
Microsoft Certified: DevOps Engineer Expert - (AZ-400) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 11 Single Choice
You have a 1-TB Azure Repos repository named repo1.
You need to clone repo1. The solution must meet the following requirements:
You must be able to search the commit history of the /src directory
The amount of time it takes to clone the repository must be minimized
Which command should you run?
Explanation

Click "Show Answer" to see the explanation here
Correct Answer(s): git clone –-filter=blob:none git@ssh.dev.azure.com:v3/org/Project1/repo1
git clone –-filter=blob:none git@ssh.dev.azure.com:v3/org/Project1/repo1 is CORRECT because it uses the partial clone feature of Git, where --filter=blob:none specifies that blobs (file content) should not be downloaded during the initial clone. This significantly reduces the amount of data transferred and thus minimizes the time it takes to clone the repository. You can still search the commit history of the /src directory, as commit and tree objects are included, but file content is fetched on-demand.
git clone –-depth-1 git@ssh.dev.azure.com:v3/org/Project1/repo1 is INCORRECT because while --depth-1 creates a shallow clone that minimizes the clone time by fetching only the latest history of the repository, it limits the ability to search the entire commit history of the /src directory. It only includes the latest commit and not the entire history.
git clone git@ssh.dev.azure.com.com:v3/org/Project1/repo1 is INCORRECT as it performs a full clone of the repository, which does not minimize the time it takes to clone a 1-TB repository.
git clone –-filter=true:0 git@ssh.dev.azure.com:v3/org/Project1/repo1 is INCORRECT because --filter=true:0 is not a valid Git filter option. The command as presented would result in an error and not execute as expected.
Reference(s):
https://git-scm.com/docs/partial-clone
https://git-scm.com/docs/git-clone#Documentation/git-clone.txt---depthltdepthgt
Explanation
Correct Answer(s): git clone –-filter=blob:none git@ssh.dev.azure.com:v3/org/Project1/repo1
git clone –-filter=blob:none git@ssh.dev.azure.com:v3/org/Project1/repo1 is CORRECT because it uses the partial clone feature of Git, where --filter=blob:none specifies that blobs (file content) should not be downloaded during the initial clone. This significantly reduces the amount of data transferred and thus minimizes the time it takes to clone the repository. You can still search the commit history of the /src directory, as commit and tree objects are included, but file content is fetched on-demand.
git clone –-depth-1 git@ssh.dev.azure.com:v3/org/Project1/repo1 is INCORRECT because while --depth-1 creates a shallow clone that minimizes the clone time by fetching only the latest history of the repository, it limits the ability to search the entire commit history of the /src directory. It only includes the latest commit and not the entire history.
git clone git@ssh.dev.azure.com.com:v3/org/Project1/repo1 is INCORRECT as it performs a full clone of the repository, which does not minimize the time it takes to clone a 1-TB repository.
git clone –-filter=true:0 git@ssh.dev.azure.com:v3/org/Project1/repo1 is INCORRECT because --filter=true:0 is not a valid Git filter option. The command as presented would result in an error and not execute as expected.
Reference(s):
https://git-scm.com/docs/partial-clone
https://git-scm.com/docs/git-clone#Documentation/git-clone.txt---depthltdepthgt
Question 12 Single Choice
Your company uses Azure DevOps and Microsoft Azure Active Directory (Azure AD), part of Microsoft Entra.
Only users who have accounts in Azure AD can access the Azure DevOps environment.
You need to ensure that only devices that are connected to the on-premises network can access the Azure DevOps environment.
What should you do?
Explanation
Click "Show Answer" to see the explanation here
Correct Answer(s): In Azure AD, configure conditional access
In Azure AD, configure conditional access is CORRECT because Azure Active Directory's conditional access policies can be set up to control access based on various conditions, including network location. By configuring a conditional access policy, you can restrict access to the Azure DevOps environment such that it is only accessible from devices connected to the on-premises network. This aligns with the requirement to ensure that only devices on the on-premises network can access Azure DevOps.
Assign the Stakeholder access level to all users is INCORRECT because the Stakeholder access level in Azure DevOps pertains to the level of access a user has within Azure DevOps (like work item tracking and viewing), but it does not control network-based access or device-based restrictions.
In Azure DevOps, configure Security in Project Settings is INCORRECT because while you can manage various permissions and security settings within Azure DevOps at the project level, this does not include the ability to restrict access based on the network location of the user's device.
In Azure AD, configure risky sign-ins is INCORRECT because risky sign-ins in Azure AD are used to identify and respond to suspicious sign-in attempts. This feature does not allow for the implementation of network location-based access restrictions for Azure DevOps.
Reference(s):
https://learn.microsoft.com/en-us/entra/identity/conditional-access/overview
https://learn.microsoft.com/en-us/azure/devops/organizations/security/access-levels?view=azure-devops
https://learn.microsoft.com/en-us/entra/id-protection/concept-identity-protection-risks
Explanation
Correct Answer(s): In Azure AD, configure conditional access
In Azure AD, configure conditional access is CORRECT because Azure Active Directory's conditional access policies can be set up to control access based on various conditions, including network location. By configuring a conditional access policy, you can restrict access to the Azure DevOps environment such that it is only accessible from devices connected to the on-premises network. This aligns with the requirement to ensure that only devices on the on-premises network can access Azure DevOps.
Assign the Stakeholder access level to all users is INCORRECT because the Stakeholder access level in Azure DevOps pertains to the level of access a user has within Azure DevOps (like work item tracking and viewing), but it does not control network-based access or device-based restrictions.
In Azure DevOps, configure Security in Project Settings is INCORRECT because while you can manage various permissions and security settings within Azure DevOps at the project level, this does not include the ability to restrict access based on the network location of the user's device.
In Azure AD, configure risky sign-ins is INCORRECT because risky sign-ins in Azure AD are used to identify and respond to suspicious sign-in attempts. This feature does not allow for the implementation of network location-based access restrictions for Azure DevOps.
Reference(s):
https://learn.microsoft.com/en-us/entra/identity/conditional-access/overview
https://learn.microsoft.com/en-us/azure/devops/organizations/security/access-levels?view=azure-devops
https://learn.microsoft.com/en-us/entra/id-protection/concept-identity-protection-risks
Question 13 Single Choice
You manage code by using GitHub.
You plan to ensure that all GitHub Actions are validated by a security team.
You create a branch protection rule requiring that code changes be reviewed by code owners.
You need to create the CODEOWNERS file.
Where should you create the file?
Explanation
Click "Show Answer" to see the explanation here
Correct Answer(s): .github/
.github/ is CORRECT because the CODEOWNERS file should be placed in the repository's .github/ directory (or alternatively in the root or docs/ directory of the repository). This file is used by GitHub to define individuals or teams that are responsible for code in the repository. When the CODEOWNERS file is in the .github/ directory, GitHub automatically uses this file to determine the code owners for each file in the repository, which is essential for implementing a branch protection rule that requires code changes to be reviewed by code owners.

.github/actions/ is INCORRECT because this directory is typically used for storing GitHub Actions workflows specific to a repository, not for the CODEOWNERS file.
.git/ is INCORRECT because this directory is used by Git for storing repository metadata and is not the correct location for the CODEOWNERS file.
.github/workflows/ is INCORRECT because this directory is specifically used for storing workflow files for GitHub Actions, not for the CODEOWNERS file.
Reference(s):
Explanation
Correct Answer(s): .github/
.github/ is CORRECT because the CODEOWNERS file should be placed in the repository's .github/ directory (or alternatively in the root or docs/ directory of the repository). This file is used by GitHub to define individuals or teams that are responsible for code in the repository. When the CODEOWNERS file is in the .github/ directory, GitHub automatically uses this file to determine the code owners for each file in the repository, which is essential for implementing a branch protection rule that requires code changes to be reviewed by code owners.
.github/actions/ is INCORRECT because this directory is typically used for storing GitHub Actions workflows specific to a repository, not for the CODEOWNERS file.
.git/ is INCORRECT because this directory is used by Git for storing repository metadata and is not the correct location for the CODEOWNERS file.
.github/workflows/ is INCORRECT because this directory is specifically used for storing workflow files for GitHub Actions, not for the CODEOWNERS file.
Reference(s):
Question 14 Single Choice
You manage source code control and versioning by using GitHub.
A large file is committed to a repository accidentally.
You need to reduce the size of the repository. The solution must remove the file from the repository.
What should you use?
Explanation
Click "Show Answer" to see the explanation here
Correct Answer(s): bfg
bfg is CORRECT because the BFG Repo-Cleaner is a tool specifically designed for cleaning unwanted data from Git repositories, particularly large files or sensitive data committed accidentally. It's more efficient than using Git's built-in filter-branch command and is well-suited for this purpose. BFG will allow you to remove the large file from the repository's history, thus reducing the repository's size.

lfs is INCORRECT because Git Large File Storage (LFS) is used for handling large files by storing references to them in the repository, rather than the files themselves. While it is useful for managing large files, it does not help in removing a file that has already been committed to the repository history.
gvfs is INCORRECT because Git Virtual File System (GVFS) allows repositories to be used on clients even if the repository is extremely large. However, it does not reduce the size of the repository; rather, it manages how much of the repository is checked out on the client's machine.
init is INCORRECT because git init is a command used to initialize a new Git repository. It is not a tool for modifying the history or size of an existing repository.
Reference(s):
https://rtyley.github.io/bfg-repo-cleaner
Explanation
Correct Answer(s): bfg
bfg is CORRECT because the BFG Repo-Cleaner is a tool specifically designed for cleaning unwanted data from Git repositories, particularly large files or sensitive data committed accidentally. It's more efficient than using Git's built-in filter-branch command and is well-suited for this purpose. BFG will allow you to remove the large file from the repository's history, thus reducing the repository's size.
lfs is INCORRECT because Git Large File Storage (LFS) is used for handling large files by storing references to them in the repository, rather than the files themselves. While it is useful for managing large files, it does not help in removing a file that has already been committed to the repository history.
gvfs is INCORRECT because Git Virtual File System (GVFS) allows repositories to be used on clients even if the repository is extremely large. However, it does not reduce the size of the repository; rather, it manages how much of the repository is checked out on the client's machine.
init is INCORRECT because git init is a command used to initialize a new Git repository. It is not a tool for modifying the history or size of an existing repository.
Reference(s):
https://rtyley.github.io/bfg-repo-cleaner
Question 15 Single Choice
You have an Azure subscription that contains four Azure virtual machines.
You need to configure the virtual machines to use a single identity. The solution must meet the following requirements:
Ensure that the credentials for the identity are managed automatically.
Support granting privileges to the identity.
Which type of identity should you use?
Explanation
Click "Show Answer" to see the explanation here
Correct Answer(s): a user-assigned managed identity
a user-assigned managed identity is CORRECT because it allows for creating a single identity that can be used by multiple Azure resources, including virtual machines. User-assigned managed identities are created as standalone Azure resources and their lifecycle is managed separately from the virtual machines. They support automatic credential management and allow for granting specific privileges, making them suitable for scenarios where a single identity needs to be shared across multiple resources.

a system-assigned managed identity is INCORRECT because it is tied to a specific Azure resource (like a virtual machine) and is automatically created and deleted with that resource. Each virtual machine would have its own system-assigned identity, which does not meet the requirement of using a single identity for all four virtual machines.
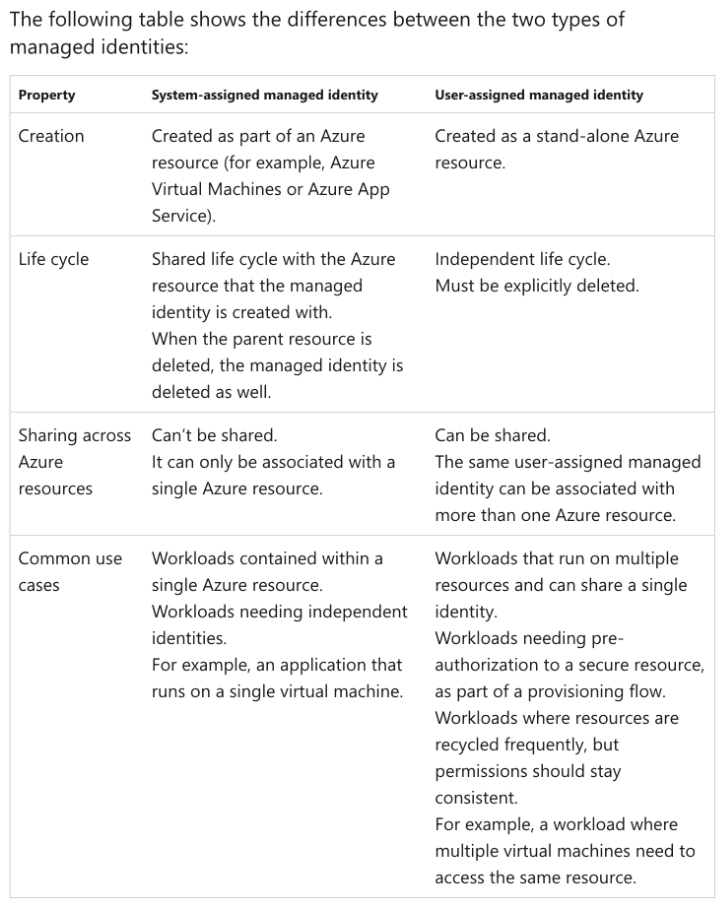
a service principal is INCORRECT because, while it can be used to represent an application or service's identity, it does not automatically manage credentials like a managed identity. Service principals are more complex to manage as they require manual handling of credentials and permissions.
a user account is INCORRECT because using a regular user account does not provide the automation in credential management and is not recommended for services or automated tools due to security and management overhead.
Reference(s):
Explanation
Correct Answer(s): a user-assigned managed identity
a user-assigned managed identity is CORRECT because it allows for creating a single identity that can be used by multiple Azure resources, including virtual machines. User-assigned managed identities are created as standalone Azure resources and their lifecycle is managed separately from the virtual machines. They support automatic credential management and allow for granting specific privileges, making them suitable for scenarios where a single identity needs to be shared across multiple resources.
a system-assigned managed identity is INCORRECT because it is tied to a specific Azure resource (like a virtual machine) and is automatically created and deleted with that resource. Each virtual machine would have its own system-assigned identity, which does not meet the requirement of using a single identity for all four virtual machines.
a service principal is INCORRECT because, while it can be used to represent an application or service's identity, it does not automatically manage credentials like a managed identity. Service principals are more complex to manage as they require manual handling of credentials and permissions.
a user account is INCORRECT because using a regular user account does not provide the automation in credential management and is not recommended for services or automated tools due to security and management overhead.
Reference(s):
Question 16 Single Choice
You have a GitHub repository that contains multiple workflows and a secret stored at the environment level.
You need to ensure that the secret can be used by all the workflows.
What should you do first?
Explanation
Click "Show Answer" to see the explanation here
Correct Answer(s): Recreate the secret at the organization level
Recreate the secret at the organization level is CORRECT because when a secret is stored at the organization level in GitHub, it can be made accessible to multiple repositories within that organization. This allows all workflows across different repositories within the organization to use the same secret, without the need to duplicate the secret in each repository. By recreating the secret at the organization level, you ensure it is centrally managed and available to all required workflows.

Recreate the secret at the repository level is INCORRECT because while this would make the secret available to all workflows within a single repository, it does not extend the availability of the secret to workflows in other repositories within the organization.
Enable required reviewers is INCORRECT because this setting pertains to the branch protection rules and code review process, and it does not relate to the sharing or accessibility of secrets across multiple workflows or repositories.
Reference(s):
Explanation
Correct Answer(s): Recreate the secret at the organization level
Recreate the secret at the organization level is CORRECT because when a secret is stored at the organization level in GitHub, it can be made accessible to multiple repositories within that organization. This allows all workflows across different repositories within the organization to use the same secret, without the need to duplicate the secret in each repository. By recreating the secret at the organization level, you ensure it is centrally managed and available to all required workflows.
Recreate the secret at the repository level is INCORRECT because while this would make the secret available to all workflows within a single repository, it does not extend the availability of the secret to workflows in other repositories within the organization.
Enable required reviewers is INCORRECT because this setting pertains to the branch protection rules and code review process, and it does not relate to the sharing or accessibility of secrets across multiple workflows or repositories.
Reference(s):
Question 17 Single Choice
You have an app named App1 that you release by using Azure Pipelines. App1 has the versions shown in the following table.

You complete a code change to fix a bug that was introduced in version 3.4.3.
Which version number should you assign to the release?
Explanation
Click "Show Answer" to see the explanation here
Correct Answer(s): 4.0.1
4.0.1 is CORRECT because according to Semantic Versioning, when a bug is fixed without introducing new features or causing breaking changes, the patch version is incremented. Since the current release is 4.0.0, the next version that includes a bug fix would be 4.0.1, regardless of when the bug was originally introduced. This ensures that all users on the current major version receive the necessary bug fixes.

Reference(s):
Explanation
Correct Answer(s): 4.0.1
4.0.1 is CORRECT because according to Semantic Versioning, when a bug is fixed without introducing new features or causing breaking changes, the patch version is incremented. Since the current release is 4.0.0, the next version that includes a bug fix would be 4.0.1, regardless of when the bug was originally introduced. This ensures that all users on the current major version receive the necessary bug fixes.
Reference(s):
Question 18 Single Choice
You have an Azure Repos repository named repo1.
You delete a branch named features/feature11.
You need to recover the deleted branch.
Which three commands should you run in sequence?
COMMANDS
git restore <SHA1>
git stash
git checkout <SHA1>
git branch features/feature11
git log
Explanation
Click "Show Answer" to see the explanation here
Correct Answer(s): 5-3-4
5-3-4 is the CORRECT set of commands in sequence.
To recover a deleted branch in Git, you would need to find the last commit that was on that branch (the SHA1 hash), and then create a new branch from that commit. The commands to do this would be:
git log - This is to find the SHA1 of the last commit on the deleted branch. This command can be used with the --all flag to show all the logs from all the branches, including the ones that are not checked out.
git checkout <SHA1> - This is to switch to the state of the repository that the commit hash represents. It doesn't create a new branch yet, it just puts you in a 'detached HEAD' state based on that commit.
git branch features/feature11 - This is to create a new branch named features/feature11 starting from the current commit you have checked out (the last commit of the deleted branch).
The commands git restore <SHA1> and git stash are not used in this scenario. git restore is used to restore working tree files, not branches, and git stash is used to save changes in your working directory and not to navigate the commit history or recover deleted branches.
Reference Links:
https://git-scm.com/docs/git-log
Explanation
Correct Answer(s): 5-3-4
5-3-4 is the CORRECT set of commands in sequence.
To recover a deleted branch in Git, you would need to find the last commit that was on that branch (the SHA1 hash), and then create a new branch from that commit. The commands to do this would be:
git log - This is to find the SHA1 of the last commit on the deleted branch. This command can be used with the --all flag to show all the logs from all the branches, including the ones that are not checked out.
git checkout <SHA1> - This is to switch to the state of the repository that the commit hash represents. It doesn't create a new branch yet, it just puts you in a 'detached HEAD' state based on that commit.
git branch features/feature11 - This is to create a new branch named features/feature11 starting from the current commit you have checked out (the last commit of the deleted branch).
The commands git restore <SHA1> and git stash are not used in this scenario. git restore is used to restore working tree files, not branches, and git stash is used to save changes in your working directory and not to navigate the commit history or recover deleted branches.
Reference Links:
https://git-scm.com/docs/git-log
Question 19 Single Choice
You are creating a dashboard in Azure Boards.
You need to visualize the time from when work starts on a work item until the work item is closed.
Which type of widget should you use?
Explanation
Click "Show Answer" to see the explanation here
Correct Answer(s): cycle time
cycle time is CORRECT because it measures the amount of time it takes for a work item to go from the start of work to completion. This metric is typically used to help teams understand the flow of work and to identify areas for process improvement.

velocity is INCORRECT because velocity tracks the amount of work a team completes during a sprint or iteration. It is a measure of throughput in agile methodologies, not the time taken from start to close for individual work items.
cumulative flow is INCORRECT because it is a visual depiction of the status of work items in a project over time, showing things like work in progress, but it doesn’t measure the time from when work starts to when it’s closed for individual items.
lead time is INCORRECT because it typically measures the time from when the work item was created until it is closed, which includes the time before work actually starts on the item.
Reference Links:
Explanation
Correct Answer(s): cycle time
cycle time is CORRECT because it measures the amount of time it takes for a work item to go from the start of work to completion. This metric is typically used to help teams understand the flow of work and to identify areas for process improvement.
velocity is INCORRECT because velocity tracks the amount of work a team completes during a sprint or iteration. It is a measure of throughput in agile methodologies, not the time taken from start to close for individual work items.
cumulative flow is INCORRECT because it is a visual depiction of the status of work items in a project over time, showing things like work in progress, but it doesn’t measure the time from when work starts to when it’s closed for individual items.
lead time is INCORRECT because it typically measures the time from when the work item was created until it is closed, which includes the time before work actually starts on the item.
Reference Links:
Question 20 Single Choice
You have a public GitHub repository named Public1.
A commit is made to Public1. The commit contains a pattern that matches a regular expression.
Who is notified first when the commit is made?
Explanation
Click "Show Answer" to see the explanation here
Correct Answer(s): the secret scanning partner
The secret scanning partner is CORRECT because when a commit is made to a public repository like Public1 and it contains a pattern that matches a regular expression, especially related to secrets, GitHub's secret scanning feature notifies the secret scanning partner (the service provider who issued the secret). This process is automatic for public repositories. The partner then validates the string and decides on the appropriate action, which may include contacting the repository's owner or taking other measures to secure the secret.
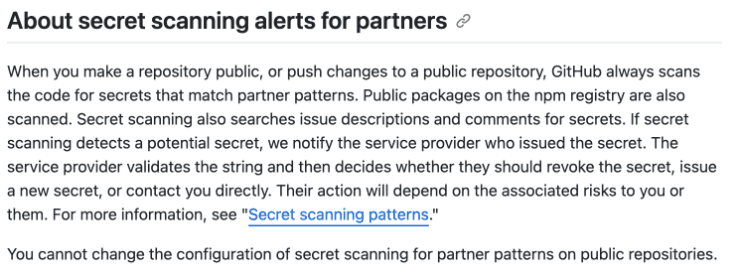
The administrator of the GitHub organization, the committer, and the owner of Public1 are INCORRECT because, in this specific scenario, they are not the first ones to be notified. The first notification goes to the secret scanning partner to validate the potential secret and determine the necessary action to mitigate any security risk.
Reference Links:
Explanation
Correct Answer(s): the secret scanning partner
The secret scanning partner is CORRECT because when a commit is made to a public repository like Public1 and it contains a pattern that matches a regular expression, especially related to secrets, GitHub's secret scanning feature notifies the secret scanning partner (the service provider who issued the secret). This process is automatic for public repositories. The partner then validates the string and decides on the appropriate action, which may include contacting the repository's owner or taking other measures to secure the secret.
The administrator of the GitHub organization, the committer, and the owner of Public1 are INCORRECT because, in this specific scenario, they are not the first ones to be notified. The first notification goes to the secret scanning partner to validate the potential secret and determine the necessary action to mitigate any security risk.
Reference Links:


