
Microsoft Certified: Azure Solutions Architect Expert - (AZ-305) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 1 Single Choice
You have the Azure subscriptions shown in the following table.
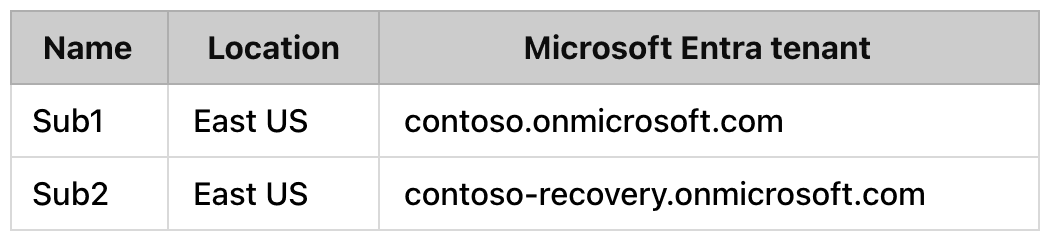
Contoso.onmicrosft.com contains a user named User1.
You need to deploy a solution to protect against ransomware attacks. The solution must meet the following requirements:
Ensure that all the resources in Sub1 are backed up by using Azure Backup.
Require that User1 first be assigned a role for Sub2 before the user can make major changes to the backup configuration.
What should you create in subscription Sub1?
Explanation

Click "Show Answer" to see the explanation here
"Ensure that all the resources in Sub1 are backed up using Azure Backup." This requirement is all about setting up backups for Sub1.
A Recovery Services vault is correct. Azure Backup uses the Recovery Services vault to hold backup data. You can use Recovery Services vaults to hold backup data for various Azure services like IaaS VMs (Linux or Windows) and SQL Server in Azure VMs. It helps protect your critical business systems and backup data from ransomware attacks by implementing preventive measures for security at every potential attack stage. It provides security to your backup environment, both when your data is in transit and at rest. By Configuring Azure Backup in Sub1 with a Recovery Services vault, you can ensure that all resources in that subscription are backed up regularly.
A Resource Guard is incorrect. Azure Backup uses the Resource Guard as an additional authorization for both Recovery Services vault and Backup vault. Therefore, to perform a critical operation successfully like Multi-User Authorization (MUA) protection. Azure Backup uses another Azure resource called the Resource Guard to ensure critical operations are performed only with applicable authorization. However the main responsibility of Resource guard is to serve as an additional authorization mechanism for Azure Backup, specifically for Recovery Services vaults or Backup vaults.
An Azure Site Recovery job is incorrect. Azure Site Recovery (ASR) is designed for disaster recovery scenarios. It ensures the protection of applications by replicating them from on-premises servers to Azure or another datacenter. ASR plays a crucial role in maintaining business continuity, allowing business applications and workloads to remain operational during outages. It replicates workloads running on physical and virtual machines (VMs) from a primary site to a secondary location. When an outage occurs at your primary site, a failover to the secondary location is initiated, enabling continued access to applications. Once the primary location is restored, you can fail back to it. ASR's replication capabilities cover various scenarios, including the replication of on-premises VMware VMs, Hyper-V VMs, physical servers (both Windows and Linux), as well as Azure Stack VMs to Azure. Additionally, it supports the replication of AWS Windows instances to Azure, providing a comprehensive solution for disaster recovery and data protection. However, ASR is not designed for regular backups and does not provide specific control for protecting against ransomware attacks on a day-to-day basis. The primary focus is on managing and recovering from disaster recovery scenarios.
Microsoft Azure Backup Server (MABS) is incorrect. Microsoft Azure Backup Server (MABS) is an on-premises backup solution seamlessly integrated with the Azure Backup service. Its primary purpose is to protect essential data stored on Windows servers and clients within a local infrastructure. MABS is designed to support a range of application workloads, including but not limited to SQL Server, SharePoint, and Exchange. However, it is important to note that Microsoft Azure Backup Server is not directly suitable for backups of Azure resources, especially in scenarios like Sub1. MABS is designed to safeguard data within a on-premises environment rather than directly in the cloud.
The Microsoft Azure Recovery Services (MARS) agent is incorrect. The Microsoft Azure Recovery Services (MARS) agent is used for protecting on-premises servers and applications. It allows you to plan daily backups, making sure all your important files, folders, and even the system state from on-premises machines and Azure VMs are securely saved. This provides an additional level of protection for your data. While it provides backup capabilities, it is not used for creating backups of Azure resources directly. In conclusion, choosing the Recovery Services vault is the correct option as it aligns with the specific requirements of backing up resources in Sub1 to protect against ransomware attacks.
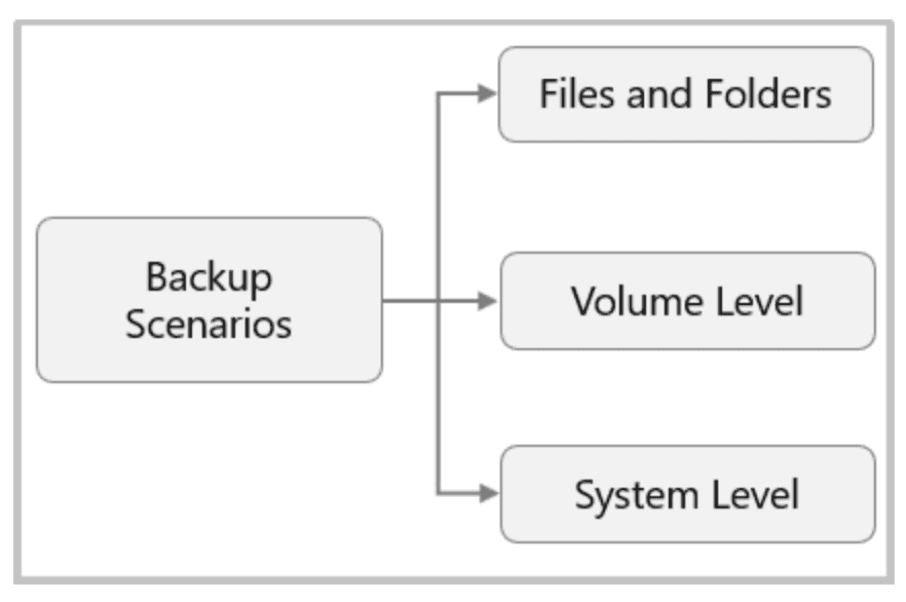
The MARS agent supports the following backup scenarios:
Read More:
https://learn.microsoft.com/en-us/azure/backup/backup-azure-recovery-services-vault-overview
https://learn.microsoft.com/en-us/azure/backup/backup-create-recovery-services-vault
https://learn.microsoft.com/en-us/azure/backup/backup-azure-about-mars
https://learn.microsoft.com/en-us/azure/backup/install-mars-agent
https://learn.microsoft.com/en-us/azure/backup/backup-mabs-whats-new-mabs
https://learn.microsoft.com/en-us/azure/site-recovery/site-recovery-overview
Explanation
"Ensure that all the resources in Sub1 are backed up using Azure Backup." This requirement is all about setting up backups for Sub1.
A Recovery Services vault is correct. Azure Backup uses the Recovery Services vault to hold backup data. You can use Recovery Services vaults to hold backup data for various Azure services like IaaS VMs (Linux or Windows) and SQL Server in Azure VMs. It helps protect your critical business systems and backup data from ransomware attacks by implementing preventive measures for security at every potential attack stage. It provides security to your backup environment, both when your data is in transit and at rest. By Configuring Azure Backup in Sub1 with a Recovery Services vault, you can ensure that all resources in that subscription are backed up regularly.
A Resource Guard is incorrect. Azure Backup uses the Resource Guard as an additional authorization for both Recovery Services vault and Backup vault. Therefore, to perform a critical operation successfully like Multi-User Authorization (MUA) protection. Azure Backup uses another Azure resource called the Resource Guard to ensure critical operations are performed only with applicable authorization. However the main responsibility of Resource guard is to serve as an additional authorization mechanism for Azure Backup, specifically for Recovery Services vaults or Backup vaults.
An Azure Site Recovery job is incorrect. Azure Site Recovery (ASR) is designed for disaster recovery scenarios. It ensures the protection of applications by replicating them from on-premises servers to Azure or another datacenter. ASR plays a crucial role in maintaining business continuity, allowing business applications and workloads to remain operational during outages. It replicates workloads running on physical and virtual machines (VMs) from a primary site to a secondary location. When an outage occurs at your primary site, a failover to the secondary location is initiated, enabling continued access to applications. Once the primary location is restored, you can fail back to it. ASR's replication capabilities cover various scenarios, including the replication of on-premises VMware VMs, Hyper-V VMs, physical servers (both Windows and Linux), as well as Azure Stack VMs to Azure. Additionally, it supports the replication of AWS Windows instances to Azure, providing a comprehensive solution for disaster recovery and data protection. However, ASR is not designed for regular backups and does not provide specific control for protecting against ransomware attacks on a day-to-day basis. The primary focus is on managing and recovering from disaster recovery scenarios.
Microsoft Azure Backup Server (MABS) is incorrect. Microsoft Azure Backup Server (MABS) is an on-premises backup solution seamlessly integrated with the Azure Backup service. Its primary purpose is to protect essential data stored on Windows servers and clients within a local infrastructure. MABS is designed to support a range of application workloads, including but not limited to SQL Server, SharePoint, and Exchange. However, it is important to note that Microsoft Azure Backup Server is not directly suitable for backups of Azure resources, especially in scenarios like Sub1. MABS is designed to safeguard data within a on-premises environment rather than directly in the cloud.
The Microsoft Azure Recovery Services (MARS) agent is incorrect. The Microsoft Azure Recovery Services (MARS) agent is used for protecting on-premises servers and applications. It allows you to plan daily backups, making sure all your important files, folders, and even the system state from on-premises machines and Azure VMs are securely saved. This provides an additional level of protection for your data. While it provides backup capabilities, it is not used for creating backups of Azure resources directly. In conclusion, choosing the Recovery Services vault is the correct option as it aligns with the specific requirements of backing up resources in Sub1 to protect against ransomware attacks.
The MARS agent supports the following backup scenarios:
Read More:
https://learn.microsoft.com/en-us/azure/backup/backup-azure-recovery-services-vault-overview
https://learn.microsoft.com/en-us/azure/backup/backup-create-recovery-services-vault
https://learn.microsoft.com/en-us/azure/backup/backup-azure-about-mars
https://learn.microsoft.com/en-us/azure/backup/install-mars-agent
https://learn.microsoft.com/en-us/azure/backup/backup-mabs-whats-new-mabs
https://learn.microsoft.com/en-us/azure/site-recovery/site-recovery-overview
Question 2 Single Choice
You have the Azure subscriptions shown in the following table.
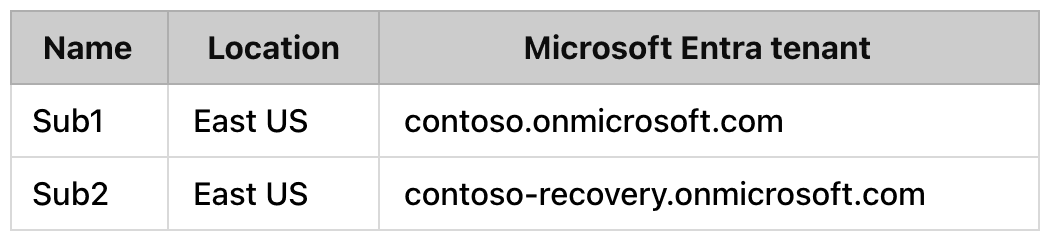
Contoso.onmicrosft.com contains a user named User1.
You need to deploy a solution to protect against ransomware attacks. The solution must meet the following requirements:
Ensure that all the resources in Sub1 are backed up by using Azure Backup.
Require that User1 first be assigned a role for Sub2 before the user can make major changes to the backup configuration.
What should you create in subscription Sub2?
Explanation
Click "Show Answer" to see the explanation here
"Require that User1 be assigned a role for Sub2 before the user can make major changes to the backup configuration." This requirement is about ensuring that User1 has the necessary permissions to make changes to the backup setup in Sub2.
A Resource Guard is correct. Azure Backup uses the Resource Guard as an additional authorization for both Recovery Services vault and Backup vault. Therefore, to perform a critical operation successfully like Multi-User Authorization (MUA) protection. Azure Backup uses another Azure resource called the Resource Guard to ensure critical operations are performed only with applicable authorization. The main responsibility of Resource guard is to serve as an additional authorization mechanism for Azure Backup, specifically for Recovery Services vaults or Backup vaults.
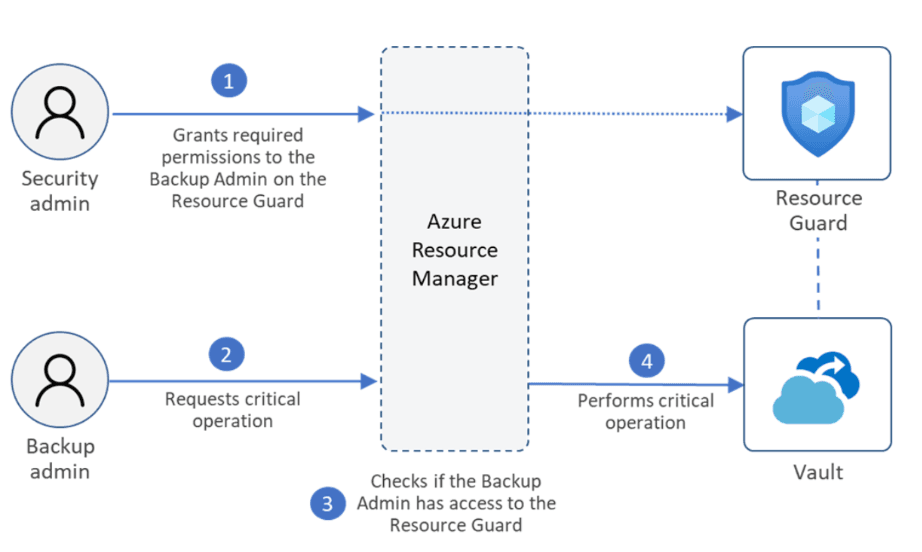
A Recovery Services vault is incorrect. Azure Backup utilizes the Recovery Services vault to store backup data, offering protection for a range of Azure services such as IaaS VMs (Linux or Windows) and SQL Server in Azure VMs. This safeguards essential business systems and backup data against ransomware attacks by implementing security measures at every potential attack stage. The security extends to both data in transit and at rest. Configuring Azure Backup in Sub1 with a Recovery Services vault ensures regular backups for all resources in that subscription. However, it does not involve configuring roles for users in Azure.
An Azure Site Recovery job is incorrect. Azure Site Recovery (ASR) is designed for disaster recovery scenarios. It ensures the protection of applications by replicating them from on-premises servers to Azure or another datacenter. ASR plays a crucial role in maintaining business continuity, allowing business applications and workloads to remain operational during outages. It replicates workloads running on physical and virtual machines (VMs) from a primary site to a secondary location. When an outage occurs at your primary site, a failover to the secondary location is initiated, enabling continued access to applications. Once the primary location is restored, you can fail back to it. ASR's replication capabilities cover various scenarios, including the replication of on-premises VMware VMs, Hyper-V VMs, physical servers (both Windows and Linux), as well as Azure Stack VMs to Azure. Additionally, it supports the replication of AWS Windows instances to Azure, providing a comprehensive solution for disaster recovery and data protection. However, ASR is not designed for assigning roles for users and does not provide specific control for protecting against ransomware attacks on a day-to-day basis. The primary focus is on managing and recovering from disaster recovery scenarios.
Microsoft Azure Backup Server (MABS) is incorrect. Microsoft Azure Backup Server (MABS) is an on-premises backup solution seamlessly integrated with the Azure Backup service. Its primary purpose is to protect essential data stored on Windows servers and clients within a local infrastructure. MABS is designed to support a range of application workloads, including but not limited to SQL Server, SharePoint, and Exchange. However, it is important to note that Microsoft Azure Backup Server is not directly suitable for configuring roles for users in Azure, especially in scenarios like Sub2. MABS is designed to safeguard data within an on-premises environment rather than directly in the cloud.
The Microsoft Azure Recovery Services (MARS) agent is incorrect. The Microsoft Azure Recovery Services (MARS) agent is used for protecting on-premises servers and applications. It allows you to plan daily backups, making sure all your important files, folders, and even the system state from on-premises machines and Azure VMs are securely saved. This provides an additional level of protection for your data. However, it doesn't specifically assist in configuring roles for users.
Read More:
https://learn.microsoft.com/en-us/azure/backup/backup-azure-recovery-services-vault-overview
https://learn.microsoft.com/en-us/azure/backup/backup-create-recovery-services-vault
https://learn.microsoft.com/en-us/azure/backup/backup-azure-about-mars
https://learn.microsoft.com/en-us/azure/backup/install-mars-agent
https://learn.microsoft.com/en-us/azure/backup/backup-mabs-whats-new-mabs
https://learn.microsoft.com/en-us/azure/site-recovery/site-recovery-overview
Explanation
"Require that User1 be assigned a role for Sub2 before the user can make major changes to the backup configuration." This requirement is about ensuring that User1 has the necessary permissions to make changes to the backup setup in Sub2.
A Resource Guard is correct. Azure Backup uses the Resource Guard as an additional authorization for both Recovery Services vault and Backup vault. Therefore, to perform a critical operation successfully like Multi-User Authorization (MUA) protection. Azure Backup uses another Azure resource called the Resource Guard to ensure critical operations are performed only with applicable authorization. The main responsibility of Resource guard is to serve as an additional authorization mechanism for Azure Backup, specifically for Recovery Services vaults or Backup vaults.
A Recovery Services vault is incorrect. Azure Backup utilizes the Recovery Services vault to store backup data, offering protection for a range of Azure services such as IaaS VMs (Linux or Windows) and SQL Server in Azure VMs. This safeguards essential business systems and backup data against ransomware attacks by implementing security measures at every potential attack stage. The security extends to both data in transit and at rest. Configuring Azure Backup in Sub1 with a Recovery Services vault ensures regular backups for all resources in that subscription. However, it does not involve configuring roles for users in Azure.
An Azure Site Recovery job is incorrect. Azure Site Recovery (ASR) is designed for disaster recovery scenarios. It ensures the protection of applications by replicating them from on-premises servers to Azure or another datacenter. ASR plays a crucial role in maintaining business continuity, allowing business applications and workloads to remain operational during outages. It replicates workloads running on physical and virtual machines (VMs) from a primary site to a secondary location. When an outage occurs at your primary site, a failover to the secondary location is initiated, enabling continued access to applications. Once the primary location is restored, you can fail back to it. ASR's replication capabilities cover various scenarios, including the replication of on-premises VMware VMs, Hyper-V VMs, physical servers (both Windows and Linux), as well as Azure Stack VMs to Azure. Additionally, it supports the replication of AWS Windows instances to Azure, providing a comprehensive solution for disaster recovery and data protection. However, ASR is not designed for assigning roles for users and does not provide specific control for protecting against ransomware attacks on a day-to-day basis. The primary focus is on managing and recovering from disaster recovery scenarios.
Microsoft Azure Backup Server (MABS) is incorrect. Microsoft Azure Backup Server (MABS) is an on-premises backup solution seamlessly integrated with the Azure Backup service. Its primary purpose is to protect essential data stored on Windows servers and clients within a local infrastructure. MABS is designed to support a range of application workloads, including but not limited to SQL Server, SharePoint, and Exchange. However, it is important to note that Microsoft Azure Backup Server is not directly suitable for configuring roles for users in Azure, especially in scenarios like Sub2. MABS is designed to safeguard data within an on-premises environment rather than directly in the cloud.
The Microsoft Azure Recovery Services (MARS) agent is incorrect. The Microsoft Azure Recovery Services (MARS) agent is used for protecting on-premises servers and applications. It allows you to plan daily backups, making sure all your important files, folders, and even the system state from on-premises machines and Azure VMs are securely saved. This provides an additional level of protection for your data. However, it doesn't specifically assist in configuring roles for users.
Read More:
https://learn.microsoft.com/en-us/azure/backup/backup-azure-recovery-services-vault-overview
https://learn.microsoft.com/en-us/azure/backup/backup-create-recovery-services-vault
https://learn.microsoft.com/en-us/azure/backup/backup-azure-about-mars
https://learn.microsoft.com/en-us/azure/backup/install-mars-agent
https://learn.microsoft.com/en-us/azure/backup/backup-mabs-whats-new-mabs
https://learn.microsoft.com/en-us/azure/site-recovery/site-recovery-overview
Question 3 Single Choice
You have an Azure subscription that contains an Azure Kubernetes Service (AKS) instance named AKS1. AKS1 hosts microservice-based APIs that are configured to listen on non-default HTTP ports.
You plan to deploy a Standard tier Azure API Management instance named APIM1 that will make the APIs available to external users.
You need to ensure that the AKS1 APIs are accessible to APIM1. The solution must meet the following requirements:
Implement MTLS authentication between APIM1 and AKS1.
Minimize development effort.
Minimize costs.
What should you do?
Explanation
Click "Show Answer" to see the explanation here
Deploy an ingress controller to AKS1 is correct. To establish a secure and authenticated connection between Azure API Management (APIM) and microservices on Azure Kubernetes Service (AKS), it is recommended to deploy an ingress controller on AKS. For this purpose, popular choices include Nginx Ingress or Azure Application Gateway Ingress Controller. Configure the ingress controller to enforce MTLS authentication between APIM1 and AKS1. Additionally, considering that the microservice-based APIs on AKS1 are configured to listen on non-default HTTP ports, ensure the Ingress resource is configured accurately by specifying the correct non-default ports for proper routing. Finally, update the APIM1 configuration to use the ingress controller's public IP, considering both the MTLS settings and the specific non-default ports, establishing secure and efficient external access to microservices.
Implement an external load balancer on AKS1 is incorrect. Azure Load Balancer, operates at layer 4 of the OSI model, supports both inbound and outbound scenarios. In the context of AKS, a public load balancer serves the dual purposes of providing outbound connections to cluster nodes within the AKS virtual network and offering access to applications via Kubernetes services of type LoadBalancer. This functionality enables the translation of private IP addresses to public IP addresses as part of its Outbound Pool. Integrating an external load balancer on AKS1 can be beneficial for improving traffic distribution. This approach may not directly fulfill the specific requirements of secure communication and Mutual TLS (MTLS) authentication. Aside from its benefits, the primary focus of the Azure Load Balancer is not on security requirements, such as secure communication and Mutual TLS (MTLS) authentication.
Redeploy APIM1 to the virtual network that contains AKS1 is incorrect. Redeploying APIM1 to the virtual network containing AKS1 has the advantage of improving network performance and reducing latency. While this relocation can have advantages in terms of network efficiency, it's important to note that this solution does not directly address the specific requirement for Mutual TLS (MTLS) authentication mentioned in the scenario. MTLS is a security measure that ensures secure communication by requiring both parties, in this case, APIM1 and AKS1, to present certificates to authenticate each other. Moreover, the process of redeployment can result in downtime, impacting the availability of the APIs and services hosted on APIM1. Additionally, the redeployment process may require careful planning and coordination to minimize disruptions and potential negative impacts on users or downstream services. In summary, while redeploying APIM1 to the virtual network shared with AKS1 can offer benefits in terms of network performance, it does not inherently address the specific security requirement for MTLS authentication.
Implement an ExternalName service on AKS1 is incorrect. The use of an ExternalName service on AKS1, designed for DNS-based service discovery. This service redirects requests to external services based on DNS configuration. ExternalName services are typically employed for different scenarios, focusing on facilitating service discovery or integrating with external services. Considering the context, where secure communication and MTLS authentication are explicit requirements, using ExternalName services might introduce limitations. These services lack features that ensure secure communication channels between services within the AKS cluster, and might be not suitable for scenarios where security measures are important.
Read More:
Explanation
Deploy an ingress controller to AKS1 is correct. To establish a secure and authenticated connection between Azure API Management (APIM) and microservices on Azure Kubernetes Service (AKS), it is recommended to deploy an ingress controller on AKS. For this purpose, popular choices include Nginx Ingress or Azure Application Gateway Ingress Controller. Configure the ingress controller to enforce MTLS authentication between APIM1 and AKS1. Additionally, considering that the microservice-based APIs on AKS1 are configured to listen on non-default HTTP ports, ensure the Ingress resource is configured accurately by specifying the correct non-default ports for proper routing. Finally, update the APIM1 configuration to use the ingress controller's public IP, considering both the MTLS settings and the specific non-default ports, establishing secure and efficient external access to microservices.
Implement an external load balancer on AKS1 is incorrect. Azure Load Balancer, operates at layer 4 of the OSI model, supports both inbound and outbound scenarios. In the context of AKS, a public load balancer serves the dual purposes of providing outbound connections to cluster nodes within the AKS virtual network and offering access to applications via Kubernetes services of type LoadBalancer. This functionality enables the translation of private IP addresses to public IP addresses as part of its Outbound Pool. Integrating an external load balancer on AKS1 can be beneficial for improving traffic distribution. This approach may not directly fulfill the specific requirements of secure communication and Mutual TLS (MTLS) authentication. Aside from its benefits, the primary focus of the Azure Load Balancer is not on security requirements, such as secure communication and Mutual TLS (MTLS) authentication.
Redeploy APIM1 to the virtual network that contains AKS1 is incorrect. Redeploying APIM1 to the virtual network containing AKS1 has the advantage of improving network performance and reducing latency. While this relocation can have advantages in terms of network efficiency, it's important to note that this solution does not directly address the specific requirement for Mutual TLS (MTLS) authentication mentioned in the scenario. MTLS is a security measure that ensures secure communication by requiring both parties, in this case, APIM1 and AKS1, to present certificates to authenticate each other. Moreover, the process of redeployment can result in downtime, impacting the availability of the APIs and services hosted on APIM1. Additionally, the redeployment process may require careful planning and coordination to minimize disruptions and potential negative impacts on users or downstream services. In summary, while redeploying APIM1 to the virtual network shared with AKS1 can offer benefits in terms of network performance, it does not inherently address the specific security requirement for MTLS authentication.
Implement an ExternalName service on AKS1 is incorrect. The use of an ExternalName service on AKS1, designed for DNS-based service discovery. This service redirects requests to external services based on DNS configuration. ExternalName services are typically employed for different scenarios, focusing on facilitating service discovery or integrating with external services. Considering the context, where secure communication and MTLS authentication are explicit requirements, using ExternalName services might introduce limitations. These services lack features that ensure secure communication channels between services within the AKS cluster, and might be not suitable for scenarios where security measures are important.
Read More:
Question 4 Single Choice
Your on-premises datacenter contains a server that runs Linux and hosts a Java app named App1. App1 has the following characteristics:
App1 is an interactive app that users access by using HTTPS connections.
The number of connections to App1 changes significantly throughout the day.
App1 runs multiple concurrent instances.
App1 requires major changes to run in a container.
You plan to migrate App1 to Azure.
You need to recommend a compute solution for App1. The solution must meet the following requirements:
The solution must run multiple instances of App1.
The number of instances must be managed automatically depending on the load.
Administrative effort must be minimized.
What should you include in the recommendation?
Explanation
Click "Show Answer" to see the explanation here
Azure App Service is correct because it provides a platform for hosting web applications like App1 without requiring them to be containerized, thus avoiding the need for major changes. Azure App Service supports automatic scaling, allowing the number of instances to be dynamically adjusted based on load, which aligns with the varying number of connections to App1 throughout the day. This capability, along with its managed nature, ensures minimal administrative effort.
Azure Virtual Machine Scale Sets, while capable of auto-scaling and running multiple instances, is incorrect as it would involve a higher administrative burden and complexity compared to Azure App Service, especially considering the requirement of minimal administrative effort and the fact that App1 needs significant changes to be run in a containerized environment.
Azure Kubernetes Service (AKS) is incorrect in this context. Despite its capability for running multiple instances and auto-scaling, it is primarily designed for containerized applications. Given the requirement that App1 requires major changes to run in a container, this would not be the most efficient choice in terms of minimizing administrative efforts.
Azure Batch is also incorrect because it is tailored for large-scale parallel and batch processing workloads, rather than hosting interactive applications like App1 that require auto-scaling based on real-time user load.
Read More:
Explanation
Azure App Service is correct because it provides a platform for hosting web applications like App1 without requiring them to be containerized, thus avoiding the need for major changes. Azure App Service supports automatic scaling, allowing the number of instances to be dynamically adjusted based on load, which aligns with the varying number of connections to App1 throughout the day. This capability, along with its managed nature, ensures minimal administrative effort.
Azure Virtual Machine Scale Sets, while capable of auto-scaling and running multiple instances, is incorrect as it would involve a higher administrative burden and complexity compared to Azure App Service, especially considering the requirement of minimal administrative effort and the fact that App1 needs significant changes to be run in a containerized environment.
Azure Kubernetes Service (AKS) is incorrect in this context. Despite its capability for running multiple instances and auto-scaling, it is primarily designed for containerized applications. Given the requirement that App1 requires major changes to run in a container, this would not be the most efficient choice in terms of minimizing administrative efforts.
Azure Batch is also incorrect because it is tailored for large-scale parallel and batch processing workloads, rather than hosting interactive applications like App1 that require auto-scaling based on real-time user load.
Read More:
Question 5 Single Choice
Your company, named Contoso, Ltd., has an Azure subscription that contains the following resources:
An Azure Synapse Analytics workspace named contosoworkspace1
An Azure Data Lake Storage account named contosolake1
An Azure SQL database named contososql1
The product data of Contoso is copied from contososql1 to contosolake1.
Contoso has a partner company named Fabrikam Inc. Fabrikam has an Azure subscription that contains the following resources:
A virtual machine named FabrikamVM1 that runs Microsoft SQL Server 2019
An Azure Storage account named fabrikamsa1
Contoso plans to upload the research data on FabrikamVM1 to contosolake1. During the upload, the research data must be transformed to the data formats used by Contoso.
The data in contosolake1 will be analyzed by using contosoworkspace1.
You need to recommend a solution that meets the following requirement:
Upload and transform the FabrikamVM1 research data.
What should you recommend?
Explanation
Click "Show Answer" to see the explanation here
Azure Synapse pipelines is correct. In the given scenario, Contoso needs to upload and transform research data from FabrikamVM1 to contosolake1, where the data will later be analyzed using contosoworkspace1. To fulfill this requirement, the recommended solution is Azure Synapse pipelines. Azure Synapse pipelines offer a cloud-based data integration service that enables the creation, scheduling, and management of data pipelines. The advantage of Synapse pipelines is that it can help in orchestrating and automating the workflow of data movement and transformation. In the given scenario, it means that Contoso can design a data pipeline using Azure Synapse pipelines to handle both the upload and transformation of the research data.
Azure Data Share is incorrect. Azure Data Share is a tool designed for securely sharing data between different organizations. It provides control to the ones sharing the data, allowing them to monitor what data is shared, when it's shared, and by whom. For example, a store might use it to share sales data with its suppliers regularly. This way, they can easily exchange information without any worries about security. For tasks related to uploading and transforming data, other Azure services such as Azure Synapse pipelines, might be more suitable.
Azure Data Box Gateway is incorrect. It is primarily designed for facilitating efficient data transfer between on-premises environments and Azure. Its main focus is on tasks such as cloud archival, disaster recovery, and processing data at cloud scale. This solution is particularly for scenarios like cloud archival, where you need to securely and efficiently copy large amounts of data to Azure storage. However, it may not be the most suitable choice for upload and direct data transformation tasks.
Read More:
Explanation
Azure Synapse pipelines is correct. In the given scenario, Contoso needs to upload and transform research data from FabrikamVM1 to contosolake1, where the data will later be analyzed using contosoworkspace1. To fulfill this requirement, the recommended solution is Azure Synapse pipelines. Azure Synapse pipelines offer a cloud-based data integration service that enables the creation, scheduling, and management of data pipelines. The advantage of Synapse pipelines is that it can help in orchestrating and automating the workflow of data movement and transformation. In the given scenario, it means that Contoso can design a data pipeline using Azure Synapse pipelines to handle both the upload and transformation of the research data.
Azure Data Share is incorrect. Azure Data Share is a tool designed for securely sharing data between different organizations. It provides control to the ones sharing the data, allowing them to monitor what data is shared, when it's shared, and by whom. For example, a store might use it to share sales data with its suppliers regularly. This way, they can easily exchange information without any worries about security. For tasks related to uploading and transforming data, other Azure services such as Azure Synapse pipelines, might be more suitable.
Azure Data Box Gateway is incorrect. It is primarily designed for facilitating efficient data transfer between on-premises environments and Azure. Its main focus is on tasks such as cloud archival, disaster recovery, and processing data at cloud scale. This solution is particularly for scenarios like cloud archival, where you need to securely and efficiently copy large amounts of data to Azure storage. However, it may not be the most suitable choice for upload and direct data transformation tasks.
Read More:
Question 6 Single Choice
Your company, named Contoso, Ltd., has an Azure subscription that contains the following resources:
An Azure Synapse Analytics workspace named contosoworkspace1
An Azure Data Lake Storage account named contosolake1
An Azure SQL database named contososql1
The product data of Contoso is copied from contososql1 to contosolake1.
Contoso has a partner company named Fabrikam Inc. Fabrikam has an Azure subscription that contains the following resources:
A virtual machine named FabrikamVM1 that runs Microsoft SQL Server 2019
An Azure Storage account named fabrikamsa1
Contoso plans to upload the research data on FabrikamVM1 to contosolake1. During the upload, the research data must be transformed to the data formats used by Contoso.
The data in contosolake1 will be analyzed by using contosoworkspace1.
You need to recommend a solution that meets the following requirement:
Provide Fabrikam with restricted access to snapshots of the data in contosoworkspace1.
What should you recommend?
Explanation
Click "Show Answer" to see the explanation here
Azure Data Share is correct. To meet the requirement of providing Fabrikam with restricted access to snapshots of the data in contosoworkspace1, the recommended solution is Azure Data Share. Azure Data Share is specifically designed for securely sharing data between organizations, allowing entities to share data with partners or customers while maintaining control over the shared data. In this scenario, Contoso wants to share specific snapshots of their data with their partner, Fabrikam. Azure Data Share ensures that only the necessary snapshots are shared, maintaining control and security over the information being passed between the two companies.
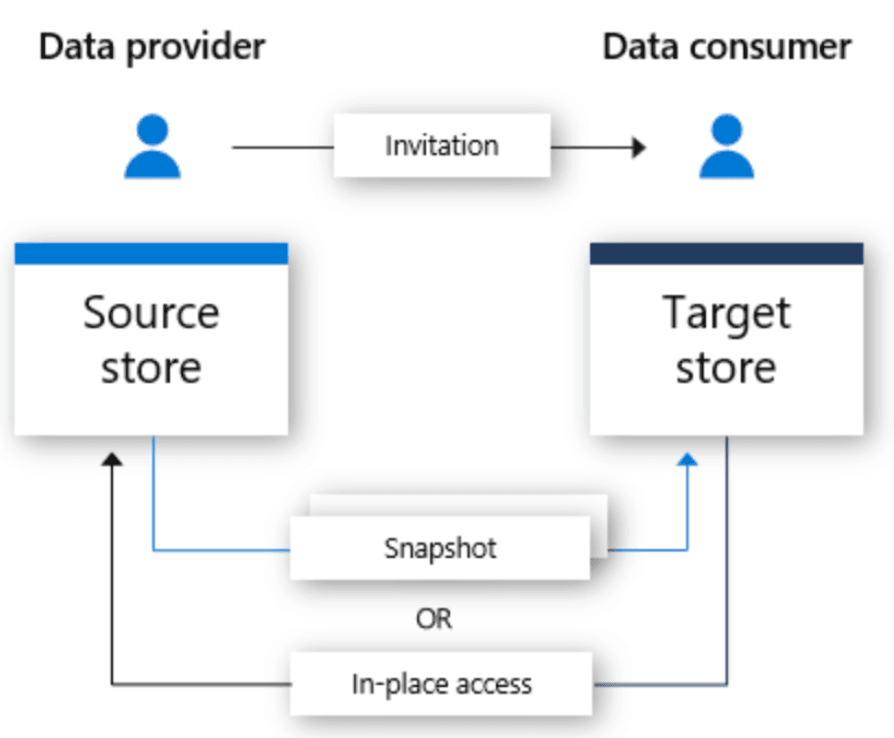
Azure Synapse pipelines is incorrect. Azure Synapse pipelines offer a cloud-based data integration service that enables the creation, scheduling, and management of data pipelines. The advantage of Synapse pipelines is that it can help in orchestrating and automating the workflow of data movement and transformation. However, in the scenario of restricting access to snapshots of data in contosoworkspace1, Azure Synapse pipelines may not be the ideal choice. This is because their primary focus is on uploading and transforming data, rather than providing the specific access restrictions required in this case.
Azure Data Box Gateway is incorrect. It is primarily designed for facilitating efficient data transfer between on-premises environments and Azure. Its main focus is on tasks such as cloud archival, disaster recovery, and processing data at cloud scale. This solution is particularly for scenarios like cloud archival, where you need to securely and efficiently copy large amounts of data to Azure storage. However, it may not be the most suitable choice for restricting access to snapshots of the data in contosoworkspace1.
Read More:
Explanation
Azure Data Share is correct. To meet the requirement of providing Fabrikam with restricted access to snapshots of the data in contosoworkspace1, the recommended solution is Azure Data Share. Azure Data Share is specifically designed for securely sharing data between organizations, allowing entities to share data with partners or customers while maintaining control over the shared data. In this scenario, Contoso wants to share specific snapshots of their data with their partner, Fabrikam. Azure Data Share ensures that only the necessary snapshots are shared, maintaining control and security over the information being passed between the two companies.
Azure Synapse pipelines is incorrect. Azure Synapse pipelines offer a cloud-based data integration service that enables the creation, scheduling, and management of data pipelines. The advantage of Synapse pipelines is that it can help in orchestrating and automating the workflow of data movement and transformation. However, in the scenario of restricting access to snapshots of data in contosoworkspace1, Azure Synapse pipelines may not be the ideal choice. This is because their primary focus is on uploading and transforming data, rather than providing the specific access restrictions required in this case.
Azure Data Box Gateway is incorrect. It is primarily designed for facilitating efficient data transfer between on-premises environments and Azure. Its main focus is on tasks such as cloud archival, disaster recovery, and processing data at cloud scale. This solution is particularly for scenarios like cloud archival, where you need to securely and efficiently copy large amounts of data to Azure storage. However, it may not be the most suitable choice for restricting access to snapshots of the data in contosoworkspace1.
Read More:
Question 7 Single Choice
You have an Azure subscription that contains the resources shown in the following table.
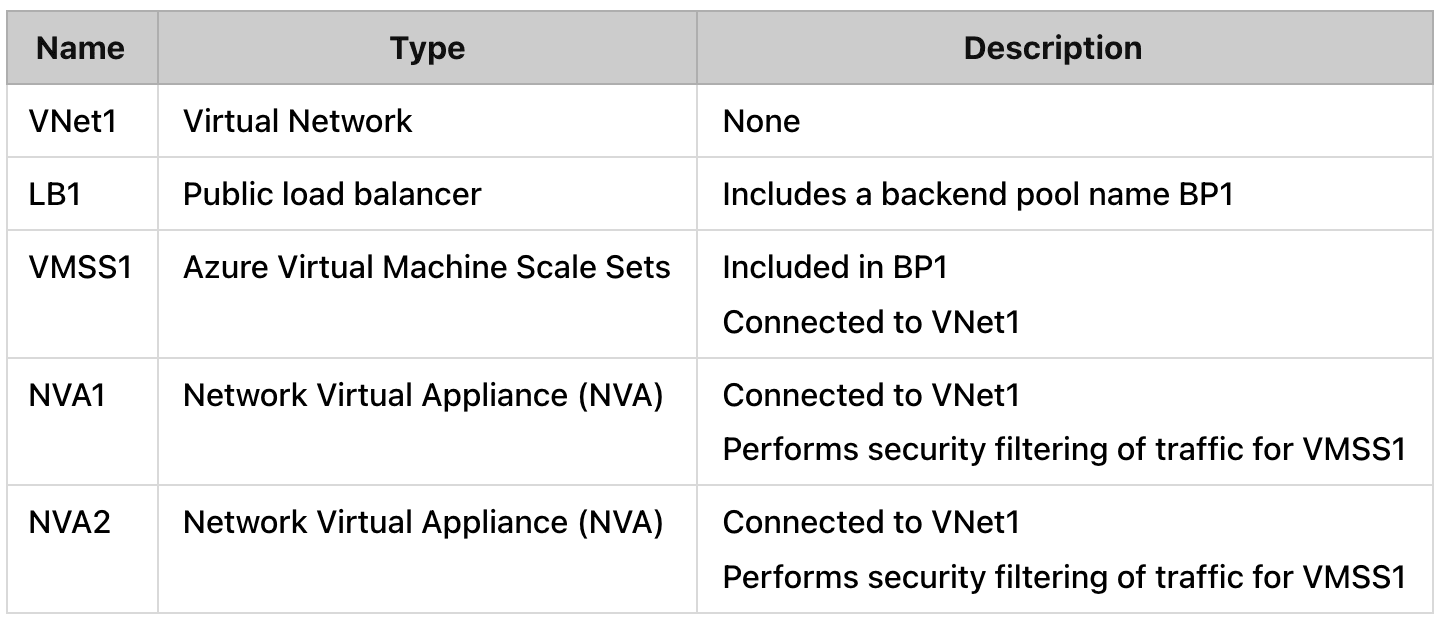
You need to recommend a load balancing solution that will distribute incoming traffic for VMSS1 across NVA1 and NVA2.
The solution must minimize administrative effort.
What should you include in the recommendation?
Explanation
Click "Show Answer" to see the explanation here
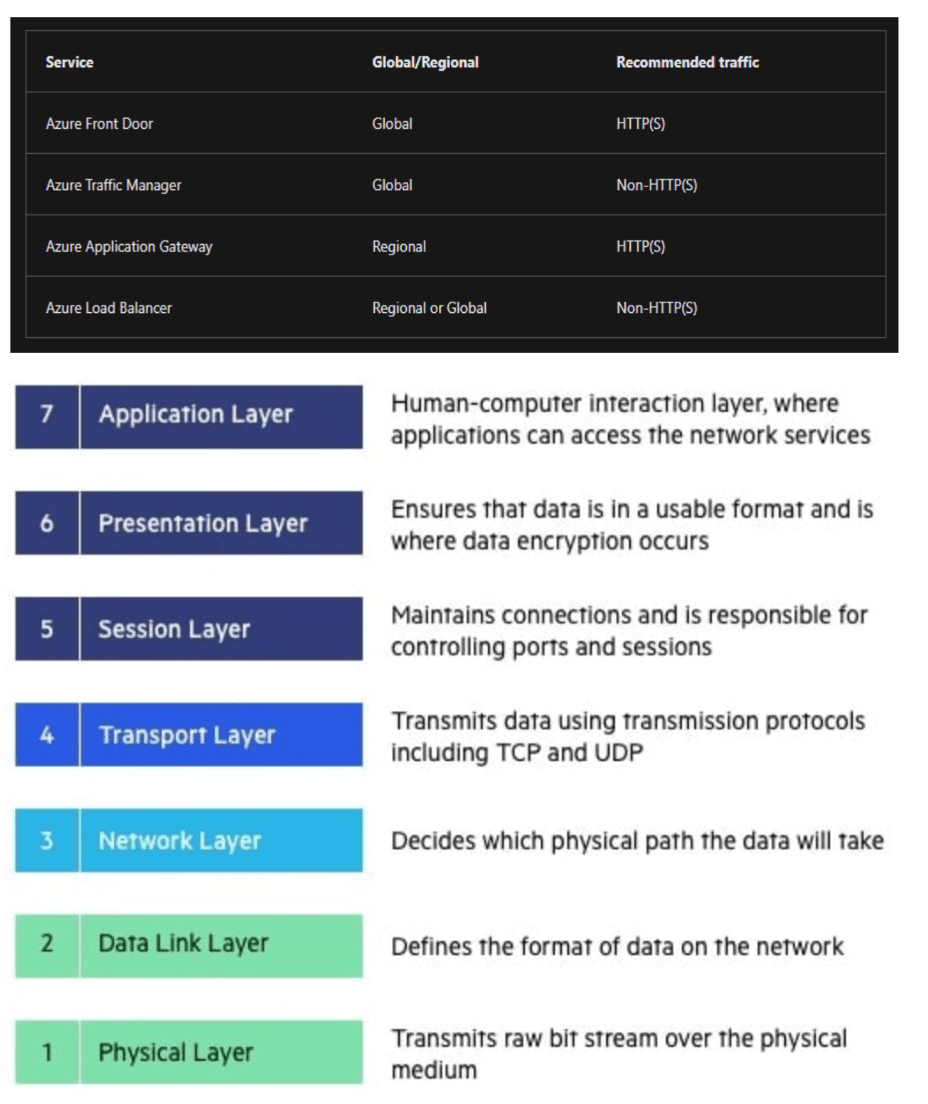
Gateway Load Balancer is correct. In the scenario of distributing traffic across NVA1 and NVA2 for VMSS1, the recommended solution is Azure Gateway Load Balancer (GLB). It operates at the network layer (Layer 4), specifically designed for efficiently handling non-HTTP/HTTPS traffic and offers seamless integration with third-party NVAs. It is optimized for high performance, serving as a general-purpose and straightforward load balancer suitable for various protocols, including TCP and UDP. GLB supports a broad range of protocols such as TCP, UDP, and even custom protocols. This option makes it suitable with general-purpose load balancing needs, eliminating the need for application-specific features. Considering a load balancing solution that will distribute incoming traffic for VMSS1 across NVA1 and NVA2, it provides the efficient distribution of traffic within Virtual Machine Scale Sets (VMSS). This feature of Azure Gateway Load Balancer provides a better solution for the specified scenario while minimizing administrative effort.
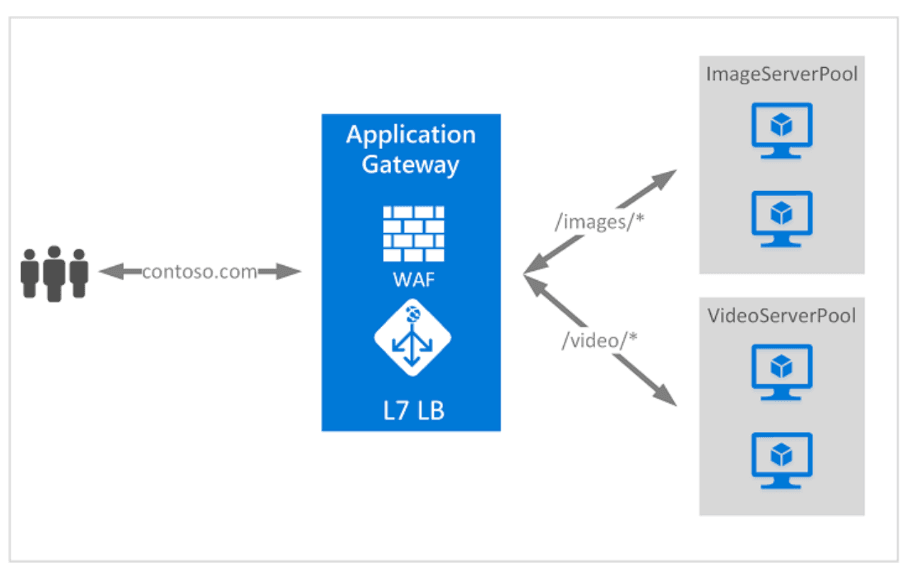
Azure Application Gateway is incorrect. In the context of distributing traffic across NVA1 and NVA2 for VMSS1, Azure Application Gateway is not a suitable choice. Azure Application Gateway is primarily designed for application-level (Layer 7) load balancing and is optimized for HTTP/HTTPS traffic. It provides advanced features like URL-based routing, SSL termination, and web application firewall. Additionally, it may require additional configuration for specific third-party components. As an example, in Azure Application Gateway, you can route traffic based on the incoming URL. So, if the incoming URL includes /images, you can configure the gateway to route that traffic to a specific set of servers, known as a pool, which is optimized for handling image requests. Similarly, if the URL contains /video, the traffic can be directed to another pool specifically configured to handle video requests. Similarly, For a scenario where the traffic does not include HTTP/HTTPS, Azure Gateway Load Balancer (GLB) would be a more fitting solution. GLB operates at the network layer (Layer 4), making it efficient for handling various protocols, including TCP and UDP. It is a general-purpose load balancer that eliminates the need for application-specific features, aligning well with the specified scenario's requirements. Choosing Azure Gateway Load Balancer over Azure Application Gateway ensures an efficient solution, minimizing administrative effort.
*Real-Time Example from Amazon
If the incoming URL includes /mobile-phones (https://www.amazon.in/mobile-phones), you can configure the gateway to route that traffic to a set of servers, for handling mobile-phone requests.

Similarly, If the URL contains /electronics (https://www.amazon.in/electronics), the traffic can be directed to another pool specifically configured to handle electronic requests.

Azure Front Door is incorrect. Azure Front Door is a global service in Azure designed to improve the performance, availability, and security of web applications. It operates by utilizing Microsoft's extensive global network infrastructure to distribute user traffic intelligently and optimize the delivery of content. It performs well in scenarios where applications require global load balancing and accelerated content delivery.In the given scenario, where the focus is on distributing traffic between NVA1 and NVA2 within a region, the capabilities of Azure Front Door might be more than what is needed. This service is primarily used for global-scale applications and not suitable for a regional use case.
Azure Traffic Manager is incorrect. It is a DNS-based load balancer and designed to distribute incoming client requests across different endpoints. It works at DNS level and resolves client queries and directs them to the appropriate endpoint based on configured routing methods, including performance, weighted, priority, and geographic routing. While Azure Traffic Manager is a powerful solution for global load balancing by routing users to the closest or best-performing endpoint, it is not a suitable choice for distributing traffic within a specific environment, such as a Virtual Machine Scale Set (VMSS). The reason is that Traffic Manager operates at the DNS level, which might not provide the control needed for distributing HTTP/HTTPS traffic within a VMSS.
Read More:
Explanation
Gateway Load Balancer is correct. In the scenario of distributing traffic across NVA1 and NVA2 for VMSS1, the recommended solution is Azure Gateway Load Balancer (GLB). It operates at the network layer (Layer 4), specifically designed for efficiently handling non-HTTP/HTTPS traffic and offers seamless integration with third-party NVAs. It is optimized for high performance, serving as a general-purpose and straightforward load balancer suitable for various protocols, including TCP and UDP. GLB supports a broad range of protocols such as TCP, UDP, and even custom protocols. This option makes it suitable with general-purpose load balancing needs, eliminating the need for application-specific features. Considering a load balancing solution that will distribute incoming traffic for VMSS1 across NVA1 and NVA2, it provides the efficient distribution of traffic within Virtual Machine Scale Sets (VMSS). This feature of Azure Gateway Load Balancer provides a better solution for the specified scenario while minimizing administrative effort.
Azure Application Gateway is incorrect. In the context of distributing traffic across NVA1 and NVA2 for VMSS1, Azure Application Gateway is not a suitable choice. Azure Application Gateway is primarily designed for application-level (Layer 7) load balancing and is optimized for HTTP/HTTPS traffic. It provides advanced features like URL-based routing, SSL termination, and web application firewall. Additionally, it may require additional configuration for specific third-party components. As an example, in Azure Application Gateway, you can route traffic based on the incoming URL. So, if the incoming URL includes /images, you can configure the gateway to route that traffic to a specific set of servers, known as a pool, which is optimized for handling image requests. Similarly, if the URL contains /video, the traffic can be directed to another pool specifically configured to handle video requests. Similarly, For a scenario where the traffic does not include HTTP/HTTPS, Azure Gateway Load Balancer (GLB) would be a more fitting solution. GLB operates at the network layer (Layer 4), making it efficient for handling various protocols, including TCP and UDP. It is a general-purpose load balancer that eliminates the need for application-specific features, aligning well with the specified scenario's requirements. Choosing Azure Gateway Load Balancer over Azure Application Gateway ensures an efficient solution, minimizing administrative effort.
*Real-Time Example from Amazon
If the incoming URL includes /mobile-phones (https://www.amazon.in/mobile-phones), you can configure the gateway to route that traffic to a set of servers, for handling mobile-phone requests.
Similarly, If the URL contains /electronics (https://www.amazon.in/electronics), the traffic can be directed to another pool specifically configured to handle electronic requests.
Azure Front Door is incorrect. Azure Front Door is a global service in Azure designed to improve the performance, availability, and security of web applications. It operates by utilizing Microsoft's extensive global network infrastructure to distribute user traffic intelligently and optimize the delivery of content. It performs well in scenarios where applications require global load balancing and accelerated content delivery.In the given scenario, where the focus is on distributing traffic between NVA1 and NVA2 within a region, the capabilities of Azure Front Door might be more than what is needed. This service is primarily used for global-scale applications and not suitable for a regional use case.
Azure Traffic Manager is incorrect. It is a DNS-based load balancer and designed to distribute incoming client requests across different endpoints. It works at DNS level and resolves client queries and directs them to the appropriate endpoint based on configured routing methods, including performance, weighted, priority, and geographic routing. While Azure Traffic Manager is a powerful solution for global load balancing by routing users to the closest or best-performing endpoint, it is not a suitable choice for distributing traffic within a specific environment, such as a Virtual Machine Scale Set (VMSS). The reason is that Traffic Manager operates at the DNS level, which might not provide the control needed for distributing HTTP/HTTPS traffic within a VMSS.
Read More:
Question 8 Single Choice
You plan to use Azure SQL as a database platform.
You need to recommend an Azure SQL product and service tier that meets the following requirements:
Automatically scales compute resources based on the workload demand
Provides per second billing
Which Azure SQL product should you recommend?
Explanation
Click "Show Answer" to see the explanation here
A single Azure SQL database is correct. Azure SQL Database is a fully managed platform-as-a-service (PaaS) database engine that manages various database functions, including upgrading, patching, backups, and monitoring, all without requiring user involvement. It has the capability to automatically scale compute resources based on workload, and users are billed precisely for the compute resources consumed during each second. Azure SQL Database scales through two distinct purchasing models: the vCore-based model and the DTU-based model. The vCore model provides control over resources by dynamically adjusting virtual cores. On the other hand, the DTU model offers a more abstract approach, measuring performance in Database Transaction Units (DTUs) that encapsulate compute, memory, and I/O resources. As a fully managed service, routine maintenance tasks and security patches are handled by Microsoft. In the scenarios where the primary requirements involve automatic scaling of compute resources based on workload demand and per-second billing Azure SQL Database is a suitable choice
An Azure SQL Database elastic pool is incorrect. Azure SQL Database Elastic Pool is designed for resource sharing among multiple databases. While it allows more efficient utilization of resources by distributing them among databases with varying workloads, the auto-scaling feature operates at the pool level. This means resources are shared among all databases in the pool, and scaling decisions are made collectively for the pool, not for individual databases. This might be less suitable for the given requirements of scaling based on the specific workload of each individual database.
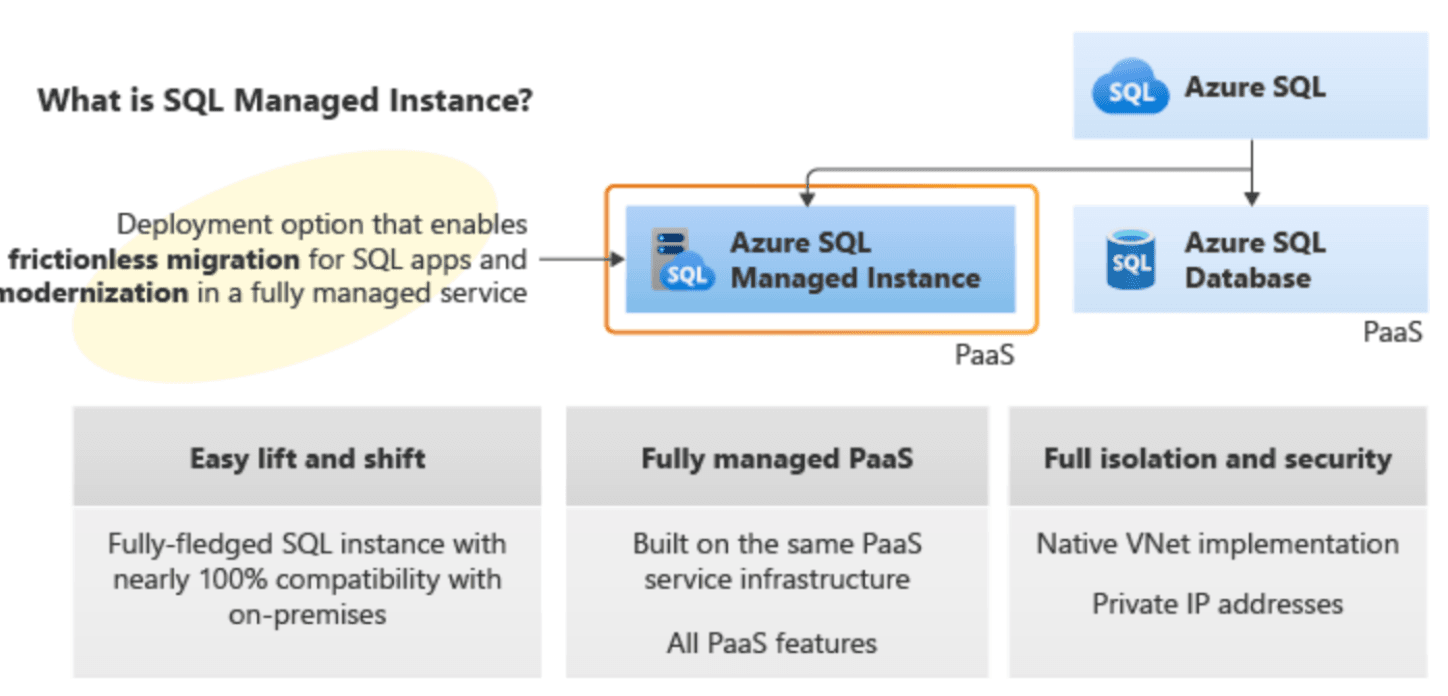
Azure SQL Managed Instance is incorrect. Azure SQL Managed Instance is ideal for organizations moving large applications from different environments (like on-premises, IaaS, or ISV solutions) to a fully managed PaaS cloud environment. Its main aim is to make the migration process smoother and is compatible with various SQL Server features and suits for large-scale migrations. However, if you specifically need per-second billing and very detailed auto-scaling for individual databases, Azure SQL Database (individual databases) is a better match. It allows you to adjust resources precisely based on each database's workload and bills you per second.
Read More:
Explanation
A single Azure SQL database is correct. Azure SQL Database is a fully managed platform-as-a-service (PaaS) database engine that manages various database functions, including upgrading, patching, backups, and monitoring, all without requiring user involvement. It has the capability to automatically scale compute resources based on workload, and users are billed precisely for the compute resources consumed during each second. Azure SQL Database scales through two distinct purchasing models: the vCore-based model and the DTU-based model. The vCore model provides control over resources by dynamically adjusting virtual cores. On the other hand, the DTU model offers a more abstract approach, measuring performance in Database Transaction Units (DTUs) that encapsulate compute, memory, and I/O resources. As a fully managed service, routine maintenance tasks and security patches are handled by Microsoft. In the scenarios where the primary requirements involve automatic scaling of compute resources based on workload demand and per-second billing Azure SQL Database is a suitable choice
An Azure SQL Database elastic pool is incorrect. Azure SQL Database Elastic Pool is designed for resource sharing among multiple databases. While it allows more efficient utilization of resources by distributing them among databases with varying workloads, the auto-scaling feature operates at the pool level. This means resources are shared among all databases in the pool, and scaling decisions are made collectively for the pool, not for individual databases. This might be less suitable for the given requirements of scaling based on the specific workload of each individual database.
Azure SQL Managed Instance is incorrect. Azure SQL Managed Instance is ideal for organizations moving large applications from different environments (like on-premises, IaaS, or ISV solutions) to a fully managed PaaS cloud environment. Its main aim is to make the migration process smoother and is compatible with various SQL Server features and suits for large-scale migrations. However, if you specifically need per-second billing and very detailed auto-scaling for individual databases, Azure SQL Database (individual databases) is a better match. It allows you to adjust resources precisely based on each database's workload and bills you per second.
Read More:
Question 9 Single Choice
You plan to use Azure SQL as a database platform.
You need to recommend an Azure SQL product and service tier that meets the following requirements:
Automatically scales compute resources based on the workload demand
Provides per second billing
Which Service tier should you recommend?
Explanation
Click "Show Answer" to see the explanation here
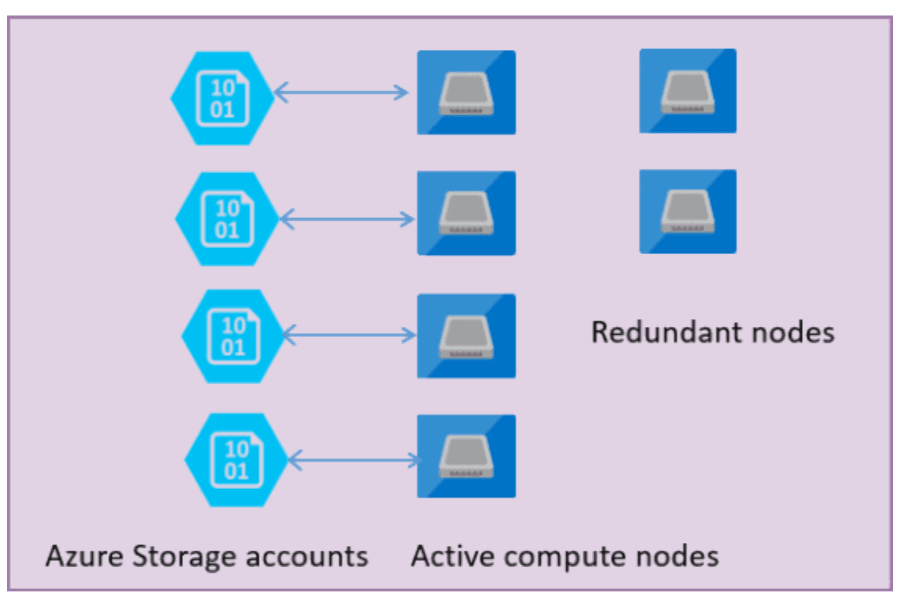
General Purpose is correct. The General Purpose service tier in Azure SQL Database is suitable for common workloads, providing a budget-oriented balanced compute and storage options. It separates compute and storage components, depending on the resilience of Azure Blob storage for transparent file replication, ensuring high availability and zero data loss during infrastructure failures. As the default service tier, it supports a wide range of generic workloads. This tier offers a fully managed database engine with a default Service Level Agreement (SLA) and efficient storage latency ranging between 5 ms and 10 ms.The General Purpose tier in Azure SQL Database is a strong choice for users looking for a reliable and cost-effective solution.
The following figure shows four nodes in the standard architectural model with the separated compute and storage layers.
Basic is incorrect. Basic service tier in Azure SQL is suitable for low-cost usage and is specifically designed for small databases with light workloads. It doesn't support automatic scaling capabilities needed for varying workloads. It is suitable for small workloads and where costs are limited.
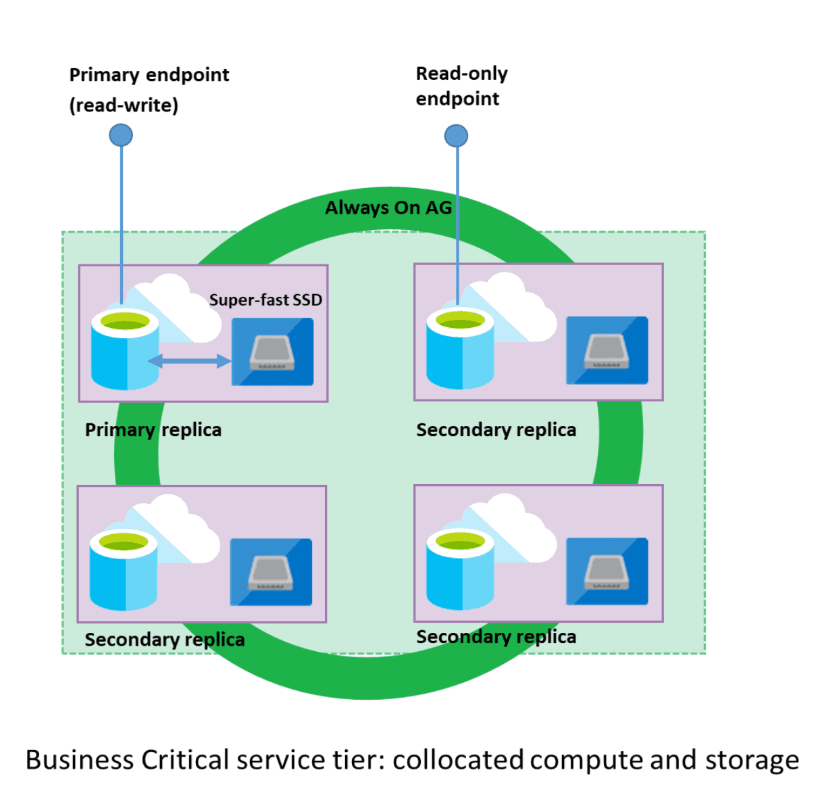
Business Critical is incorrect. The Business Critical service tier operates on a clustered model with multiple database engine processes, ensuring robustness. This architecture relies on a quorum of nodes to minimize performance impacts during maintenance, allowing for transparent upgrades and patches to the underlying components, such as the operating system, drivers, and database engine, with minimal downtime for users.In this model, each node integrates compute and storage, utilizing locally attached SSD for data storage. The replication of data between database engine processes on a four-node cluster achieves high availability, contributing to enhanced performance for high-demand OLTP workloads.While Business Critical excels in availability and performance, it does not inherently support automatic scaling based on workload fluctuations. Additionally, the billing model is generally not based on a per-second basis. Therefore, if automatic scaling and per-second billing are key priorities, Business Critical may not be the most aligned choice for these specific requirements.
The following diagram shows how the Business Critical service tier organizes a cluster of database engine nodes in availability group replicas.
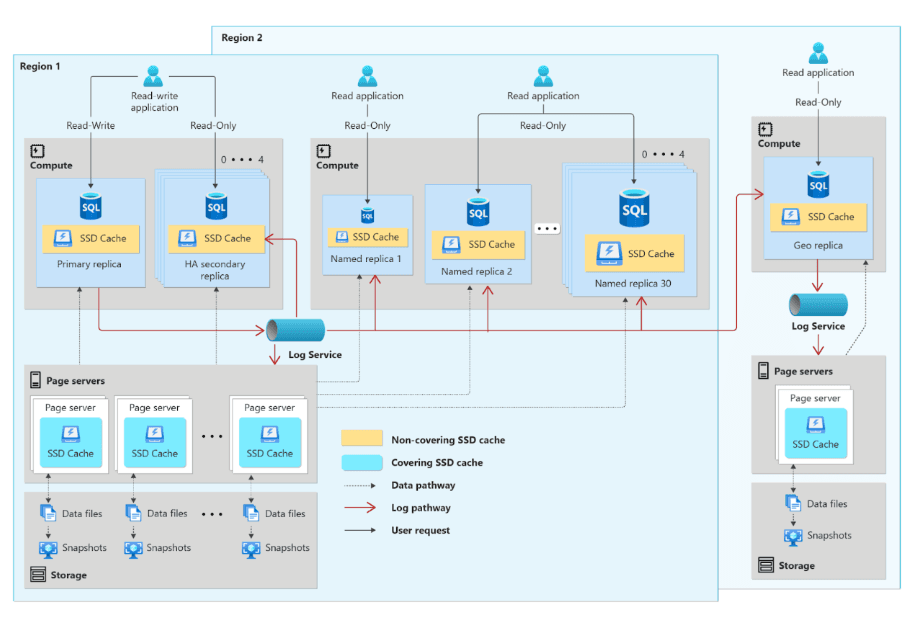
Hyperscale is incorrect. For the given scenario of using Azure SQL as a database platform with the requirements of automatic scaling of compute resources based on workload demand and per-second billing, the Hyperscale service tier may not be the most suitable recommendation. While Hyperscale is powerful and supports extensive scalability, it does not provide automatic scaling, which also offer such capabilities but they are currently in preview and may not be recommended for production use due to potential limitations. The Hyperscale compute unit price is per replica. Users can adjust the total number of high-availability secondary replicas from 0 to 4, depending on availability and scalability requirements, and create up to 30 named replicas to support various read scale-out workloads. A more suitable would be the General Purpose service tier, this choice meets with the requirements, offering both automatic scaling of compute resources based on workload demand and per-second billing features.
The following diagram illustrates the functional Hyperscale architecture.
Standard is incorrect. The Standard service tier is a basic offering that provides balanced compute and memory resources, making it suitable for most database workloads. However, it lacks some advanced features found in higher tiers, such as serverless compute. Standard does not support automatic scaling based on workload changes, and the billing model is usually not on a per-second basis. In a scenario where advanced features like automatic scaling and per-second billing are required, the Standard tier may not be the most suitable option.
Read More:
Explanation
General Purpose is correct. The General Purpose service tier in Azure SQL Database is suitable for common workloads, providing a budget-oriented balanced compute and storage options. It separates compute and storage components, depending on the resilience of Azure Blob storage for transparent file replication, ensuring high availability and zero data loss during infrastructure failures. As the default service tier, it supports a wide range of generic workloads. This tier offers a fully managed database engine with a default Service Level Agreement (SLA) and efficient storage latency ranging between 5 ms and 10 ms.The General Purpose tier in Azure SQL Database is a strong choice for users looking for a reliable and cost-effective solution.
The following figure shows four nodes in the standard architectural model with the separated compute and storage layers.
Basic is incorrect. Basic service tier in Azure SQL is suitable for low-cost usage and is specifically designed for small databases with light workloads. It doesn't support automatic scaling capabilities needed for varying workloads. It is suitable for small workloads and where costs are limited.
Business Critical is incorrect. The Business Critical service tier operates on a clustered model with multiple database engine processes, ensuring robustness. This architecture relies on a quorum of nodes to minimize performance impacts during maintenance, allowing for transparent upgrades and patches to the underlying components, such as the operating system, drivers, and database engine, with minimal downtime for users.In this model, each node integrates compute and storage, utilizing locally attached SSD for data storage. The replication of data between database engine processes on a four-node cluster achieves high availability, contributing to enhanced performance for high-demand OLTP workloads.While Business Critical excels in availability and performance, it does not inherently support automatic scaling based on workload fluctuations. Additionally, the billing model is generally not based on a per-second basis. Therefore, if automatic scaling and per-second billing are key priorities, Business Critical may not be the most aligned choice for these specific requirements.
The following diagram shows how the Business Critical service tier organizes a cluster of database engine nodes in availability group replicas.
Hyperscale is incorrect. For the given scenario of using Azure SQL as a database platform with the requirements of automatic scaling of compute resources based on workload demand and per-second billing, the Hyperscale service tier may not be the most suitable recommendation. While Hyperscale is powerful and supports extensive scalability, it does not provide automatic scaling, which also offer such capabilities but they are currently in preview and may not be recommended for production use due to potential limitations. The Hyperscale compute unit price is per replica. Users can adjust the total number of high-availability secondary replicas from 0 to 4, depending on availability and scalability requirements, and create up to 30 named replicas to support various read scale-out workloads. A more suitable would be the General Purpose service tier, this choice meets with the requirements, offering both automatic scaling of compute resources based on workload demand and per-second billing features.
The following diagram illustrates the functional Hyperscale architecture.
Standard is incorrect. The Standard service tier is a basic offering that provides balanced compute and memory resources, making it suitable for most database workloads. However, it lacks some advanced features found in higher tiers, such as serverless compute. Standard does not support automatic scaling based on workload changes, and the billing model is usually not on a per-second basis. In a scenario where advanced features like automatic scaling and per-second billing are required, the Standard tier may not be the most suitable option.
Read More:
Question 10 Single Choice
You have an Azure subscription that contains the resources shown in the following table:
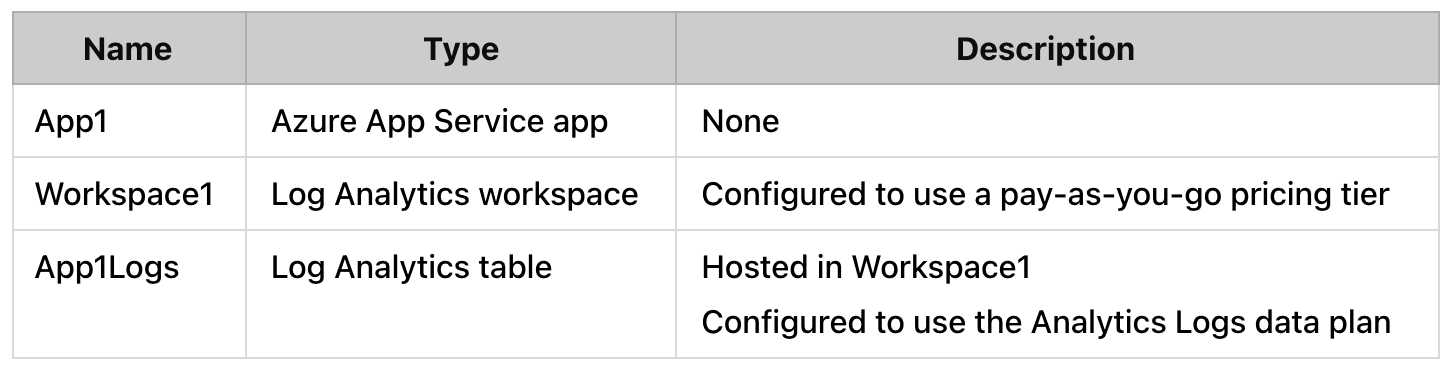
Log files from App1 are registered to App1Logs. An average of 120 GB of log data is ingested per day.
You configure an Azure Monitor alert that will be triggered if the App1 logs contain error messages.
You need to minimize the Log Analytics costs associated with App1. The solution must meet the following requirements:
Ensure that all the log files from App1 are ingested to App1 Logs.
Minimize the impact on the Azure Monitor alert.
Which resource should you modify?
Explanation
Click "Show Answer" to see the explanation here
Workspace1 is correct. Imagine Workspace1 as the main hub for all the logs from App1 in Azure. It's where these logs are collected, analyzed, and used to trigger alerts. Since your App1 Logs are hosted in Workspace1 and you've got the Analytics log data plan, you have some valuable tools. Customizing Workspace1 means you're adjusting how it deals with the log data. You can choose which logs are important, keeping only the essential ones, and with the Analytics log data plan, you gain access to advanced tools for analyzing these logs. Workspace1 is also where you control the alert system. You can adjust it to watch out for specific errors from App1, ensuring you only receive alerts for crucial things.In simpler terms, by adjusting Workspace1, using its App1 Logs hosting and the Analytics plan, you're managing how logs are handled. It's not just about having the data; it's about having the right data and making sure your alert system is set up correctly. All of this helps you save money while closely monitoring what's happening with your App1.
App1 is incorrect. Modifying the application, App1, would not directly influence Log Analytics costs or data ingestion efficiency. The application serves as the source of log data, and the control over data processing and storage typically lives at the Log Analytics workspace level. And setting up the application to create specific log messages is important for the alert system to work well. However, when it comes to handling overall data ingestion and making sure costs are optimized, it's more effective to deal with workspace level.
App1 Logs is incorrect. In the Azure Monitor setup, where App1 Logs serve as the assigned repository within Workspace1 for log data, direct modifications to App1 Logs, even with the application of the Analytics log data plan, provide only limited control. While it provides some modifications to retention policies, determining how long logs are stored, but they lack the necessary control for configuring detailed aspects of data ingestion and alert settings. When you try to say exactly which logs to use, how to sort them, and when alerts should pop up, you find some limitations. But if you look at the bigger picture and use the broader settings available in the workspace, like Workspace1, it's more helpful. Workspaces usually have required options, making it easier to set up how data comes in and customize alerts. Choosing to set things up in Workspace1 not only makes the process easier, but also saving money by not taking any unnecessary data, and it also helps you manage log data in a thorough and flexible way, following the best practices in Azure Monitor.
Read More:
Explanation
Workspace1 is correct. Imagine Workspace1 as the main hub for all the logs from App1 in Azure. It's where these logs are collected, analyzed, and used to trigger alerts. Since your App1 Logs are hosted in Workspace1 and you've got the Analytics log data plan, you have some valuable tools. Customizing Workspace1 means you're adjusting how it deals with the log data. You can choose which logs are important, keeping only the essential ones, and with the Analytics log data plan, you gain access to advanced tools for analyzing these logs. Workspace1 is also where you control the alert system. You can adjust it to watch out for specific errors from App1, ensuring you only receive alerts for crucial things.In simpler terms, by adjusting Workspace1, using its App1 Logs hosting and the Analytics plan, you're managing how logs are handled. It's not just about having the data; it's about having the right data and making sure your alert system is set up correctly. All of this helps you save money while closely monitoring what's happening with your App1.
App1 is incorrect. Modifying the application, App1, would not directly influence Log Analytics costs or data ingestion efficiency. The application serves as the source of log data, and the control over data processing and storage typically lives at the Log Analytics workspace level. And setting up the application to create specific log messages is important for the alert system to work well. However, when it comes to handling overall data ingestion and making sure costs are optimized, it's more effective to deal with workspace level.
App1 Logs is incorrect. In the Azure Monitor setup, where App1 Logs serve as the assigned repository within Workspace1 for log data, direct modifications to App1 Logs, even with the application of the Analytics log data plan, provide only limited control. While it provides some modifications to retention policies, determining how long logs are stored, but they lack the necessary control for configuring detailed aspects of data ingestion and alert settings. When you try to say exactly which logs to use, how to sort them, and when alerts should pop up, you find some limitations. But if you look at the bigger picture and use the broader settings available in the workspace, like Workspace1, it's more helpful. Workspaces usually have required options, making it easier to set up how data comes in and customize alerts. Choosing to set things up in Workspace1 not only makes the process easier, but also saving money by not taking any unnecessary data, and it also helps you manage log data in a thorough and flexible way, following the best practices in Azure Monitor.
Read More:


