
AWS Certified DevOps Engineer - Professional - (DOP-C02) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 11 Single Choice
A company wants to create an automated monitoring solution to generate real-time customized notifications regarding unrestricted security groups in the company's production AWS account. The notification must contain the name and ID of the noncompliant security group. The DevOps team at the company has already activated the restricted-ssh AWS Config managed rule. The team has also set up an Amazon Simple Notification Service (Amazon SNS) topic and subscribed relevant personnel to it.
Which of the following options represents the BEST solution for the given scenario?
Explanation

Click "Show Answer" to see the explanation here
Correct option:
Set up an Amazon EventBridge rule that matches an AWS Config evaluation result of NON_COMPLIANT for the restricted-ssh rule. Create an input transformer for the EventBridge rule. Set up the EventBridge rule to publish a notification to the SNS topic
You can use AWS Config to evaluate the configuration settings of your AWS resources. You do this by creating AWS Config rules, which represent your ideal configuration settings. AWS Config provides customizable, predefined rules called managed rules to help you get started. While AWS Config continuously tracks the configuration changes that occur among your resources, it checks whether these changes do not comply with the conditions in your rules.
The restricted-ssh rule checks if the incoming SSH traffic for the security groups is accessible. The rule is COMPLIANT when IP addresses of the incoming SSH traffic in the security groups are restricted (CIDR other than 0.0.0.0/0). This rule applies only to IPv4.
For the given use case, you need to monitor for the NON_COMPLIANT evaluation result of the rule, which implies that the rule has failed the conditions of the compliance check. You can then create an Amazon EventBridge rule (with AWS Config configured as a source) that is put in action when it matches the NON_COMPLIANT evaluation result of the restricted-ssh rule. The EventBridge rule, in turn, publishes a notification to the SNS topic.
 via - https://docs.aws.amazon.com/config/latest/developerguide/evaluate-config.html
via - https://docs.aws.amazon.com/config/latest/developerguide/evaluate-config.html
Incorrect options:
Set up an Amazon EventBridge rule that matches an AWS Config evaluation result of NON_COMPLIANT for all AWS Config managed rules. Create an input transformer for the EventBridge rule. Set up the EventBridge rule to publish a notification to the SNS topic. Set up a filter policy on the SNS topic to send only notifications that contain the text of NON_COMPLIANT in the notification to subscribers
Set up an Amazon EventBridge rule that matches all AWS Config evaluation results for the restricted-ssh rule. Create an input transformer for the EventBridge rule. Set up the EventBridge rule to publish a notification to the SNS topic. Set up a filter policy on the SNS topic to send only notifications that contain the text of NON_COMPLIANT in the notification to subscribers
You should note that you can only set up a filter policy on an SNS subscription and NOT on the SNS topic itself. In addition, it is wasteful to set up Amazon EventBridge rule on all AWS Config managed rules, rather than only the restricted-ssh rule. Therefore, both these options are incorrect.
Set up an Amazon EventBridge rule that matches an AWS Config evaluation result of ERROR for the restricted-ssh rule. Create an input transformer for the EventBridge rule. Set up the EventBridge rule to publish a notification to the SNS topic - You get an ERROR evaluation result when one of the required/optional parameters is not valid, or not of the correct type, or is formatted incorrectly. This option has been added as a distractor.
References:
https://docs.aws.amazon.com/config/latest/developerguide/evaluate-config.html
https://docs.aws.amazon.com/config/latest/developerguide/restricted-ssh.html
https://docs.aws.amazon.com/sns/latest/dg/sns-message-filtering.html
Explanation
Correct option:
Set up an Amazon EventBridge rule that matches an AWS Config evaluation result of NON_COMPLIANT for the restricted-ssh rule. Create an input transformer for the EventBridge rule. Set up the EventBridge rule to publish a notification to the SNS topic
You can use AWS Config to evaluate the configuration settings of your AWS resources. You do this by creating AWS Config rules, which represent your ideal configuration settings. AWS Config provides customizable, predefined rules called managed rules to help you get started. While AWS Config continuously tracks the configuration changes that occur among your resources, it checks whether these changes do not comply with the conditions in your rules.
The restricted-ssh rule checks if the incoming SSH traffic for the security groups is accessible. The rule is COMPLIANT when IP addresses of the incoming SSH traffic in the security groups are restricted (CIDR other than 0.0.0.0/0). This rule applies only to IPv4.
For the given use case, you need to monitor for the NON_COMPLIANT evaluation result of the rule, which implies that the rule has failed the conditions of the compliance check. You can then create an Amazon EventBridge rule (with AWS Config configured as a source) that is put in action when it matches the NON_COMPLIANT evaluation result of the restricted-ssh rule. The EventBridge rule, in turn, publishes a notification to the SNS topic.
via - https://docs.aws.amazon.com/config/latest/developerguide/evaluate-config.html
Incorrect options:
Set up an Amazon EventBridge rule that matches an AWS Config evaluation result of NON_COMPLIANT for all AWS Config managed rules. Create an input transformer for the EventBridge rule. Set up the EventBridge rule to publish a notification to the SNS topic. Set up a filter policy on the SNS topic to send only notifications that contain the text of NON_COMPLIANT in the notification to subscribers
Set up an Amazon EventBridge rule that matches all AWS Config evaluation results for the restricted-ssh rule. Create an input transformer for the EventBridge rule. Set up the EventBridge rule to publish a notification to the SNS topic. Set up a filter policy on the SNS topic to send only notifications that contain the text of NON_COMPLIANT in the notification to subscribers
You should note that you can only set up a filter policy on an SNS subscription and NOT on the SNS topic itself. In addition, it is wasteful to set up Amazon EventBridge rule on all AWS Config managed rules, rather than only the restricted-ssh rule. Therefore, both these options are incorrect.
Set up an Amazon EventBridge rule that matches an AWS Config evaluation result of ERROR for the restricted-ssh rule. Create an input transformer for the EventBridge rule. Set up the EventBridge rule to publish a notification to the SNS topic - You get an ERROR evaluation result when one of the required/optional parameters is not valid, or not of the correct type, or is formatted incorrectly. This option has been added as a distractor.
References:
https://docs.aws.amazon.com/config/latest/developerguide/evaluate-config.html
https://docs.aws.amazon.com/config/latest/developerguide/restricted-ssh.html
https://docs.aws.amazon.com/sns/latest/dg/sns-message-filtering.html
Question 12 Single Choice
A support team wants to be notified via an Amazon Simple Notification Service (Amazon SNS) notification when an AWS Glue job fails a retry.
As a DevOps Engineer, how will you implement this requirement?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Configure Amazon EventBridge events for AWS Glue. Define the AWS Lambda function as a target to the EventBridge. The Lambda function will have the logic to process the events and filter the AWS Glue job retry failure event. Publish a message to Amazon Simple Notification Service (Amazon SNS) notification if such an event is found
Amazon EventBridge events for AWS Glue can be used to create Amazon SNS alerts, but the alerts might not be specific enough for certain situations. To receive SNS notifications for certain AWS Glue Events, such as an AWS Glue job failing on retry, you can use AWS Lambda. You can create a Lambda function to do the following:
- Check the incoming event for a specific string.
- Publish a message to Amazon SNS if the string in the event matches the string in the Lambda function.
To use an AWS Lambda function to receive an email from SNS when any of your AWS Glue jobs fail a retry, do the following: 1. Create an Amazon SNS topic. 2. Create an AWS Lambda function. 3. Create an Amazon EventBridge event that uses the Lambda function to initiate email notifications.
AWS Lambda function logic: 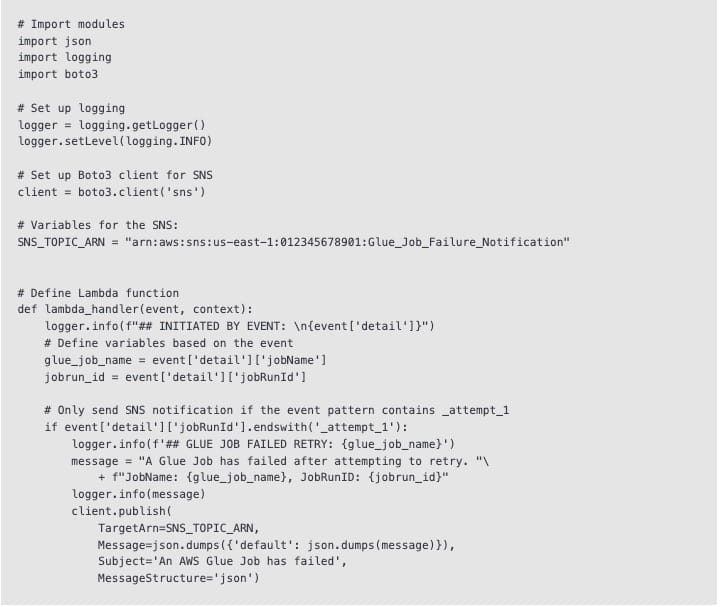 via - https://repost.aws/knowledge-center/glue-job-fail-retry-lambda-sns-alerts
via - https://repost.aws/knowledge-center/glue-job-fail-retry-lambda-sns-alerts
Incorrect options:
Configure Amazon EventBridge events for AWS Glue. Configure an Amazon Simple Notification Service (Amazon SNS) notification when the Glue job fails a retry - Amazon EventBridge cannot be directly used without a Lambda function since the use case needs notifications only for Glue job retry failure. So this logic has to be included in a Lambda function.
Amazon Simple Notification Service (Amazon SNS) cannot retry failures, leverage Amazon Simple Queue Service (Amazon SQS) dead-letter queues to retry the failed Glue jobs - The use case is not about retrying the Glue job, but about sending an SNS notification when the retry of the job fails.
Check the AWS Personal Health Dashboard for failed AWS Glue jobs. Schedule an AWS Lambda function to pick the failed event from the service health dashboard and trigger an Amazon Simple Notification Service (Amazon SNS) notification when a retry fails - AWS Personal Health Dashboard provides proactive notifications of scheduled activities, such as any changes to the infrastructure powering your resources, enabling you to better plan for events that may affect you. This option is not relevant to the given requirements.
Reference:
https://repost.aws/knowledge-center/glue-job-fail-retry-lambda-sns-alerts
Explanation
Correct option:
Configure Amazon EventBridge events for AWS Glue. Define the AWS Lambda function as a target to the EventBridge. The Lambda function will have the logic to process the events and filter the AWS Glue job retry failure event. Publish a message to Amazon Simple Notification Service (Amazon SNS) notification if such an event is found
Amazon EventBridge events for AWS Glue can be used to create Amazon SNS alerts, but the alerts might not be specific enough for certain situations. To receive SNS notifications for certain AWS Glue Events, such as an AWS Glue job failing on retry, you can use AWS Lambda. You can create a Lambda function to do the following:
- Check the incoming event for a specific string.
- Publish a message to Amazon SNS if the string in the event matches the string in the Lambda function.
To use an AWS Lambda function to receive an email from SNS when any of your AWS Glue jobs fail a retry, do the following: 1. Create an Amazon SNS topic. 2. Create an AWS Lambda function. 3. Create an Amazon EventBridge event that uses the Lambda function to initiate email notifications.
AWS Lambda function logic: via - https://repost.aws/knowledge-center/glue-job-fail-retry-lambda-sns-alerts
Incorrect options:
Configure Amazon EventBridge events for AWS Glue. Configure an Amazon Simple Notification Service (Amazon SNS) notification when the Glue job fails a retry - Amazon EventBridge cannot be directly used without a Lambda function since the use case needs notifications only for Glue job retry failure. So this logic has to be included in a Lambda function.
Amazon Simple Notification Service (Amazon SNS) cannot retry failures, leverage Amazon Simple Queue Service (Amazon SQS) dead-letter queues to retry the failed Glue jobs - The use case is not about retrying the Glue job, but about sending an SNS notification when the retry of the job fails.
Check the AWS Personal Health Dashboard for failed AWS Glue jobs. Schedule an AWS Lambda function to pick the failed event from the service health dashboard and trigger an Amazon Simple Notification Service (Amazon SNS) notification when a retry fails - AWS Personal Health Dashboard provides proactive notifications of scheduled activities, such as any changes to the infrastructure powering your resources, enabling you to better plan for events that may affect you. This option is not relevant to the given requirements.
Reference:
https://repost.aws/knowledge-center/glue-job-fail-retry-lambda-sns-alerts
Question 13 Single Choice
A DevOps Engineer has been asked to chalk out a disaster recovery (DR) plan for a workload in production. The workload runs on Amazon EC2 instances behind an Application Load Balancer (ALB). The EC2 instances are configured with an Auto Scaling group across multiple Availability Zones. Amazon Route 53 is configured to point to the ALB using an alias record. Amazon RDS for PostgreSQL DB instance is the database service. The draft DR plan mandates an RTO of three hours and an RPO of around 15 minutes.
Which Disaster Recovery (DR) strategy should the DevOps Engineer opt for a cost-effective solution?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Opt for a pilot light DR strategy. Provision a copy of your core workload infrastructure to a different AWS Region. Create an RDS read replica in the new Region, and configure the new environment to point to the local RDS PostgreSQL DB instance. Configure Amazon Route 53 health checks to automatically initiate DNS failover to a new Region. Promote the read replica to the primary DB instance in case of a disaster
With the pilot light approach, you replicate your data from one Region to another and provision a copy of your core workload infrastructure. Resources required to support data replication and backup, such as databases and object storage, are always on. Other elements, such as application servers, are loaded with application code and configurations, but are "switched off" and are only used during testing or when disaster recovery failover is invoked. In the cloud, you have the flexibility to de-provision resources when you do not need them, and provision them when you do. A best practice for “switched off” is to not deploy the resource, and then create the configuration and capabilities to deploy it (“switch on”) when needed. Unlike the backup and restore approach, your core infrastructure is always available and you always have the option to quickly provision a full-scale production environment by switching on and scaling out your application servers.
A pilot light approach minimizes the ongoing cost of disaster recovery by minimizing the active resources and simplifies recovery at the time of a disaster because the core infrastructure requirements are all in place.
For pilot light, continuous data replication to live databases and data stores in the DR region is the best approach for low RPO. When failing over to run your read/write workload from the disaster recovery Region, you must promote an RDS read replica to become the primary instance.
For an active/passive configuration such as the pilot light, all traffic initially goes to the primary Region and switches to the disaster recovery Region if the primary Region is no longer available. This failover operation can be initiated either automatically or manually.
Using Amazon Route 53, you can associate multiple IP endpoints in one or more AWS Regions with a Route 53 domain name. Then, you can route traffic to the appropriate endpoint under that domain name. On failover you need to switch traffic to the recovery endpoint, and away from the primary endpoint. Amazon Route 53 health checks monitor these endpoints. Using these health checks, you can configure automatically initiated DNS failover to ensure traffic is sent only to healthy endpoints, which is a highly reliable operation done on the data plane.
The pilot light strategy is the one best suited for the given requirements since it keeps the overall costs down when compared to the rest of the options. Also, the core infrastructure is ready to be used as and when required. Since RTO is given in hours, we can spin up these resources well before the given time. The database is update-to-date and only needs a switch from replica to primary. This is the right strategy when RPO is in minutes.
Pilot light DR strategy: 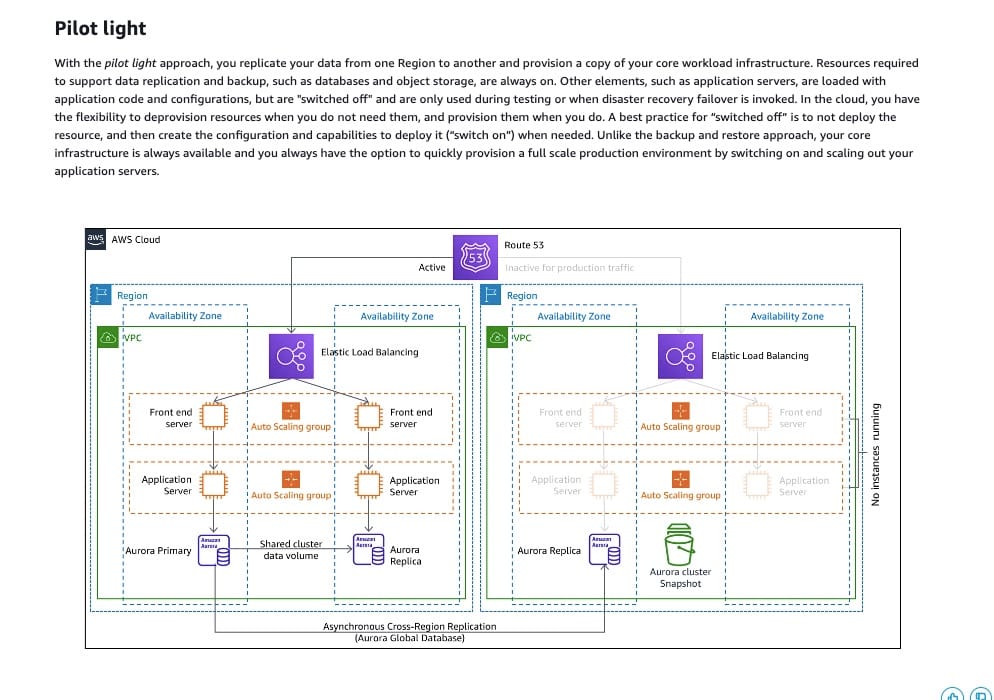 via - https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-options-in-the-cloud.html
via - https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-options-in-the-cloud.html
Incorrect options:
Opt for a pilot light DR strategy. Provision a copy of your entire workload infrastructure to a different AWS Region. Copy the first backup that consists of a full instance backup to the new RDS instance. In case of disaster, apply the incremental backup to the RDS instance in the new AWS Region. Configure Amazon Route 53 health checks to automatically initiate DNS failover to new Region - With pilot light DR strategy, resources required to support data replication and backup, such as databases and object storage, are always on. When the expected RPO is 15 minutes, it is not possible to apply incremental backups to the database since this could be huge amounts of data which may take hours. Hence, this option is incorrect.
Configure your workload to simultaneously run in multiple AWS Regions as part of a multi-site active/active DR strategy. Replicate your entire workload to another AWS Region. With this strategy, asynchronous data replication between the regions enables near-zero RPO. Configure Amazon Route 53 with latency-based routing to choose between the active regional endpoint for directing user traffic - You can run your workload simultaneously in multiple Regions as part of a multi-site active/active strategy. Multi-site active/active serves traffic from all regions to which it is deployed. With a multi-site active/active approach, users can access your workload in any of the Regions in which it is deployed. This approach is the most complex and costly approach to disaster recovery, but it can reduce your recovery time to near zero for most disasters with the correct technology choices and implementation. Since RTO is given as three hours, opting for this DR strategy will prove to be cost-ineffective.
Opt for a Warm standby approach by ensuring that there is a scaled-down, but fully functional, copy of your production environment in another AWS Region. Then, deploy enough resources to handle initial traffic, ensuring low RTO, and then rely on Auto Scaling to ramp up for subsequent traffic - The warm standby approach involves ensuring that there is a scaled-down, but fully functional, copy of your production environment in another Region. This approach extends the pilot light concept and decreases the time to recovery because your workload is always-on in another Region. Since RTO is given as three hours, the warm standby approach will end up being a costly alternative to an otherwise cost-effective pilot light strategy.
References:
https://aws.amazon.com/blogs/mt/establishing-rpo-and-rto-targets-for-cloud-applications/
https://aws.amazon.com/blogs/database/implementing-a-disaster-recovery-strategy-with-amazon-rds/
Explanation
Correct option:
Opt for a pilot light DR strategy. Provision a copy of your core workload infrastructure to a different AWS Region. Create an RDS read replica in the new Region, and configure the new environment to point to the local RDS PostgreSQL DB instance. Configure Amazon Route 53 health checks to automatically initiate DNS failover to a new Region. Promote the read replica to the primary DB instance in case of a disaster
With the pilot light approach, you replicate your data from one Region to another and provision a copy of your core workload infrastructure. Resources required to support data replication and backup, such as databases and object storage, are always on. Other elements, such as application servers, are loaded with application code and configurations, but are "switched off" and are only used during testing or when disaster recovery failover is invoked. In the cloud, you have the flexibility to de-provision resources when you do not need them, and provision them when you do. A best practice for “switched off” is to not deploy the resource, and then create the configuration and capabilities to deploy it (“switch on”) when needed. Unlike the backup and restore approach, your core infrastructure is always available and you always have the option to quickly provision a full-scale production environment by switching on and scaling out your application servers.
A pilot light approach minimizes the ongoing cost of disaster recovery by minimizing the active resources and simplifies recovery at the time of a disaster because the core infrastructure requirements are all in place.
For pilot light, continuous data replication to live databases and data stores in the DR region is the best approach for low RPO. When failing over to run your read/write workload from the disaster recovery Region, you must promote an RDS read replica to become the primary instance.
For an active/passive configuration such as the pilot light, all traffic initially goes to the primary Region and switches to the disaster recovery Region if the primary Region is no longer available. This failover operation can be initiated either automatically or manually.
Using Amazon Route 53, you can associate multiple IP endpoints in one or more AWS Regions with a Route 53 domain name. Then, you can route traffic to the appropriate endpoint under that domain name. On failover you need to switch traffic to the recovery endpoint, and away from the primary endpoint. Amazon Route 53 health checks monitor these endpoints. Using these health checks, you can configure automatically initiated DNS failover to ensure traffic is sent only to healthy endpoints, which is a highly reliable operation done on the data plane.
The pilot light strategy is the one best suited for the given requirements since it keeps the overall costs down when compared to the rest of the options. Also, the core infrastructure is ready to be used as and when required. Since RTO is given in hours, we can spin up these resources well before the given time. The database is update-to-date and only needs a switch from replica to primary. This is the right strategy when RPO is in minutes.
Pilot light DR strategy: via - https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-options-in-the-cloud.html
Incorrect options:
Opt for a pilot light DR strategy. Provision a copy of your entire workload infrastructure to a different AWS Region. Copy the first backup that consists of a full instance backup to the new RDS instance. In case of disaster, apply the incremental backup to the RDS instance in the new AWS Region. Configure Amazon Route 53 health checks to automatically initiate DNS failover to new Region - With pilot light DR strategy, resources required to support data replication and backup, such as databases and object storage, are always on. When the expected RPO is 15 minutes, it is not possible to apply incremental backups to the database since this could be huge amounts of data which may take hours. Hence, this option is incorrect.
Configure your workload to simultaneously run in multiple AWS Regions as part of a multi-site active/active DR strategy. Replicate your entire workload to another AWS Region. With this strategy, asynchronous data replication between the regions enables near-zero RPO. Configure Amazon Route 53 with latency-based routing to choose between the active regional endpoint for directing user traffic - You can run your workload simultaneously in multiple Regions as part of a multi-site active/active strategy. Multi-site active/active serves traffic from all regions to which it is deployed. With a multi-site active/active approach, users can access your workload in any of the Regions in which it is deployed. This approach is the most complex and costly approach to disaster recovery, but it can reduce your recovery time to near zero for most disasters with the correct technology choices and implementation. Since RTO is given as three hours, opting for this DR strategy will prove to be cost-ineffective.
Opt for a Warm standby approach by ensuring that there is a scaled-down, but fully functional, copy of your production environment in another AWS Region. Then, deploy enough resources to handle initial traffic, ensuring low RTO, and then rely on Auto Scaling to ramp up for subsequent traffic - The warm standby approach involves ensuring that there is a scaled-down, but fully functional, copy of your production environment in another Region. This approach extends the pilot light concept and decreases the time to recovery because your workload is always-on in another Region. Since RTO is given as three hours, the warm standby approach will end up being a costly alternative to an otherwise cost-effective pilot light strategy.
References:
https://aws.amazon.com/blogs/mt/establishing-rpo-and-rto-targets-for-cloud-applications/
https://aws.amazon.com/blogs/database/implementing-a-disaster-recovery-strategy-with-amazon-rds/
Question 14 Single Choice
A multi-national company with hundreds of AWS accounts has slowly adopted AWS Organizations with all features enabled. The company has also configured a few Organization Units (OUs) to serve its business objectives. The company has some AWS Identity and Access Management (IAM) roles that need to be configured for every new AWS account created for the company. Also, the security policy mandates enabling AWS CloudTrail for all AWS accounts. The company is looking for an automated solution that can add the mandatory IAM Roles and CloudTrail configurations to all newly created accounts and also delete the resources/configurations when an account leaves the organization without manual intervention.
What should a DevOps engineer do to meet these requirements with the minimal overhead?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
From the management account of AWS Organizations, create an AWS CloudFormation stack set to enable AWS Config and deploy your centralized AWS Identity and Access Management (IAM) roles. Configure the stack set to deploy automatically when an account is created through AWS Organizations
You can centrally orchestrate any AWS CloudFormation enabled service across multiple AWS accounts and regions. For example, you can deploy your centralized AWS Identity and Access Management (IAM) roles, provision Amazon Elastic Compute Cloud (Amazon EC2) instances or AWS Lambda functions across AWS Regions and accounts in your organization. CloudFormation StackSets simplify the configuration of cross-account permissions and allow for the automatic creation and deletion of resources when accounts are joined or removed from your Organization.
You can get started by enabling data sharing between CloudFormation and Organizations from the StackSets console. Once done, you will be able to use StackSets in the AWS Organizations master account to deploy stacks to all accounts in your organization or specific organizational units (OUs). A new service-managed permission model is available with these StackSets. Choosing Service managed permissions allows StackSets to automatically configure the necessary IAM permissions required to deploy your stack to the accounts in your organization.
In addition to setting permissions, CloudFormation StackSets offer the option for automatically creating or removing your CloudFormation stacks when a new AWS account joins or quits your Organization. You do not need to remember to manually connect to the new account to deploy your common infrastructure or to delete infrastructure when an account is removed from your Organization. When an account leaves the organization, the stack will be removed from the management of StackSets. However, you can choose to either delete or retain the resources managed by the stack.
Lastly, you choose whether to deploy a stack to your entire organization or just to one or more Organization Units (OU). You also choose a couple of deployment options: how many accounts will be prepared in parallel, and how many failures you tolerate before stopping the entire deployment.
Use AWS CloudFormation StackSets for Multiple Accounts in an AWS Organization: 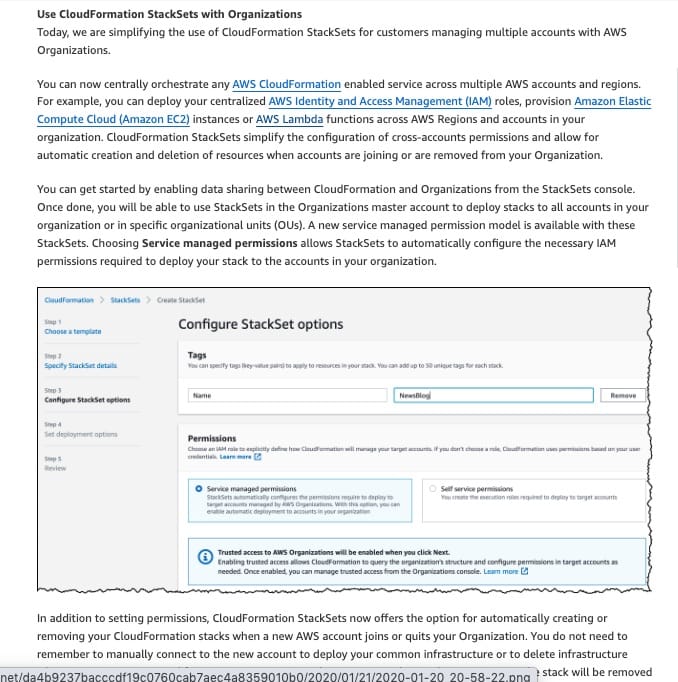 via - https://aws.amazon.com/blogs/aws/new-use-aws-cloudformation-stacksets-for-multiple-accounts-in-an-aws-organization/
via - https://aws.amazon.com/blogs/aws/new-use-aws-cloudformation-stacksets-for-multiple-accounts-in-an-aws-organization/
Incorrect options:
From the management account of AWS Organizations, create an Amazon EventBridge rule that is triggered by an AWS account creation API call. Configure an AWS Lambda function to enable CloudTrail logging and to attach the necessary IAM roles to the account - This option involves using too many services which unnecessarily adds to the complexity and cost of the overall solution. So, this option is incorrect.
Run automation across multiple accounts using AWS System Manager Automation. Create an AWS resource group from the management account (or any centralized account) and name it exactly the same for all accounts and OUs and add the account ID or OU as a prefix as per standard naming convention. Include the CloudTrail configuration and the IAM role to be created - While you can use AWS Systems Manager to automate tasks across multiple accounts in AWS Organization, the other details in this option are irrelevant to the given use case.
When you run automation across multiple Regions and accounts, you target resources by using tags or the name of an AWS resource group. The resource group must exist in each target account and Region. The resource group name must be the same in each target account and Region. The automation fails to run on those resources that don't have the specified tag or that aren't included in the specified resource group.
From the management account of AWS Organizations, enable AWS CloudTrail logs for all member accounts. Similarly, create an IAM role and share it across accounts and OUs of the AWS Organization - It is possible to enable CloudTrail logging from the management account of AWS Organizations, and is referred to as the organization trail. The use case is to be able to log all Trail events to a commonplace. Also, creating an IAM role in the management account and sharing it across all member accounts is not straightforward and requires manual work. Hence, this option is incorrect for the given use case.
IAM policies usage in AWS Organizations:  via - https://docs.aws.amazon.com/organizations/latest/userguide/orgs_permissions_overview.html
via - https://docs.aws.amazon.com/organizations/latest/userguide/orgs_permissions_overview.html
References:
https://docs.aws.amazon.com/awscloudtrail/latest/userguide/creating-trail-organization.html
Explanation
Correct option:
From the management account of AWS Organizations, create an AWS CloudFormation stack set to enable AWS Config and deploy your centralized AWS Identity and Access Management (IAM) roles. Configure the stack set to deploy automatically when an account is created through AWS Organizations
You can centrally orchestrate any AWS CloudFormation enabled service across multiple AWS accounts and regions. For example, you can deploy your centralized AWS Identity and Access Management (IAM) roles, provision Amazon Elastic Compute Cloud (Amazon EC2) instances or AWS Lambda functions across AWS Regions and accounts in your organization. CloudFormation StackSets simplify the configuration of cross-account permissions and allow for the automatic creation and deletion of resources when accounts are joined or removed from your Organization.
You can get started by enabling data sharing between CloudFormation and Organizations from the StackSets console. Once done, you will be able to use StackSets in the AWS Organizations master account to deploy stacks to all accounts in your organization or specific organizational units (OUs). A new service-managed permission model is available with these StackSets. Choosing Service managed permissions allows StackSets to automatically configure the necessary IAM permissions required to deploy your stack to the accounts in your organization.
In addition to setting permissions, CloudFormation StackSets offer the option for automatically creating or removing your CloudFormation stacks when a new AWS account joins or quits your Organization. You do not need to remember to manually connect to the new account to deploy your common infrastructure or to delete infrastructure when an account is removed from your Organization. When an account leaves the organization, the stack will be removed from the management of StackSets. However, you can choose to either delete or retain the resources managed by the stack.
Lastly, you choose whether to deploy a stack to your entire organization or just to one or more Organization Units (OU). You also choose a couple of deployment options: how many accounts will be prepared in parallel, and how many failures you tolerate before stopping the entire deployment.
Use AWS CloudFormation StackSets for Multiple Accounts in an AWS Organization: via - https://aws.amazon.com/blogs/aws/new-use-aws-cloudformation-stacksets-for-multiple-accounts-in-an-aws-organization/
Incorrect options:
From the management account of AWS Organizations, create an Amazon EventBridge rule that is triggered by an AWS account creation API call. Configure an AWS Lambda function to enable CloudTrail logging and to attach the necessary IAM roles to the account - This option involves using too many services which unnecessarily adds to the complexity and cost of the overall solution. So, this option is incorrect.
Run automation across multiple accounts using AWS System Manager Automation. Create an AWS resource group from the management account (or any centralized account) and name it exactly the same for all accounts and OUs and add the account ID or OU as a prefix as per standard naming convention. Include the CloudTrail configuration and the IAM role to be created - While you can use AWS Systems Manager to automate tasks across multiple accounts in AWS Organization, the other details in this option are irrelevant to the given use case.
When you run automation across multiple Regions and accounts, you target resources by using tags or the name of an AWS resource group. The resource group must exist in each target account and Region. The resource group name must be the same in each target account and Region. The automation fails to run on those resources that don't have the specified tag or that aren't included in the specified resource group.
From the management account of AWS Organizations, enable AWS CloudTrail logs for all member accounts. Similarly, create an IAM role and share it across accounts and OUs of the AWS Organization - It is possible to enable CloudTrail logging from the management account of AWS Organizations, and is referred to as the organization trail. The use case is to be able to log all Trail events to a commonplace. Also, creating an IAM role in the management account and sharing it across all member accounts is not straightforward and requires manual work. Hence, this option is incorrect for the given use case.
IAM policies usage in AWS Organizations: via - https://docs.aws.amazon.com/organizations/latest/userguide/orgs_permissions_overview.html
References:
https://docs.aws.amazon.com/awscloudtrail/latest/userguide/creating-trail-organization.html
Question 15 Single Choice
An e-commerce company has a serverless application stack that consists of CloudFront, API Gateway and Lambda functions. The company has hired you to improve the current deployment process which creates a new version of the Lambda function and then runs an AWS CLI script for deployment. In case the new version errors out, then another CLI script is invoked to deploy the previous working version of the Lambda function. The company has mandated you to decrease the time to deploy new versions of the Lambda functions and also reduce the time to detect and roll back when errors are identified.
Which of the following solutions would you suggest for the given use case?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use Serverless Application Model (SAM) and leverage the built-in traffic-shifting feature of SAM to deploy the new Lambda version via CodeDeploy and use pre-traffic and post-traffic test functions to verify code. Rollback in case CloudWatch alarms are triggered
The AWS Serverless Application Model (SAM) is an open-source framework for building serverless applications. It provides shorthand syntax to express functions, APIs, databases, and event source mappings. You define the application you want with just a few lines per resource and model it using YAML. During deployment, SAM transforms and expands the SAM syntax into AWS CloudFormation syntax. Then, CloudFormation provisions your resources with reliable deployment capabilities.
To address the given use case, you can use the traffic shifting feature of SAM to easily test the new version of the Lambda function without having to manually move 100% of the traffic to the new version in one shot.
You can use CodeDeploy to create a deployment process that publishes the new Lambda version but does not send any traffic to it. Then it executes a PreTraffic test to ensure that your new function works as expected. After the test succeeds, CodeDeploy automatically shifts traffic gradually to the new version of the Lambda function. This workflow addresses one of the key requirements of reducing the time to detect errors. You can roll back to the previous version in case the new version errors out.
 via - https://aws.amazon.com/blogs/compute/implementing-safe-aws-lambda-deployments-with-aws-codedeploy/
via - https://aws.amazon.com/blogs/compute/implementing-safe-aws-lambda-deployments-with-aws-codedeploy/
Incorrect options:
Set up and deploy nested CloudFormation stacks with the CloudFront distribution as well as the API Gateway in the parent stack. Create and deploy a child stack containing the Lambda functions. To address any changes in a Lambda function, create a CloudFormation change set and deploy. In case the Lambda function errors out, rollback the CloudFormation change set to the previous version - You can use CloudFormation change sets to preview how proposed changes to a stack might impact your running resources, for example, whether your changes will delete or replace any critical resources, AWS CloudFormation makes the changes to your stack only when you decide to execute the change set, allowing you to decide whether to proceed with your proposed changes or explore other changes by creating another change set.
This option does not help in reducing the time to detect any potential deployment errors as you would not know about any potential failures until you actually deploy the stack.
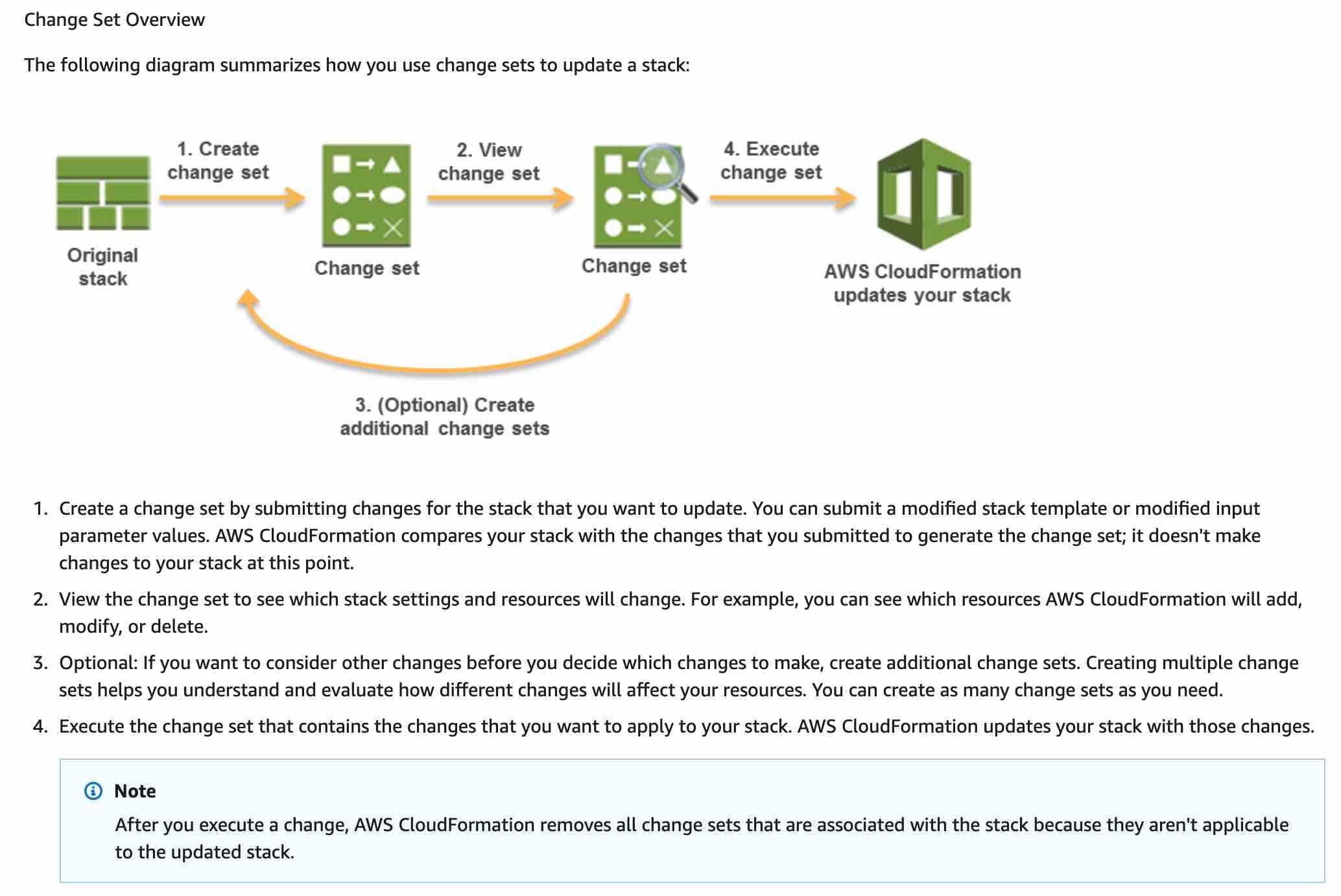 via -
via - Instead, you should use SAM to create your serverless application as it comes built-in with CodeDeploy to provide gradual Lambda deployments. Also, you can define pre-traffic and post-traffic test functions to verify that the newly deployed code is configured correctly and your application operates as expected. You can roll back the deployment if CloudWatch alarms are triggered.
Set up and deploy a CloudFormation stack containing a new API Gateway endpoint that points to the new Lambda version. Test the updated CloudFront origin that points to this new API Gateway endpoint and in case errors are detected then revert the CloudFront origin to the previous working API Gateway endpoint - This option does not help in reducing the time to detect any potential deployment errors as you would not know about any potential failures until you actually deploy the stack and point to the new endpoint.
Instead, you should use SAM to create your serverless application as it comes built-in with CodeDeploy to provide gradual Lambda deployments. Also, you can define pre-traffic and post-traffic test functions to verify that the newly deployed code is configured correctly and your application operates as expected. You can roll back the deployment if CloudWatch alarms are triggered.
Set up and deploy nested CloudFormation stacks with the CloudFront distribution as well as the API Gateway in the parent stack. Create and deploy a child stack containing the Lambda functions. To address any changes in a Lambda function, create a CloudFormation change set and deploy. Use pre-traffic and post-traffic test functions of the change set to verify the deployment. Rollback in case CloudWatch alarms are triggered - This option has been added as a distractor since CloudFormation change sets do not have pre-traffic and post-traffic test functions. Therefore this option is incorrect.
References:
https://aws.amazon.com/blogs/compute/implementing-safe-aws-lambda-deployments-with-aws-codedeploy/
Explanation
Correct option:
Use Serverless Application Model (SAM) and leverage the built-in traffic-shifting feature of SAM to deploy the new Lambda version via CodeDeploy and use pre-traffic and post-traffic test functions to verify code. Rollback in case CloudWatch alarms are triggered
The AWS Serverless Application Model (SAM) is an open-source framework for building serverless applications. It provides shorthand syntax to express functions, APIs, databases, and event source mappings. You define the application you want with just a few lines per resource and model it using YAML. During deployment, SAM transforms and expands the SAM syntax into AWS CloudFormation syntax. Then, CloudFormation provisions your resources with reliable deployment capabilities.
To address the given use case, you can use the traffic shifting feature of SAM to easily test the new version of the Lambda function without having to manually move 100% of the traffic to the new version in one shot.
You can use CodeDeploy to create a deployment process that publishes the new Lambda version but does not send any traffic to it. Then it executes a PreTraffic test to ensure that your new function works as expected. After the test succeeds, CodeDeploy automatically shifts traffic gradually to the new version of the Lambda function. This workflow addresses one of the key requirements of reducing the time to detect errors. You can roll back to the previous version in case the new version errors out.
via - https://aws.amazon.com/blogs/compute/implementing-safe-aws-lambda-deployments-with-aws-codedeploy/
Incorrect options:
Set up and deploy nested CloudFormation stacks with the CloudFront distribution as well as the API Gateway in the parent stack. Create and deploy a child stack containing the Lambda functions. To address any changes in a Lambda function, create a CloudFormation change set and deploy. In case the Lambda function errors out, rollback the CloudFormation change set to the previous version - You can use CloudFormation change sets to preview how proposed changes to a stack might impact your running resources, for example, whether your changes will delete or replace any critical resources, AWS CloudFormation makes the changes to your stack only when you decide to execute the change set, allowing you to decide whether to proceed with your proposed changes or explore other changes by creating another change set.
This option does not help in reducing the time to detect any potential deployment errors as you would not know about any potential failures until you actually deploy the stack.
Instead, you should use SAM to create your serverless application as it comes built-in with CodeDeploy to provide gradual Lambda deployments. Also, you can define pre-traffic and post-traffic test functions to verify that the newly deployed code is configured correctly and your application operates as expected. You can roll back the deployment if CloudWatch alarms are triggered.
Set up and deploy a CloudFormation stack containing a new API Gateway endpoint that points to the new Lambda version. Test the updated CloudFront origin that points to this new API Gateway endpoint and in case errors are detected then revert the CloudFront origin to the previous working API Gateway endpoint - This option does not help in reducing the time to detect any potential deployment errors as you would not know about any potential failures until you actually deploy the stack and point to the new endpoint.
Instead, you should use SAM to create your serverless application as it comes built-in with CodeDeploy to provide gradual Lambda deployments. Also, you can define pre-traffic and post-traffic test functions to verify that the newly deployed code is configured correctly and your application operates as expected. You can roll back the deployment if CloudWatch alarms are triggered.
Set up and deploy nested CloudFormation stacks with the CloudFront distribution as well as the API Gateway in the parent stack. Create and deploy a child stack containing the Lambda functions. To address any changes in a Lambda function, create a CloudFormation change set and deploy. Use pre-traffic and post-traffic test functions of the change set to verify the deployment. Rollback in case CloudWatch alarms are triggered - This option has been added as a distractor since CloudFormation change sets do not have pre-traffic and post-traffic test functions. Therefore this option is incorrect.
References:
https://aws.amazon.com/blogs/compute/implementing-safe-aws-lambda-deployments-with-aws-codedeploy/
Question 16 Multiple Choice
An application runs on a fleet of Amazon EC2 Windows instances configured with an Auto Scaling group (ASG). When scaling-in takes place in the ASG, the instances are terminated without notification. The application team wants to create an AMI and remove the Amazon EC2 Windows instance from its domain before terminating the scaled-in instances.
As a DevOps Engineer, which combination of steps will you choose to implement this requirement? (Select two)
Explanation
Click "Show Answer" to see the explanation here
Correct options:
Add a lifecycle hook that puts the instance in Terminating:Wait status and setup an Amazon CloudWatch event to monitor the Terminating:Wait status
Add an AWS Systems Manager automation document as a CloudWatch Event target. The automation document runs a Windows PowerShell script to remove the instance from the domain and create an AMI of the EC2 instance
Oftentimes, you may want to execute some code and actions before terminating an Amazon Elastic Compute Cloud (Amazon EC2) instance that is part of an Amazon EC2 Auto Scaling group.
One way to execute code and actions before terminating an instance is to create a lifecycle hook that puts the instance in Terminating:Wait status. This allows you to perform any desired actions before immediately terminating the instance within the Auto Scaling group. The Terminating:Wait status can be monitored by an Amazon CloudWatch event, which triggers an AWS Systems Manager automation document to perform the action you want.
Broadly, the steps needed for the above configuration: 1. Add a lifecycle hook. 2. Create a Systems Manager automation document. 3. Create AWS Identity and Access Management (IAM) policies and a role to delegate permissions to the Systems Manager automation document. 4. Create IAM policies and a role to delegate permissions to CloudWatch Events, which invokes the Systems Manager automation document. 5. Create a CloudWatch Events rule. 6. Add a Systems Manager automation document as a CloudWatch Event target.
Using Lifecycle hooks to run code before terminating an EC2 Auto Scaling instance:  via - https://aws.amazon.com/blogs/infrastructure-and-automation/run-code-before-terminating-an-ec2-auto-scaling-instance/
via - https://aws.amazon.com/blogs/infrastructure-and-automation/run-code-before-terminating-an-ec2-auto-scaling-instance/
Incorrect options:
Add a lifecycle hook that puts the instance in Terminating:Pending status and set up an Amazon CloudWatch event to monitor the Terminating:Pending status - Terminating:Pending is not a valid state. The following are the transitions between instance states in the Amazon EC2 Auto Scaling lifecycle.
Amazon EC2 Auto Scaling instance lifecycle: 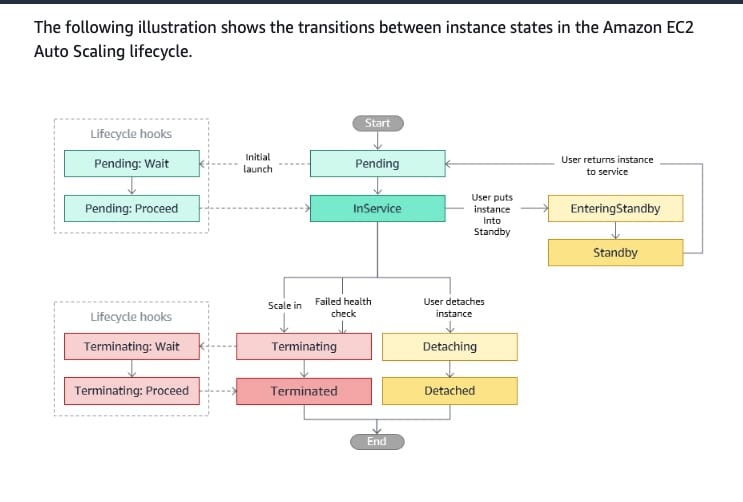 via - https://docs.aws.amazon.com/autoscaling/ec2/userguide/ec2-auto-scaling-lifecycle.html
via - https://docs.aws.amazon.com/autoscaling/ec2/userguide/ec2-auto-scaling-lifecycle.html
Add an AWS Systems Manager Patch Manager as a CloudWatch Event target. The automation document runs a Windows PowerShell script to remove the computer from the domain and creates an AMI of the EC2 instance - Patch Manager is a capability of AWS Systems Manager that automates the process of patching managed nodes with both security-related updates and other types of updates. It cannot be used for the processing of custom logic/code.
Configure an AWS Systems Manager Maintenance Window to schedule an action to run a Windows PowerShell script to remove the computer from the domain and creates an AMI of the EC2 instance - Maintenance Windows is a capability of AWS Systems Manager that helps you define a schedule for when to perform potentially disruptive actions on your nodes such as patching an operating system, updating drivers, or installing software or patches. Maintenance Windows is not relevant for the given use case, since we want the custom logic to run immediately and return to the instance termination triggered by Auto Scaling Group.
References:
https://docs.aws.amazon.com/autoscaling/ec2/userguide/ec2-auto-scaling-lifecycle.html
https://docs.aws.amazon.com/systems-manager/latest/userguide/systems-manager-maintenance.html
Explanation
Correct options:
Add a lifecycle hook that puts the instance in Terminating:Wait status and setup an Amazon CloudWatch event to monitor the Terminating:Wait status
Add an AWS Systems Manager automation document as a CloudWatch Event target. The automation document runs a Windows PowerShell script to remove the instance from the domain and create an AMI of the EC2 instance
Oftentimes, you may want to execute some code and actions before terminating an Amazon Elastic Compute Cloud (Amazon EC2) instance that is part of an Amazon EC2 Auto Scaling group.
One way to execute code and actions before terminating an instance is to create a lifecycle hook that puts the instance in Terminating:Wait status. This allows you to perform any desired actions before immediately terminating the instance within the Auto Scaling group. The Terminating:Wait status can be monitored by an Amazon CloudWatch event, which triggers an AWS Systems Manager automation document to perform the action you want.
Broadly, the steps needed for the above configuration: 1. Add a lifecycle hook. 2. Create a Systems Manager automation document. 3. Create AWS Identity and Access Management (IAM) policies and a role to delegate permissions to the Systems Manager automation document. 4. Create IAM policies and a role to delegate permissions to CloudWatch Events, which invokes the Systems Manager automation document. 5. Create a CloudWatch Events rule. 6. Add a Systems Manager automation document as a CloudWatch Event target.
Using Lifecycle hooks to run code before terminating an EC2 Auto Scaling instance: via - https://aws.amazon.com/blogs/infrastructure-and-automation/run-code-before-terminating-an-ec2-auto-scaling-instance/
Incorrect options:
Add a lifecycle hook that puts the instance in Terminating:Pending status and set up an Amazon CloudWatch event to monitor the Terminating:Pending status - Terminating:Pending is not a valid state. The following are the transitions between instance states in the Amazon EC2 Auto Scaling lifecycle.
Amazon EC2 Auto Scaling instance lifecycle: via - https://docs.aws.amazon.com/autoscaling/ec2/userguide/ec2-auto-scaling-lifecycle.html
Add an AWS Systems Manager Patch Manager as a CloudWatch Event target. The automation document runs a Windows PowerShell script to remove the computer from the domain and creates an AMI of the EC2 instance - Patch Manager is a capability of AWS Systems Manager that automates the process of patching managed nodes with both security-related updates and other types of updates. It cannot be used for the processing of custom logic/code.
Configure an AWS Systems Manager Maintenance Window to schedule an action to run a Windows PowerShell script to remove the computer from the domain and creates an AMI of the EC2 instance - Maintenance Windows is a capability of AWS Systems Manager that helps you define a schedule for when to perform potentially disruptive actions on your nodes such as patching an operating system, updating drivers, or installing software or patches. Maintenance Windows is not relevant for the given use case, since we want the custom logic to run immediately and return to the instance termination triggered by Auto Scaling Group.
References:
https://docs.aws.amazon.com/autoscaling/ec2/userguide/ec2-auto-scaling-lifecycle.html
https://docs.aws.amazon.com/systems-manager/latest/userguide/systems-manager-maintenance.html
Question 17 Single Choice
The flagship application at a company is deployed on Amazon EC2 instances running behind an Application Load Balancer (ALB) within an Auto Scaling group. A DevOps Engineer wants to configure a Blue/Green deployment for this application and has already created launch templates and Auto Scaling groups for both blue and green environments, each deploying to their respective target groups. The ALB can direct traffic to either environment's target group, and an Amazon Route 53 record points to the ALB. The goal is to enable an all-at-once transition of traffic from the software running on the blue environment's EC2 instances to the newly deployed software on the green environment's EC2 instances.
What steps should the DevOps Engineer take to fulfill these requirements?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Initiate a rolling restart of the Auto Scaling group for the green environment to deploy the new software on the green environment's EC2 instances. Once the rolling restart is complete, leverage an AWS CLI command to update the ALB and direct traffic to the green environment's target group
A Blue/Green deployment is a deployment strategy in which you create two separate, but identical environments. One environment (blue) is running the current application version and one environment (green) is running the new application version. Using a Blue/Green deployment strategy increases application availability and reduces deployment risk by simplifying the rollback process if a deployment fails. Once testing has been completed on the green environment, live application traffic is directed to the green environment and the blue environment is deprecated.
Several AWS deployment services support Blue/Green deployment strategies including Elastic Beanstalk, OpsWorks, CloudFormation, CodeDeploy, and Amazon ECS.
For the given use case, the blue group carries the production load while the green group is staged and deployed with the new code. When it’s time to deploy, you simply attach the green group to the existing load balancer to introduce traffic to the new environment. As you scale up the green Auto Scaling group, you can take the blue Auto Scaling group instances out of service by either terminating them or putting them in a Standby state.
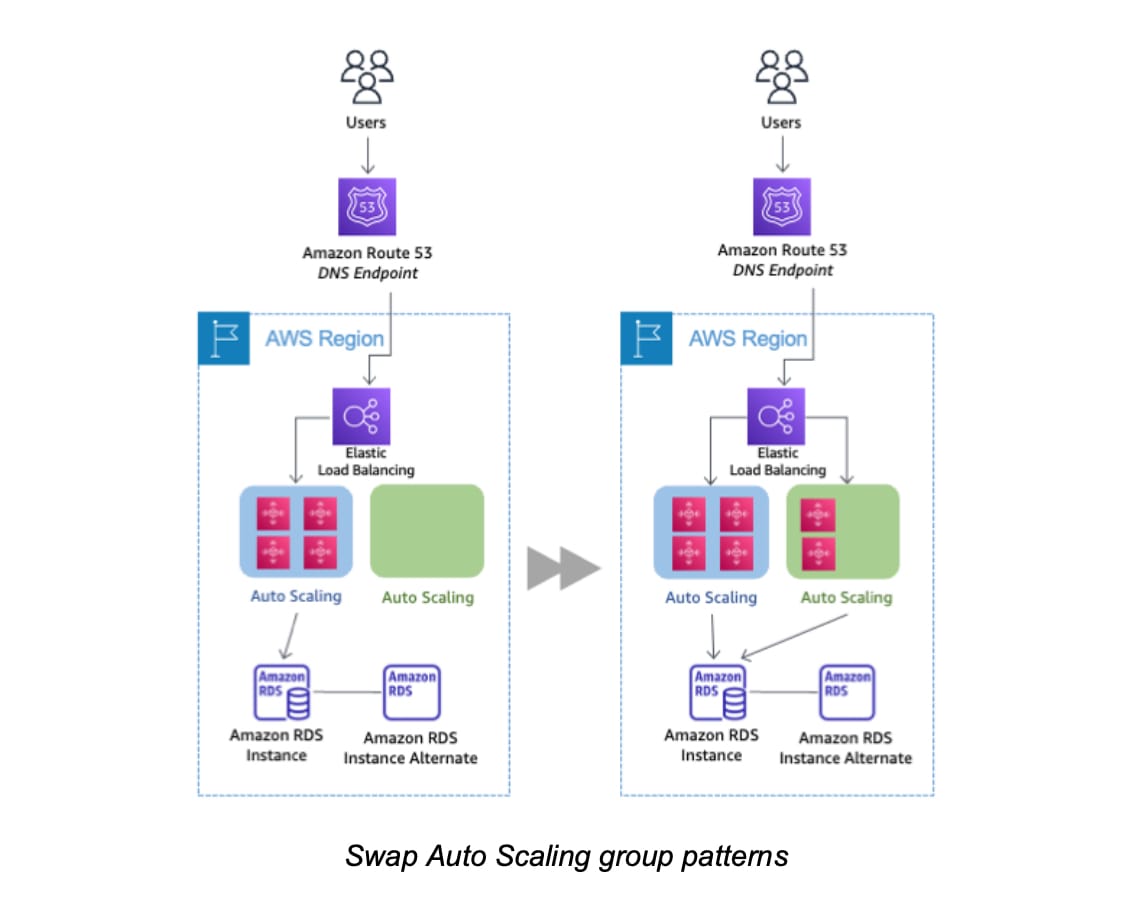 via - https://d1.awsstatic.com/whitepapers/AWS_Blue_Green_Deployments.pdf
via - https://d1.awsstatic.com/whitepapers/AWS_Blue_Green_Deployments.pdf
Incorrect options:
Set up an all-at-once deployment to the blue environment's EC2 instances. Perform a Route 53 DNS swap to the green environment's endpoint on the ALB
Initiate a rolling restart of the Auto Scaling group for the green environment to deploy the new software on the green environment's EC2 instances. Perform a Route 53 DNS swap to the green environment's endpoint on the ALB
Both these options have been added as distractors. Since there is only a single ALB per the given use case, so there is no alternate endpoint available for a Route 53 DNS update.
Leverage an AWS CLI command to update the ALB and direct traffic to the green environment's target group. Then initiate a rolling restart of the Auto Scaling group for the green environment to deploy the new software on the green environment's EC2 instances - The order of execution for this option is incorrect as it points the ALB to the green environment's target group before deploying the new software on the green environment's EC2 instances.
References:
https://d1.awsstatic.com/whitepapers/AWS_Blue_Green_Deployments.pdf
https://docs.aws.amazon.com/codedeploy/latest/userguide/deployments.html
Explanation
Correct option:
Initiate a rolling restart of the Auto Scaling group for the green environment to deploy the new software on the green environment's EC2 instances. Once the rolling restart is complete, leverage an AWS CLI command to update the ALB and direct traffic to the green environment's target group
A Blue/Green deployment is a deployment strategy in which you create two separate, but identical environments. One environment (blue) is running the current application version and one environment (green) is running the new application version. Using a Blue/Green deployment strategy increases application availability and reduces deployment risk by simplifying the rollback process if a deployment fails. Once testing has been completed on the green environment, live application traffic is directed to the green environment and the blue environment is deprecated.
Several AWS deployment services support Blue/Green deployment strategies including Elastic Beanstalk, OpsWorks, CloudFormation, CodeDeploy, and Amazon ECS.
For the given use case, the blue group carries the production load while the green group is staged and deployed with the new code. When it’s time to deploy, you simply attach the green group to the existing load balancer to introduce traffic to the new environment. As you scale up the green Auto Scaling group, you can take the blue Auto Scaling group instances out of service by either terminating them or putting them in a Standby state.
via - https://d1.awsstatic.com/whitepapers/AWS_Blue_Green_Deployments.pdf
Incorrect options:
Set up an all-at-once deployment to the blue environment's EC2 instances. Perform a Route 53 DNS swap to the green environment's endpoint on the ALB
Initiate a rolling restart of the Auto Scaling group for the green environment to deploy the new software on the green environment's EC2 instances. Perform a Route 53 DNS swap to the green environment's endpoint on the ALB
Both these options have been added as distractors. Since there is only a single ALB per the given use case, so there is no alternate endpoint available for a Route 53 DNS update.
Leverage an AWS CLI command to update the ALB and direct traffic to the green environment's target group. Then initiate a rolling restart of the Auto Scaling group for the green environment to deploy the new software on the green environment's EC2 instances - The order of execution for this option is incorrect as it points the ALB to the green environment's target group before deploying the new software on the green environment's EC2 instances.
References:
https://d1.awsstatic.com/whitepapers/AWS_Blue_Green_Deployments.pdf
https://docs.aws.amazon.com/codedeploy/latest/userguide/deployments.html
Question 18 Single Choice
A developer has uploaded an object of size 100 MB to an Amazon S3 bucket as a single-part direct upload using the REST API that has checksum enabled. The checksum of the object uploaded via the REST API was the checksum of the entire object. Later that day, the developer used the AWS Management Console to rename the object, copy it and edit its metadata. Later, when the developer checked for the checksum of the object updated via the AWS Management Console, the checksum was not the checksum of the entire object. Confused by the behavior, the developer has reached out to you for a possible solution.
As an AWS Certified DevOps Engineer - Professional, which of the following options would you identify as the reason for this behavior?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
A new checksum value for the object that is calculated based on the checksum values of the individual parts has been created. This behavior is expected
When you perform some operations using the AWS Management Console, Amazon S3 uses a multipart upload if the object is greater than 16 MB in size. In this case, the checksum is not a direct checksum of the full object, but rather a calculation based on the checksum values of each individual part.
For example, consider an object 100 MB in size that you uploaded as a single-part direct upload using the REST API. The checksum in this case is a checksum of the entire object. If you later use the console to rename that object, copy it, change the storage class, or edit the metadata, Amazon S3 uses the multipart upload functionality to update the object. As a result, Amazon S3 creates a new checksum value for the object that is calculated based on the checksum values of the individual parts.
Incorrect options:
If an object is greater than 50 MB in size, checksum will be a calculation based on the checksum values of each individual parts. The developer's initial calculation for the REST API based checksum was incorrect. This resulted in the mismatch of the two checksum values - This option is incorrect. When you perform some operations using the AWS Management Console, Amazon S3 uses a multipart upload if the object is greater than 16 MB (NOT 50 MB) in size.
When you change metadata of an object in S3, the checksum algorithm of the objects changes by default. This is an expected behavior - The checksum algorithm does not change when you change the metadata of the S3 object, so this option is incorrect.
If an object is greater than 16 MB in size, checksum will be a calculation based on the checksum values of each individual parts. The developer's initial calculation for the REST API based checksum was incorrect. This resulted in the mismatch of the two checksum values - This option is incorrect. When you perform some operations using the AWS Management Console, Amazon S3 uses a multipart upload if the object is greater than 16 MB in size. In this case, the checksum is not a direct checksum of the full object, but rather a calculation based on the checksum values of each individual part. On the other hand, when you upload an object as a single-part direct upload using the REST API, the checksum in this case is a checksum of the entire object. So you can say that the developer's initial calculation for the REST API based checksum was indeed correct.
Reference:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/checking-object-integrity.html
Explanation
Correct option:
A new checksum value for the object that is calculated based on the checksum values of the individual parts has been created. This behavior is expected
When you perform some operations using the AWS Management Console, Amazon S3 uses a multipart upload if the object is greater than 16 MB in size. In this case, the checksum is not a direct checksum of the full object, but rather a calculation based on the checksum values of each individual part.
For example, consider an object 100 MB in size that you uploaded as a single-part direct upload using the REST API. The checksum in this case is a checksum of the entire object. If you later use the console to rename that object, copy it, change the storage class, or edit the metadata, Amazon S3 uses the multipart upload functionality to update the object. As a result, Amazon S3 creates a new checksum value for the object that is calculated based on the checksum values of the individual parts.
Incorrect options:
If an object is greater than 50 MB in size, checksum will be a calculation based on the checksum values of each individual parts. The developer's initial calculation for the REST API based checksum was incorrect. This resulted in the mismatch of the two checksum values - This option is incorrect. When you perform some operations using the AWS Management Console, Amazon S3 uses a multipart upload if the object is greater than 16 MB (NOT 50 MB) in size.
When you change metadata of an object in S3, the checksum algorithm of the objects changes by default. This is an expected behavior - The checksum algorithm does not change when you change the metadata of the S3 object, so this option is incorrect.
If an object is greater than 16 MB in size, checksum will be a calculation based on the checksum values of each individual parts. The developer's initial calculation for the REST API based checksum was incorrect. This resulted in the mismatch of the two checksum values - This option is incorrect. When you perform some operations using the AWS Management Console, Amazon S3 uses a multipart upload if the object is greater than 16 MB in size. In this case, the checksum is not a direct checksum of the full object, but rather a calculation based on the checksum values of each individual part. On the other hand, when you upload an object as a single-part direct upload using the REST API, the checksum in this case is a checksum of the entire object. So you can say that the developer's initial calculation for the REST API based checksum was indeed correct.
Reference:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/checking-object-integrity.html
Question 19 Single Choice
A company uses multiple AWS accounts to help isolate and manage business applications. This multi-account environment consists of an AWS Transit Gateway to route all outbound traffic through a common network account. A firewall appliance inspects all traffic before it is forwarded to an internet gateway. The firewall appliance is configured to send logs to Amazon CloudWatch Logs for all events generated.
Recently, the security team has advised about probable illegal access of resources. As DevOps Engineer, you have been advised to configure an alert to the security team if the firewall appliance generates an event of Critical severity.
How should a DevOps engineer configure this requirement?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Create a metric filter on Amazon CloudWatch by filtering the log data to match the term Critical from log events. Publish a custom metric for the finding and configure a CloudWatch alarm on this custom metric to publish a notification to an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe the email address of the security team to the SNS topic
You can search and filter the log data coming into CloudWatch Logs by creating one or more metric filters. Metric filters define the terms and patterns to look for in log data as it is sent to CloudWatch Logs. CloudWatch Logs uses these metric filters to turn log data into numerical CloudWatch metrics that you can graph or set an alarm on.
A metric alarm watches a single CloudWatch metric or the result of a math expression based on CloudWatch metrics. The alarm performs one or more actions based on the value of the metric or expression relative to a threshold over a number of time periods. The action can be sending a notification to an Amazon SNS topic, performing an Amazon EC2 action or an Amazon EC2 Auto Scaling action, or creating an OpsItem or incident in Systems Manager.
Amazon CloudWatch metrics and alarms: 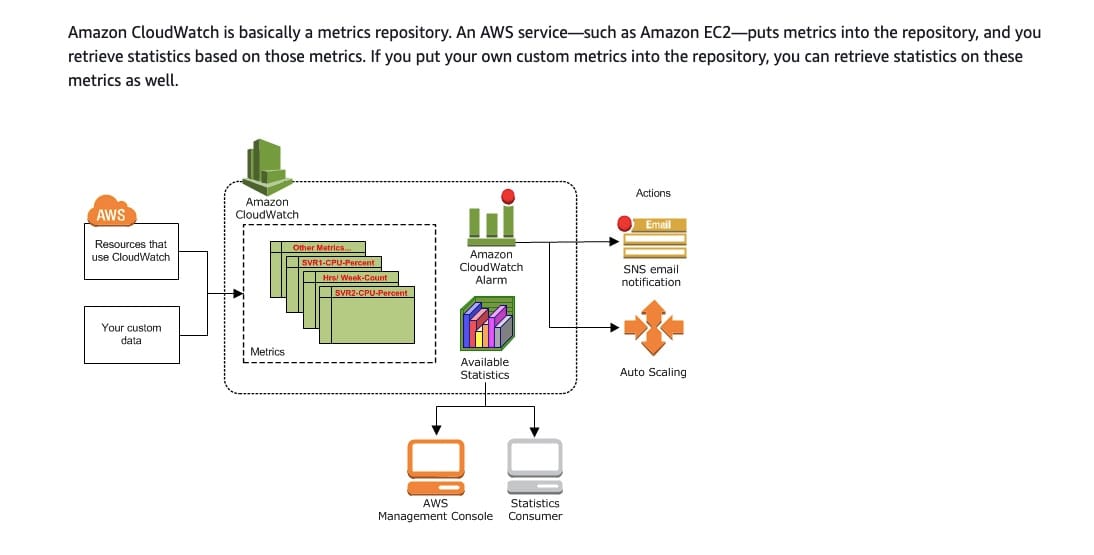 via - https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/cloudwatch_architecture.html
via - https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/cloudwatch_architecture.html
Incorrect options:
Create a metric filter on Amazon CloudWatch by filtering the log data to match the term Critical from log events. Configure a metric stream using Kinesis Data Firehose delivery stream and AWS Lambda as the destination. Process the stream data with Lambda and send a notification to an Amazon Simple Notification Service (Amazon SNS) topic if a Critical event is detected. Subscribe the email address of the security team to the SNS topic - You can use metric streams to continually stream CloudWatch metrics to a destination of your choice, with near-real-time delivery and low latency. Supported destinations include AWS destinations such as Amazon Simple Storage Service and several third-party service provider destinations. Kinesis Data Firehose is not supported as a destination for the metric streams.
Create a Transit Gateway Flow Log to capture all the information sent by the firewall appliance. Publish the flow log data to Amazon CloudWatch logs. Create a metric filter on Amazon CloudWatch by filtering the log data to match the term Critical from log events. Publish a custom metric for the finding and configure a CloudWatch alarm on this custom metric to publish a notification to an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe the email address of the security team to the SNS topic - Transit Gateway Flow Logs is a feature that enables you to capture information about the IP traffic going to and from your transit gateways. This does not meet our objective of analyzing firewall log data.
Create a metric filter on Amazon CloudWatch by filtering the log data to match the term Critical from log events. Publish a custom metric for the finding. Use CloudWatch Lambda Insights to filter out the Critical event and send a notification using an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe the email address of the security team to the SNS topic - CloudWatch Lambda Insights is a monitoring and troubleshooting solution for serverless applications running on AWS Lambda. The solution collects, aggregates, and summarizes system-level metrics including CPU time, memory, disk, and network. This option acts as a distractor for the given use case.
References:
https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/MonitoringLogData.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch-Metric-Streams.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/Lambda-Insights.html
https://docs.aws.amazon.com/vpc/latest/tgw/tgw-flow-logs.html
Explanation
Correct option:
Create a metric filter on Amazon CloudWatch by filtering the log data to match the term Critical from log events. Publish a custom metric for the finding and configure a CloudWatch alarm on this custom metric to publish a notification to an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe the email address of the security team to the SNS topic
You can search and filter the log data coming into CloudWatch Logs by creating one or more metric filters. Metric filters define the terms and patterns to look for in log data as it is sent to CloudWatch Logs. CloudWatch Logs uses these metric filters to turn log data into numerical CloudWatch metrics that you can graph or set an alarm on.
A metric alarm watches a single CloudWatch metric or the result of a math expression based on CloudWatch metrics. The alarm performs one or more actions based on the value of the metric or expression relative to a threshold over a number of time periods. The action can be sending a notification to an Amazon SNS topic, performing an Amazon EC2 action or an Amazon EC2 Auto Scaling action, or creating an OpsItem or incident in Systems Manager.
Amazon CloudWatch metrics and alarms: via - https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/cloudwatch_architecture.html
Incorrect options:
Create a metric filter on Amazon CloudWatch by filtering the log data to match the term Critical from log events. Configure a metric stream using Kinesis Data Firehose delivery stream and AWS Lambda as the destination. Process the stream data with Lambda and send a notification to an Amazon Simple Notification Service (Amazon SNS) topic if a Critical event is detected. Subscribe the email address of the security team to the SNS topic - You can use metric streams to continually stream CloudWatch metrics to a destination of your choice, with near-real-time delivery and low latency. Supported destinations include AWS destinations such as Amazon Simple Storage Service and several third-party service provider destinations. Kinesis Data Firehose is not supported as a destination for the metric streams.
Create a Transit Gateway Flow Log to capture all the information sent by the firewall appliance. Publish the flow log data to Amazon CloudWatch logs. Create a metric filter on Amazon CloudWatch by filtering the log data to match the term Critical from log events. Publish a custom metric for the finding and configure a CloudWatch alarm on this custom metric to publish a notification to an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe the email address of the security team to the SNS topic - Transit Gateway Flow Logs is a feature that enables you to capture information about the IP traffic going to and from your transit gateways. This does not meet our objective of analyzing firewall log data.
Create a metric filter on Amazon CloudWatch by filtering the log data to match the term Critical from log events. Publish a custom metric for the finding. Use CloudWatch Lambda Insights to filter out the Critical event and send a notification using an Amazon Simple Notification Service (Amazon SNS) topic. Subscribe the email address of the security team to the SNS topic - CloudWatch Lambda Insights is a monitoring and troubleshooting solution for serverless applications running on AWS Lambda. The solution collects, aggregates, and summarizes system-level metrics including CPU time, memory, disk, and network. This option acts as a distractor for the given use case.
References:
https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/MonitoringLogData.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch-Metric-Streams.html
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/Lambda-Insights.html
https://docs.aws.amazon.com/vpc/latest/tgw/tgw-flow-logs.html
Question 20 Single Choice
A developer configured an AWS CloudFormation template to create custom resource necessary for the project. The AWS Lambda function for the custom resource executed successfully as seen by the successful creation of the custom resource. But, the CloudFormation stack is not transitioning from in-progress status (CREATE_IN_PROGRESS) to completion status (CREATE_COMPLETE).
Which step did the developer possibly miss for the successful completion of the CloudFormation stack?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Configure the AWS Lambda function to send the response(SUCCESS or FAILED) of the custom resource creation to a pre-signed Amazon Simple Storage Service URL
Custom resources enable you to write custom provisioning logic in templates that AWS CloudFormation runs anytime you create, update (if you changed the custom resource), or delete stacks. Use the AWS::CloudFormation::CustomResource or Custom::MyCustomResourceTypeName resource type to define custom resources in your templates. Custom resources require one property: the service token, which specifies where AWS CloudFormation sends requests to, such as an Amazon SNS topic.
The custom resource provider processes the AWS CloudFormation request and returns a response of SUCCESS or FAILED to the pre-signed URL. The custom resource provider responds with a JSON-formatted file and uploads it to the pre-signed S3 URL. If this URL is not provided, the calling template will not get an update of the status of the Lambda function and will remain in an in-progress state.
How custom resources work: 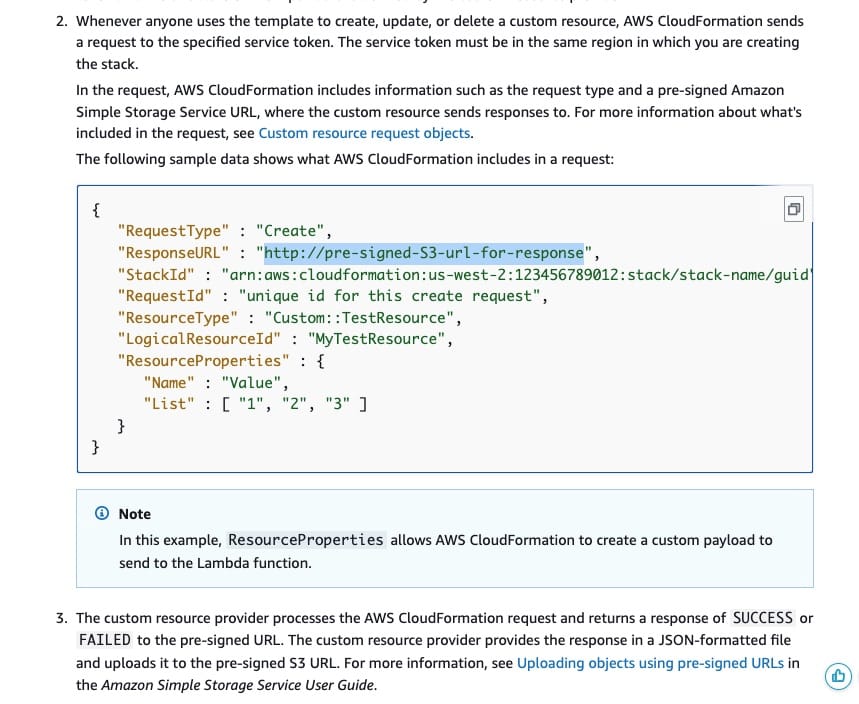 via - https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/template-custom-resources.html
via - https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/template-custom-resources.html
Incorrect options:
The AWS CloudFormation resource AWS::CloudFormation::CustomResource should be used to specify a custom resource in the template - You can use the AWS::CloudFormation::CustomResource or Custom::MyCustomResourceTypeName resource type to define custom resources in your templates. However, this has no bearing on the given use case.
If the template developer and custom resource provider are configured to the same person or entity then CloudFormation stack completion fails - This statement is incorrect. The template developer and custom resource provider can be the same person or entity.
After executing the send method in the cfn-response module, the Lambda function terminates, so anything written after this method is ignored - The cfn-response module is available only when you use the ZipFile property to write your source code. This is irrelevant to the given use case.
References:
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/template-custom-resources.html
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/template-custom-resources-lambda.html
Explanation
Correct option:
Configure the AWS Lambda function to send the response(SUCCESS or FAILED) of the custom resource creation to a pre-signed Amazon Simple Storage Service URL
Custom resources enable you to write custom provisioning logic in templates that AWS CloudFormation runs anytime you create, update (if you changed the custom resource), or delete stacks. Use the AWS::CloudFormation::CustomResource or Custom::MyCustomResourceTypeName resource type to define custom resources in your templates. Custom resources require one property: the service token, which specifies where AWS CloudFormation sends requests to, such as an Amazon SNS topic.
The custom resource provider processes the AWS CloudFormation request and returns a response of SUCCESS or FAILED to the pre-signed URL. The custom resource provider responds with a JSON-formatted file and uploads it to the pre-signed S3 URL. If this URL is not provided, the calling template will not get an update of the status of the Lambda function and will remain in an in-progress state.
How custom resources work: via - https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/template-custom-resources.html
Incorrect options:
The AWS CloudFormation resource AWS::CloudFormation::CustomResource should be used to specify a custom resource in the template - You can use the AWS::CloudFormation::CustomResource or Custom::MyCustomResourceTypeName resource type to define custom resources in your templates. However, this has no bearing on the given use case.
If the template developer and custom resource provider are configured to the same person or entity then CloudFormation stack completion fails - This statement is incorrect. The template developer and custom resource provider can be the same person or entity.
After executing the send method in the cfn-response module, the Lambda function terminates, so anything written after this method is ignored - The cfn-response module is available only when you use the ZipFile property to write your source code. This is irrelevant to the given use case.
References:
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/template-custom-resources.html
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/template-custom-resources-lambda.html


