
AWS Certified Machine Learning Engineer - Associate - (MLA-C01) Exam Questions
Total Questions
Last Updated
1st Try Guaranteed

Experts Verified
Question 1 Single Choice
A retail company is building a web-based AI application using Amazon SageMaker to predict customer purchase behavior. The system must support full ML lifecycle features such as experimentation, training, centralized model registry, deployment, and monitoring. The training data is securely stored in Amazon S3, and the models need to be deployed to real-time endpoints to serve predictions. The company is now planning to run an on-demand workflow to monitor for bias drift in the deployed models to ensure fairness and accuracy in predictions.
What do you recommend?
Explanation

Click "Show Answer" to see the explanation here
Correct option:
Use Amazon SageMaker Clarify to analyze captured inference data from real-time endpoints for bias detection on demand
Amazon SageMaker Clarify can analyze bias in the input and output data captured from SageMaker real-time endpoints. By enabling data capture in SageMaker endpoints and integrating Clarify, you can run on-demand bias analysis workflows to identify and measure bias drift.
This solution leverages Clarify’s post-deployment bias detection capabilities, allowing the company to analyze inference data over time and ensure the model maintains fairness in production.
Key Steps:
Enable data capture for real-time endpoints.
Use SageMaker Clarify to analyze the captured data for bias.
Generate detailed reports to detect and quantify bias drift.
 via - https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-model-monitor-bias-drift.html
via - https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-model-monitor-bias-drift.html
Incorrect options:
Use Amazon SageMaker Lineage Tracking to trace and analyze bias drift in model predictions - SageMaker Lineage Tracking is designed to track the lineage of ML artifacts, such as datasets, models, and experiments. While useful for auditability and reproducibility, it does not perform bias drift analysis or real-time model monitoring.
Use AWS Glue Data Quality to validate and monitor data quality for detecting bias drift in real-time endpoints - AWS Glue Data Quality is designed to evaluate and enforce data quality rules on datasets processed through AWS Glue ETL jobs. While it ensures input data meets quality thresholds during extraction, transformation, and loading, it does not provide bias drift monitoring for deployed machine learning models at real-time endpoints.
Use the sagemaker-model-monitor-analyzer built-in SageMaker image to automatically analyze and resolve bias drift in deployed models - The sagemaker-model-monitor-analyzer built-in image is used as part of Amazon SageMaker Model Monitor to run custom monitoring jobs, such as analyzing data captured from endpoints for drift, bias, or feature issues. However, this built-in image is only used for analysis and reporting purposes. It does not automatically resolve or fix bias drift.
Reference:
https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-model-monitor-bias-drift.html
Explanation
Correct option:
Use Amazon SageMaker Clarify to analyze captured inference data from real-time endpoints for bias detection on demand
Amazon SageMaker Clarify can analyze bias in the input and output data captured from SageMaker real-time endpoints. By enabling data capture in SageMaker endpoints and integrating Clarify, you can run on-demand bias analysis workflows to identify and measure bias drift.
This solution leverages Clarify’s post-deployment bias detection capabilities, allowing the company to analyze inference data over time and ensure the model maintains fairness in production.
Key Steps:
Enable data capture for real-time endpoints.
Use SageMaker Clarify to analyze the captured data for bias.
Generate detailed reports to detect and quantify bias drift.
via - https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-model-monitor-bias-drift.html
Incorrect options:
Use Amazon SageMaker Lineage Tracking to trace and analyze bias drift in model predictions - SageMaker Lineage Tracking is designed to track the lineage of ML artifacts, such as datasets, models, and experiments. While useful for auditability and reproducibility, it does not perform bias drift analysis or real-time model monitoring.
Use AWS Glue Data Quality to validate and monitor data quality for detecting bias drift in real-time endpoints - AWS Glue Data Quality is designed to evaluate and enforce data quality rules on datasets processed through AWS Glue ETL jobs. While it ensures input data meets quality thresholds during extraction, transformation, and loading, it does not provide bias drift monitoring for deployed machine learning models at real-time endpoints.
Use the sagemaker-model-monitor-analyzer built-in SageMaker image to automatically analyze and resolve bias drift in deployed models - The sagemaker-model-monitor-analyzer built-in image is used as part of Amazon SageMaker Model Monitor to run custom monitoring jobs, such as analyzing data captured from endpoints for drift, bias, or feature issues. However, this built-in image is only used for analysis and reporting purposes. It does not automatically resolve or fix bias drift.
Reference:
https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-model-monitor-bias-drift.html
Question 2 Single Choice
You are a data scientist at a financial institution tasked with building a model to detect fraudulent transactions. The dataset is highly imbalanced, with only a small percentage of transactions being fraudulent. After experimenting with several models, you decide to implement a boosting technique to improve the model’s accuracy, particularly on the minority class. You are considering different types of boosting, including Adaptive Boosting (AdaBoost), Gradient Boosting, and Extreme Gradient Boosting (XGBoost).
Given the problem context and the need to effectively handle class imbalance, which boosting technique is MOST SUITABLE for this scenario?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Apply Extreme Gradient Boosting (XGBoost) for its ability to handle imbalanced datasets effectively through regularization, weighted classes, and optimized computational efficiency
The XGBoost (eXtreme Gradient Boosting) is a popular and efficient open-source implementation of the gradient boosted trees algorithm. Gradient boosting is a supervised learning algorithm that tries to accurately predict a target variable by combining multiple estimates from a set of simpler models. The XGBoost algorithm performs well in machine learning competitions for the following reasons:
Its robust handling of a variety of data types, relationships, distributions.
The variety of hyperparameters that you can fine-tune.
XGBoost is an extension of Gradient Boosting that includes additional features such as regularization, handling of missing values, and support for weighted classes, making it particularly well-suited for imbalanced datasets like fraud detection. It also offers significant computational efficiency, which is beneficial when working with large datasets.
 via - https://aws.amazon.com/what-is/boosting/
via - https://aws.amazon.com/what-is/boosting/
Incorrect options:
Use Adaptive Boosting (AdaBoost) to focus on correcting the errors of weak classifiers, giving more weight to incorrectly classified instances during each iteration - AdaBoost works by focusing on correcting the errors of weak classifiers, assigning more weight to misclassified instances in each iteration. However, it may struggle with noisy data and extreme class imbalance, as it can overemphasize hard-to-classify instances.
Implement Gradient Boosting to sequentially train weak learners, using the gradient of the loss function to improve performance on the minority class - Gradient Boosting is a powerful technique that uses the gradient of the loss function to improve the model iteratively. While it can be adapted to handle class imbalance, it does not inherently provide the same level of flexibility and computational optimization as XGBoost for this specific problem.
Use Gradient Boosting and manually adjust the learning rate and class weights to improve performance on the minority class, avoiding the complexities of XGBoost - While manually adjusting the learning rate and class weights in Gradient Boosting can help, XGBoost already provides built-in mechanisms to handle these challenges more effectively, including advanced regularization techniques and hyperparameter optimization.
References:
https://aws.amazon.com/what-is/boosting/
https://docs.aws.amazon.com/sagemaker/latest/dg/xgboost.html
https://docs.aws.amazon.com/sagemaker/latest/dg/xgboost_hyperparameters.html
https://aws.amazon.com/blogs/gametech/fraud-detection-for-games-using-machine-learning/
Explanation
Correct option:
Apply Extreme Gradient Boosting (XGBoost) for its ability to handle imbalanced datasets effectively through regularization, weighted classes, and optimized computational efficiency
The XGBoost (eXtreme Gradient Boosting) is a popular and efficient open-source implementation of the gradient boosted trees algorithm. Gradient boosting is a supervised learning algorithm that tries to accurately predict a target variable by combining multiple estimates from a set of simpler models. The XGBoost algorithm performs well in machine learning competitions for the following reasons:
Its robust handling of a variety of data types, relationships, distributions.
The variety of hyperparameters that you can fine-tune.
XGBoost is an extension of Gradient Boosting that includes additional features such as regularization, handling of missing values, and support for weighted classes, making it particularly well-suited for imbalanced datasets like fraud detection. It also offers significant computational efficiency, which is beneficial when working with large datasets.
via - https://aws.amazon.com/what-is/boosting/
Incorrect options:
Use Adaptive Boosting (AdaBoost) to focus on correcting the errors of weak classifiers, giving more weight to incorrectly classified instances during each iteration - AdaBoost works by focusing on correcting the errors of weak classifiers, assigning more weight to misclassified instances in each iteration. However, it may struggle with noisy data and extreme class imbalance, as it can overemphasize hard-to-classify instances.
Implement Gradient Boosting to sequentially train weak learners, using the gradient of the loss function to improve performance on the minority class - Gradient Boosting is a powerful technique that uses the gradient of the loss function to improve the model iteratively. While it can be adapted to handle class imbalance, it does not inherently provide the same level of flexibility and computational optimization as XGBoost for this specific problem.
Use Gradient Boosting and manually adjust the learning rate and class weights to improve performance on the minority class, avoiding the complexities of XGBoost - While manually adjusting the learning rate and class weights in Gradient Boosting can help, XGBoost already provides built-in mechanisms to handle these challenges more effectively, including advanced regularization techniques and hyperparameter optimization.
References:
https://aws.amazon.com/what-is/boosting/
https://docs.aws.amazon.com/sagemaker/latest/dg/xgboost.html
https://docs.aws.amazon.com/sagemaker/latest/dg/xgboost_hyperparameters.html
https://aws.amazon.com/blogs/gametech/fraud-detection-for-games-using-machine-learning/
Question 3 Single Choice
A retail company has deployed a machine learning (ML) model using Amazon SageMaker to forecast product demand. The model is exposed via a SageMaker endpoint that processes requests from multiple applications. The company needs to record and monitor all API call events made to the endpoint and receive a notification whenever the number of requests exceeds a specific threshold during peak traffic hours.
Which solution will meet these requirements?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use Amazon CloudWatch to monitor the API call metrics for the SageMaker endpoint and create an alarm to send notifications through Amazon SNS when the call count breaches the threshold
Amazon CloudWatch is the most suitable solution for this scenario because it provides:
Metrics for API call counts - CloudWatch automatically collects invocation metrics for SageMaker endpoints, including Invocations, InvocationErrors, and Latency.
Alarms - Alarms can be created to monitor thresholds for metrics, such as the number of API calls.
Notifications - When a threshold is breached, the alarm can send notifications through Amazon Simple Notification Service (SNS).
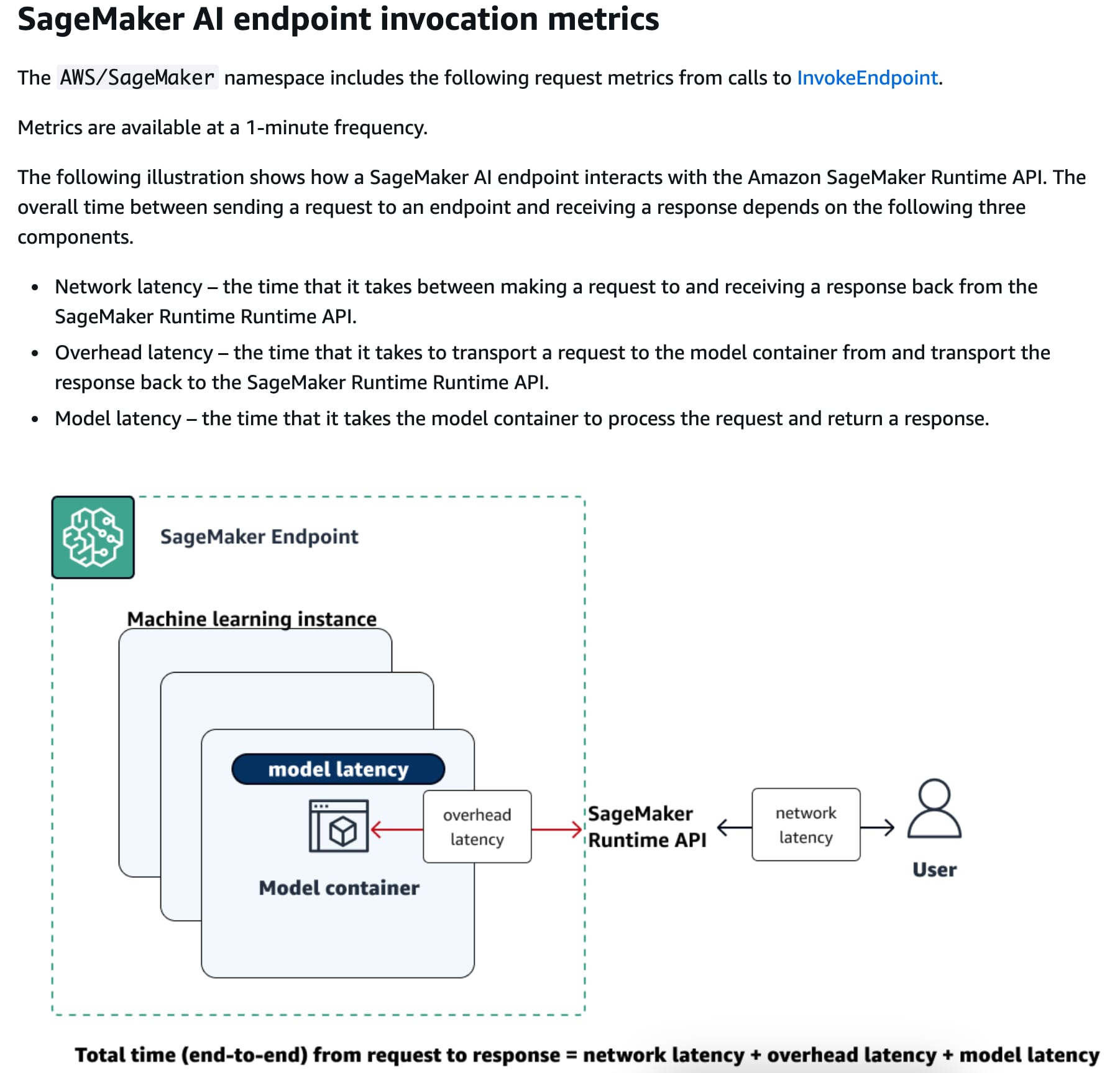 via - https://docs.aws.amazon.com/sagemaker/latest/dg/monitoring-cloudwatch.html
via - https://docs.aws.amazon.com/sagemaker/latest/dg/monitoring-cloudwatch.html
Incorrect options:
Enable AWS CloudTrail to log all SageMaker API call events and use CloudTrail Insights to send notifications when the API call volume exceeds a threshold - AWS CloudTrail logs API calls for auditing purposes and can detect unusual activity using CloudTrail Insights. However, it is not designed for threshold-based alarms.
Use SageMaker Model Monitor to capture and analyze endpoint traffic and configure a rule to notify when API calls exceed the specified threshold - SageMaker Model Monitor is used to track data quality, bias, and drift for endpoint traffic. It does not natively monitor API call metrics or provide mechanisms for triggering notifications based on call counts.
Use Amazon EventBridge to capture SageMaker API call events and configure a rule to send a notification when the event count breaches the threshold - EventBridge is suitable for capturing and routing specific event patterns, but it does not aggregate or monitor API metrics over time. It lacks the capability to set thresholds or alarms for continuous monitoring.
Reference:
https://docs.aws.amazon.com/sagemaker/latest/dg/monitoring-cloudwatch.html
Explanation
Correct option:
Use Amazon CloudWatch to monitor the API call metrics for the SageMaker endpoint and create an alarm to send notifications through Amazon SNS when the call count breaches the threshold
Amazon CloudWatch is the most suitable solution for this scenario because it provides:
Metrics for API call counts - CloudWatch automatically collects invocation metrics for SageMaker endpoints, including Invocations, InvocationErrors, and Latency.
Alarms - Alarms can be created to monitor thresholds for metrics, such as the number of API calls.
Notifications - When a threshold is breached, the alarm can send notifications through Amazon Simple Notification Service (SNS).
via - https://docs.aws.amazon.com/sagemaker/latest/dg/monitoring-cloudwatch.html
Incorrect options:
Enable AWS CloudTrail to log all SageMaker API call events and use CloudTrail Insights to send notifications when the API call volume exceeds a threshold - AWS CloudTrail logs API calls for auditing purposes and can detect unusual activity using CloudTrail Insights. However, it is not designed for threshold-based alarms.
Use SageMaker Model Monitor to capture and analyze endpoint traffic and configure a rule to notify when API calls exceed the specified threshold - SageMaker Model Monitor is used to track data quality, bias, and drift for endpoint traffic. It does not natively monitor API call metrics or provide mechanisms for triggering notifications based on call counts.
Use Amazon EventBridge to capture SageMaker API call events and configure a rule to send a notification when the event count breaches the threshold - EventBridge is suitable for capturing and routing specific event patterns, but it does not aggregate or monitor API metrics over time. It lacks the capability to set thresholds or alarms for continuous monitoring.
Reference:
https://docs.aws.amazon.com/sagemaker/latest/dg/monitoring-cloudwatch.html
Question 4 Single Choice
A financial analytics company runs a data aggregation job every Saturday night to process transactional data from the past week. The job is scheduled to run for approximately 2 hours and can tolerate interruptions without impacting the results. The company plans to run this job consistently every weekend for the next 6 months.
Which EC2 instance purchasing option will meet these requirements MOST cost-effectively?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use EC2 Spot Instances to run the aggregation job, as they provide substantial cost savings and can handle interruptions
EC2 Spot Instances are the best fit for this scenario because they allow the company to:
Leverage unused EC2 capacity at significantly reduced prices, offering up to 90% cost savings compared to On-Demand pricing.
Run the job in off-peak hours (Saturday night), reducing the likelihood of interruptions.
Benefit from the fact that the job tolerates interruptions, aligning perfectly with Spot Instances' use case.
This makes Spot Instances the most cost-effective solution for a short-duration, intermittent, and interruption-tolerant workload.
Incorrect options:
Use EC2 On-Demand Instances to run the job each weekend for 2 hours, paying only for the compute time consumed - On-Demand Instances are more expensive compared to Spot Instances. While they provide guaranteed availability, the workload can handle interruptions, making Spot Instances a better choice.
Use EC2 Reserved Instances with a 6-month commitment to ensure lower costs and guaranteed availability - Reserved Instances are suitable for long-term, predictable workloads that require guaranteed availability. The available term for Reserved Instances is 1 or 3 years. For a weekly job that is slated to run only for 6 months, this approach would result in wasted costs for unused hours.
Use EC2 Dedicated Hosts to run the job for full control over the infrastructure and long-term cost efficiency - Dedicated Hosts are expensive and are typically used for workloads requiring dedicated physical servers due to compliance or licensing requirements. They are not cost-effective for short-duration batch jobs.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/instance-purchasing-options.html
Explanation
Correct option:
Use EC2 Spot Instances to run the aggregation job, as they provide substantial cost savings and can handle interruptions
EC2 Spot Instances are the best fit for this scenario because they allow the company to:
Leverage unused EC2 capacity at significantly reduced prices, offering up to 90% cost savings compared to On-Demand pricing.
Run the job in off-peak hours (Saturday night), reducing the likelihood of interruptions.
Benefit from the fact that the job tolerates interruptions, aligning perfectly with Spot Instances' use case.
This makes Spot Instances the most cost-effective solution for a short-duration, intermittent, and interruption-tolerant workload.
Incorrect options:
Use EC2 On-Demand Instances to run the job each weekend for 2 hours, paying only for the compute time consumed - On-Demand Instances are more expensive compared to Spot Instances. While they provide guaranteed availability, the workload can handle interruptions, making Spot Instances a better choice.
Use EC2 Reserved Instances with a 6-month commitment to ensure lower costs and guaranteed availability - Reserved Instances are suitable for long-term, predictable workloads that require guaranteed availability. The available term for Reserved Instances is 1 or 3 years. For a weekly job that is slated to run only for 6 months, this approach would result in wasted costs for unused hours.
Use EC2 Dedicated Hosts to run the job for full control over the infrastructure and long-term cost efficiency - Dedicated Hosts are expensive and are typically used for workloads requiring dedicated physical servers due to compliance or licensing requirements. They are not cost-effective for short-duration batch jobs.
Reference:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/instance-purchasing-options.html
Question 5 Single Choice
Which AWS service is used to store, share and manage inputs to Machine Learning models used during training and inference?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Amazon SageMaker Feature Store
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. For example, in an application that recommends a music playlist, features could include song ratings, listening duration, and listener demographics.
You can ingest data into SageMaker Feature Store from a variety of sources, such as application and service logs, clickstreams, sensors, and tabular data from Amazon Simple Storage Service (Amazon S3), Amazon Redshift, AWS Lake Formation, Snowflake, and Databricks Delta Lake.
How Feature Store works: 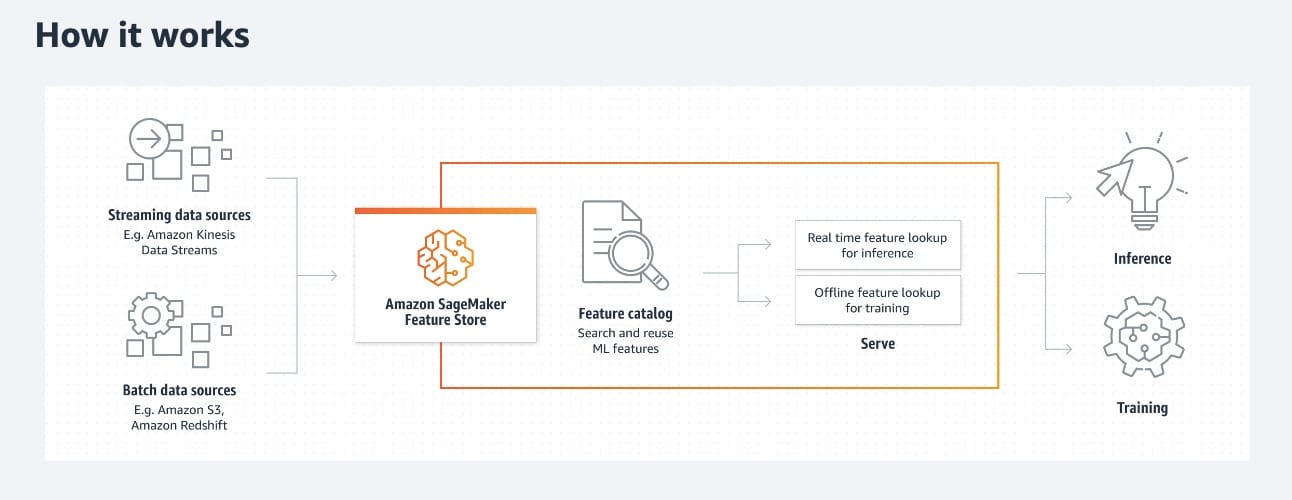 via - https://aws.amazon.com/sagemaker/feature-store/
via - https://aws.amazon.com/sagemaker/feature-store/
Incorrect options:
Amazon SageMaker Clarify - SageMaker Clarify helps identify potential bias during data preparation without writing code. You specify input features, such as gender or age, and SageMaker Clarify runs an analysis job to detect potential bias in those features.
Amazon SageMaker Data Wrangler - Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for ML from weeks to minutes. With SageMaker Data Wrangler, you can simplify the process of data preparation and feature engineering, and complete each step of the data preparation workflow (including data selection, cleansing, exploration, visualization, and processing at scale) from a single visual interface.
Amazon SageMaker Ground Truth - Amazon SageMaker Ground Truth offers the most comprehensive set of human-in-the-loop capabilities, allowing you to harness the power of human feedback across the ML lifecycle to improve the accuracy and relevancy of models. You can complete a variety of human-in-the-loop tasks with SageMaker Ground Truth, from data generation and annotation to model review, customization, and evaluation, either through a self-service or an AWS-managed offering.
References:
https://aws.amazon.com/sagemaker/feature-store/
https://aws.amazon.com/sagemaker/groundtruth
Explanation
Correct option:
Amazon SageMaker Feature Store
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. For example, in an application that recommends a music playlist, features could include song ratings, listening duration, and listener demographics.
You can ingest data into SageMaker Feature Store from a variety of sources, such as application and service logs, clickstreams, sensors, and tabular data from Amazon Simple Storage Service (Amazon S3), Amazon Redshift, AWS Lake Formation, Snowflake, and Databricks Delta Lake.
How Feature Store works: via - https://aws.amazon.com/sagemaker/feature-store/
Incorrect options:
Amazon SageMaker Clarify - SageMaker Clarify helps identify potential bias during data preparation without writing code. You specify input features, such as gender or age, and SageMaker Clarify runs an analysis job to detect potential bias in those features.
Amazon SageMaker Data Wrangler - Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for ML from weeks to minutes. With SageMaker Data Wrangler, you can simplify the process of data preparation and feature engineering, and complete each step of the data preparation workflow (including data selection, cleansing, exploration, visualization, and processing at scale) from a single visual interface.
Amazon SageMaker Ground Truth - Amazon SageMaker Ground Truth offers the most comprehensive set of human-in-the-loop capabilities, allowing you to harness the power of human feedback across the ML lifecycle to improve the accuracy and relevancy of models. You can complete a variety of human-in-the-loop tasks with SageMaker Ground Truth, from data generation and annotation to model review, customization, and evaluation, either through a self-service or an AWS-managed offering.
References:
https://aws.amazon.com/sagemaker/feature-store/
https://aws.amazon.com/sagemaker/groundtruth
Question 6 Single Choice
A pharmaceutical company is using Amazon SageMaker to develop machine learning models for drug discovery. The data scientists need a solution that provides granular control over their ML pipelines to manage the steps involved in preclinical testing simulations. They also require the ability to visualize workflows for experiments as a directed acyclic graph (DAG) to better understand dependencies. In addition, the solution must allow them to maintain a history of experiment trials for reproducibility and optimization, as well as tools to implement model governance for regulatory audits and compliance verifications.
Which solution will meet these requirements?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Use SageMaker Pipelines for orchestrating ML workflows, visualize them as a DAG, and leverage SageMaker ML Lineage Tracking for auditing and compliance
SageMaker Pipelines is specifically designed for ML workflow orchestration. It provides:
Fine-grained control - Data scientists can define step-by-step ML workflows, including data preparation, model training, and deployment.
Visualization as a DAG - Workflows are represented as a directed acyclic graph (DAG), making it easy to visualize dependencies.
Seamless integration with SageMaker ML Lineage Tracking - Automatically tracks lineage information, including input datasets, model artifacts, and inference endpoints, ensuring compliance and auditability.
SageMaker ML Lineage Tracking provides tools to establish model governance by maintaining a detailed record of all components involved in the ML lifecycle.
Amazon SageMaker ML Lineage Tracking: 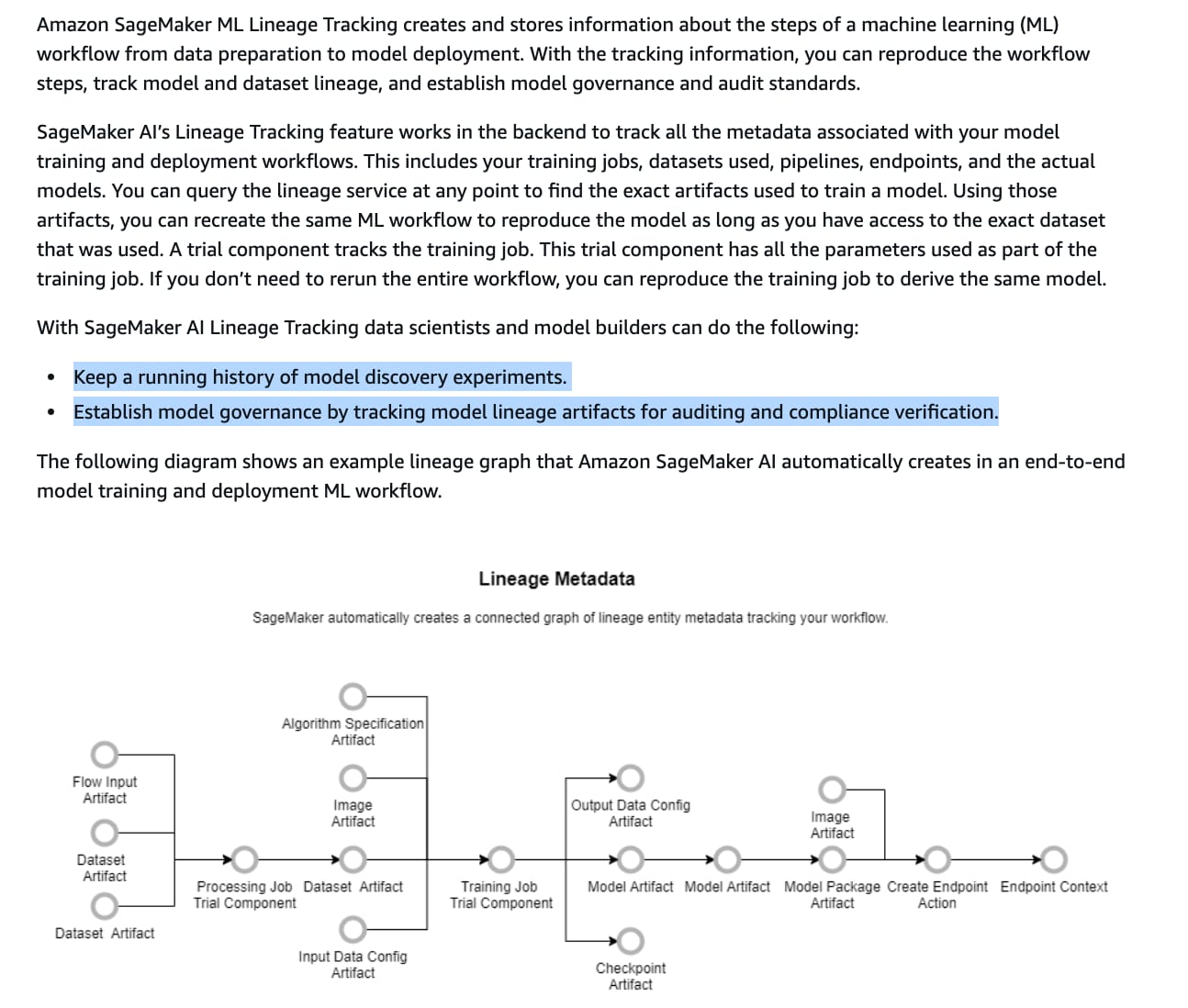 via - https://docs.aws.amazon.com/sagemaker/latest/dg/lineage-tracking.html
via - https://docs.aws.amazon.com/sagemaker/latest/dg/lineage-tracking.html
Incorrect options:
Use AWS CodePipeline for orchestration, visualize workflows as a series of stages, and implement SageMaker Experiments to maintain a running history of model discovery experiments - AWS CodePipeline is a general-purpose CI/CD tool for automating workflows, but it does not provide DAG visualization or fine-grained control for ML-specific workflows like SageMaker Pipelines. Additionally, SageMaker Experiments does not track lineage for auditing and compliance.
Use SageMaker Experiments for tracking and visualizing all workflows and rely on AWS CodePipeline for orchestration and governance - SageMaker Experiments tracks and organizes experiment trials but does not provide workflow orchestration or DAG visualization. It also lacks tools for comprehensive compliance and auditing.
Use SageMaker Pipelines for orchestration, visualize workflows as a DAG, and leverage SageMaker Experiments for model governance and compliance - SageMaker Experiments is useful for managing experiments but does not provide lineage tracking, which is critical for ensuring governance for regulatory audits and compliance verifications.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/lineage-tracking.html
Explanation
Correct option:
Use SageMaker Pipelines for orchestrating ML workflows, visualize them as a DAG, and leverage SageMaker ML Lineage Tracking for auditing and compliance
SageMaker Pipelines is specifically designed for ML workflow orchestration. It provides:
Fine-grained control - Data scientists can define step-by-step ML workflows, including data preparation, model training, and deployment.
Visualization as a DAG - Workflows are represented as a directed acyclic graph (DAG), making it easy to visualize dependencies.
Seamless integration with SageMaker ML Lineage Tracking - Automatically tracks lineage information, including input datasets, model artifacts, and inference endpoints, ensuring compliance and auditability.
SageMaker ML Lineage Tracking provides tools to establish model governance by maintaining a detailed record of all components involved in the ML lifecycle.
Amazon SageMaker ML Lineage Tracking: via - https://docs.aws.amazon.com/sagemaker/latest/dg/lineage-tracking.html
Incorrect options:
Use AWS CodePipeline for orchestration, visualize workflows as a series of stages, and implement SageMaker Experiments to maintain a running history of model discovery experiments - AWS CodePipeline is a general-purpose CI/CD tool for automating workflows, but it does not provide DAG visualization or fine-grained control for ML-specific workflows like SageMaker Pipelines. Additionally, SageMaker Experiments does not track lineage for auditing and compliance.
Use SageMaker Experiments for tracking and visualizing all workflows and rely on AWS CodePipeline for orchestration and governance - SageMaker Experiments tracks and organizes experiment trials but does not provide workflow orchestration or DAG visualization. It also lacks tools for comprehensive compliance and auditing.
Use SageMaker Pipelines for orchestration, visualize workflows as a DAG, and leverage SageMaker Experiments for model governance and compliance - SageMaker Experiments is useful for managing experiments but does not provide lineage tracking, which is critical for ensuring governance for regulatory audits and compliance verifications.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/lineage-tracking.html
Question 7 Single Choice
An ML engineer is training a time series forecasting model using a recurrent neural network (RNN) to predict electricity demand for a utility company. The model is trained using stochastic gradient descent (SGD) as the optimizer. During training, the engineer notices the following:
The training loss and validation loss remain high.
The loss values oscillate, decreasing for a few epochs and then increasing again before repeating the cycle.
The ML engineer needs to resolve this issue to stabilize the training process and improve model performance. What should the ML engineer do to improve the training process?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Reduce the learning rate to allow the gradient updates to converge more smoothly and prevent oscillations in the loss values
The oscillating pattern of the loss values during training and validation suggests that the learning rate is too high. When the learning rate is large:
The gradient updates overshoot the optimal solution, causing loss values to oscillate instead of converging.
Training cannot settle into a local minimum, resulting in poor performance on the test set.
By reducing the learning rate, the gradient updates become smaller, allowing the model to converge more smoothly and stabilize the training process. This will help the loss values decrease steadily over time.
Incorrect options:
Apply dropout regularization to the RNN layers to improve generalization and reduce oscillations in the loss - Dropout regularization helps reduce overfitting, but the described issue is a training instability problem caused by a high learning rate.
Increase the learning rate to allow the gradient updates to converge more smoothly and prevent oscillations in the loss values - Increasing the learning rate would further exacerbate the problem. Too large a learning rate might prevent the weights from approaching the optimal solution.
Increase the number of training epochs to give the model more time to learn the patterns in the data - Increasing epochs won’t resolve oscillations caused by a high learning rate. The model will continue to oscillate without convergence.
Reference:
https://docs.aws.amazon.com/machine-learning/latest/dg/training-parameters1.html
Explanation
Correct option:
Reduce the learning rate to allow the gradient updates to converge more smoothly and prevent oscillations in the loss values
The oscillating pattern of the loss values during training and validation suggests that the learning rate is too high. When the learning rate is large:
The gradient updates overshoot the optimal solution, causing loss values to oscillate instead of converging.
Training cannot settle into a local minimum, resulting in poor performance on the test set.
By reducing the learning rate, the gradient updates become smaller, allowing the model to converge more smoothly and stabilize the training process. This will help the loss values decrease steadily over time.
Incorrect options:
Apply dropout regularization to the RNN layers to improve generalization and reduce oscillations in the loss - Dropout regularization helps reduce overfitting, but the described issue is a training instability problem caused by a high learning rate.
Increase the learning rate to allow the gradient updates to converge more smoothly and prevent oscillations in the loss values - Increasing the learning rate would further exacerbate the problem. Too large a learning rate might prevent the weights from approaching the optimal solution.
Increase the number of training epochs to give the model more time to learn the patterns in the data - Increasing epochs won’t resolve oscillations caused by a high learning rate. The model will continue to oscillate without convergence.
Reference:
https://docs.aws.amazon.com/machine-learning/latest/dg/training-parameters1.html
Question 8 Single Choice
A healthcare company is building an AI application to predict patient readmission rates using Amazon SageMaker. The application must support end-to-end machine learning workflows, including data preprocessing, model training, version management, and deployment. The training data, stored securely in Amazon S3, must be used in isolated and secure environments to comply with regulatory requirements. As part of model experimentation, the data science team is running multiple training jobs back-to-back to test different hyperparameter configurations.
To improve the team’s productivity, the company needs to reduce the startup time for each consecutive training job. What is the most efficient solution to achieve this goal?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Enable SageMaker Warm Pools to reuse training instances between jobs
Amazon SageMaker Warm Pools allow reuse of ML compute infrastructure between consecutive training jobs. This significantly reduces startup times because instances remain warm and do not require new provisioning or configuration. Warm Pools work seamlessly with SageMaker training jobs, helping minimize infrastructure startup overhead while ensuring the infrastructure is reused securely and efficiently. This is ideal for use cases where consecutive training jobs are frequent, as in experimentation workflows.
Key Benefits:
Reduces time spent on infrastructure provisioning.
Optimizes compute resource utilization for iterative training.
Supports secure training job execution as it integrates with SageMaker's role-based permissions.
 via - https://docs.aws.amazon.com/sagemaker/latest/dg/model-registry.html
via - https://docs.aws.amazon.com/sagemaker/latest/dg/model-registry.html
Incorrect options:
Use Amazon SageMaker Managed Spot Training for faster resource allocation - Managed Spot Training in Amazon SageMaker is a cost-saving feature that uses spare EC2 capacity to run training jobs at a reduced cost. However, spot instances are not guaranteed to always be available and may lead to longer infrastructure startup times due to capacity provisioning delays. It does not minimize startup times and is not ideal for consecutive training jobs requiring quick infrastructure readiness.
Use Amazon EC2 On-Demand Instances with pre-configured AMIs for SageMaker - While pre-configured AMIs can reduce configuration time, EC2 On-Demand Instances still require provisioning at the start of each job. SageMaker Warm Pools are specifically designed to minimize startup times for training jobs.
Use SageMaker Training Compiler to minimize data transfer latency - The SageMaker Training Compiler is used to optimize deep learning training workloads by accelerating model training and reducing costs. While it improves training performance, it does not address infrastructure startup times or reduce the time required to initialize the training environment.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/train-warm-pools.html
Explanation
Correct option:
Enable SageMaker Warm Pools to reuse training instances between jobs
Amazon SageMaker Warm Pools allow reuse of ML compute infrastructure between consecutive training jobs. This significantly reduces startup times because instances remain warm and do not require new provisioning or configuration. Warm Pools work seamlessly with SageMaker training jobs, helping minimize infrastructure startup overhead while ensuring the infrastructure is reused securely and efficiently. This is ideal for use cases where consecutive training jobs are frequent, as in experimentation workflows.
Key Benefits:
Reduces time spent on infrastructure provisioning.
Optimizes compute resource utilization for iterative training.
Supports secure training job execution as it integrates with SageMaker's role-based permissions.
via - https://docs.aws.amazon.com/sagemaker/latest/dg/model-registry.html
Incorrect options:
Use Amazon SageMaker Managed Spot Training for faster resource allocation - Managed Spot Training in Amazon SageMaker is a cost-saving feature that uses spare EC2 capacity to run training jobs at a reduced cost. However, spot instances are not guaranteed to always be available and may lead to longer infrastructure startup times due to capacity provisioning delays. It does not minimize startup times and is not ideal for consecutive training jobs requiring quick infrastructure readiness.
Use Amazon EC2 On-Demand Instances with pre-configured AMIs for SageMaker - While pre-configured AMIs can reduce configuration time, EC2 On-Demand Instances still require provisioning at the start of each job. SageMaker Warm Pools are specifically designed to minimize startup times for training jobs.
Use SageMaker Training Compiler to minimize data transfer latency - The SageMaker Training Compiler is used to optimize deep learning training workloads by accelerating model training and reducing costs. While it improves training performance, it does not address infrastructure startup times or reduce the time required to initialize the training environment.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/train-warm-pools.html
Question 9 Single Choice
You are a machine learning engineer at a biotech company developing a custom deep learning model for analyzing genomic data. The model relies on a specific version of TensorFlow with custom Python libraries and dependencies that are not available in the standard SageMaker environments. To ensure compatibility and flexibility, you decide to use the "Bring Your Own Container" (BYOC) approach with Amazon SageMaker for both training and inference.
Given this scenario, which steps are MOST IMPORTANT for successfully deploying your custom container with SageMaker, ensuring that it meets the company’s requirements?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Create a Docker container with the required environment, push the container image to Amazon ECR (Elastic Container Registry), and use SageMaker’s Script Mode to execute the training script within the container
Script mode enables you to write custom training and inference code while still utilizing common ML framework containers maintained by AWS.
SageMaker supports most of the popular ML frameworks through pre-built containers, and has taken the extra step to optimize them to work especially well on AWS compute and network infrastructure in order to achieve near-linear scaling efficiency. These pre-built containers also provide some additional Python packages, such as Pandas and NumPy, so you can write your own code for training an algorithm. These frameworks also allow you to install any Python package hosted on PyPi by including a requirements.txt file with your training code or to include your own code directories.
This is the correct approach for using the BYOC strategy with SageMaker. You build a Docker container that includes the required TensorFlow version and custom dependencies, then push the image to Amazon ECR. SageMaker can reference this image to create training jobs and deploy endpoints. By using Script Mode, you can execute your custom training script within the container, ensuring compatibility with your specific environment.
 via -
via - Incorrect options:
Build a Docker container with the required TensorFlow version and dependencies, push the container image to Docker Hub, and reference the image in SageMaker when creating the training job - While Docker Hub can be used to host container images, Amazon SageMaker is optimized to work with images stored in Amazon ECR, providing better security, performance, and integration with AWS services. Additionally, using Docker Hub for production ML workloads may pose security and compliance risks.
Package the model as a SageMaker-compatible file, upload it to Amazon S3, and use a pre-built SageMaker container for training, ensuring that the training job uses the custom environment - This option describes a standard SageMaker workflow using pre-built containers, which does not provide the customization required by the BYOC approach. SageMaker pre-built containers may not support the specific custom libraries and dependencies your model requires.
Deploy the model locally using Docker, then use the AWS Management Console to manually copy the environment and model files to a SageMaker instance for training - Manually deploying the model and environment locally and then copying files to SageMaker instances is not scalable or maintainable. SageMaker BYOC allows for a more robust, automated, and integrated solution.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/docker-containers.html
Explanation
Correct option:
Create a Docker container with the required environment, push the container image to Amazon ECR (Elastic Container Registry), and use SageMaker’s Script Mode to execute the training script within the container
Script mode enables you to write custom training and inference code while still utilizing common ML framework containers maintained by AWS.
SageMaker supports most of the popular ML frameworks through pre-built containers, and has taken the extra step to optimize them to work especially well on AWS compute and network infrastructure in order to achieve near-linear scaling efficiency. These pre-built containers also provide some additional Python packages, such as Pandas and NumPy, so you can write your own code for training an algorithm. These frameworks also allow you to install any Python package hosted on PyPi by including a requirements.txt file with your training code or to include your own code directories.
This is the correct approach for using the BYOC strategy with SageMaker. You build a Docker container that includes the required TensorFlow version and custom dependencies, then push the image to Amazon ECR. SageMaker can reference this image to create training jobs and deploy endpoints. By using Script Mode, you can execute your custom training script within the container, ensuring compatibility with your specific environment.
Incorrect options:
Build a Docker container with the required TensorFlow version and dependencies, push the container image to Docker Hub, and reference the image in SageMaker when creating the training job - While Docker Hub can be used to host container images, Amazon SageMaker is optimized to work with images stored in Amazon ECR, providing better security, performance, and integration with AWS services. Additionally, using Docker Hub for production ML workloads may pose security and compliance risks.
Package the model as a SageMaker-compatible file, upload it to Amazon S3, and use a pre-built SageMaker container for training, ensuring that the training job uses the custom environment - This option describes a standard SageMaker workflow using pre-built containers, which does not provide the customization required by the BYOC approach. SageMaker pre-built containers may not support the specific custom libraries and dependencies your model requires.
Deploy the model locally using Docker, then use the AWS Management Console to manually copy the environment and model files to a SageMaker instance for training - Manually deploying the model and environment locally and then copying files to SageMaker instances is not scalable or maintainable. SageMaker BYOC allows for a more robust, automated, and integrated solution.
References:
https://docs.aws.amazon.com/sagemaker/latest/dg/docker-containers.html
Question 10 Single Choice
A company stores its training datasets on Amazon S3 in the form of tabular data running into millions of rows. The company needs to prepare this data for Machine Learning jobs. The data preparation involves data selection, cleansing, exploration, and visualization using a single visual interface.
Which Amazon SageMaker service is the best fit for this requirement?
Explanation
Click "Show Answer" to see the explanation here
Correct option:
Amazon SageMaker Data Wrangler
Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for ML from weeks to minutes. With SageMaker Data Wrangler, you can simplify the process of data preparation and feature engineering, and complete each step of the data preparation workflow (including data selection, cleansing, exploration, visualization, and processing at scale) from a single visual interface. You can use SQL to select the data that you want from various data sources and import it quickly. Next, you can use the data quality and insights report to automatically verify data quality and detect anomalies, such as duplicate rows and target leakage. SageMaker Data Wrangler contains over 300 built-in data transformations, so you can quickly transform data without writing code.
With the SageMaker Data Wrangler data selection tool, you can quickly access and select your tabular and image data from various popular sources - such as Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift, AWS Lake Formation, Snowflake, and Databricks - and over 50 other third-party sources - such as Salesforce, SAP, Facebook Ads, and Google Analytics. You can also write queries for data sources using SQL and import data directly into SageMaker from various file formats, such as CSV, Parquet, JSON, and database tables.
How Data Wrangler works: 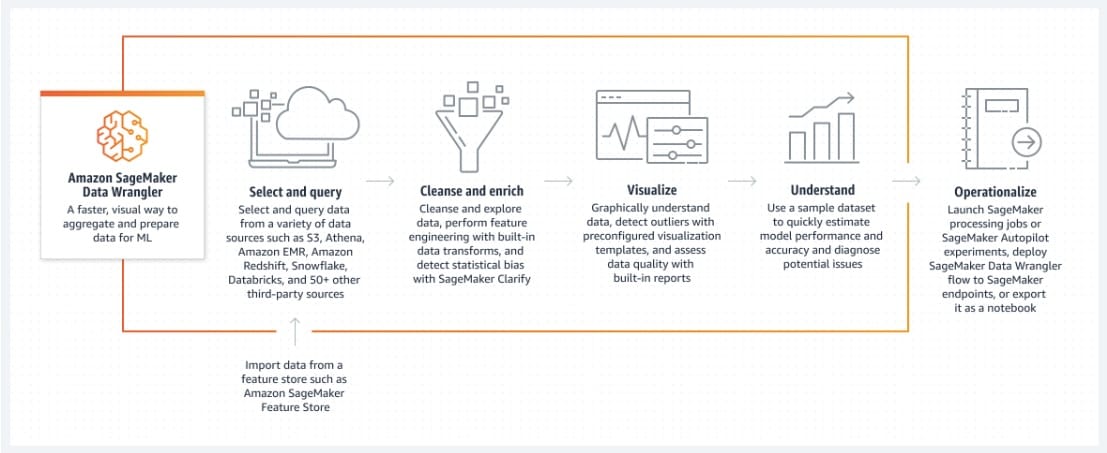 via - https://aws.amazon.com/sagemaker/data-wrangler/
via - https://aws.amazon.com/sagemaker/data-wrangler/
Incorrect options:
SageMaker Model Dashboard - Amazon SageMaker Model Dashboard is a centralized portal, accessible from the SageMaker console, where you can view, search, and explore all of the models in your account. You can track which models are deployed for inference and if they are used in batch transform jobs or hosted on endpoints.
Amazon SageMaker Clarify - SageMaker Clarify helps identify potential bias during data preparation without writing code. You specify input features, such as gender or age, and SageMaker Clarify runs an analysis job to detect potential bias in those features.
Amazon SageMaker Feature Store - Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference.
Reference:
Explanation
Correct option:
Amazon SageMaker Data Wrangler
Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for ML from weeks to minutes. With SageMaker Data Wrangler, you can simplify the process of data preparation and feature engineering, and complete each step of the data preparation workflow (including data selection, cleansing, exploration, visualization, and processing at scale) from a single visual interface. You can use SQL to select the data that you want from various data sources and import it quickly. Next, you can use the data quality and insights report to automatically verify data quality and detect anomalies, such as duplicate rows and target leakage. SageMaker Data Wrangler contains over 300 built-in data transformations, so you can quickly transform data without writing code.
With the SageMaker Data Wrangler data selection tool, you can quickly access and select your tabular and image data from various popular sources - such as Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift, AWS Lake Formation, Snowflake, and Databricks - and over 50 other third-party sources - such as Salesforce, SAP, Facebook Ads, and Google Analytics. You can also write queries for data sources using SQL and import data directly into SageMaker from various file formats, such as CSV, Parquet, JSON, and database tables.
How Data Wrangler works: via - https://aws.amazon.com/sagemaker/data-wrangler/
Incorrect options:
SageMaker Model Dashboard - Amazon SageMaker Model Dashboard is a centralized portal, accessible from the SageMaker console, where you can view, search, and explore all of the models in your account. You can track which models are deployed for inference and if they are used in batch transform jobs or hosted on endpoints.
Amazon SageMaker Clarify - SageMaker Clarify helps identify potential bias during data preparation without writing code. You specify input features, such as gender or age, and SageMaker Clarify runs an analysis job to detect potential bias in those features.
Amazon SageMaker Feature Store - Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference.
Reference:


