
AWS Certified AI Practitioner - (AIF-C01) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 11 Single Choice
A Large Language Model (LLM) chatbot is generating responses that appear plausible and factual but are actually incorrect. What is this phenomenon called?
Explanation

Click "Show Answer" to see the explanation here
Correct option:
This is known as a hallucination, where the model generates seemingly accurate information that is, in fact, incorrect or fabricated
The term "hallucination" refers to a phenomenon in which a language model generates responses that sound plausible and appear factual but are actually false or unsupported by any underlying data. Hallucinations occur because the model relies on patterns learned during training rather than verified knowledge. This is a known limitation of LLMs, which can create convincing text that may mislead users if not carefully monitored or verified against reliable sources.
 via -
via - Incorrect options:
This is known as data drift, where the statistical properties of the input data change over time, causing the model's predictions to become less accurate - Data drift occurs when the distribution or characteristics of the input data change over time, which can cause the model’s performance to degrade. However, data drift does not explain why an LLM would produce plausible but incorrect responses; it is more related to changes in the data environment rather than the inherent behavior of the model in generating misleading information.
This is referred to as overfitting, where the model performs exceptionally well on the training data but fails to generalize to new, unseen data - Overfitting occurs when a model learns the training data too well, capturing noise or irrelevant details, which results in poor performance on new data. However, overfitting does not specifically describe the generation of plausible but incorrect responses; rather, it is about the model's failure to generalize beyond the examples it has been trained on.
This is an example of underfitting, where the model fails to capture the underlying patterns in the data, resulting in poor performance on both training and new data - Underfitting happens when a model is too simple to learn the complexities of the data, leading to poor performance on both training and unseen datasets. While underfitting does cause incorrect responses, it is due to the model's inability to learn from data, not because it is generating fabricated or misleadingly plausible information.
References:
Explanation
Correct option:
This is known as a hallucination, where the model generates seemingly accurate information that is, in fact, incorrect or fabricated
The term "hallucination" refers to a phenomenon in which a language model generates responses that sound plausible and appear factual but are actually false or unsupported by any underlying data. Hallucinations occur because the model relies on patterns learned during training rather than verified knowledge. This is a known limitation of LLMs, which can create convincing text that may mislead users if not carefully monitored or verified against reliable sources.
Incorrect options:
This is known as data drift, where the statistical properties of the input data change over time, causing the model's predictions to become less accurate - Data drift occurs when the distribution or characteristics of the input data change over time, which can cause the model’s performance to degrade. However, data drift does not explain why an LLM would produce plausible but incorrect responses; it is more related to changes in the data environment rather than the inherent behavior of the model in generating misleading information.
This is referred to as overfitting, where the model performs exceptionally well on the training data but fails to generalize to new, unseen data - Overfitting occurs when a model learns the training data too well, capturing noise or irrelevant details, which results in poor performance on new data. However, overfitting does not specifically describe the generation of plausible but incorrect responses; rather, it is about the model's failure to generalize beyond the examples it has been trained on.
This is an example of underfitting, where the model fails to capture the underlying patterns in the data, resulting in poor performance on both training and new data - Underfitting happens when a model is too simple to learn the complexities of the data, leading to poor performance on both training and unseen datasets. While underfitting does cause incorrect responses, it is due to the model's inability to learn from data, not because it is generating fabricated or misleadingly plausible information.
References:
Question 12 Single Choice
A manufacturing company aims to leverage Amazon Bedrock to create a generative AI application that automates the monitoring of inventory levels, sales data, and supply chain information. The application should also recommend optimal reorder points and quantities to enhance operational efficiency.
What do you recommend?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Agents for Amazon Bedrock
Agents for Amazon Bedrock are fully managed capabilities that make it easier for developers to create generative AI-based applications that can complete complex tasks for a wide range of use cases and deliver up-to-date answers based on proprietary knowledge sources.
Agents are software components or entities designed to autonomously or semi-autonomously perform specific actions or tasks based on predefined rules or algorithms. With Amazon Bedrock, agents are utilized to manage and execute various multi-step tasks related to infrastructure provisioning, application deployment, and operational activities. For example, you can create an agent that helps customers process insurance claims or an agent that helps customers make travel reservations. You don't have to provision capacity, manage infrastructure, or write custom code. Amazon Bedrock manages prompt engineering, memory, monitoring, encryption, user permissions, and API invocation.
 via - https://docs.aws.amazon.com/bedrock/latest/userguide/agents.html
via - https://docs.aws.amazon.com/bedrock/latest/userguide/agents.html
Incorrect options:
Knowledge Bases for Amazon Bedrock - With Knowledge Bases for Amazon Bedrock, you can give FMs and agents contextual information from your company’s private data sources for Retrieval Augmented Generation (RAG) to deliver more relevant, accurate, and customized responses. You cannot use Knowledge Bases for Amazon Bedrock for the given use case.
Watermark detection for Amazon Bedrock - The watermark detection mechanism allows you to identify images generated by Amazon Titan Image Generator, a foundation model that allows users to create realistic, studio-quality images in large volumes and at low cost, using natural language prompts. With watermark detection, you can increase transparency around AI-generated content by mitigating harmful content generation and reducing the spread of misinformation. You cannot use watermark detection for the given use case.
Guardrails for Amazon Bedrock - Guardrails for Amazon Bedrock help you implement safeguards for your generative AI applications based on your use cases and responsible AI policies. It helps control the interaction between users and FMs by filtering undesirable and harmful content, redacts personally identifiable information (PII), and enhances content safety and privacy in generative AI applications. You cannot use Guardrails for Amazon Bedrock for the given use case.
References:
Explanation
Correct option:
Agents for Amazon Bedrock
Agents for Amazon Bedrock are fully managed capabilities that make it easier for developers to create generative AI-based applications that can complete complex tasks for a wide range of use cases and deliver up-to-date answers based on proprietary knowledge sources.
Agents are software components or entities designed to autonomously or semi-autonomously perform specific actions or tasks based on predefined rules or algorithms. With Amazon Bedrock, agents are utilized to manage and execute various multi-step tasks related to infrastructure provisioning, application deployment, and operational activities. For example, you can create an agent that helps customers process insurance claims or an agent that helps customers make travel reservations. You don't have to provision capacity, manage infrastructure, or write custom code. Amazon Bedrock manages prompt engineering, memory, monitoring, encryption, user permissions, and API invocation.
via - https://docs.aws.amazon.com/bedrock/latest/userguide/agents.html
Incorrect options:
Knowledge Bases for Amazon Bedrock - With Knowledge Bases for Amazon Bedrock, you can give FMs and agents contextual information from your company’s private data sources for Retrieval Augmented Generation (RAG) to deliver more relevant, accurate, and customized responses. You cannot use Knowledge Bases for Amazon Bedrock for the given use case.
Watermark detection for Amazon Bedrock - The watermark detection mechanism allows you to identify images generated by Amazon Titan Image Generator, a foundation model that allows users to create realistic, studio-quality images in large volumes and at low cost, using natural language prompts. With watermark detection, you can increase transparency around AI-generated content by mitigating harmful content generation and reducing the spread of misinformation. You cannot use watermark detection for the given use case.
Guardrails for Amazon Bedrock - Guardrails for Amazon Bedrock help you implement safeguards for your generative AI applications based on your use cases and responsible AI policies. It helps control the interaction between users and FMs by filtering undesirable and harmful content, redacts personally identifiable information (PII), and enhances content safety and privacy in generative AI applications. You cannot use Guardrails for Amazon Bedrock for the given use case.
References:
Question 13 Single Choice
A company is deploying a generative AI model on Amazon Bedrock and needs to reduce the cost of usage while using prompt examples of up to 10 sample tasks as part of each input.
Which approach would be the most effective in minimizing the costs associated with model usage?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
The company should reduce the number of tokens in the input
For the given use case, reducing the number of tokens in the input is the most effective way to minimize costs associated with the use of a generative AI model on Amazon Bedrock. Each token represents a piece of text that the model processes, and the cost is directly proportional to the number of tokens in the input. By reducing the input length, the company can decrease the amount of computational power required for each request, thereby lowering the cost of usage.
 via - https://docs.aws.amazon.com/bedrock/latest/userguide/bedrock-pricing.html
via - https://docs.aws.amazon.com/bedrock/latest/userguide/bedrock-pricing.html
Incorrect options:
The company should reduce the temperature inference parameter for the model - Reducing the temperature affects the creativity and randomness of the model's output but has no effect on the cost related to input processing. The cost of using a generative AI model is primarily determined by the number of tokens processed, not by the temperature setting. Thus, adjusting the temperature is irrelevant to cost reduction.
The company should reduce the top-P inference parameter for the model - Reducing the top-P value affects the diversity and variety of the model's generated output but does not influence the cost of processing the input. Since the cost is based on the number of tokens in the input, changing the top-P value does not contribute to reducing expenses.
The company should reduce the batch size while training the model - This option acts as a distractor. Modifying the batch size while training the model has no impact on the cost of model usage during inference. You should also note that you cannot train the base Foundation Models (FMs) using Amazon Bedrock, rather you can only customize the base FMs wherein you create your own private copy of the base FM using Provisioned Throughput mode.
References:
https://docs.aws.amazon.com/bedrock/latest/userguide/bedrock-pricing.html
https://docs.aws.amazon.com/bedrock/latest/userguide/inference-parameters.html
https://docs.aws.amazon.com/bedrock/latest/userguide/model-customization-guidelines.html
Explanation
Correct option:
The company should reduce the number of tokens in the input
For the given use case, reducing the number of tokens in the input is the most effective way to minimize costs associated with the use of a generative AI model on Amazon Bedrock. Each token represents a piece of text that the model processes, and the cost is directly proportional to the number of tokens in the input. By reducing the input length, the company can decrease the amount of computational power required for each request, thereby lowering the cost of usage.
via - https://docs.aws.amazon.com/bedrock/latest/userguide/bedrock-pricing.html
Incorrect options:
The company should reduce the temperature inference parameter for the model - Reducing the temperature affects the creativity and randomness of the model's output but has no effect on the cost related to input processing. The cost of using a generative AI model is primarily determined by the number of tokens processed, not by the temperature setting. Thus, adjusting the temperature is irrelevant to cost reduction.
The company should reduce the top-P inference parameter for the model - Reducing the top-P value affects the diversity and variety of the model's generated output but does not influence the cost of processing the input. Since the cost is based on the number of tokens in the input, changing the top-P value does not contribute to reducing expenses.
The company should reduce the batch size while training the model - This option acts as a distractor. Modifying the batch size while training the model has no impact on the cost of model usage during inference. You should also note that you cannot train the base Foundation Models (FMs) using Amazon Bedrock, rather you can only customize the base FMs wherein you create your own private copy of the base FM using Provisioned Throughput mode.
References:
https://docs.aws.amazon.com/bedrock/latest/userguide/bedrock-pricing.html
https://docs.aws.amazon.com/bedrock/latest/userguide/inference-parameters.html
https://docs.aws.amazon.com/bedrock/latest/userguide/model-customization-guidelines.html
Question 14 Multiple Choice
A financial services company is building machine learning models to predict customer churn and detect fraudulent transactions. The data science team is exploring different machine learning approaches and needs to understand which methods fall under supervised learning, where the model is trained on labeled data with known outcomes. Identifying the correct supervised learning techniques will help the team select the most appropriate models for their predictive tasks.
Which of the following are examples of supervised learning? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Supervised learning algorithms train on sample data that specifies both the algorithm's input and output. For example, the data could be images of handwritten numbers that are annotated to indicate which numbers they represent. Given sufficient labeled data, the supervised learning system would eventually recognize the clusters of pixels and shapes associated with each handwritten number.
 via - https://aws.amazon.com/compare/the-difference-between-machine-learning-supervised-and-unsupervised/
via - https://aws.amazon.com/compare/the-difference-between-machine-learning-supervised-and-unsupervised/
Linear regression
Linear regression refers to supervised learning models that, based on one or more inputs, predict a value from a continuous scale. An example of linear regression is predicting a house price. You could predict a house’s price based on its location, age, and number of rooms after you train a model on a set of historical sales training data with those variables.
Neural network
A neural network solution is a more complex supervised learning technique. To produce a given outcome, it takes some given inputs and performs one or more layers of mathematical transformation based on adjusting data weightings. An example of a neural network technique is predicting a digit from a handwritten image.
Incorrect options:
Document classification - This is an example of semi-supervised learning. Semi-supervised learning is when you apply both supervised and unsupervised learning techniques to a common problem. This technique relies on using a small amount of labeled data and a large amount of unlabeled data to train systems. When applying categories to a large document base, there may be too many documents to physically label. For example, these could be countless reports, transcripts, or specifications. Training on the unlabeled data helps identify similar documents for labeling.
Association rule learning - This is an example of unsupervised learning. Association rule learning techniques uncover rule-based relationships between inputs in a dataset. For example, the Apriori algorithm conducts market basket analysis to identify rules like coffee and milk often being purchased together.
Clustering - Clustering is an unsupervised learning technique that groups certain data inputs, so they may be categorized as a whole. There are various types of clustering algorithms depending on the input data. An example of clustering is identifying different types of network traffic to predict potential security incidents.
References:
https://aws.amazon.com/what-is/machine-learning/
https://aws.amazon.com/compare/the-difference-between-machine-learning-supervised-and-unsupervised/
Explanation
Correct options:
Supervised learning algorithms train on sample data that specifies both the algorithm's input and output. For example, the data could be images of handwritten numbers that are annotated to indicate which numbers they represent. Given sufficient labeled data, the supervised learning system would eventually recognize the clusters of pixels and shapes associated with each handwritten number.
via - https://aws.amazon.com/compare/the-difference-between-machine-learning-supervised-and-unsupervised/
Linear regression
Linear regression refers to supervised learning models that, based on one or more inputs, predict a value from a continuous scale. An example of linear regression is predicting a house price. You could predict a house’s price based on its location, age, and number of rooms after you train a model on a set of historical sales training data with those variables.
Neural network
A neural network solution is a more complex supervised learning technique. To produce a given outcome, it takes some given inputs and performs one or more layers of mathematical transformation based on adjusting data weightings. An example of a neural network technique is predicting a digit from a handwritten image.
Incorrect options:
Document classification - This is an example of semi-supervised learning. Semi-supervised learning is when you apply both supervised and unsupervised learning techniques to a common problem. This technique relies on using a small amount of labeled data and a large amount of unlabeled data to train systems. When applying categories to a large document base, there may be too many documents to physically label. For example, these could be countless reports, transcripts, or specifications. Training on the unlabeled data helps identify similar documents for labeling.
Association rule learning - This is an example of unsupervised learning. Association rule learning techniques uncover rule-based relationships between inputs in a dataset. For example, the Apriori algorithm conducts market basket analysis to identify rules like coffee and milk often being purchased together.
Clustering - Clustering is an unsupervised learning technique that groups certain data inputs, so they may be categorized as a whole. There are various types of clustering algorithms depending on the input data. An example of clustering is identifying different types of network traffic to predict potential security incidents.
References:
https://aws.amazon.com/what-is/machine-learning/
https://aws.amazon.com/compare/the-difference-between-machine-learning-supervised-and-unsupervised/
Question 15 Single Choice
A technology consulting firm is working with clients to implement generative AI solutions and needs to help them understand the differences between various AI models. In particular, the firm is evaluating the use of Foundation Models (FMs) and Large Language Models (LLMs) for tasks such as text generation, image creation, and data summarization. The firm wants to clarify the distinctions between these two types of models, especially in terms of their design, capabilities, and application scope.
What is a key difference between Foundation Models (FMs) and Large Language Models (LLMs) in the context of generative AI?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
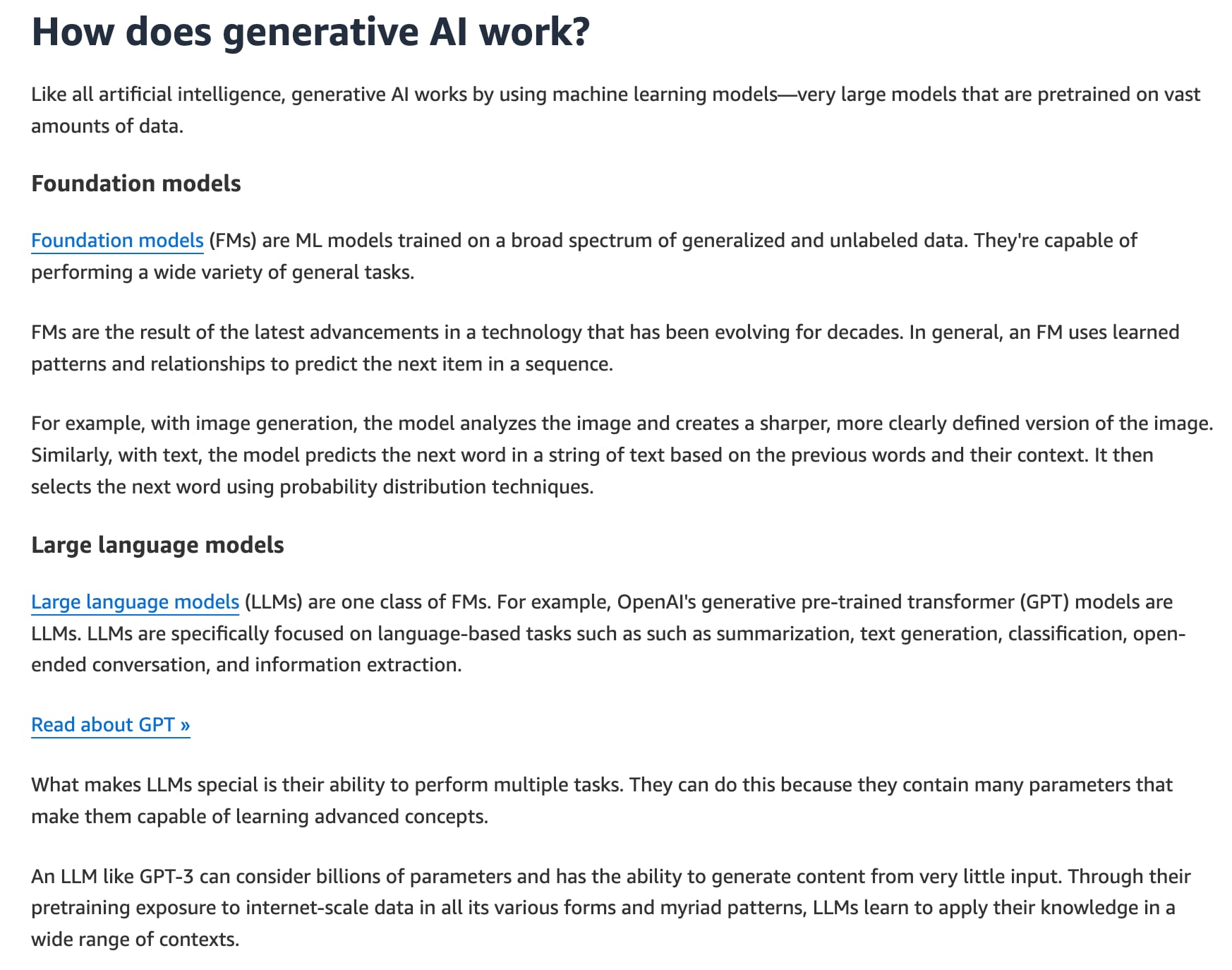
Foundation Models serve as a broad base for various AI applications by providing generalized capabilities, whereas Large Language Models are specialized for understanding and generating human language
Foundation Models provide a broad base with generalized capabilities that can be applied to various tasks such as natural language processing (NLP), question answering, and image classification. The size and general-purpose nature of FMs make them different from traditional ML models, which typically perform specific tasks, like analyzing text for sentiment, classifying images, and forecasting trends.
Generally, an FM uses learned patterns and relationships to predict the next item in a sequence. For example, with image generation, the model analyzes the image and creates a sharper, more clearly defined version of the image. Similarly, with text, the model predicts the next word in a string of text based on the previous words and their context. It then selects the next word using probability distribution techniques.
In contrast, Large Language Models are specifically designed for tasks involving the understanding and generation of human language, making them more specialized. LLMs are specifically focused on language-based tasks such as summarization, text generation, classification, open-ended conversation, and information extraction.
 via - https://aws.amazon.com/what-is/generative-ai/
via - https://aws.amazon.com/what-is/generative-ai/
Incorrect options:
Foundation Models are specifically designed for text generation, while Large Language Models can generate images, videos, and audio - Foundation Models and Large Language Models (LLMs) can both be used for a variety of generative tasks, not limited to specific types like text generation or multimedia content.
Large Language Models are pre-trained on massive datasets and can be fine-tuned for specific tasks, whereas Foundation Models are not pre-trained and are built from scratch for each application - Both Foundation Models and LLMs are pre-trained on massive datasets. The distinction is more about their general purpose versus their specialized nature.
Foundation Models are only used in academic research, while Large Language Models are used in commercial applications - Both Foundation Models and Large Language Models are used in various settings, including academic research and commercial applications.
References:
https://aws.amazon.com/what-is/generative-ai/
Explanation
Correct option:
Foundation Models serve as a broad base for various AI applications by providing generalized capabilities, whereas Large Language Models are specialized for understanding and generating human language
Foundation Models provide a broad base with generalized capabilities that can be applied to various tasks such as natural language processing (NLP), question answering, and image classification. The size and general-purpose nature of FMs make them different from traditional ML models, which typically perform specific tasks, like analyzing text for sentiment, classifying images, and forecasting trends.
Generally, an FM uses learned patterns and relationships to predict the next item in a sequence. For example, with image generation, the model analyzes the image and creates a sharper, more clearly defined version of the image. Similarly, with text, the model predicts the next word in a string of text based on the previous words and their context. It then selects the next word using probability distribution techniques.
In contrast, Large Language Models are specifically designed for tasks involving the understanding and generation of human language, making them more specialized. LLMs are specifically focused on language-based tasks such as summarization, text generation, classification, open-ended conversation, and information extraction.
via - https://aws.amazon.com/what-is/generative-ai/
Incorrect options:
Foundation Models are specifically designed for text generation, while Large Language Models can generate images, videos, and audio - Foundation Models and Large Language Models (LLMs) can both be used for a variety of generative tasks, not limited to specific types like text generation or multimedia content.
Large Language Models are pre-trained on massive datasets and can be fine-tuned for specific tasks, whereas Foundation Models are not pre-trained and are built from scratch for each application - Both Foundation Models and LLMs are pre-trained on massive datasets. The distinction is more about their general purpose versus their specialized nature.
Foundation Models are only used in academic research, while Large Language Models are used in commercial applications - Both Foundation Models and Large Language Models are used in various settings, including academic research and commercial applications.
References:
https://aws.amazon.com/what-is/generative-ai/
Question 16 Single Choice
The development team at an e-commerce company is considering using Amazon Personalize to create tailored experiences based on user behavior, such as purchase history and browsing patterns. To make an informed decision, the team needs a clear understanding of how Amazon Personalize works and how it generates these recommendations in real time.
Given this context, which statement best describes the Amazon Personalize service?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Elevate the customer experience with ML-powered personalization
Amazon Personalize is a fully managed machine learning (ML) service that uses your data to generate product and content recommendations for your users. You provide data about your end-users (e.g., age, location, device type), items in your catalog (e.g., genre, price), and interactions between users and items (e.g., clicks, purchases). Personalize uses this data to train custom, private models that generate recommendations that can be surfaced via an API.
The service uses algorithms to analyze customer behavior and recommend products, content, and services that are likely to be of interest to them. This enhanced customer experience approach can increase customer engagement, loyalty, and sales, which can lead to increases in revenue and profitability.
Here are some reasons why businesses choose Amazon Personalize for personalization:
Improve user engagement and conversion rates: Users are more likely to interact with products and services that are tailored to their preferences, thus businesses can boost user engagement and conversion rates by offering personalized recommendations.
Increase customer satisfaction: Businesses can offer a better customer experience by using personalization to surface products and services that are more relevant to their needs and interests.
Incorrect options:
Automatically convert speech to text and gain insights - Amazon Transcribe is an automatic speech recognition service that uses machine learning models to convert audio to text. You can use Amazon Transcribe as a standalone transcription service or add speech-to-text capabilities to any application.
Derive and understand valuable insights from text within documents - Amazon Comprehend is a natural language processing (NLP) service that uses machine learning to find meaning and insights in text. By utilizing NLP, you can extract important phrases, sentiments, syntax, key entities such as brand, date, location, person, etc., and the language of the text. You can use Amazon Comprehend to identify the language of the text, extract key phrases, places, people, brands, or events, understand sentiment about products or services, and identify the main topics from a library of documents.
Deploy high-quality, natural-sounding human voices in dozens of languages - Amazon Polly uses deep learning technologies to synthesize natural-sounding human speech, so you can convert articles to speech. With dozens of lifelike voices across a broad set of languages, use Amazon Polly to build speech-activated applications.
Reference:
Explanation
Correct option:
Elevate the customer experience with ML-powered personalization
Amazon Personalize is a fully managed machine learning (ML) service that uses your data to generate product and content recommendations for your users. You provide data about your end-users (e.g., age, location, device type), items in your catalog (e.g., genre, price), and interactions between users and items (e.g., clicks, purchases). Personalize uses this data to train custom, private models that generate recommendations that can be surfaced via an API.
The service uses algorithms to analyze customer behavior and recommend products, content, and services that are likely to be of interest to them. This enhanced customer experience approach can increase customer engagement, loyalty, and sales, which can lead to increases in revenue and profitability.
Here are some reasons why businesses choose Amazon Personalize for personalization:
Improve user engagement and conversion rates: Users are more likely to interact with products and services that are tailored to their preferences, thus businesses can boost user engagement and conversion rates by offering personalized recommendations.
Increase customer satisfaction: Businesses can offer a better customer experience by using personalization to surface products and services that are more relevant to their needs and interests.
Incorrect options:
Automatically convert speech to text and gain insights - Amazon Transcribe is an automatic speech recognition service that uses machine learning models to convert audio to text. You can use Amazon Transcribe as a standalone transcription service or add speech-to-text capabilities to any application.
Derive and understand valuable insights from text within documents - Amazon Comprehend is a natural language processing (NLP) service that uses machine learning to find meaning and insights in text. By utilizing NLP, you can extract important phrases, sentiments, syntax, key entities such as brand, date, location, person, etc., and the language of the text. You can use Amazon Comprehend to identify the language of the text, extract key phrases, places, people, brands, or events, understand sentiment about products or services, and identify the main topics from a library of documents.
Deploy high-quality, natural-sounding human voices in dozens of languages - Amazon Polly uses deep learning technologies to synthesize natural-sounding human speech, so you can convert articles to speech. With dozens of lifelike voices across a broad set of languages, use Amazon Polly to build speech-activated applications.
Reference:
Question 17 Single Choice
A software development company is interested in using Amazon Q Developer to enhance its applications by integrating AI-driven features such as automated code suggestions, task automation, and content generation. To understand the technical foundation behind Amazon Q Developer and how it leverages cloud-based services for its capabilities, the development team is looking to identify which AWS service powers its core functionalities.
Which of the following AWS services powers Amazon Q Developer?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Amazon Bedrock
Amazon Q Developer is a generative artificial intelligence (AI) powered conversational assistant that can help you understand, build, extend, and operate AWS applications. You can ask questions about AWS architecture, your AWS resources, best practices, documentation, support, and more. Amazon Q is constantly updating its capabilities so your questions get the most contextually relevant and actionable answers.
Amazon Q Developer is powered by Amazon Bedrock.
 via - https://docs.aws.amazon.com/amazonq/latest/qbusiness-ug/what-is.html
via - https://docs.aws.amazon.com/amazonq/latest/qbusiness-ug/what-is.html
Incorrect options:
Amazon Q Apps - Amazon Q Apps is a capability within Amazon Q Business for users to create generative artificial intelligence (generative AI)–powered apps based on the organization’s data. Users can build apps using natural language and securely publish them to the organization’s app library for everyone to use.
Amazon SageMaker Jumpstart - Amazon SageMaker JumpStart is a machine learning hub with foundation models, built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks With SageMaker JumpStart, you can access pre-trained models, including foundation models, to perform tasks like article summarization and image generation.
Amazon Kendra - Amazon Kendra is an intelligent search service that uses natural language processing and advanced machine learning algorithms to return specific answers to search questions from your data.
References:
https://docs.aws.amazon.com/amazonq/latest/qbusiness-ug/what-is.html
https://docs.aws.amazon.com/amazonq/latest/qbusiness-ug/concepts-terms.html
https://docs.aws.amazon.com/kendra/latest/dg/what-is-kendra.html
Explanation
Correct option:
Amazon Bedrock
Amazon Q Developer is a generative artificial intelligence (AI) powered conversational assistant that can help you understand, build, extend, and operate AWS applications. You can ask questions about AWS architecture, your AWS resources, best practices, documentation, support, and more. Amazon Q is constantly updating its capabilities so your questions get the most contextually relevant and actionable answers.
Amazon Q Developer is powered by Amazon Bedrock.
via - https://docs.aws.amazon.com/amazonq/latest/qbusiness-ug/what-is.html
Incorrect options:
Amazon Q Apps - Amazon Q Apps is a capability within Amazon Q Business for users to create generative artificial intelligence (generative AI)–powered apps based on the organization’s data. Users can build apps using natural language and securely publish them to the organization’s app library for everyone to use.
Amazon SageMaker Jumpstart - Amazon SageMaker JumpStart is a machine learning hub with foundation models, built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks With SageMaker JumpStart, you can access pre-trained models, including foundation models, to perform tasks like article summarization and image generation.
Amazon Kendra - Amazon Kendra is an intelligent search service that uses natural language processing and advanced machine learning algorithms to return specific answers to search questions from your data.
References:
https://docs.aws.amazon.com/amazonq/latest/qbusiness-ug/what-is.html
https://docs.aws.amazon.com/amazonq/latest/qbusiness-ug/concepts-terms.html
https://docs.aws.amazon.com/kendra/latest/dg/what-is-kendra.html
Question 18 Single Choice
In the context of the shared responsibility model for AWS cloud services, which of the following best describes the division of responsibilities between the customer and AWS?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
AWS is responsible for the security "of" the cloud, including infrastructure, hardware, and software, while the customer is responsible for security "in" the cloud, including data, applications, and access management
In the shared responsibility model, AWS is responsible for the security of the cloud, which includes the physical security of data centers, networking infrastructure, and hardware. The customer is responsible for security in the cloud, which includes securing their data, managing access and identity, configuring network settings, and ensuring application security.
Shared Responsibility Model Overview: 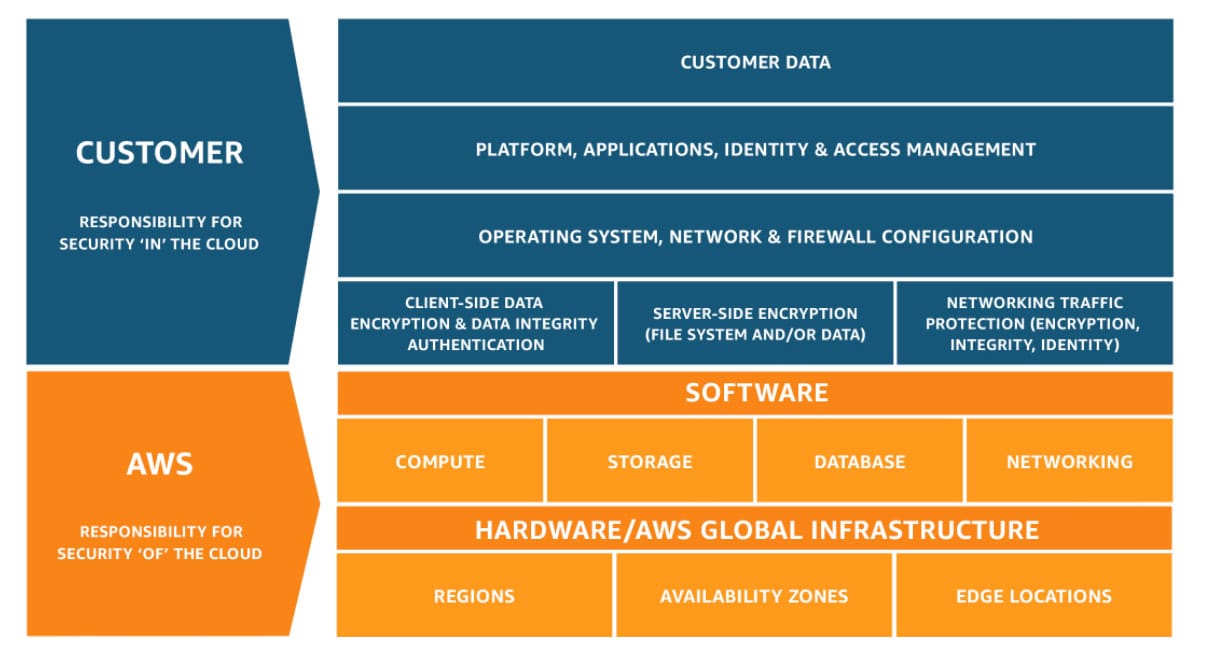 via - https://aws.amazon.com/compliance/shared-responsibility-model/
via - https://aws.amazon.com/compliance/shared-responsibility-model/
Incorrect options:
AWS is responsible for configuring and managing the security settings of the customer's applications, while the customer is responsible for the underlying hardware infrastructure - AWS manages the underlying infrastructure, including the hardware, but the customer is responsible for configuring and managing the security settings of their applications.
AWS handles all security aspects including data encryption, user access management, and application security, while the customer only needs to manage their virtual machines - AWS does not handle all aspects of security; customers must manage their own data encryption, user access management, and application security.
Customers are responsible for ensuring the physical security of data centers, while AWS is responsible for monitoring network traffic and managing user identities - Customers do not manage the physical security of data centers; AWS is responsible for this aspect of security.
Reference:
https://aws.amazon.com/compliance/shared-responsibility-model/
Explanation
Correct option:
AWS is responsible for the security "of" the cloud, including infrastructure, hardware, and software, while the customer is responsible for security "in" the cloud, including data, applications, and access management
In the shared responsibility model, AWS is responsible for the security of the cloud, which includes the physical security of data centers, networking infrastructure, and hardware. The customer is responsible for security in the cloud, which includes securing their data, managing access and identity, configuring network settings, and ensuring application security.
Shared Responsibility Model Overview: via - https://aws.amazon.com/compliance/shared-responsibility-model/
Incorrect options:
AWS is responsible for configuring and managing the security settings of the customer's applications, while the customer is responsible for the underlying hardware infrastructure - AWS manages the underlying infrastructure, including the hardware, but the customer is responsible for configuring and managing the security settings of their applications.
AWS handles all security aspects including data encryption, user access management, and application security, while the customer only needs to manage their virtual machines - AWS does not handle all aspects of security; customers must manage their own data encryption, user access management, and application security.
Customers are responsible for ensuring the physical security of data centers, while AWS is responsible for monitoring network traffic and managing user identities - Customers do not manage the physical security of data centers; AWS is responsible for this aspect of security.
Reference:
https://aws.amazon.com/compliance/shared-responsibility-model/
Question 19 Single Choice
Which of the following embedding models would be most suitable for differentiating the contextual meanings of words when applied to different phrases?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Bidirectional Encoder Representations from Transformers (BERT)
Embedding models are algorithms trained to encapsulate information into dense representations in a multi-dimensional space. Data scientists use embedding models to enable ML models to comprehend and reason with high-dimensional data.
BERT is the correct answer because it is specifically designed to capture the contextual meaning of words by looking at both the words that come before and after them (bidirectional context). Unlike older models that use static embeddings, BERT creates dynamic word embeddings that change depending on the surrounding text, allowing it to understand the different meanings of the same word in various contexts. This makes BERT ideal for tasks that require understanding the nuances and subtleties of language.
 via - https://aws.amazon.com/what-is/embeddings-in-machine-learning/
via - https://aws.amazon.com/what-is/embeddings-in-machine-learning/
Incorrect options:
Principal Component Analysis (PCA) - PCA is a statistical method used for reducing the dimensions of large datasets to simplify them while retaining most of the variance in the data. While it can be applied to various fields, including image compression and data visualization, PCA does not understand or differentiate the contextual meanings of words in natural language processing. Thus, it is not a suitable choice for understanding word meanings in different phrases.
Word2Vec - Word2Vec is an early embedding model that creates vector representations of words based on their co-occurrence in a given text. However, it uses static embeddings, meaning each word has a single vector representation regardless of the context. This limitation makes Word2Vec less effective at differentiating words with multiple meanings across different phrases since it cannot adjust the embedding based on context, unlike BERT.
Singular Value Decomposition (SVD) - SVD is a matrix decomposition method used in various applications like data compression and noise reduction. Although it can be part of older methods for text analysis, such as Latent Semantic Analysis (LSA), it is not designed to handle the dynamic, context-dependent meanings of words in sentences. Therefore, it is not suitable for differentiating contextual meanings of words across various phrases.
Reference:
https://aws.amazon.com/what-is/embeddings-in-machine-learning/
Explanation
Correct option:
Bidirectional Encoder Representations from Transformers (BERT)
Embedding models are algorithms trained to encapsulate information into dense representations in a multi-dimensional space. Data scientists use embedding models to enable ML models to comprehend and reason with high-dimensional data.
BERT is the correct answer because it is specifically designed to capture the contextual meaning of words by looking at both the words that come before and after them (bidirectional context). Unlike older models that use static embeddings, BERT creates dynamic word embeddings that change depending on the surrounding text, allowing it to understand the different meanings of the same word in various contexts. This makes BERT ideal for tasks that require understanding the nuances and subtleties of language.
via - https://aws.amazon.com/what-is/embeddings-in-machine-learning/
Incorrect options:
Principal Component Analysis (PCA) - PCA is a statistical method used for reducing the dimensions of large datasets to simplify them while retaining most of the variance in the data. While it can be applied to various fields, including image compression and data visualization, PCA does not understand or differentiate the contextual meanings of words in natural language processing. Thus, it is not a suitable choice for understanding word meanings in different phrases.
Word2Vec - Word2Vec is an early embedding model that creates vector representations of words based on their co-occurrence in a given text. However, it uses static embeddings, meaning each word has a single vector representation regardless of the context. This limitation makes Word2Vec less effective at differentiating words with multiple meanings across different phrases since it cannot adjust the embedding based on context, unlike BERT.
Singular Value Decomposition (SVD) - SVD is a matrix decomposition method used in various applications like data compression and noise reduction. Although it can be part of older methods for text analysis, such as Latent Semantic Analysis (LSA), it is not designed to handle the dynamic, context-dependent meanings of words in sentences. Therefore, it is not suitable for differentiating contextual meanings of words across various phrases.
Reference:
https://aws.amazon.com/what-is/embeddings-in-machine-learning/
Question 20 Multiple Choice
A company is exploring Amazon Q to streamline its internal business processes through automation and generative AI capabilities. The team is particularly interested in understanding how Amazon Q integrates generative AI techniques within its web application workflow to enhance tasks such as automating report generation, creating summaries, and analyzing large datasets. They want to know which specific generative AI techniques are employed in Amazon Q to achieve these outcomes.
Which of the following generative AI techniques are used in the Amazon Q Business web application workflow? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Large Language Model (LLM)
Large language models (LLMs) are a class of Foundation Models (FMs). For example, OpenAI's generative pre-trained transformer (GPT) models are LLMs. LLMs are specifically focused on language-based tasks such as such as summarization, text generation, classification, open-ended conversation, and information extraction.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response. Large Language Models (LLMs) are trained on vast volumes of data and use billions of parameters to generate original output for tasks like answering questions, translating languages, and completing sentences. RAG extends the already powerful capabilities of LLMs to specific domains or an organization's internal knowledge base, all without the need to retrain the model. It is a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts.
Depending on the configuration, Amazon Q Business web application workflow can use LLM/RAG or both.
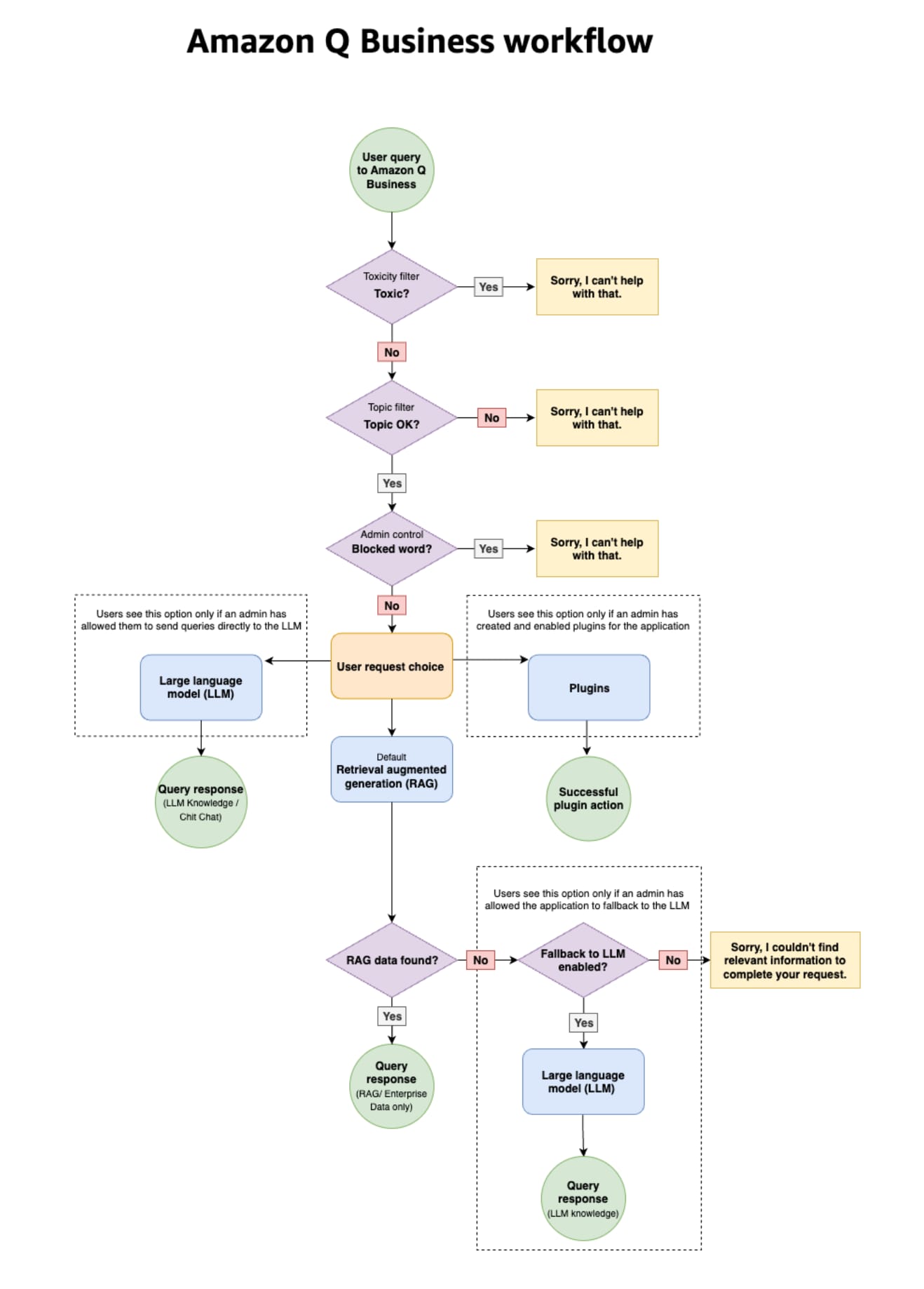 via - https://docs.aws.amazon.com/amazonq/latest/qbusiness-ug/how-it-works.html
via - https://docs.aws.amazon.com/amazonq/latest/qbusiness-ug/how-it-works.html
Incorrect options:
Diffusion Model - Diffusion models create new data by iteratively making controlled random changes to an initial data sample. They start with the original data and add subtle changes (noise), progressively making it less similar to the original. This noise is carefully controlled to ensure the generated data remains coherent and realistic. After adding noise over several iterations, the diffusion model reverses the process. Reverse denoising gradually removes the noise to produce a new data sample that resembles the original.
Generative adversarial network (GAN) - GANs work by training two neural networks in a competitive manner. The first network, known as the generator, generates fake data samples by adding random noise. The second network, called the discriminator, tries to distinguish between real data and the fake data produced by the generator. During training, the generator continually improves its ability to create realistic data while the discriminator becomes better at telling real from fake. This adversarial process continues until the generator produces data that is so convincing that the discriminator can't differentiate it from real data.
Variational autoencoders (VAE) - VAEs use two neural networks—the encoder and the decoder. The encoder neural network maps the input data to a mean and variance for each dimension of the latent space. It generates a random sample from a Gaussian (normal) distribution. This sample is a point in the latent space and represents a compressed, simplified version of the input data. The decoder neural network takes this sampled point from the latent space and reconstructs it back into data that resembles the original input.
References:
https://aws.amazon.com/what-is/generative-ai/
https://aws.amazon.com/what-is/retrieval-augmented-generation/
https://docs.aws.amazon.com/amazonq/latest/qbusiness-ug/how-it-works.html
Explanation
Correct options:
Large Language Model (LLM)
Large language models (LLMs) are a class of Foundation Models (FMs). For example, OpenAI's generative pre-trained transformer (GPT) models are LLMs. LLMs are specifically focused on language-based tasks such as such as summarization, text generation, classification, open-ended conversation, and information extraction.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response. Large Language Models (LLMs) are trained on vast volumes of data and use billions of parameters to generate original output for tasks like answering questions, translating languages, and completing sentences. RAG extends the already powerful capabilities of LLMs to specific domains or an organization's internal knowledge base, all without the need to retrain the model. It is a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts.
Depending on the configuration, Amazon Q Business web application workflow can use LLM/RAG or both.
via - https://docs.aws.amazon.com/amazonq/latest/qbusiness-ug/how-it-works.html
Incorrect options:
Diffusion Model - Diffusion models create new data by iteratively making controlled random changes to an initial data sample. They start with the original data and add subtle changes (noise), progressively making it less similar to the original. This noise is carefully controlled to ensure the generated data remains coherent and realistic. After adding noise over several iterations, the diffusion model reverses the process. Reverse denoising gradually removes the noise to produce a new data sample that resembles the original.
Generative adversarial network (GAN) - GANs work by training two neural networks in a competitive manner. The first network, known as the generator, generates fake data samples by adding random noise. The second network, called the discriminator, tries to distinguish between real data and the fake data produced by the generator. During training, the generator continually improves its ability to create realistic data while the discriminator becomes better at telling real from fake. This adversarial process continues until the generator produces data that is so convincing that the discriminator can't differentiate it from real data.
Variational autoencoders (VAE) - VAEs use two neural networks—the encoder and the decoder. The encoder neural network maps the input data to a mean and variance for each dimension of the latent space. It generates a random sample from a Gaussian (normal) distribution. This sample is a point in the latent space and represents a compressed, simplified version of the input data. The decoder neural network takes this sampled point from the latent space and reconstructs it back into data that resembles the original input.
References:
https://aws.amazon.com/what-is/generative-ai/
https://aws.amazon.com/what-is/retrieval-augmented-generation/
https://docs.aws.amazon.com/amazonq/latest/qbusiness-ug/how-it-works.html


