection. This option costs more than simply performing your own backups, or using the Azure resource provider for SQL Server, but does offer a more complete backup feature set.
Availability Groups
In addition to the high availability scenarios described above, Always On Availability Groups can be used for disaster recovery purposes. You can implement up to nine replicas of a database across Azure regions, and stretch this architecture even further using Distributed Availability Groups. Availability Groups ensure that a viable copy of your database(s) is in another location beyond the primary region. By doing so, you help to ensure that your data ecosystem is protected against natural disasters as well as some human made ones.
The image above shows a logical diagram of an Always On Availability Group, running on a Windows Server Failover Cluster. There are one primary and four secondary replicas. In this scenario all five replicas could be synchronous, or some combination of synchronous and asynchronous replicas. Keep in mind that the unit of failover is the group of databases and not the instance. While a failover cluster instance provides HA at an instance level, it doesn't provide disaster recovery.
Azure Site Recovery
Azure Site Recovery is a low-cost solution that will perform block level replication of your Azure virtual machine. This service offers various options, including the ability to test and verify your disaster recovery strategy. This solution is best used for stateless environments (for example, web servers) versus transactional database virtual machines. Azure Site Recovery is supported for use with SQL Server, but keep in mind that you will need to set a higher recovery point which means potential loss. In this case, your RTO will essentially be your RPO.
Question 12 Single Choice
Identify the missing word(s) in the following sentence within the context of Microsoft Azure.
The Azure Monitor service includes the ability to track various metrics about the overall health of a given resource. Metrics are gathered at regular intervals and are the gateway for alerting processes that will help to resolve issues quickly and efficiently. Azure Monitor Metrics is a powerful subsystem that allows you to not only analyze and visualize your performance data, but to also [?].
Explanation
Click "Show Answer" to see the explanation here
The Azure Monitor service includes the ability to track various metrics about the overall health of a given resource. Metrics are gathered at regular intervals and are the gateway for alerting processes that will help to resolve issues quickly and efficiently. Azure Monitor Metrics is a powerful subsystem that allows you to not only analyze and visualize your performance data, but to also trigger alerts that notify administrators or automated actions that can trigger an Azure Automation runbook or a webhook. You also have the option to archive your Azure Metrics data to Azure Storage, since active data is only stored for 93 days.
Create metric alerts
Utilizing the Azure portal, you can create alert rules, based on defined metrics, in the overview section of the Azure Monitor blade. Azure Monitor Alerts can be scoped in three ways. For example, using Azure Virtual Machines as an example you can specify the scope as:
• A list of virtual machines in one Azure region within a subscription
• All virtual machines (in one Azure region) in one or more resource groups in a subscription
• All virtual machines (in one Azure region) in one subscription
In this manner, you can create an alert rule based on resources contained within resource groups as shown.
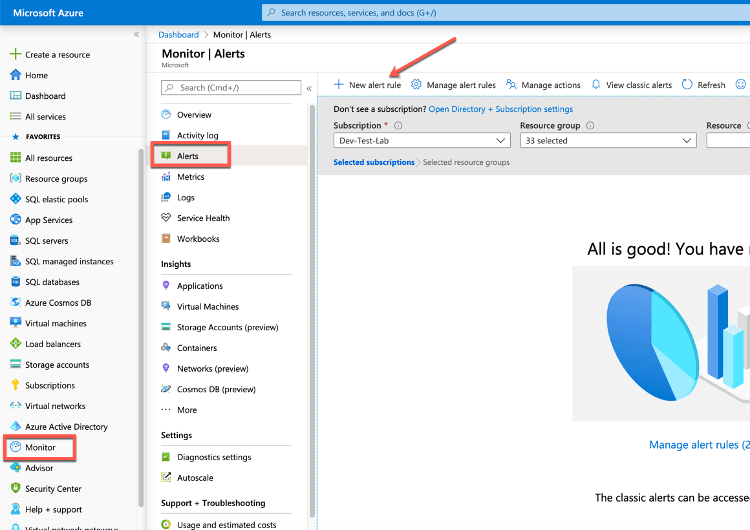
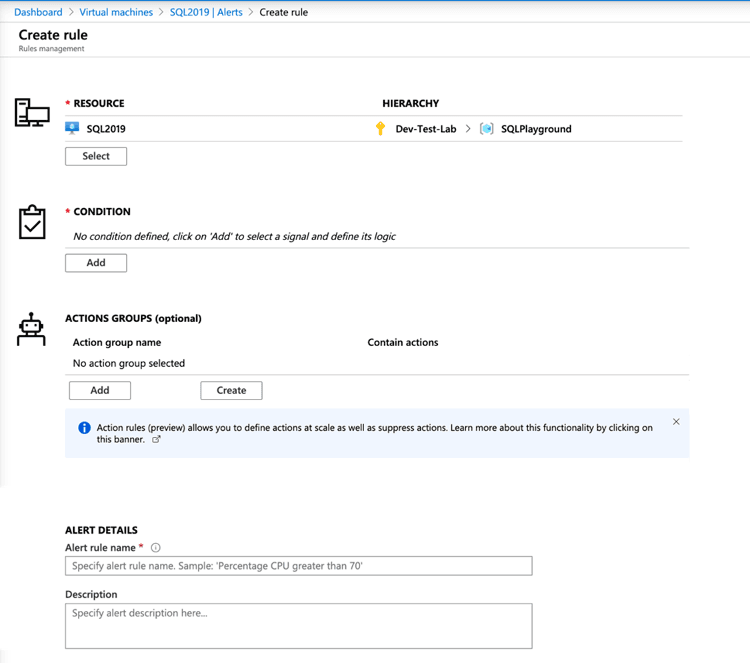
The example shown below reflects a virtual machine named SQL2019 on which we are creating an alert that is at the scope of the individual virtual machine.
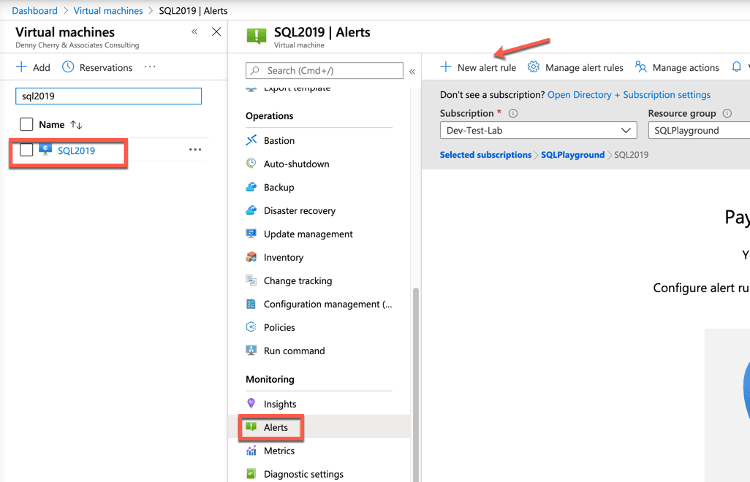
Regardless the scope of the alert, the creation process is the same.
From the alerts screen, click on New Alert Rule. If an alert is created from within the scope of a resource, the resource values should be populated for you. You can see that the resource is the SQL2019 virtual machine, the subscription is Dev-Test-Lab and the resource group in which it resides is SQLPlayground.
Under the Condition section, click Add:
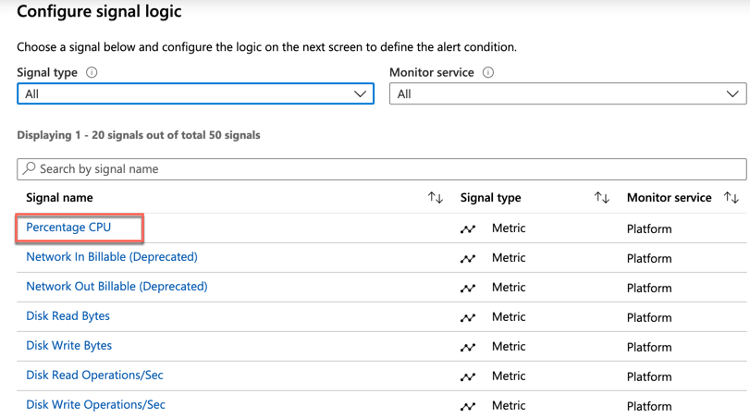
Select the metric that you wish to alert on. The following image shows Percentage CPU, which you will then see selected.
The alerts can be configured in a static manner (for example, raise an alert when CPU goes over 95%) or in a dynamic fashion using Dynamic Thresholds. Dynamic Thresholds learn the historical behaviour of the metric and raise an alert when the resources are operating in an abnormal manner. These Dynamic Thresholds can detect seasonality in your workloads and adjust the alerting accordingly.
If Static alerts are used, you must provide a threshold for the selected metric. In this example, 80 percent was specified. This threshold means that if the CPU utilization exceeds 80 percentage over a given period, an alert will be fired and react as specified.
Both types of alerts offer Booleans operators such as the 'greater than' or 'less than' operators. Along with Boolean operators, there are aggregate measurements to select from such as average, minimum, maximum, count, average, and total. With these options available, it’s easy to construct a flexible alert that will suit just about any enterprise level alerting.
After creating the alert, in order to notify administrators or launch an automation process, an action group needs to be configured.
Once you click Create Action group, you will see the screen shown below. You will name the action group and define an alert and the response. In this example, the administrator is going to be emailed in the event of the alert’s condition being triggered.
You can configure the email or SMS details as can be seen below. You can reach this screen either by clicking Edit Details under Configure, or by adding a new action, which will also bring up the configuration screen.
With an action group, there are several ways in which you can respond to the alert. The following options are available for defining the action to take:
Automation Runbook
Azure Function
Email Azure Resource Manager Role
Email/SMS/Push/Voice
ITSM
Azure Logic App
Secure Webhook
Webhook
There are two categories to these actions—notification, which means notifying an administrator or group of administrators of an event, and automation, which is taking a defined action to respond to a performance condition.
Explanation
The Azure Monitor service includes the ability to track various metrics about the overall health of a given resource. Metrics are gathered at regular intervals and are the gateway for alerting processes that will help to resolve issues quickly and efficiently. Azure Monitor Metrics is a powerful subsystem that allows you to not only analyze and visualize your performance data, but to also trigger alerts that notify administrators or automated actions that can trigger an Azure Automation runbook or a webhook. You also have the option to archive your Azure Metrics data to Azure Storage, since active data is only stored for 93 days.
Create metric alerts
Utilizing the Azure portal, you can create alert rules, based on defined metrics, in the overview section of the Azure Monitor blade. Azure Monitor Alerts can be scoped in three ways. For example, using Azure Virtual Machines as an example you can specify the scope as:
• A list of virtual machines in one Azure region within a subscription
• All virtual machines (in one Azure region) in one or more resource groups in a subscription
• All virtual machines (in one Azure region) in one subscription
In this manner, you can create an alert rule based on resources contained within resource groups as shown.
The example shown below reflects a virtual machine named SQL2019 on which we are creating an alert that is at the scope of the individual virtual machine.
Regardless the scope of the alert, the creation process is the same.
From the alerts screen, click on New Alert Rule. If an alert is created from within the scope of a resource, the resource values should be populated for you. You can see that the resource is the SQL2019 virtual machine, the subscription is Dev-Test-Lab and the resource group in which it resides is SQLPlayground.
Under the Condition section, click Add:
Select the metric that you wish to alert on. The following image shows Percentage CPU, which you will then see selected.
The alerts can be configured in a static manner (for example, raise an alert when CPU goes over 95%) or in a dynamic fashion using Dynamic Thresholds. Dynamic Thresholds learn the historical behaviour of the metric and raise an alert when the resources are operating in an abnormal manner. These Dynamic Thresholds can detect seasonality in your workloads and adjust the alerting accordingly.
If Static alerts are used, you must provide a threshold for the selected metric. In this example, 80 percent was specified. This threshold means that if the CPU utilization exceeds 80 percentage over a given period, an alert will be fired and react as specified.
Both types of alerts offer Booleans operators such as the 'greater than' or 'less than' operators. Along with Boolean operators, there are aggregate measurements to select from such as average, minimum, maximum, count, average, and total. With these options available, it’s easy to construct a flexible alert that will suit just about any enterprise level alerting.
After creating the alert, in order to notify administrators or launch an automation process, an action group needs to be configured.
Once you click Create Action group, you will see the screen shown below. You will name the action group and define an alert and the response. In this example, the administrator is going to be emailed in the event of the alert’s condition being triggered.
You can configure the email or SMS details as can be seen below. You can reach this screen either by clicking Edit Details under Configure, or by adding a new action, which will also bring up the configuration screen.
With an action group, there are several ways in which you can respond to the alert. The following options are available for defining the action to take:
Automation Runbook
Azure Function
Email Azure Resource Manager Role
Email/SMS/Push/Voice
ITSM
Azure Logic App
Secure Webhook
Webhook
There are two categories to these actions—notification, which means notifying an administrator or group of administrators of an event, and automation, which is taking a defined action to respond to a performance condition.
Question 13 Single Choice
Identify the missing word(s) in the following sentence within the context of Microsoft Azure.
[?] is a concept where a query is built programmatically and allows T-SQL statements to be generated within a stored procedure or a query itself. See the following code as an example.
- SQL
- SELECT 'BACKUP DATABASE ' + name + ' TO DISK =''\\backup\sql1\' + name + '.bak'''
- FROM sys.databases
Explanation
Click "Show Answer" to see the explanation here
Dynamic SQL
Dynamic SQL is a concept where a query is built programmatically. Dynamic SQL allows T-SQL statements to be generated within a stored procedure or a query itself. A simple example is shown below.
- SQL
- SELECT 'BACKUP DATABASE ' + name + ' TO DISK =''\\backup\sql1\' + name + '.bak'''
- FROM sys.databases
The above statement will generate a list of T-SQL statements to back up all of the database on the server. Typically, this generated T-SQL will be executed using sp_executesql or passed to another program to execute.
Explanation
Dynamic SQL
Dynamic SQL is a concept where a query is built programmatically. Dynamic SQL allows T-SQL statements to be generated within a stored procedure or a query itself. A simple example is shown below.
- SQL
- SELECT 'BACKUP DATABASE ' + name + ' TO DISK =''\\backup\sql1\' + name + '.bak'''
- FROM sys.databases
The above statement will generate a list of T-SQL statements to back up all of the database on the server. Typically, this generated T-SQL will be executed using sp_executesql or passed to another program to execute.
Question 14 Single Choice
What is the unit of execution for your Azure Automation Account?
Explanation
Click "Show Answer" to see the explanation here
Runbooks are the unit of execution in Azure Automation.
You can add a runbook to Azure Automation by either creating a new one or importing an existing one from a file or the Runbook Gallery.
Explanation
Runbooks are the unit of execution in Azure Automation.
You can add a runbook to Azure Automation by either creating a new one or importing an existing one from a file or the Runbook Gallery.
Question 15 Single Choice
Which platforms can an Azure Database for PostgreSQL database backup be restored to?
Explanation
Click "Show Answer" to see the explanation here
Similar to all other Azure PaaS offerings, these backups can only be used by Azure Database for PostgreSQL and not a standard installation of PostgreSQL.
Explanation
Similar to all other Azure PaaS offerings, these backups can only be used by Azure Database for PostgreSQL and not a standard installation of PostgreSQL.
Question 16 Single Choice
Scenario: You are working as a consultant at Advanced Idea Mechanics (A.I.M.) who is a privately funded think tank organized of a group of brilliant scientists whose sole dedication is to acquire and develop power through technological means. Their goal is to use this power to overthrow the governments of the world. They supply arms and technology to radicals and subversive organizations in order to foster a violent technological revolution of society while making a profit.
The company has 10,000 employees. Most employees are located in Europe. The company supports teams worldwide.
AIM has two main locations: the main office in London, England, and a manufacturing plant in Berlin, Germany.
At the moment, you are leading a Workgroup meeting with the IT Team where the topic of discussion is database synchronization.
Which of the following replicates data synchronously across three Azure availability zones in the primary region using zone-redundant storage (ZRS), then replicates asynchronously to the secondary region?
Explanation
Click "Show Answer" to see the explanation here
Azure Storage offers two options for geo-redundant replication. The only difference between these two options is how data is replicated in the primary region:
Geo-zone-redundant storage (GZRS): Data is replicated synchronously across three Azure availability zones in the primary region using zone-redundant storage (ZRS), then replicated asynchronously to the secondary region. For read access to data in the secondary region, enable read-access geo-zone-redundant storage (RA-GZRS).
Microsoft recommends using GZRS/RA-GZRS for scenarios that require maximum availability and durability.
Geo-redundant storage (GRS): Data is replicated synchronously three times in the primary region using locally redundant storage (LRS), then replicated asynchronously to the secondary region. For read access to data in the secondary region, enable read-access geo-redundant storage (RA-GRS).
Azure SQL Database allows you to track and analyze the changes to your data using a feature called Temporal Tables. This feature requires that the tables themselves be converted to be temporal, which means the table will have special properties and will also have a corresponding history table. The Temporal Table feature allows you to use the history table to recover data that may have been deleted or updated. Recovering data from the history table is a manual process involving Transact-SQL, but could be helpful in certain scenarios such as if a user accidentally deletes important data that the business needs.
Another method to increase availability for Azure SQL Database is to use active geo-replication. Active geo-replication creates a replica of the database in another region that is asynchronously kept up to date. That replica is also readable, similar to an AG in IaaS. Underneath the surface, Azure is using the same methods as an AG, which is why some of the terminology and functionality is similar(primary and secondary logical servers, read-only databases, etc.).
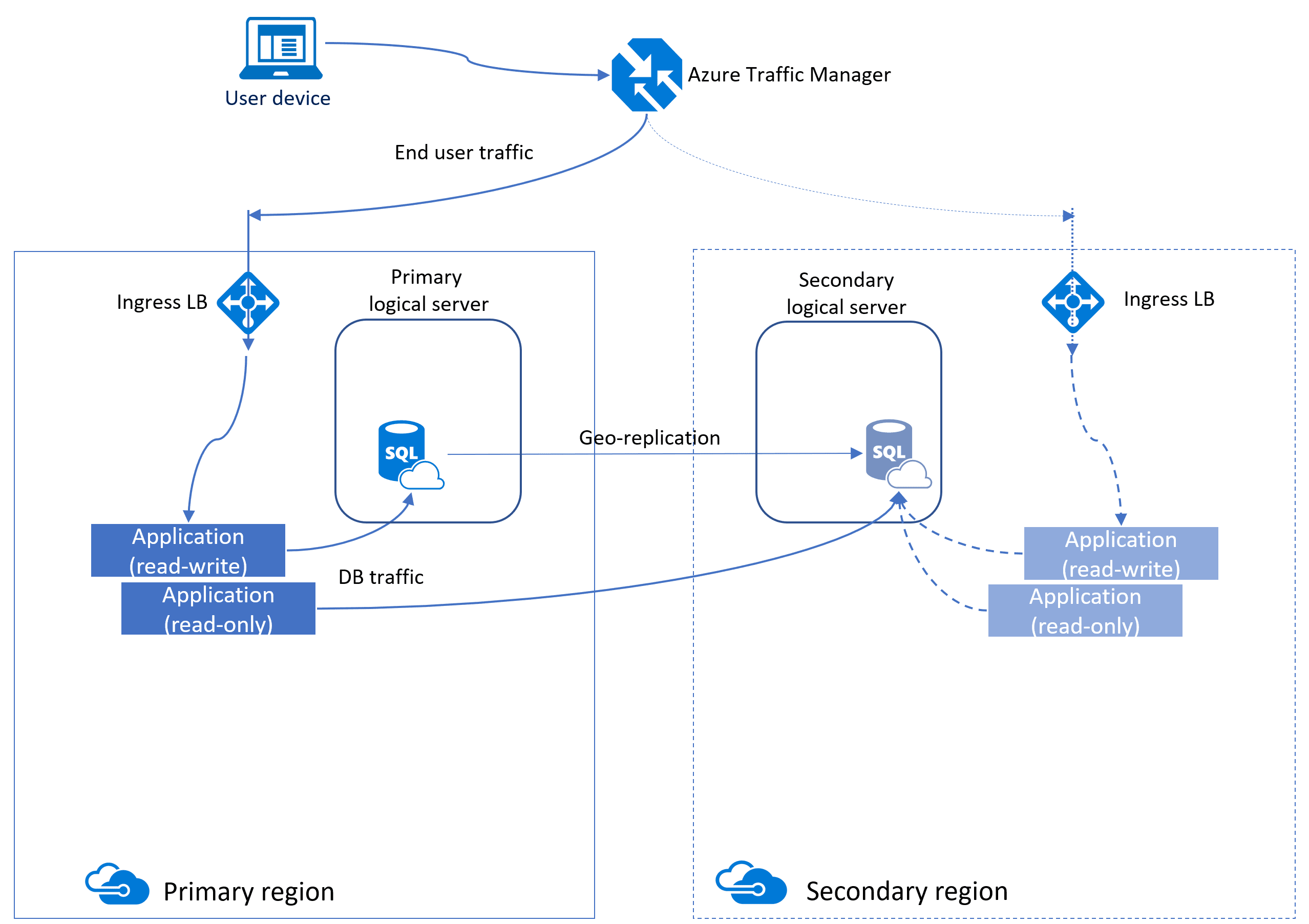
Auto-failover groups for Azure SQL Database and Azure SQL Database Managed Instance
An auto-failover group is an availability feature that can be used with both Azure SQL Database and Azure SQL Database Managed Instance. Autofailover groups let you manage how databases on an Azure SQL Database server or databases in Azure SQL Database Managed Instance are replicated to another region, and let you manage how failover could happen. The name assigned to the autofailover group must be unique within the *.database.windows.net domain. Azure SQL Database Managed Instance only supports one autofailover group.
Autofailover groups provide AG-like functionality called a listener, which allows both read-write and read-only activity. This functionality can be seen in the image below which is slightly different than the one for active geo-replication. There are two different kinds of listeners: one for read-write and one for read-only traffic. Behind the scenes in a failover, DNS is updated so clients will be able to point to the abstracted listener name and not need to know anything else. The database server containing the read-write copies is the primary, and the server that is receiving the transactions from the primary is a secondary.
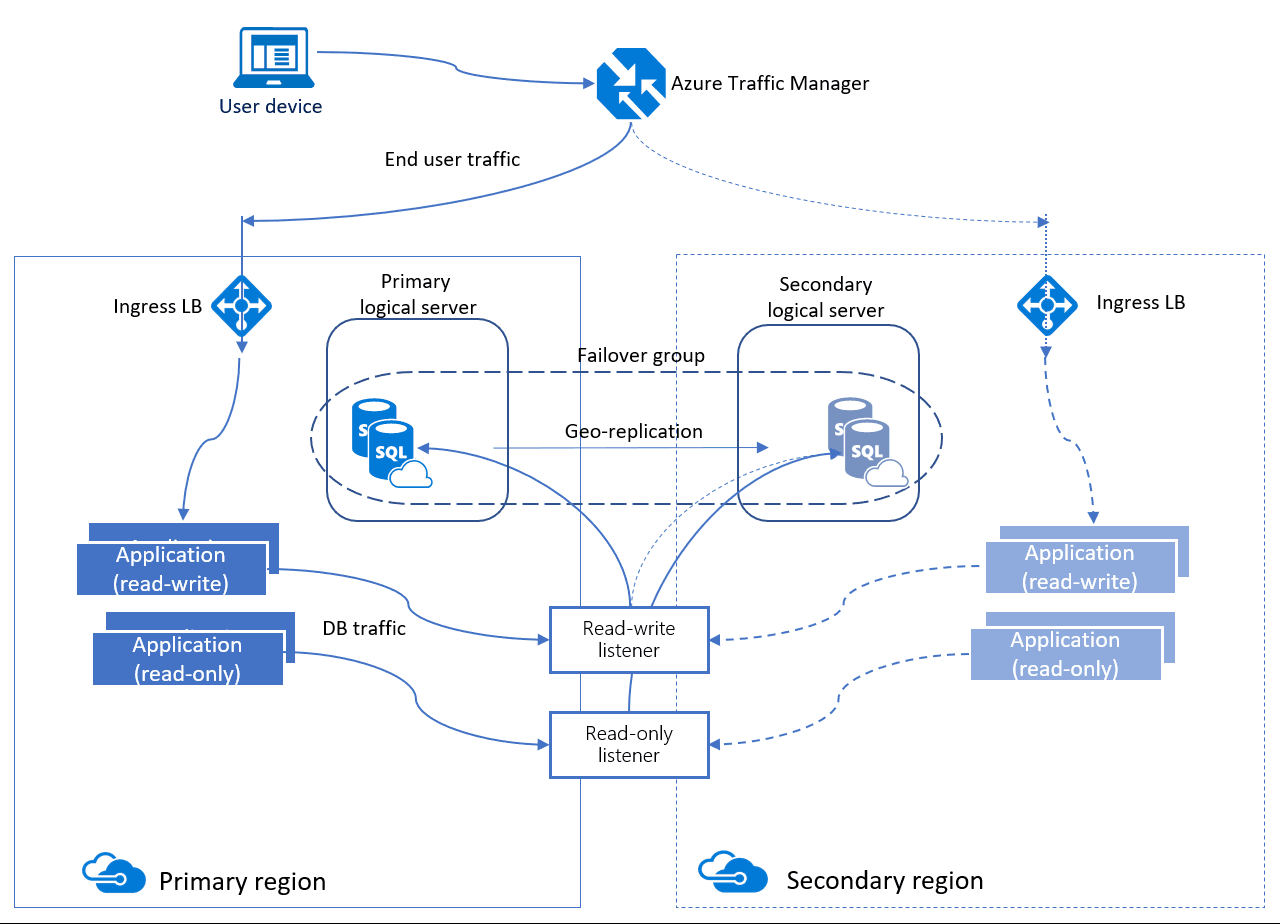
When it comes to fail over, autofailover groups have two different policies that can be configured.
• Automatic – By default, when a failure occurs and it is determined that a failover must happen, the autofailover group will switch regions. The ability to fail over automatically can be disabled.
• Read-Only – By default, if a failover occurs, the read-only listener is disabled to ensure performance of the new primary when the secondary is down. This behavior can be changed so that both types of traffic are enabled after a failover.
Failovers can be performed manually even if automatic failover is allowed. Depending on the type of failover, there could be data loss. Unplanned failovers could result in data loss if forced and the secondary is not fully synchronized with the primary. Configuring GracePeriodWithDataLossHours controls how long Azure waits before failing over. The default is one hour. If you have a tight RPO and cannot afford much data loss, set the value higher so Azure will wait longer before failing over, hopefully resulting in less data loss.
One autofailover group can contain one or more databases. The database size and edition will be the same on both the primary and secondary. The database is created automatically on the secondary through a process called seeding. Depending on the size of the database, this may take some time. Ensure that you plan accordingly and that you take into account things like the speed of the network.
Explanation
Azure Storage offers two options for geo-redundant replication. The only difference between these two options is how data is replicated in the primary region:
Geo-zone-redundant storage (GZRS): Data is replicated synchronously across three Azure availability zones in the primary region using zone-redundant storage (ZRS), then replicated asynchronously to the secondary region. For read access to data in the secondary region, enable read-access geo-zone-redundant storage (RA-GZRS).
Microsoft recommends using GZRS/RA-GZRS for scenarios that require maximum availability and durability.
Geo-redundant storage (GRS): Data is replicated synchronously three times in the primary region using locally redundant storage (LRS), then replicated asynchronously to the secondary region. For read access to data in the secondary region, enable read-access geo-redundant storage (RA-GRS).
Azure SQL Database allows you to track and analyze the changes to your data using a feature called Temporal Tables. This feature requires that the tables themselves be converted to be temporal, which means the table will have special properties and will also have a corresponding history table. The Temporal Table feature allows you to use the history table to recover data that may have been deleted or updated. Recovering data from the history table is a manual process involving Transact-SQL, but could be helpful in certain scenarios such as if a user accidentally deletes important data that the business needs.
Another method to increase availability for Azure SQL Database is to use active geo-replication. Active geo-replication creates a replica of the database in another region that is asynchronously kept up to date. That replica is also readable, similar to an AG in IaaS. Underneath the surface, Azure is using the same methods as an AG, which is why some of the terminology and functionality is similar(primary and secondary logical servers, read-only databases, etc.).
Auto-failover groups for Azure SQL Database and Azure SQL Database Managed Instance
An auto-failover group is an availability feature that can be used with both Azure SQL Database and Azure SQL Database Managed Instance. Autofailover groups let you manage how databases on an Azure SQL Database server or databases in Azure SQL Database Managed Instance are replicated to another region, and let you manage how failover could happen. The name assigned to the autofailover group must be unique within the *.database.windows.net domain. Azure SQL Database Managed Instance only supports one autofailover group.
Autofailover groups provide AG-like functionality called a listener, which allows both read-write and read-only activity. This functionality can be seen in the image below which is slightly different than the one for active geo-replication. There are two different kinds of listeners: one for read-write and one for read-only traffic. Behind the scenes in a failover, DNS is updated so clients will be able to point to the abstracted listener name and not need to know anything else. The database server containing the read-write copies is the primary, and the server that is receiving the transactions from the primary is a secondary.
When it comes to fail over, autofailover groups have two different policies that can be configured.
• Automatic – By default, when a failure occurs and it is determined that a failover must happen, the autofailover group will switch regions. The ability to fail over automatically can be disabled.
• Read-Only – By default, if a failover occurs, the read-only listener is disabled to ensure performance of the new primary when the secondary is down. This behavior can be changed so that both types of traffic are enabled after a failover.
Failovers can be performed manually even if automatic failover is allowed. Depending on the type of failover, there could be data loss. Unplanned failovers could result in data loss if forced and the secondary is not fully synchronized with the primary. Configuring GracePeriodWithDataLossHours controls how long Azure waits before failing over. The default is one hour. If you have a tight RPO and cannot afford much data loss, set the value higher so Azure will wait longer before failing over, hopefully resulting in less data loss.
One autofailover group can contain one or more databases. The database size and edition will be the same on both the primary and secondary. The database is created automatically on the secondary through a process called seeding. Depending on the size of the database, this may take some time. Ensure that you plan accordingly and that you take into account things like the speed of the network.
Question 17 Single Choice
Which isolation level should you choose if you want to prevent users reading data from blocking users writing data?
Explanation
Click "Show Answer" to see the explanation here
The Read Committed Snapshot Isolation level allows each reader to have their own version of the data and prevents readers from blocking writers.
Explanation
The Read Committed Snapshot Isolation level allows each reader to have their own version of the data and prevents readers from blocking writers.
Question 18 Multiple Choice
Scenario: You are working as a consultant at Advanced Idea Mechanics (A.I.M.) who is a privately funded think tank organized of a group of brilliant scientists whose sole dedication is to acquire and develop power through technological means. Their goal is to use this power to overthrow the governments of the world. They supply arms and technology to radicals and subversive organizations in order to foster a violent technological revolution of society while making a profit.
The company has 10,000 employees. Most employees are located in Europe. The company supports teams worldwide.
AIM has two main locations: the main office in London, England, and a manufacturing plant in Berlin, Germany.
At the moment, you are leading a Workgroup meeting with the IT Team where the topic of discussion is about the creation of a WSFC.
Which of the following tools can be used to create a WSFC in Azure for AGs and FCIs? (Select all that apply)
Explanation
Click "Show Answer" to see the explanation here
The Failover Cluster feature can be enabled using Server Manager, or via PowerShell.
For all availability configurations of availability groups (AGs), an underlying cluster is required. There are many aspects of setting up a cluster that you need to be aware of.
Considerations for a Windows Server Failover Cluster in Azure
Deploying a Windows Server Failover Cluster (WSFC) in Azure is similar to configuring one on premises. There are some Azure-specific considerations, which is what this section will focus on.
One of the most important aspects is deciding what to use for a witness resource. Witness is a core component of the quorum mechanism. Quorum is what helps ensure that everything in the WSFC stays up and running. If you lose quorum, the WSFC will go down taking an AG or FCI with it. The witness resource can be a disk, file share (SMB 2.0 or later), or cloud witness. It is recommended that you use a cloud witness as it is fully Azure-based, especially for solutions that will span multiple Azure regions or are hybrid. The cloud witness feature is available in Windows Server 2016 and later.
The next consideration is the Microsoft Distributed Transaction Coordinator (DTC or MSDTC). Some applications use it, but the majority of applications do not. If you require DTC and are deploying an AG or FCI, you should cluster DTC. Clustering DTC requires a shared disk to work properly even though you may not require one otherwise, as in the case of an AG.
Most WSFC deployments require the use of both AD DS and DNS; FCIs always do. AGs can be configured without requiring AD DS but still needing DNS. In Windows Server 2016, there is a variant of a WSFC called a Workgroup Cluster, which can be used with AGs only.
The WSFC itself needs a unique name in the domain (and DNS) and requires an object in AD DS called the cluster name object (CNO). Anything created in context of the WSFC that has a name will require a unique name, as well as at least one IP address. If the configuration will stay in a single region, IP addresses will be in a single subnet. If the WSFC will span multiple regions, more than one IP address will be associated with the WSFC, as well as an AG if it spans multiple regions as part of the WSFC.
A typical Azure-based WSFC will only require a single virtual network card (vNIC). Unlike the setup for an on-premises physical or virtual server, the IP address for the vNIC has to be configured in Azure, not in the VM. That means inside the VM it will show up as a dynamic (DHCP) address. This is expected, however cluster validation will generate a warning that can safely be ignored.
Considerations for the WSFC’s IP address is also different from on premises. There is no way to reserve the IP address at the Azure level since it is fully maintained within the guest configuration. This means that if subsequent resources that use an IP address in Azure use DHCP, you must check for conflicts.
The failover clustering feature
Before a WSFC can be configured, the underlying Windows feature must be enabled on every node that will participate in the WSFC. This can be done in one of two ways: using the Server Manager or via PowerShell.
In Server Manager, Failover Clustering must be enabled in the Add Roles and Features Wizard.
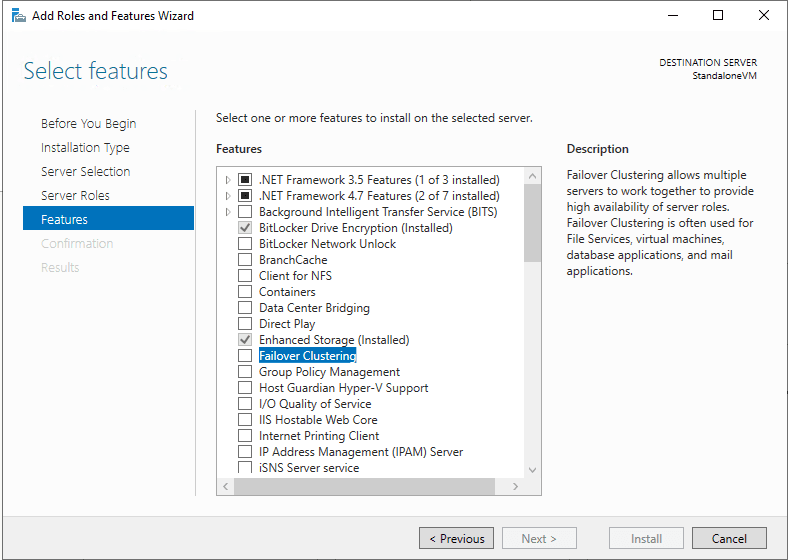
To enable the feature via PowerShell, use the following command, which will also install the utilities, which will be used to administer a WSFC:
- PowerShell
- Install-WindowsFeature Failover-Clustering -IncludeManagementTools
Cluster validation
For a WSFC to be considered supported, it must pass cluster validation. Cluster validation is a built-in process that checks the nodes via a series of tests to ensure that the entire configuration is suitable for clustering. After running validation, each of the tests will come back with an error, a warning, a pass, or a message that the test is not applicable. Warnings are acceptable if that condition is expected in your environment. If not, it should be addressed. All errors must be resolved.
Validation can be run via Failover Cluster Manager or by using the Test-Cluster PowerShell cmdlet.
For FCIs, these tests also check the shared storage to ensure that the disks are configured correctly. For AGs with no shared storage, in Windows Server 2016 and later, the results will come back as not applicable. For Windows Server 2012 R2, the disk tests will show a warning when there are no shared disks. This state is expected.
Once the configuration is deemed valid by the cluster validation process, you can then create the WSFC.
Create a Windows Server Failover Cluster
To create a WSFC properly in Azure, you cannot use the Wizard in Failover Cluster Manager for FCIs or AGs deployed using Windows Server 2016 and earlier. Due to the DHCP issue mentioned earlier, currently the only way to create the WSFC is to use PowerShell and specify the IP address. This could change in future versions of Windows Server.
For a configuration that has shared storage, use the following syntax:
- PowerShell
- New-Cluster -Name MyWSFC -Node Node1,Node2,…,NodeN -StaticAddress w.x.y.z
Where MyWSFC is the name of the WSFC you want, Node1, Node2,…, NodeN are the names of the nodes that will participate in the WSFC, and w.x.y.z is the IP address of the WSFC (for example: 10.252.1.100.) If you are creating a WSFC that spans multiple subnets, you can specify more than one IP address for -StaticAddress separated by commas.
For a configuration that does not have shared storage, add the -NoStorage option.
- PowerShell
- New-Cluster -Name MyWSFC -Node Node1,Node2,…,NodeN -StaticAddress w.x.y.z -NoStorage
For a Workgroup Cluster that will only use DNS, the syntax is also slightly different.
- PowerShell
- New-Cluster -Name MyWSFC -Node Node1,Node2,…,NodeN -StaticAddress w.x.y.z -NoStorage -AdministrativeAccessPoint DNS
Windows Server 2019 by default will use a distributed network name for IaaS. A distributed network name is one that creates just a network name, but the IP address is tied to the underlying nodes. You no longer need to specify an IP address as shown above if it is not needed or necessary. A distributed network name is for the WSFC’s name only; it cannot be used with the name of an AG or FCI.
The WSFC creation mechanism in Windows Server 2019 detects if it is running in Azure or not and will create the cluster using a distributed network name unless you tell it to do something else. Currently, distributed network names are incompatible with FCIs and while they do work with AGs, if you encounter an issue, you may want to consider deploying a WSFC traditionally using PowerShell. You need to add one more option: -ManagementPointNetwork with a value of Singleton. An example would look like this:
- PowerShell
- New-Cluster -Name MyWSFC -Node Node1,Node2,…,NodeN -StaticAddress w.x.y.z -NoStorage -ManagementPointNetwork Singleton
For a Workgroup Cluster, you will need to ensure the name and IP address(es) are in DNS for any name or IP address created in the context of the WSFC such as the WSFC itself, an FCI name and IP address, and an AG listener name and IP address.
With Windows Server 2019, Microsoft changed how WSFCs are created by default in Azure. Instead of creating a network name and an IP address, it uses a distributed network name. This is not yet supported with either of the Always On features, so it is still required to create the WSFC using the method described above.
Test the Windows Server Failover Cluster
After the WSFC is created but before configuring FCIs or AGs, test that the WSFC is working properly For clusters that require shared storage, such as for those supporting a SQL Server Failover Cluster Instance, it is important that your test the ability for all of the nodes in the cluster to access any shared storage, and to take ownership of the storage as they would in a failover. You can do this by clicking on Storage, then Disks in Failover Cluster Manager, as shown in the image below. If you right-click on each clustered disk device, you will see the option Move Available Storage. If you choose the Select Node option, you can force the storage to fail over to the other nodes in the cluster to confirm this functionality.
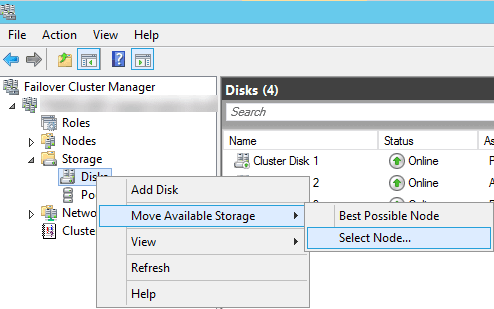
Explanation
The Failover Cluster feature can be enabled using Server Manager, or via PowerShell.
For all availability configurations of availability groups (AGs), an underlying cluster is required. There are many aspects of setting up a cluster that you need to be aware of.
Considerations for a Windows Server Failover Cluster in Azure
Deploying a Windows Server Failover Cluster (WSFC) in Azure is similar to configuring one on premises. There are some Azure-specific considerations, which is what this section will focus on.
One of the most important aspects is deciding what to use for a witness resource. Witness is a core component of the quorum mechanism. Quorum is what helps ensure that everything in the WSFC stays up and running. If you lose quorum, the WSFC will go down taking an AG or FCI with it. The witness resource can be a disk, file share (SMB 2.0 or later), or cloud witness. It is recommended that you use a cloud witness as it is fully Azure-based, especially for solutions that will span multiple Azure regions or are hybrid. The cloud witness feature is available in Windows Server 2016 and later.
The next consideration is the Microsoft Distributed Transaction Coordinator (DTC or MSDTC). Some applications use it, but the majority of applications do not. If you require DTC and are deploying an AG or FCI, you should cluster DTC. Clustering DTC requires a shared disk to work properly even though you may not require one otherwise, as in the case of an AG.
Most WSFC deployments require the use of both AD DS and DNS; FCIs always do. AGs can be configured without requiring AD DS but still needing DNS. In Windows Server 2016, there is a variant of a WSFC called a Workgroup Cluster, which can be used with AGs only.
The WSFC itself needs a unique name in the domain (and DNS) and requires an object in AD DS called the cluster name object (CNO). Anything created in context of the WSFC that has a name will require a unique name, as well as at least one IP address. If the configuration will stay in a single region, IP addresses will be in a single subnet. If the WSFC will span multiple regions, more than one IP address will be associated with the WSFC, as well as an AG if it spans multiple regions as part of the WSFC.
A typical Azure-based WSFC will only require a single virtual network card (vNIC). Unlike the setup for an on-premises physical or virtual server, the IP address for the vNIC has to be configured in Azure, not in the VM. That means inside the VM it will show up as a dynamic (DHCP) address. This is expected, however cluster validation will generate a warning that can safely be ignored.
Considerations for the WSFC’s IP address is also different from on premises. There is no way to reserve the IP address at the Azure level since it is fully maintained within the guest configuration. This means that if subsequent resources that use an IP address in Azure use DHCP, you must check for conflicts.
The failover clustering feature
Before a WSFC can be configured, the underlying Windows feature must be enabled on every node that will participate in the WSFC. This can be done in one of two ways: using the Server Manager or via PowerShell.
In Server Manager, Failover Clustering must be enabled in the Add Roles and Features Wizard.
To enable the feature via PowerShell, use the following command, which will also install the utilities, which will be used to administer a WSFC:
- PowerShell
- Install-WindowsFeature Failover-Clustering -IncludeManagementTools
Cluster validation
For a WSFC to be considered supported, it must pass cluster validation. Cluster validation is a built-in process that checks the nodes via a series of tests to ensure that the entire configuration is suitable for clustering. After running validation, each of the tests will come back with an error, a warning, a pass, or a message that the test is not applicable. Warnings are acceptable if that condition is expected in your environment. If not, it should be addressed. All errors must be resolved.
Validation can be run via Failover Cluster Manager or by using the Test-Cluster PowerShell cmdlet.
For FCIs, these tests also check the shared storage to ensure that the disks are configured correctly. For AGs with no shared storage, in Windows Server 2016 and later, the results will come back as not applicable. For Windows Server 2012 R2, the disk tests will show a warning when there are no shared disks. This state is expected.
Once the configuration is deemed valid by the cluster validation process, you can then create the WSFC.
Create a Windows Server Failover Cluster
To create a WSFC properly in Azure, you cannot use the Wizard in Failover Cluster Manager for FCIs or AGs deployed using Windows Server 2016 and earlier. Due to the DHCP issue mentioned earlier, currently the only way to create the WSFC is to use PowerShell and specify the IP address. This could change in future versions of Windows Server.
For a configuration that has shared storage, use the following syntax:
- PowerShell
- New-Cluster -Name MyWSFC -Node Node1,Node2,…,NodeN -StaticAddress w.x.y.z
Where MyWSFC is the name of the WSFC you want, Node1, Node2,…, NodeN are the names of the nodes that will participate in the WSFC, and w.x.y.z is the IP address of the WSFC (for example: 10.252.1.100.) If you are creating a WSFC that spans multiple subnets, you can specify more than one IP address for -StaticAddress separated by commas.
For a configuration that does not have shared storage, add the -NoStorage option.
- PowerShell
- New-Cluster -Name MyWSFC -Node Node1,Node2,…,NodeN -StaticAddress w.x.y.z -NoStorage
For a Workgroup Cluster that will only use DNS, the syntax is also slightly different.
- PowerShell
- New-Cluster -Name MyWSFC -Node Node1,Node2,…,NodeN -StaticAddress w.x.y.z -NoStorage -AdministrativeAccessPoint DNS
Windows Server 2019 by default will use a distributed network name for IaaS. A distributed network name is one that creates just a network name, but the IP address is tied to the underlying nodes. You no longer need to specify an IP address as shown above if it is not needed or necessary. A distributed network name is for the WSFC’s name only; it cannot be used with the name of an AG or FCI.
The WSFC creation mechanism in Windows Server 2019 detects if it is running in Azure or not and will create the cluster using a distributed network name unless you tell it to do something else. Currently, distributed network names are incompatible with FCIs and while they do work with AGs, if you encounter an issue, you may want to consider deploying a WSFC traditionally using PowerShell. You need to add one more option: -ManagementPointNetwork with a value of Singleton. An example would look like this:
- PowerShell
- New-Cluster -Name MyWSFC -Node Node1,Node2,…,NodeN -StaticAddress w.x.y.z -NoStorage -ManagementPointNetwork Singleton
For a Workgroup Cluster, you will need to ensure the name and IP address(es) are in DNS for any name or IP address created in the context of the WSFC such as the WSFC itself, an FCI name and IP address, and an AG listener name and IP address.
With Windows Server 2019, Microsoft changed how WSFCs are created by default in Azure. Instead of creating a network name and an IP address, it uses a distributed network name. This is not yet supported with either of the Always On features, so it is still required to create the WSFC using the method described above.
Test the Windows Server Failover Cluster
After the WSFC is created but before configuring FCIs or AGs, test that the WSFC is working properly For clusters that require shared storage, such as for those supporting a SQL Server Failover Cluster Instance, it is important that your test the ability for all of the nodes in the cluster to access any shared storage, and to take ownership of the storage as they would in a failover. You can do this by clicking on Storage, then Disks in Failover Cluster Manager, as shown in the image below. If you right-click on each clustered disk device, you will see the option Move Available Storage. If you choose the Select Node option, you can force the storage to fail over to the other nodes in the cluster to confirm this functionality.
Question 19 Single Choice
Identify the missing word(s) in the following sentence within the context of Microsoft Azure.
Dick Grayson has just joined Wayne Enterprises and asks Bruce Wayne a common question, “What is the difference between Microsoft Entra ID and Windows Server Active Directory?”
Bruce replies that “[A] use(s) a protocol called Kerberos to provide authentication using tickets, and it is queried by the Lightweight Directory Access Protocol (LDAP). [B] uses HTTPS protocols like SAML and OpenID Connect for authentication and uses OAuth for authorization.”
Explanation
Click "Show Answer" to see the explanation here
A common question is what is the difference between Microsoft Entra ID and Windows Server Active Directory, which we’ll refer to simply as ‘Active Directory’?
Both solutions provide authentication services and identity management, but in different ways—Active Directory uses a protocol called Kerberos to provide authentication using tickets, and it is queried by the Lightweight Directory Access Protocol (LDAP). Microsoft Entra ID uses HTTPS protocols like SAML and OpenID Connect for authentication and uses OAuth for authorization.
The two services have different use cases—for example, you cannot join a Windows Server to an Microsoft Entra ID domain and work together in most organizations to provide a single set of user identities. A service called Microsoft Entra ID Connect connects your Microsoft Entra identities with your Microsoft Entra ID.
Microsoft Entra ID was previously known as Azure Active Directory (Azure AD).
Explanation
A common question is what is the difference between Microsoft Entra ID and Windows Server Active Directory, which we’ll refer to simply as ‘Active Directory’?
Both solutions provide authentication services and identity management, but in different ways—Active Directory uses a protocol called Kerberos to provide authentication using tickets, and it is queried by the Lightweight Directory Access Protocol (LDAP). Microsoft Entra ID uses HTTPS protocols like SAML and OpenID Connect for authentication and uses OAuth for authorization.
The two services have different use cases—for example, you cannot join a Windows Server to an Microsoft Entra ID domain and work together in most organizations to provide a single set of user identities. A service called Microsoft Entra ID Connect connects your Microsoft Entra identities with your Microsoft Entra ID.
Microsoft Entra ID was previously known as Azure Active Directory (Azure AD).
Question 20 Single Choice
Identify the missing word(s) in the following sentence within the context of Microsoft Azure.
When you deploy an SQL Server VM from the Azure Marketplace, part of the process installs the[?]. Extensions are code that is executed on your VM post-deployment, typically to perform post deployment configurations. Some examples are installing anti-virus features, or installing a Windows feature.
Explanation
Click "Show Answer" to see the explanation here
SQL Server IaaS Agent Extension
When you deploy an SQL Server VM from the Azure Marketplace, part of the process installs the IaaS Agent Extension.
Extensions are code that is executed on your VM post-deployment, typically to perform post deployment configurations. Some examples are installing anti-virus features, or installing a Windows feature. The SQL Server IaaS Agent Extension provides three key features that can reduce your administrative overhead.
• SQL Server automated backup
• SQL Server automated patching
• Azure Key Vault integration
In addition to these features, the extension allows you to view information about your SQL Server’s configuration and storage utilization.
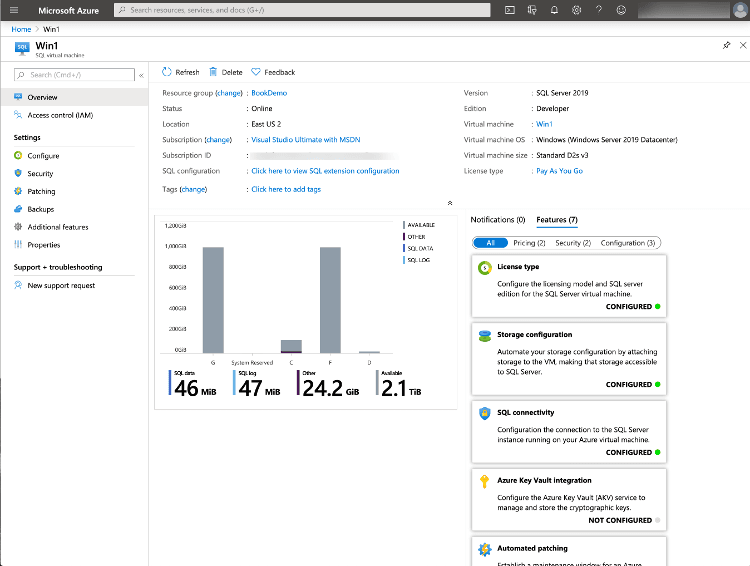
Explanation
SQL Server IaaS Agent Extension
When you deploy an SQL Server VM from the Azure Marketplace, part of the process installs the IaaS Agent Extension.
Extensions are code that is executed on your VM post-deployment, typically to perform post deployment configurations. Some examples are installing anti-virus features, or installing a Windows feature. The SQL Server IaaS Agent Extension provides three key features that can reduce your administrative overhead.
• SQL Server automated backup
• SQL Server automated patching
• Azure Key Vault integration
In addition to these features, the extension allows you to view information about your SQL Server’s configuration and storage utilization.


